Trust-Aware Multi-Agent Traceability: Confidence-Calibrated Knowledge Graphs for Consistent Software Artifact Management
Pith reviewed 2026-06-27 02:44 UTC · model grok-4.3
The pith
A shared knowledge graph with calibrated confidence scores lets agents coordinate and avoid propagating errors through sequential software engineering pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a trust-aware coordination framework where a shared knowledge graph serves as both centralized semantic memory and a coordination surface through which agents assess and build upon each other's contributions using calibrated confidence scores. Our approach introduces a two-stage traceability link prediction pipeline combining embedding-based retrieval with LLM-based multi-criteria analysis, a traceability seeding mechanism that enables comparison between derivation-time and validation-time confidence, and a consistency protocol governing pipeline interactions through confidence threshold gating, confidence divergence detection, and conflict resolution.
What carries the argument
The shared knowledge graph as coordination surface that stores contributions alongside calibrated confidence scores for agent-to-agent assessment.
If this is right
- Two-stage prediction improves link quality by first retrieving candidates then applying multi-criteria LLM review.
- Seeding allows direct comparison of confidence at creation versus later validation.
- Threshold gating stops low-confidence outputs from entering the shared graph.
- Divergence detection flags cases where later validation disagrees with initial scores.
- Conflict resolution keeps the graph consistent when agents propose conflicting links.
Where Pith is reading between the lines
- The same graph-plus-scores surface could coordinate agents in domains outside software, such as regulatory document chains.
- Threshold sensitivity observed in the study implies that each new application domain would require its own calibration tuning.
- If seeding proves effective, it could be added to existing multi-agent toolchains without redesigning the underlying models.
- The ablation result on calibration suggests that omitting the confidence layer would collapse coordination benefits even if the graph structure remains.
Load-bearing premise
That agents can produce confidence scores which accurately reflect the reliability of their decisions and that the graph can block unreliable contributions from affecting later stages.
What would settle it
A measurement showing that the reported confidence scores from upstream agents have no correlation with the actual accuracy of the traceability links they generate when checked against ground truth in the automotive case study.
Figures

read the original abstract
Multi-agent AI systems are increasingly used to automate software engineering tasks including requirements analysis, architecture design, test generation, and traceability linking. When these agents operate as a sequential pipeline over shared software artifacts, errors and low-confidence decisions made by upstream agents propagate to downstream stages, producing orphaned requirements, contradictory links, and compliance gaps that pose significant risks in safety-critical domains. We propose a trust-aware coordination framework where a shared knowledge graph serves as both centralized semantic memory and a coordination surface through which agents assess and build upon each other's contributions using calibrated confidence scores. Our approach introduces a two-stage traceability link prediction pipeline combining embedding-based retrieval with LLM-based multi-criteria analysis, a traceability seeding mechanism that enables comparison between derivation-time and validation-time confidence, and a consistency protocol governing pipeline interactions through confidence threshold gating, confidence divergence detection, and conflict resolution. We evaluate on an automotive software engineering case study measuring link prediction calibration, protocol effectiveness, threshold sensitivity, and the impact of traceability seeding. Ablation studies confirm that confidence calibration is essential for effective pipeline coordination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a trust-aware coordination framework for multi-agent AI systems automating software engineering tasks. A shared knowledge graph serves as both centralized semantic memory and coordination surface, enabling agents to assess and build on contributions via calibrated confidence scores. Core elements include a two-stage traceability link prediction pipeline (embedding-based retrieval plus LLM-based multi-criteria analysis), a traceability seeding mechanism comparing derivation-time and validation-time confidence, and a consistency protocol using threshold gating, divergence detection, and conflict resolution. Evaluation occurs on an automotive software engineering case study, reporting metrics on link prediction calibration, protocol effectiveness, threshold sensitivity, and seeding impact, with ablations asserted to confirm calibration's necessity.
Significance. If the calibration of agent confidence scores is shown to be reliable and the protocol demonstrably reduces error propagation, the framework could meaningfully advance reliable multi-agent pipelines in safety-critical domains such as automotive software. The positioning of the knowledge graph as an active coordination surface, combined with traceability seeding, offers a concrete mechanism for trust-aware artifact management that addresses a recognized pain point in sequential agent workflows.
major comments (2)
- [Abstract] Abstract: The text asserts that 'ablation studies confirm that confidence calibration is essential for effective pipeline coordination' and that the evaluation measures 'link prediction calibration,' yet supplies no description of the calibration procedure itself (e.g., temperature scaling, isotonic regression, or proper scoring rules) and reports no quantitative validation such as ECE or Brier scores. This directly undermines the central claim that the consistency protocol can block error propagation, because the protocol's gating and conflict-resolution steps presuppose that the scores accurately reflect reliability.
