Telenor Nordics Customer Service self-help corpus
Pith reviewed 2026-06-29 18:23 UTC · model grok-4.3
The pith
A new public corpus supplies 1,122 validated self-help documents across Finnish, Danish, Norwegian, and Swedish for customer-service NLP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
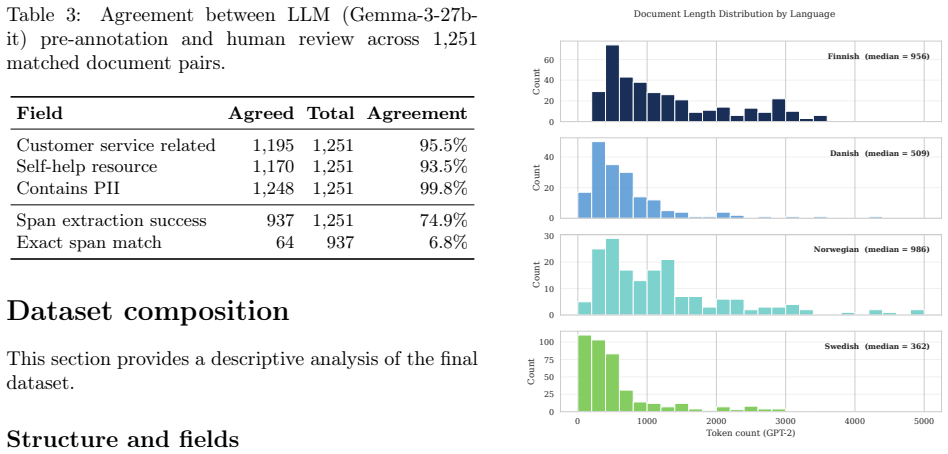
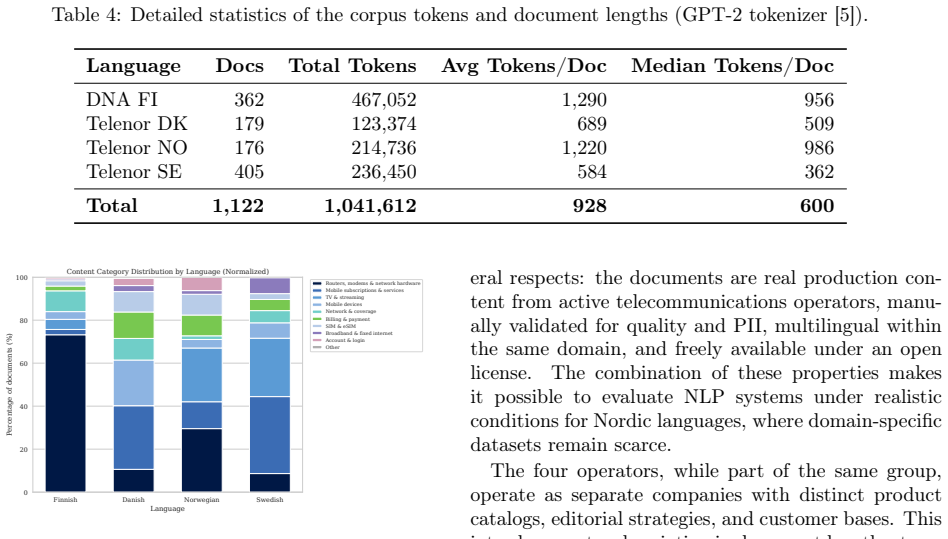
The paper establishes a multilingual customer service self-help corpus of 1,122 manually validated documents in Finnish, Danish, Norwegian, and Swedish. The texts were gathered from public operator pages, filtered for relevance and absence of personal data via an LLM-plus-human pipeline, and released under CC-BY-NC-SA-4.0. Analysis shows differences in document length and structure by operator together with coverage of network hardware, mobile services, TV, billing, and account management.
What carries the argument
The multilingual customer service self-help corpus, which aggregates and validates operator documents to serve as training and evaluation data for Nordic-language NLP tasks.
If this is right
- Enables reproducible experiments on retrieval-augmented generation in customer-service settings for Nordic languages.
- Supports cross-lingual transfer learning studies that include Finnish, Danish, Norwegian, and Swedish.
- Provides material for training or evaluating agent-based service architectures in the telecom domain.
- Allows quantitative comparison of editorial practices across operators through measurable differences in document length and structure.
Where Pith is reading between the lines
- The corpus could be used to test whether language models trained on general web text underperform on the specific vocabulary and phrasing found in operator self-help pages.
- Release under a non-commercial license may limit certain industry applications while still permitting academic and nonprofit reuse.
- The observed variation in document length suggests that any downstream model would need to handle both short procedural answers and longer explanatory articles.
Load-bearing premise
The combined LLM and human filtering step has removed personal information and retained only relevant documents without introducing substantial errors or omissions.
What would settle it
Inspection of the released files reveals either persistent personal names, phone numbers, or account details, or a large fraction of documents that do not address customer service topics.
