BluTrain: A C++/CUDA Framework for AI Systems
Pith reviewed 2026-06-25 23:21 UTC · model grok-4.3
The pith
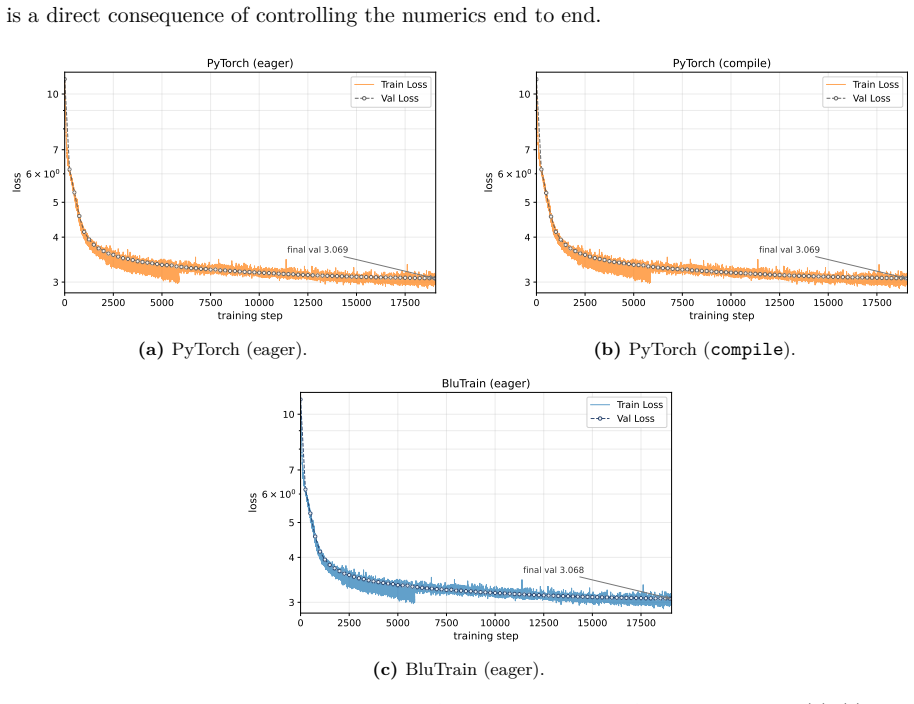
A native C++ and CUDA training framework sustains higher throughput and lower memory use than PyTorch for a 124M GPT-2 model while preserving numerical fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
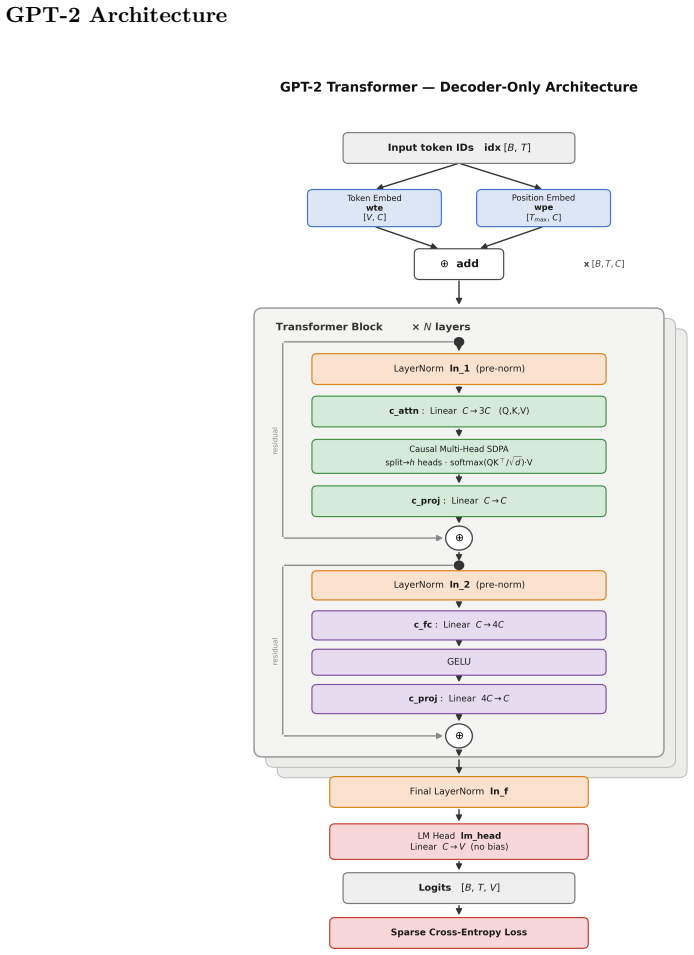
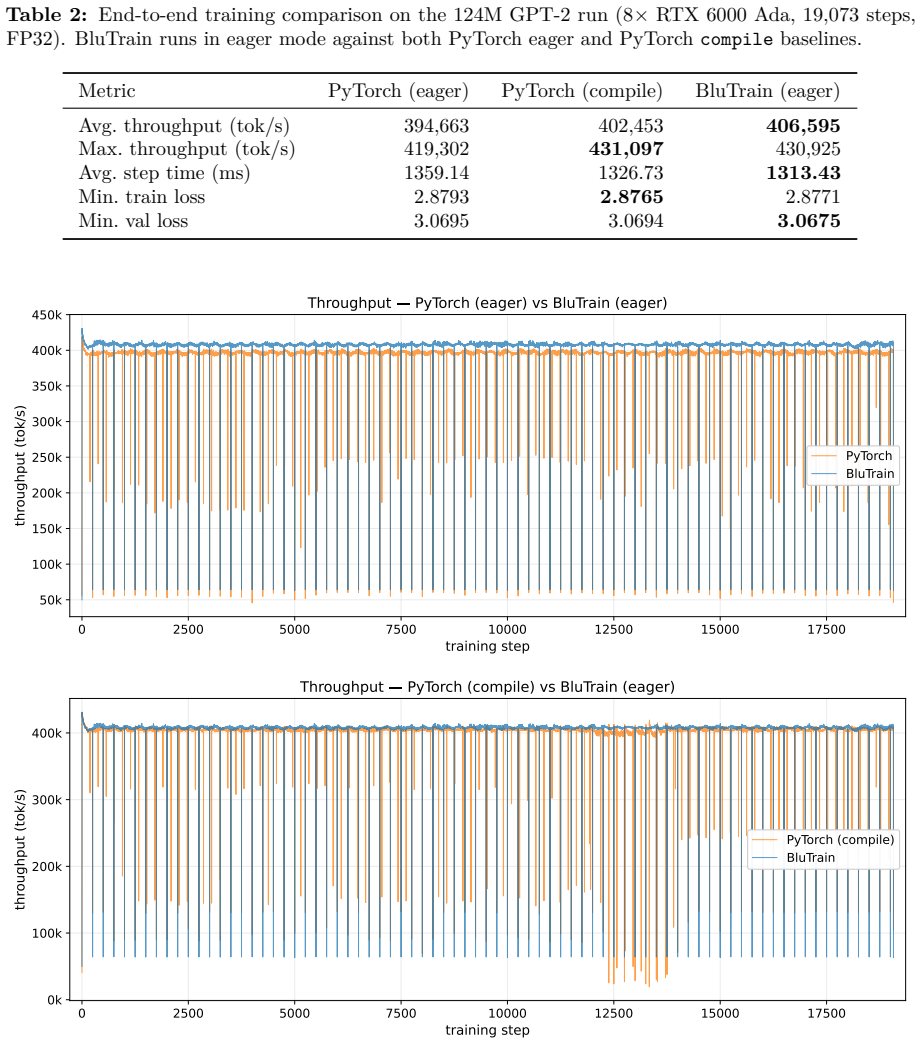
BluTrain is a lightweight, architecture-general training framework in C++ and CUDA with a typed tensor module that includes reverse-mode autograd, a linear-algebra library, a caching allocator, a multi-mode distributed-execution module, and an MLIR-based deep-learning compiler. Every layer is implemented natively to achieve absolute control over hardware expression while abstracting systems complexity. In formal evaluations on a 124M-parameter GPT-2 baseline in FP32 on an 8-GPU 6000 Ada system, it sustains an average of 407K tokens/s versus PyTorch's 395K tokens/s, achieves up to a 22% footprint reduction, preserves numerical fidelity, and converges to a marginally lower final validation los
What carries the argument
The native C++/CUDA implementation of every layer, including the typed tensor module with reverse-mode autograd and the multi-mode distributed-execution module, which carries the argument by enabling direct hardware control and tuning.
If this is right
- Training throughput for models like GPT-2 can reach 407K tokens per second on 8-GPU systems through native framework design.
- Memory footprint during training can be reduced by up to 22% compared with industry-standard frameworks.
- Numerical fidelity remains strictly preserved and validation loss can reach a marginally lower value.