- [Evaluation section] Evaluation section: The manuscript claims quantitative assessment of 'protocol effectiveness,' 'threshold sensitivity,' and 'the impact of traceability seeding' on an automotive case study, but the provided description contains no tables, figures, numerical results, or statistical comparisons. Without these data it is impossible to evaluate whether the framework achieves its stated coordination benefits or whether the ablations actually support the necessity of calibration.
minor comments (2)
- The terms 'calibrated confidence scores' and 'traceability seeding' are introduced without an initial formal definition or illustrative example, which may hinder immediate comprehension of how the scores are produced and compared.
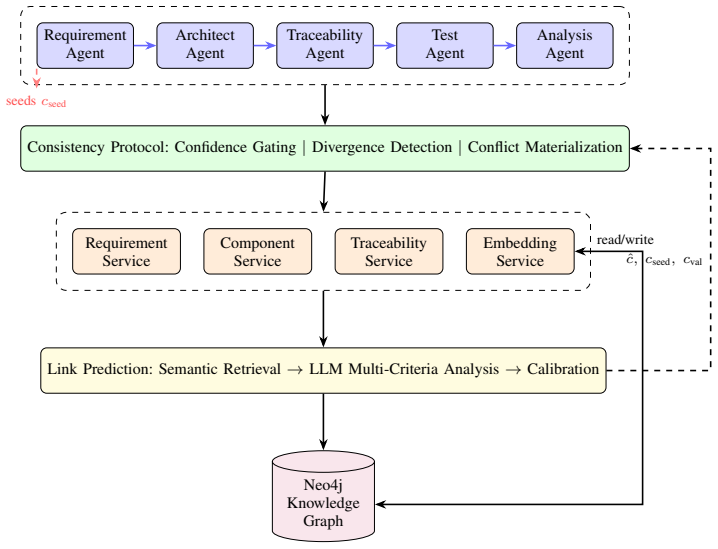
- A diagram showing the overall architecture (agents, shared KG, two-stage pipeline, and consistency protocol) would clarify the data and control flows.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and commit to revisions that directly resolve the identified gaps in detail and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The text asserts that 'ablation studies confirm that confidence calibration is essential for effective pipeline coordination' and that the evaluation measures 'link prediction calibration,' yet supplies no description of the calibration procedure itself (e.g., temperature scaling, isotonic regression, or proper scoring rules) and reports no quantitative validation such as ECE or Brier scores. This directly undermines the central claim that the consistency protocol can block error propagation, because the protocol's gating and conflict-resolution steps presuppose that the scores accurately reflect reliability.
Authors: We agree that the abstract currently references ablation studies and link-prediction calibration without describing the procedure or reporting quantitative metrics such as ECE or Brier scores. The full manuscript describes temperature scaling for calibration and computes ECE/Brier scores in the evaluation, but these elements are not sufficiently foregrounded. We will revise the abstract to include a concise statement of the calibration method and key calibration metrics, and we will add explicit cross-references to the evaluation results that link calibration quality to the protocol's error-blocking performance. revision: yes
-
Referee: [Evaluation section] Evaluation section: The manuscript claims quantitative assessment of 'protocol effectiveness,' 'threshold sensitivity,' and 'the impact of traceability seeding' on an automotive case study, but the provided description contains no tables, figures, numerical results, or statistical comparisons. Without these data it is impossible to evaluate whether the framework achieves its stated coordination benefits or whether the ablations actually support the necessity of calibration.
Authors: We accept that the current evaluation section does not present the supporting tables, figures, numerical results, or statistical comparisons. In the revised manuscript we will insert the missing quantitative results (including calibration metrics, protocol-effectiveness measures, threshold-sensitivity curves, seeding-impact comparisons, and ablation tables) together with the corresponding figures and statistical tests. This will allow direct assessment of the claimed coordination benefits and the necessity of calibration. revision: yes
Circularity Check
No significant circularity; no derivations or self-referential steps present
full rationale
The paper proposes a trust-aware multi-agent framework relying on calibrated confidence scores and a shared knowledge graph for traceability, but the abstract and description contain no equations, derivations, fitted parameters, or load-bearing claims that reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a way that creates circularity. The approach references external calibration concepts without detailing them internally, but since no mathematical chain or prediction-by-fit is claimed, the derivation (such as it is) is self-contained and independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models for software engineering: Survey and open problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large language models for software engineering: Survey and open problems,”arXiv preprint arXiv:2310.03533, 2023
-
[2]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[3]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta programming for a multi-agent collaborative framework,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[4]
ChatDev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun, “ChatDev: Communicative agents for software development,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. [5]ISO 26262: Road Vehicles – Functional Safety, International Organiza- tio...