Figures
read the original abstract
This paper presents a multilingual customer service self-help corpus comprising 1,122 manually validated documents in Finnish, Danish, Norwegian, and Swedish, totaling 274,599 words and 1,884,833 characters. The documents have been sourced from the public self-help pages of four Nordic telecommunications operators and subsequently filtered for person-identifiable information and relevance through a combined LLM and human annotation pipeline. Domain-specific datasets for Nordic languages remain scarce, particularly in customer service: a domain of growing importance for retrieval-augmented generation, cross-lingual transfer learning, and emerging agent-based service architectures. An analysis of the corpus reveals substantial variation in document length and structure across operators, reflecting distinct editorial strategies, as well as broad topical coverage spanning network hardware, mobile services, TV and streaming, billing, and account management. The dataset is publicly available under a CC-BY-NC-SA-4.0 license at https://zenodo.org/records/20732652, intended to support reproducible research in Nordic NLP and information retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a multilingual customer service self-help corpus comprising 1,122 manually validated documents in Finnish, Danish, Norwegian, and Swedish (totaling 274,599 words and 1,884,833 characters). Documents were sourced from public self-help pages of four Nordic telecom operators and filtered for person-identifiable information and relevance via a combined LLM and human annotation pipeline. The dataset is released publicly under CC-BY-NC-SA-4.0 at a Zenodo URL to support Nordic NLP and IR research, with an accompanying analysis of length variation and topical coverage.
Significance. If the validation claims hold, the release fills a documented gap in domain-specific Nordic-language resources for customer service, a domain relevant to RAG, cross-lingual transfer, and agent architectures. The public availability under a clear license is a concrete strength for reproducibility.
major comments (1)
- [filtering pipeline description (Methods)] The description of the LLM+human filtering pipeline (for PII removal and relevance) provides no inter-annotator agreement scores, no LLM prompt text or parameters, no false-positive/false-negative rates from held-out checks, and no post-filter audit statistics. This directly affects the load-bearing claim that the 1,122 documents are 'manually validated' and reliably cleaned; residual PII or off-topic items would falsify the headline counts and qualifiers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the filtering pipeline. We address the major comment below and commit to revisions where possible to strengthen the manuscript.
read point-by-point responses
-
Referee: [filtering pipeline description (Methods)] The description of the LLM+human filtering pipeline (for PII removal and relevance) provides no inter-annotator agreement scores, no LLM prompt text or parameters, no false-positive/false-negative rates from held-out checks, and no post-filter audit statistics. This directly affects the load-bearing claim that the 1,122 documents are 'manually validated' and reliably cleaned; residual PII or off-topic items would falsify the headline counts and qualifiers.
Authors: We agree the current Methods description is insufficiently detailed. In revision we will add the exact LLM prompts, model names, and parameters used for the initial filtering steps. We will also expand the description of the human validation stage, including the criteria applied for PII and relevance, and report any available post-filter audit numbers (e.g., documents reviewed or removed after the LLM stage). revision: yes
- Inter-annotator agreement scores and false-positive/false-negative rates from held-out checks, because these metrics were not computed during the original single-pass LLM-assisted human validation process.
Circularity Check
Data release paper with no derivations, predictions, or equations
full rationale
This is a data release paper presenting a corpus of 1,122 documents. The abstract and full text describe sourcing from public pages, filtering via LLM+human pipeline, and releasing the dataset under CC-BY-NC-SA-4.0. No equations, models, predictions, or first-principles derivations are present. The central claim is the corpus description and counts, which stand as factual reporting without any reduction to self-defined inputs, fitted parameters renamed as predictions, or self-citation chains. No load-bearing steps match the enumerated circularity patterns. The paper is self-contained against external benchmarks as a resource contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kvale K, Freddi E, Hodnebrog S, Sell OA, and Følstad A. Understanding the User Experience of Customer Service Chatbots: What Can We Learn from Customer Satisfaction Surveys?Chatbot Re- search and Design (CONVERSATIONS 2020). Vol. 12604. Lecture Notes in Computer Science. Springer, 2021 :205–18.doi:10.1007/978- 3- 030-68288-0_14
-
[2]
Riess M and Jørgensen TE. The BRAGE Bench- mark: Evaluating Zero-shot Learning Capabili- ties of Large Language Models for Norwegian Customer Service Dialogues.Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Hu- man Language Technologies (NoDaLiDa/Baltic- HLT 2025). Ed. by Johansson R and Stymne S...