- The performance ceiling for training becomes the framework's own to raise through explicit native tuning of every layer.
Where Pith is reading between the lines
- Teams training large models on specific hardware clusters could adopt native frameworks to lower per-epoch wall-clock time and hardware requirements.
- Open native code bases might allow targeted optimizations for new accelerator generations that closed frameworks cannot expose.
- The same approach could be tested on other model families such as vision transformers or diffusion models to check for similar gains.
- Production pipelines might integrate such frameworks to reduce overall training energy use when the reported memory savings scale.
Load-bearing premise
The reported throughput and memory numbers were obtained under identical experimental conditions, model configurations, and optimization settings as the PyTorch baseline.
What would settle it
Re-running the 124M-parameter GPT-2 training experiment on the same 8-GPU system with all data loading, precision handling, and kernel parameters fully disclosed and identical to the baseline, then checking whether the 407K versus 395K tokens/s difference and 22% memory reduction still appear.
Figures

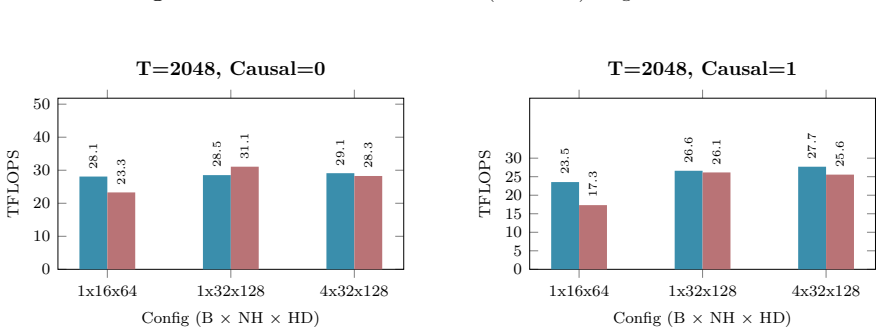
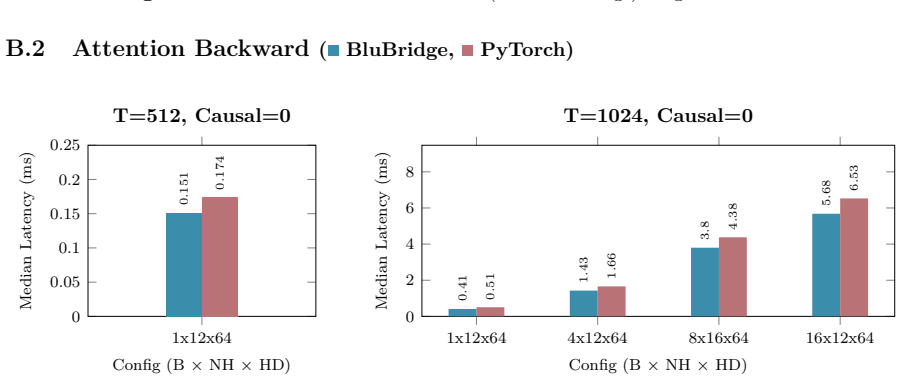
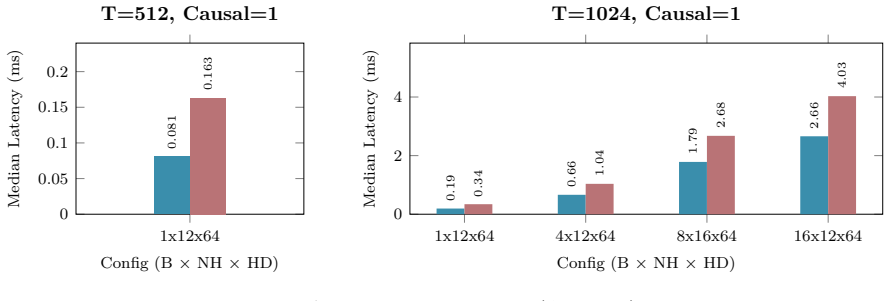
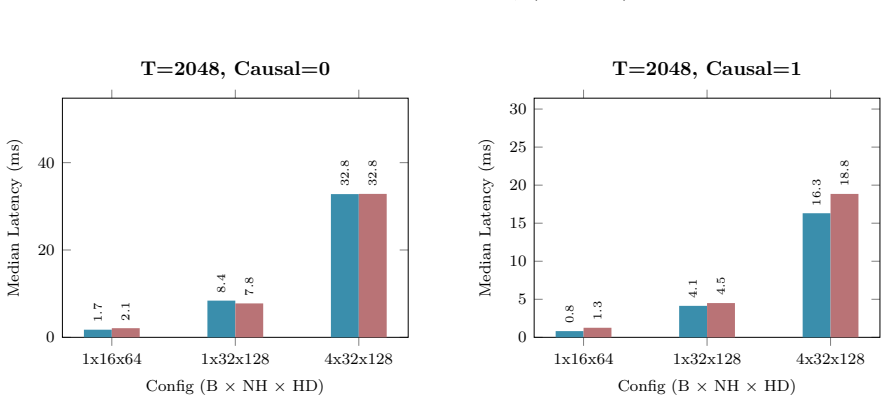
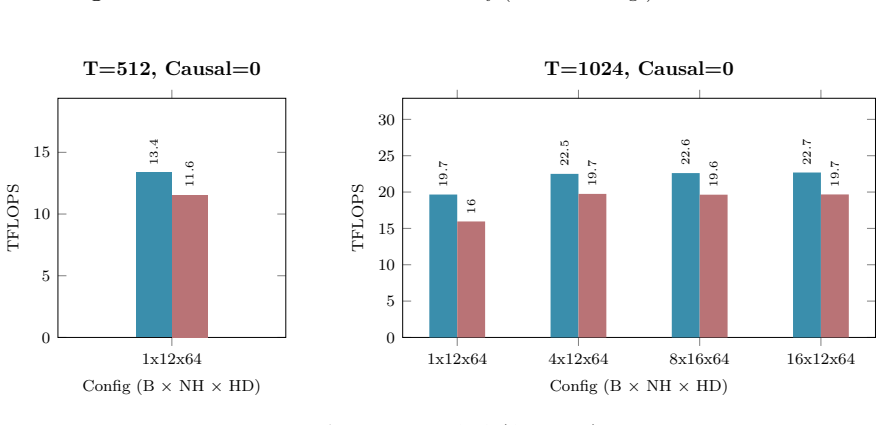
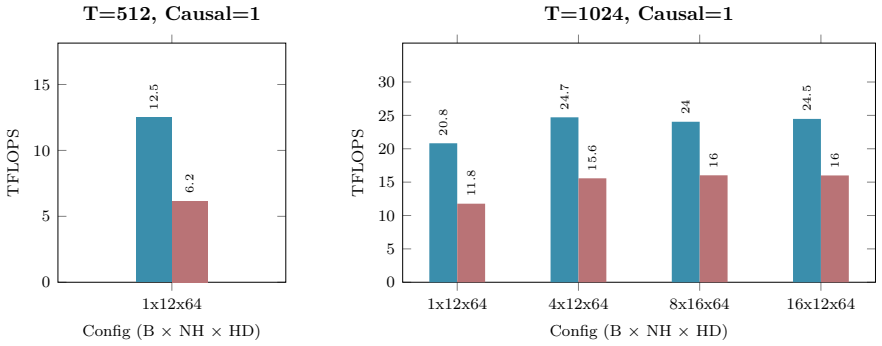
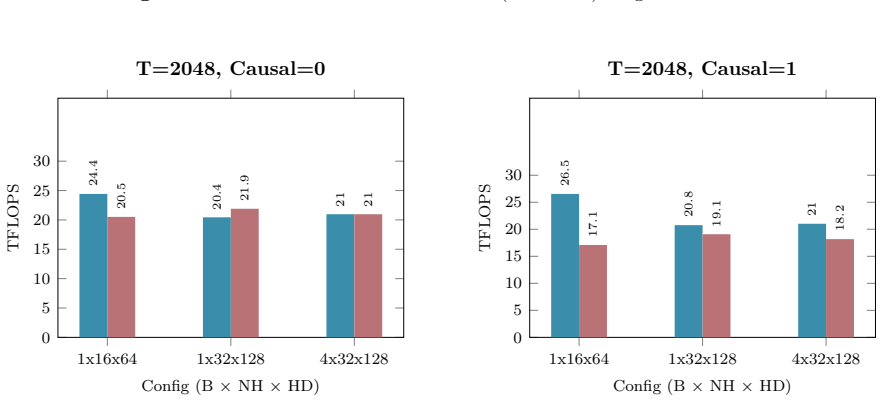
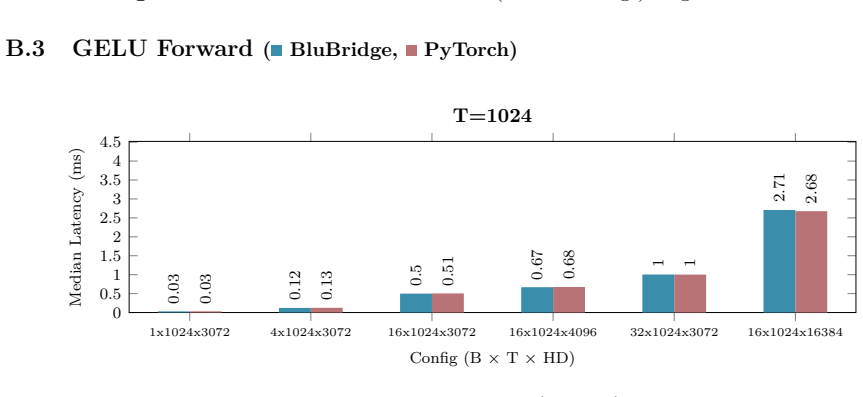


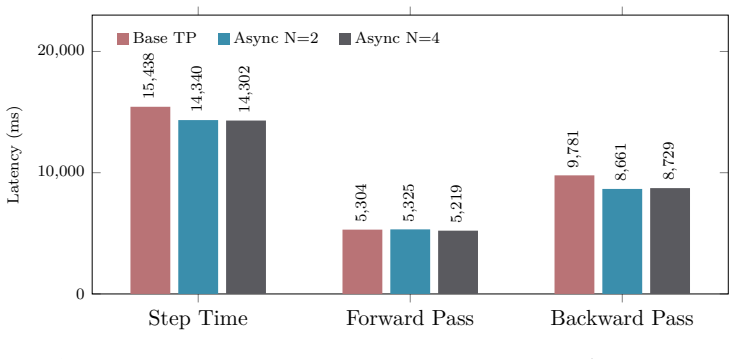

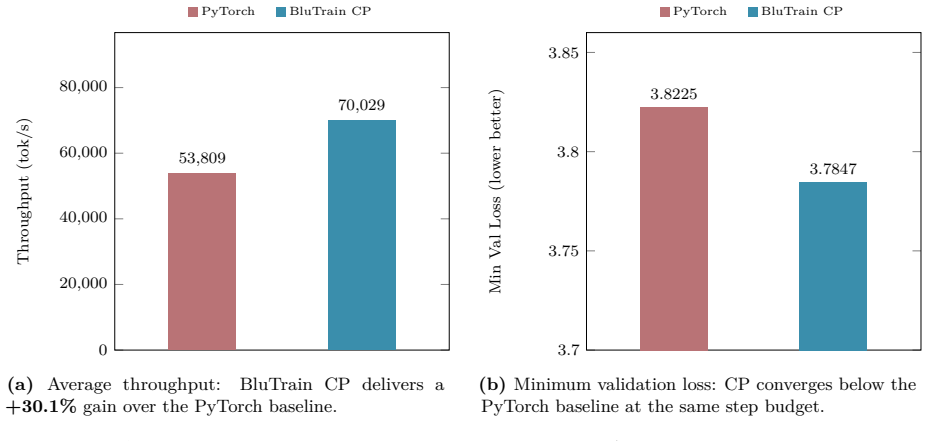
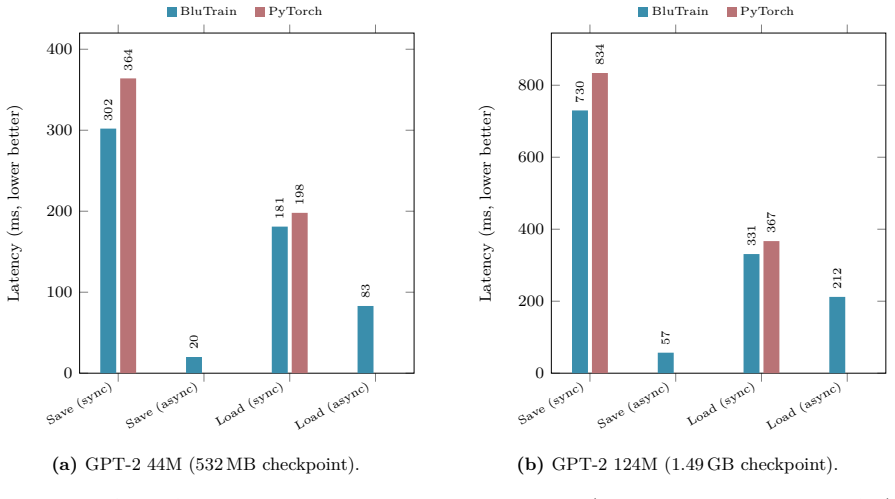
read the original abstract