2024
-
[5]
Recovering from a decade: A systematic mapping of information retrieval approaches to software traceability,
M. Borg, P. Runeson, and A. Ardö, “Recovering from a decade: A systematic mapping of information retrieval approaches to software traceability,”Empirical Software Engineering, vol. 19, no. 6, pp. 1565– 1616, 2014
2014
-
[6]
Semantically enhanced soft- ware traceability using deep learning techniques,
J. Guo, J. Cheng, and J. Cleland-Huang, “Semantically enhanced soft- ware traceability using deep learning techniques,” inProceedings of the 39th International Conference on Software Engineering (ICSE). IEEE, 2017, pp. 3–14
2017
-
[7]
Traceability transformed: Generating more accurate links with pre-trained BERT models,
J. Lin, Y . Liu, Q. Zeng, M. Jiang, and J. Cleland-Huang, “Traceability transformed: Generating more accurate links with pre-trained BERT models,” inProceedings of the 43rd International Conference on Soft- ware Engineering (ICSE). IEEE, 2021, pp. 324–335
2021
-
[8]
Prompts matter: Insights and strategies for prompt engineering in automated software traceability,
D. Rodriguez-Cardenas, D. N. Palacio, S. Khoshmanesh, D. Poshyvanyk, and A. Bansal, “Prompts matter: Insights and strategies for prompt engineering in automated software traceability,” inProceedings of the IEEE International Requirements Engineering Conference (RE). IEEE, 2023
2023
-
[9]
Software knowledge graph: A survey,
Y . Zhao, X. Wang, and W. Che, “Software knowledge graph: A survey,” IEEE Transactions on Software Engineering, vol. 49, no. 4, pp. 2576– 2595, 2023
2023
-
[10]
The COEST/TraceLab machine learning chal- lenge for automated traceability link recovery,
M. Rath and P. Mäder, “The COEST/TraceLab machine learning chal- lenge for automated traceability link recovery,” inProceedings of the 6th International Workshop on Realizing Artificial Intelligence Synergies in Software Engineering (RAISE). ACM, 2018, pp. 26–29
2018
-
[11]
Recovering traceability links between code and documentation,
G. Antoniol, G. Canfora, G. Casazza, A. De Lucia, and E. Merlo, “Recovering traceability links between code and documentation,”IEEE Transactions on Software Engineering, vol. 28, no. 10, pp. 970–983, 2002
2002
-
[12]
Requirements traceabil- ity link recovery via retrieval-augmented generation,
T. Hey, J. Keim, A. Koziolek, and W. F. Tichy, “Requirements traceabil- ity link recovery via retrieval-augmented generation,” inProceedings of the International Conference on Conceptual Modeling (ER). Springer, 2024
2024
-
[13]
LLM- based approach to automatically establish traceability between require- ments and MBSE,
M. Bonner, M. Zeller, G. Schulz, D. Beyer, and M. Olteanu, “LLM- based approach to automatically establish traceability between require- ments and MBSE,” inINCOSE International Symposium, vol. 34. Wiley, 2024
2024
-
[14]
Who's Who? LLM-assisted Software Traceability with Architecture Entity Recognition
J. Keim, D. Fuchss, and A. Koziolek, “Who’s who? LLM-assisted software traceability with architecture entity recognition,”arXiv preprint arXiv:2511.02434, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Cleland-Huang, O
J. Cleland-Huang, O. Gotel, and A. Zisman,Software and Systems Traceability. Springer, 2012
2012
-
[16]
AGENTiGraph: A multi- agent knowledge graph framework for interactive, domain-specific LLM chatbots,
Y . Yang, S. Park, A. S. Kim, and J. Lee, “AGENTiGraph: A multi- agent knowledge graph framework for interactive, domain-specific LLM chatbots,”arXiv preprint arXiv:2508.02999, 2025
-
[17]
KARMA: Leveraging multi-agent LLMs for automated knowledge graph enrichment,
Anonymous, “KARMA: Leveraging multi-agent LLMs for automated knowledge graph enrichment,”OpenReview (Under Review), 2025
2025
-
[18]
On agent-based software engineering,
N. R. Jennings, “On agent-based software engineering,”Artificial Intel- ligence, vol. 117, no. 2, pp. 277–296, 2000
2000
-
[19]
Intelligent agents: Theory and practice,
M. Wooldridge and N. R. Jennings, “Intelligent agents: Theory and practice,”The Knowledge Engineering Review, vol. 10, no. 2, pp. 115– 152, 1995
1995
-
[20]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,
K. Tian, E. Mitchell, A. Zhou, A. Sharma, R. Rafailov, H. Yao, C. Finn, and C. D. Manning, “Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Lin...
2023
-
[21]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProceedings of the 34th International Conference on Machine Learning (ICML). PMLR, 2017, pp. 1321– 1330
2017
-
[22]
Can LLMs express their uncertainty? an empirical evaluation of confidence elicita- tion in LLMs,
M. Xiong, Z. Hu, X. Lu, Y . Li, J. Fu, J. He, and B. Hooi, “Can LLMs express their uncertainty? an empirical evaluation of confidence elicita- tion in LLMs,” inInternational Conference on Learning Representations (ICLR), 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.