2025
-
[3]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Gebru T, Morgenstern J, Vecchione B, Vaughan JW, Wallach H, III HD, and Crawford K. Datasheets for datasets. Commun. ACM 2021; 64:86–92.doi:10.1145/3458723
-
[4]
Gemma Team. Gemma 3 Technical Report. 2025. arXiv:2503.19786 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Language Models are Unsuper- vised Multitask Learners
Radford A, Wu J, Child R, Luan D, Amodei D, and Sutskever I. Language Models are Unsuper- vised Multitask Learners. OpenAI Blog 2019. Available from:https : / / cdn . openai . com / better- language- models/language_models_ are_unsupervised_multitask_learners.pdf
2019
-
[6]
Multilingual E5 Text Embeddings: A Technical Report
Wang L, Yang N, Huang X, Yang L, Majumder R, and Wei F. Multilingual E5 Text Embeddings: A Technical Report. 2024. arXiv:2402 . 05672 [cs.CL]
2024
-
[7]
The Scandinavian Embedding Bench- marks: Evaluating Multilingual and Monolingual Text Embedding for Scandinavian Languages
Enevoldsen K, Kardos M, Muennighoff N, and Nielbo KL. The Scandinavian Embedding Bench- marks: Evaluating Multilingual and Monolingual Text Embedding for Scandinavian Languages. Proceedings of the 38th International Confer- ence on Neural Information Processing Systems (NeurIPS). Curran Associates Inc., 2024
2024
-
[8]
Cohen D et al. WixQA: A Multi-Dataset Bench- mark for Enterprise Retrieval-Augmented Gener- ation. 2025. arXiv:2505.08643 [cs.CL]
-
[9]
CXMArena: Unified Dataset to Benchmark Customer Experience Management
Sprinklr AI. CXMArena: Unified Dataset to Benchmark Customer Experience Management
- [10]
-
[11]
Judgment under Uncertainty: Heuristics and Biases
Tversky A and Kahneman D. Judgment under Uncertainty: Heuristics and Biases. Science 1974; 185:1124–31.doi:10.1126/science.185.4157. 1124
-
[12]
Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Sub- jective Tasks
Chiang CW et al. Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Sub- jective Tasks. 2025. arXiv:2507.15821 [cs.CL] 5
-
[13]
Telenor Nordics Customer Service Self- Help Corpus
Riess M. Telenor Nordics Customer Service Self- Help Corpus. Version 1.0. Zenodo, 2026 Apr. doi:10.5281/zenodo.19493152. Available from: https://doi.org/10.5281/zenodo.19493152 6 Appendices
-
[14]
f i l t e r i n g
Prompt used for annotation Data annotation prompt: gemma-3-27b-it You are an expert text analyst tasked with a n n o t a t i n g web page content based on s pec if ic ,→c rit er ia . Analyze the f o l l o w i n g d oc um en t text and provide your an aly si s ONLY in ,→the form of a valid JSON object m at ch ing the s p e c i f i e d s t r u c t u r e . *...
-
[15]
** F i l t e r i n g :** D e t e r m i n e the boolean values for ‘ c u s t o m e r _ s e r v i c e _ r e l a t e d ‘ and ‘ ,→s e l f _ h e l p _ r e s o u r c e ‘
-
[16]
Set ‘ contains_pii ‘ to true ONLY if full names are found
** PII D e t e c t i o n :** D e t e r m i n e if the d oc ume nt con ta in s any ** full names of ,→i n d i v i d u a l s **. Set ‘ contains_pii ‘ to true ONLY if full names are found
-
[17]
f i l t e r i n g
** Content S e l e c t i o n :** Id en tif y the single , c o n t i n u o u s block of text within the ,→do cum en t that r e p r e s e n t s the most re lev an t core content for the purpose of ,→cu sto me r service or self - help i n f o r m a t i o n . Exclude common headers , footers , ,→navigation , ads , and b o i l e r p l a t e . * If a re le va n...
-
[18]
Pre se rv e the or ig in al m ar kd own ,→f o r m a t t i n g ( headings , lists , code blocks , links , bold , italics , etc .) exactly
Prompt used for translation Data translation prompt: gemma-3-27b-it T r a n s l a t e the f o l l o w i n g m ark do wn d oc um en t into English . Pre se rv e the or ig in al m ar kd own ,→f o r m a t t i n g ( headings , lists , code blocks , links , bold , italics , etc .) exactly . ,→Output ONLY the t r a n s l a t e d English ma rk do wn text . D O C...
-
[19]
quick select
Annotation UI Figure 3: Screenshot of the Annotation UI used to select the relevant text and annotate the documents. This UI also had a “quick select” button for regex pattern matching when the LLM-suggested span was invalid. 8
-
[20]
Content Categories Table 5: Content category distribution by language, based on zero-shot embedding classification of English translations. Category FI DK NO SE Total Routers & network hardware 265 19 52 35 371 Mobile subscriptions 9 53 22 145 229 TV & streaming 17 0 44 110 171 Mobile devices 13 38 7 29 87 Network & coverage 35 18 3 23 79 Billing & paymen...
-
[21]
Descriptions used for topic classification Table 6: Category descriptions used for zero-shot embedding classification. Category Description Mobile subscriptions & services Mobile phone subscriptions, plans, prepaid, roaming, MMS, SMS, VoLTE, VoWiFi, mobile services Broadband & fixed inter- net Broadband, fiber, DSL, fixed internet connection, internet spe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.