Progress in deep learning is, at scale, more a matter of systems engineering than of modelling: the behaviour of a model in training (its throughput, its memory footprint, and the numerical fidelity of the result) is determined less by the architecture itself than by how that architecture is expressed on the hardware. To achieve absolute control over this hardware expression while abstracting away systems complexity to make modelling seamless and eliminating the need for repetitive orchestration logic, BluTrain was architected from first principles as a robust, lightweight, and architecture-general training framework in standard C++ and the core CUDA programming model. Every layer is implemented natively: a typed tensor module with reverse-mode autograd, a linear-algebra library, a caching allocator, a multi-mode distributed-execution module, and an MLIR-based deep-learning compiler. In formal evaluations training a 124M-parameter GPT-2 baseline in FP32 on an 8-GPU 6000 Ada system, BluTrain outperforms industry-standard baselines in both throughput (sustaining an average of 407K tokens/s versus PyTorch's 395K tokens/s) and memory efficiency (achieving up to a 22% footprint reduction), while strictly preserving numerical fidelity and converging to a marginally lower final validation loss. With every layer explicitly open to native tuning, the performance ceiling is the framework's own to raise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BluTrain, a C++/CUDA training framework built from first principles with native typed tensors and reverse-mode autograd, a linear-algebra library, caching allocator, multi-mode distributed execution, and an MLIR-based compiler. It claims that training a 124M-parameter GPT-2 model in FP32 on an 8-GPU Ada 6000 system yields 407K tokens/s throughput (vs. PyTorch 395K) and up to 22% lower memory footprint while preserving numerical fidelity and achieving a marginally lower validation loss.
Significance. If the performance claims can be substantiated under controlled conditions, the work would offer a fully open, natively tunable alternative to dominant frameworks, with the potential to raise performance ceilings through direct kernel access; however, the absence of verifiable experimental controls currently prevents this assessment.
major comments (1)
- [Abstract] Abstract: the headline claims of 407K vs 395K tokens/s throughput and 22% memory reduction are presented with no description of batch size, sequence length, data-loader implementation, gradient-accumulation steps, optimizer-state placement, kernel-launch configuration, or whether the PyTorch baseline used stock nn.Linear/F.scaled_dot_product_attention or any custom extensions; without these controls the 3% throughput delta cannot be attributed to the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern regarding insufficient experimental controls in the abstract is valid, and we will revise the manuscript to address it directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 407K vs 395K tokens/s throughput and 22% memory reduction are presented with no description of batch size, sequence length, data-loader implementation, gradient-accumulation steps, optimizer-state placement, kernel-launch configuration, or whether the PyTorch baseline used stock nn.Linear/F.scaled_dot_product_attention or any custom extensions; without these controls the 3% throughput delta cannot be attributed to the framework.
Authors: We agree that the abstract, in its current form, omits key experimental parameters required to interpret the reported deltas. In the revised manuscript we will expand the abstract to specify the batch size, sequence length, data-loader implementation, number of gradient-accumulation steps, optimizer-state placement (CPU vs. GPU), kernel-launch configuration, and explicit confirmation that the PyTorch baseline used only stock nn.Linear and F.scaled_dot_product_attention with no custom extensions. These additions will make the 3 % throughput and 22 % memory claims attributable to BluTrain under controlled conditions. revision: yes
Circularity Check
No circularity; paper is a systems description with no derivations or fitted predictions
full rationale
The manuscript describes the architecture and implementation of a C++/CUDA training framework, including native layers, autograd, allocator, and compiler components. Performance numbers (407K vs 395K tokens/s, 22% memory reduction) are presented as direct empirical measurements on a GPT-2 baseline. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on benchmark results rather than any mathematical reduction to inputs. This matches the default expectation of no significant circularity for non-derivational systems papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The CUDA programming model and MLIR infrastructure behave as documented by NVIDIA and the MLIR project.
Reference graph
Works this paper leans on
-
[1]
C. Lattner et al. MLIR: A Compiler Infrastructure for the End of Moore’s Law. arXiv:2002.11654, 2020
arXiv 2002
-
[2]
Li et al
S. Li et al. PyTorch Distributed: Experiences on Accelerating Data Parallel Training.VLDB, 2020
2020
-
[3]
Paszke et al
A. Paszke et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library.NeurIPS, 2019
2019
-
[4]
M. Shoeybi et al. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053, 2019
Pith/arXiv arXiv 1909
-
[5]
He et al
H. He et al. Introducing Async Tensor Parallelism in PyTorch (TorchTitan).PyTorch Dev Discuss, 2024
2024
-
[6]
Wu et al
X. Wu et al. Breaking Barriers: Training Long Context LLMs with 1M Sequence Length in PyTorch Using Context Parallel.PyTorch Dev Discuss, 2025
2025
-
[7]
Dao et al
T. Dao et al. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS, 2022
2022
-
[8]
Liu et al
H. Liu et al. Ring Attention with Blockwise Transformers for Near-Infinite Context.ICLR, 2024
2024
-
[9]
Introducing Context Parallelism
Insujang. Introducing Context Parallelism. https://insujang.github.io/2024-09-20/ introducing-context-parallelism/, 2024
2024
-
[10]
Narayanan et al
D. Narayanan et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron- LM.SC, 2021. 19
2021
-
[11]
Eisenman et al
A. Eisenman et al. Check-N-Run: A Checkpointing System for Training Deep Learning Recommen- dation Models.NSDI, 2022
2022
-
[12]
Nie et al
B. Nie et al. Characterizing Temperature, Power, and Soft-Error Behaviors in Data Center GPUs: A Field Study. 2018
2018
-
[13]
Zhao et al
Y. Zhao et al. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.VLDB, 2023
2023
-
[14]
BluBLAS: Hand-Tuned GEMM Kernels for Ada Lovelace Tensor Cores
BluBridge Team. BluBLAS: Hand-Tuned GEMM Kernels for Ada Lovelace Tensor Cores. BluBridge Technologies, technical report, 2026
2026
-
[15]
Radford et al
A. Radford et al. Language Models are Unsupervised Multitask Learners. OpenAI, 2019
2019
-
[16]
G. Penedo et al. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. arXiv:2406.17557, 2024
Pith/arXiv arXiv 2024
-
[17]
Loshchilov, F
I. Loshchilov, F. Hutter. Decoupled Weight Decay Regularization.ICLR, 2019
2019
-
[18]
Ansel et al
A. Ansel et al. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transfor- mation and Graph Compilation.ASPLOS, 2024
2024
-
[19]
Abadi et al
M. Abadi et al. TensorFlow: A System for Large-Scale Machine Learning.OSDI, 2016
2016
-
[20]
TorchDynamo
PyTorch Team. TorchDynamo. https://docs.pytorch.org/docs/2.12/user_guide/torch_ compiler/torch.compiler_dynamo_overview.html, 2022
2022
-
[21]
A. Sergeev, M. Del Balso. Horovod: Fast and Easy Distributed Deep Learning in TensorFlow. arXiv:1802.05799, 2018
Pith/arXiv arXiv 2018
-
[22]
Rajbhandari et al
S. Rajbhandari et al. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.SC, 2020
2020
-
[23]
Ren et al
J. Ren et al. ZeRO-Offload: Democratizing Billion-Scale Model Training.USENIX ATC, 2021
2021
-
[24]
Rajbhandari et al
S. Rajbhandari et al. ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning.SC, 2021
2021
-
[25]
Rasley et al
J. Rasley et al. DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters.KDD, 2020
2020
-
[26]
Shazeer et al
N. Shazeer et al. Mesh-TensorFlow: Deep Learning for Supercomputers.NeurIPS, 2018
2018
-
[27]
S. Jacobs et al. DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models. arXiv:2309.14509, 2023
Pith/arXiv arXiv 2023
-
[28]
Tillet et al
P. Tillet et al. Triton: An Intermediate Language and Compiler for Tiled Neural Network Computa- tions.MAPL, 2019
2019
-
[29]
P. Tillet. Introducing Triton: Open-Source GPU Programming for Neural Networks.OpenAI Blog, 2021
2021
-
[30]
Chen et al
T. Chen et al. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.OSDI, 2018
2018
-
[31]
Leary et al
C. Leary et al. XLA: TensorFlow, Compiled.TensorFlow Dev Summit, 2017
2017
-
[32]
T. Chen et al. Training Deep Nets with Sublinear Memory Cost. arXiv:1604.06174, 2016. 20
Pith/arXiv arXiv 2016
-
[33]
Peng et al
X. Peng et al. Capuchin: Tensor-based GPU Memory Management for Deep Learning.ASPLOS, 2020
2020
-
[34]
CUTLASS: Fast Linear Algebra in CUDA C++.https://github.com/NVIDIA/cutlass
NVIDIA. CUTLASS: Fast Linear Algebra in CUDA C++.https://github.com/NVIDIA/cutlass
-
[35]
M. Milakov, N. Gimelshein. Online Normalizer Calculation for Softmax. arXiv:1805.02867, 2018
Pith/arXiv arXiv 2018
-
[36]
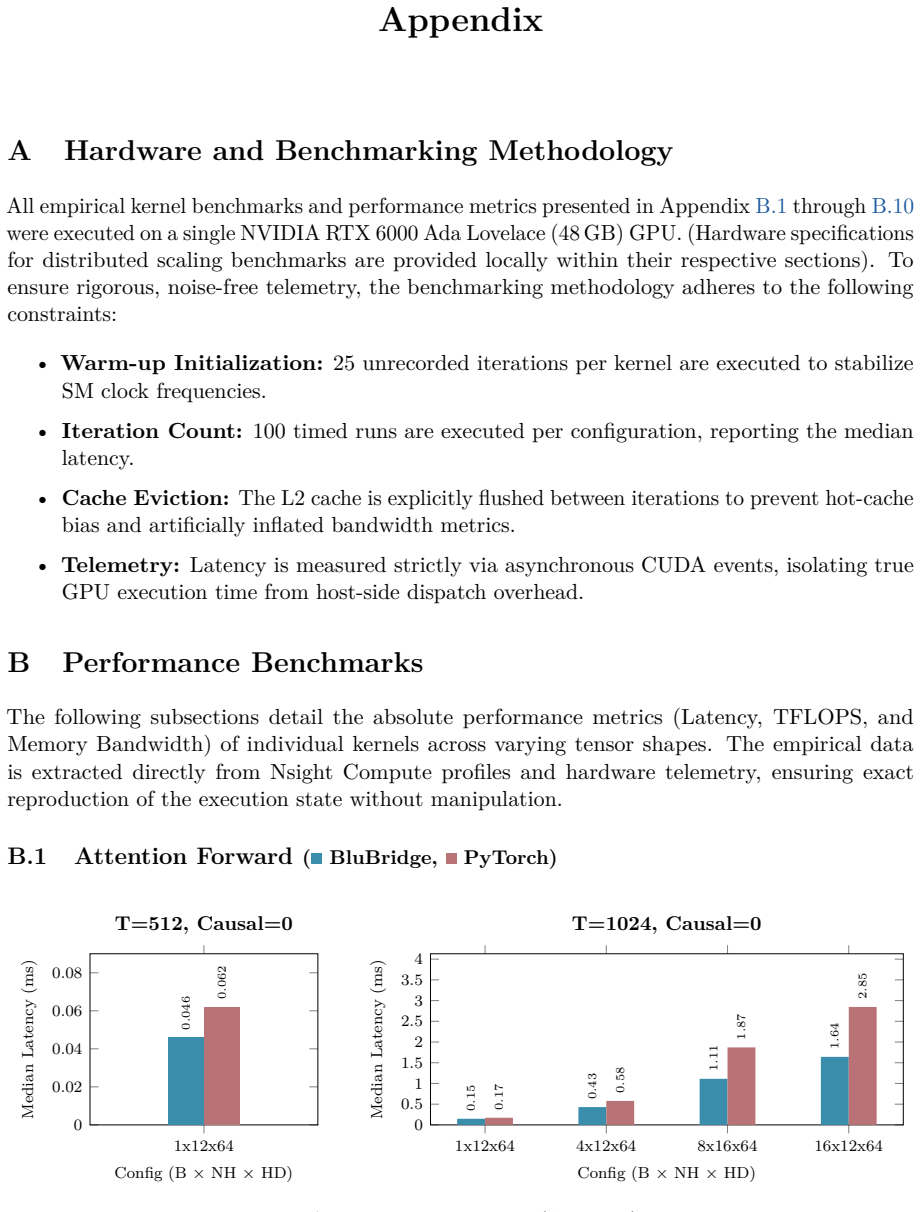
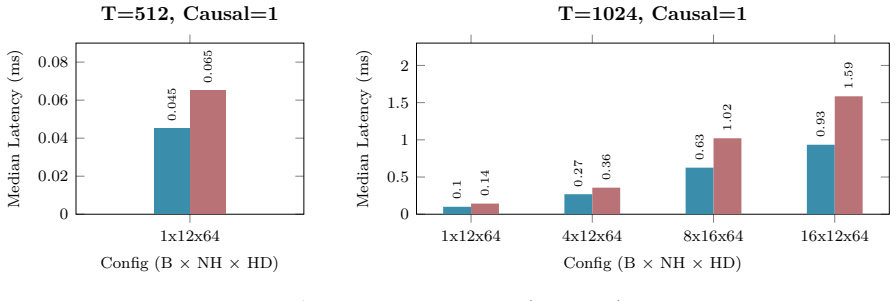
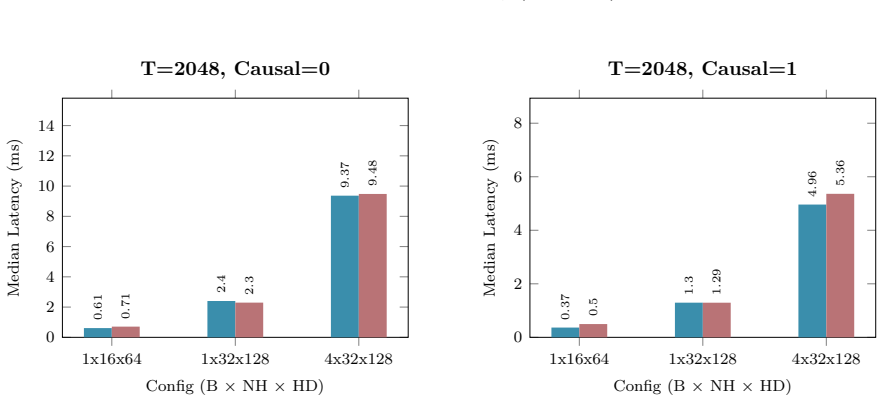
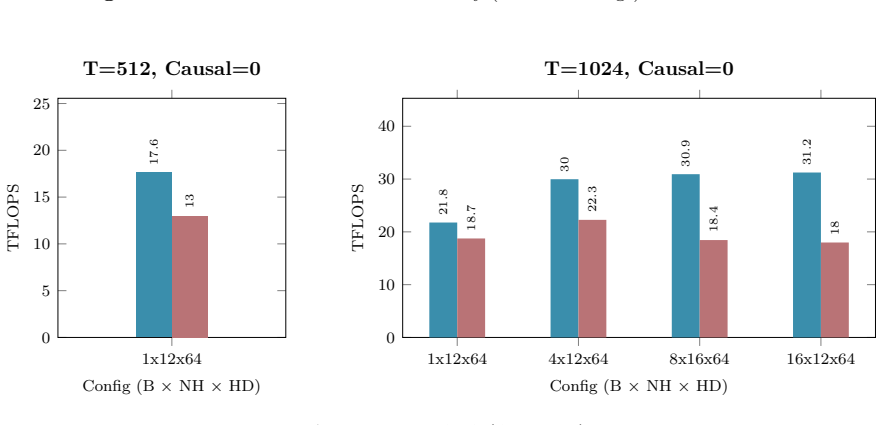
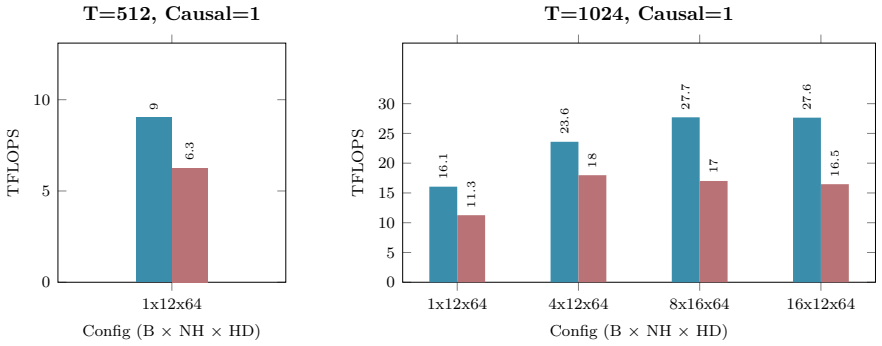
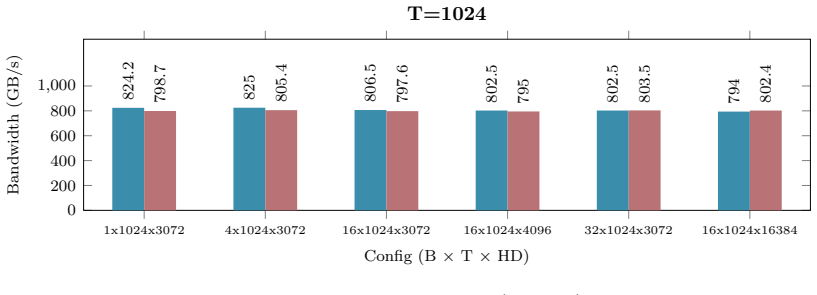
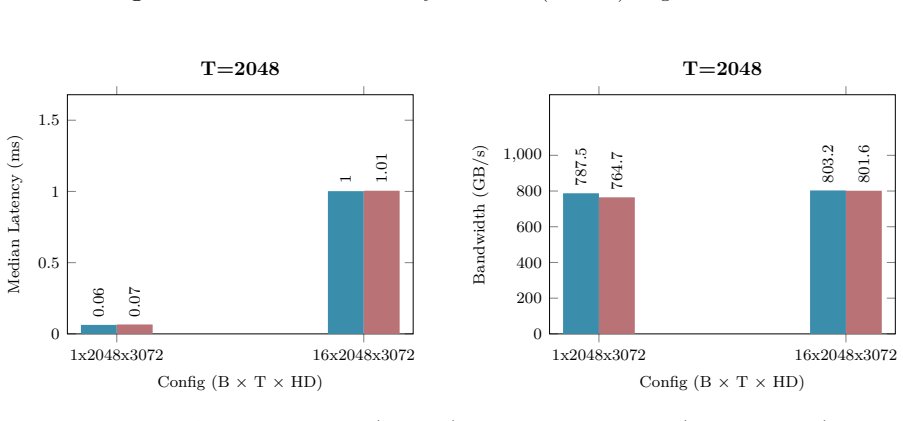
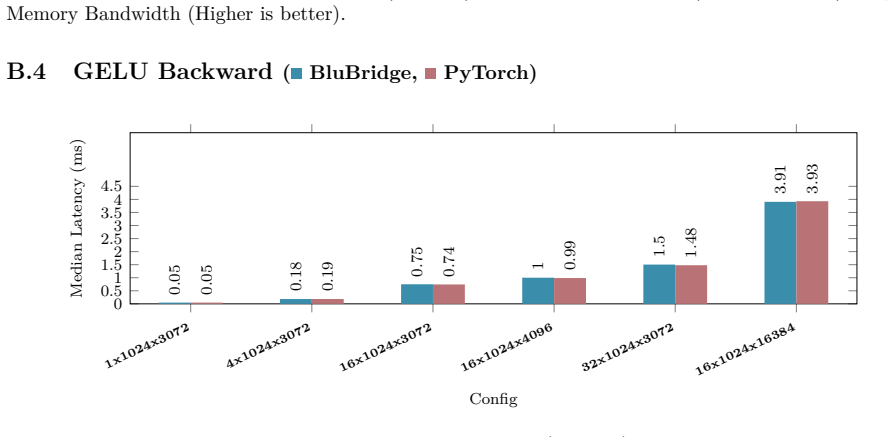
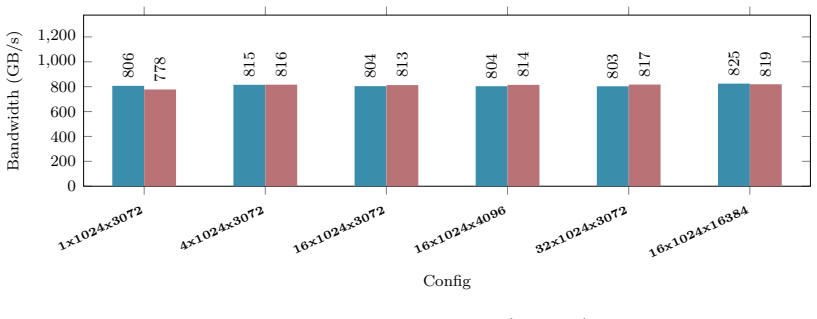
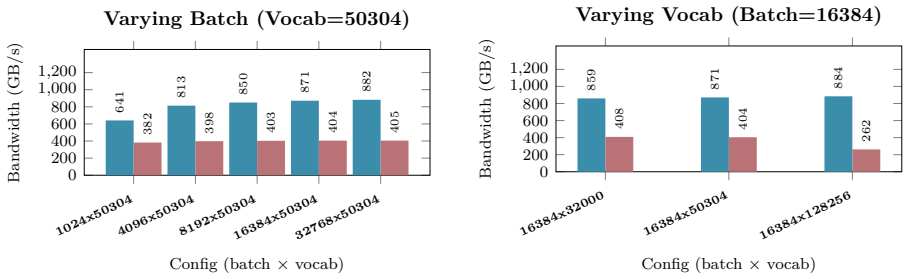
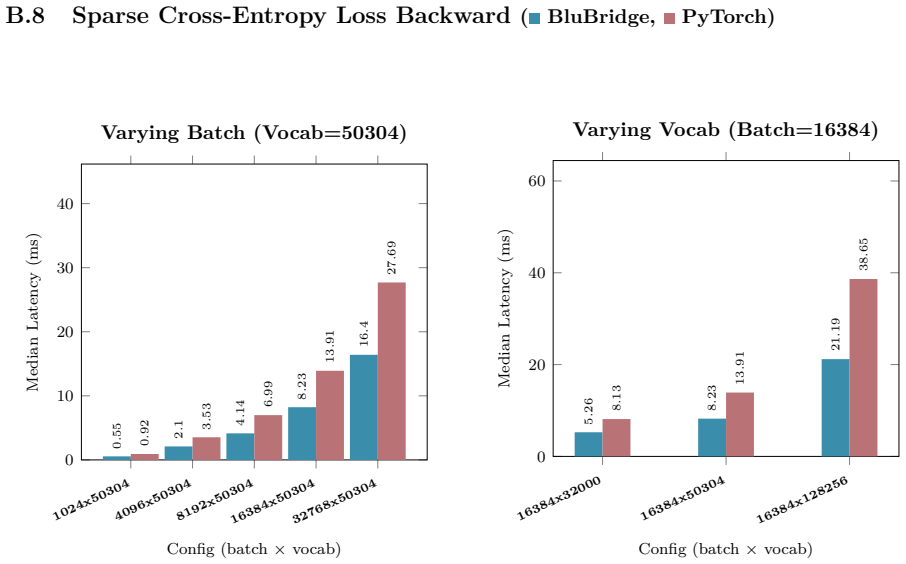
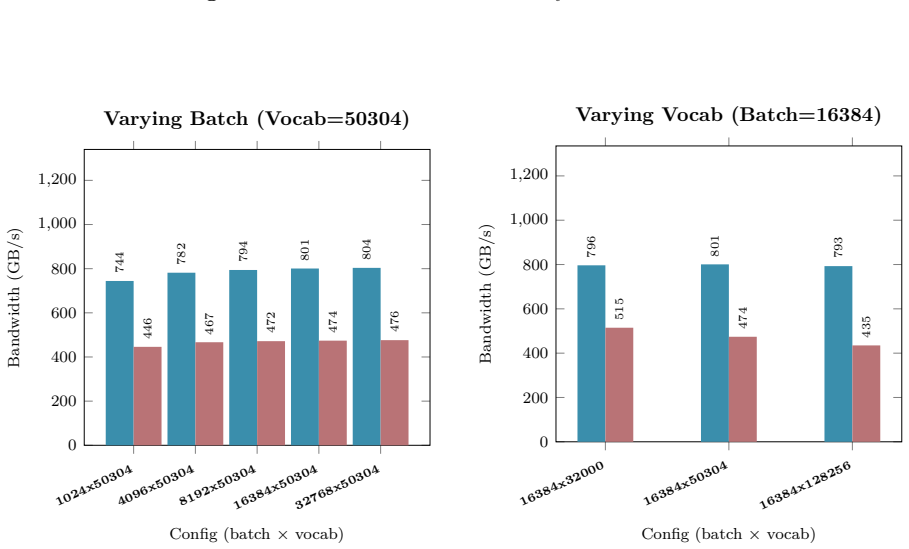
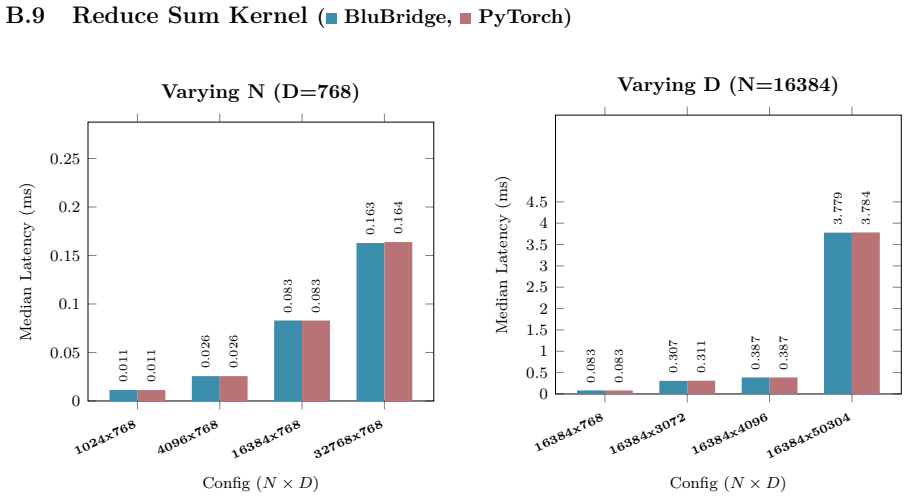
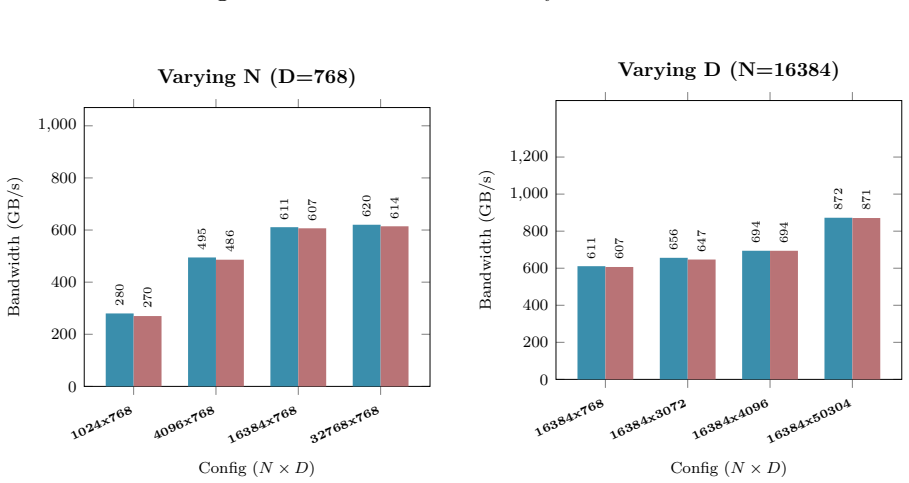
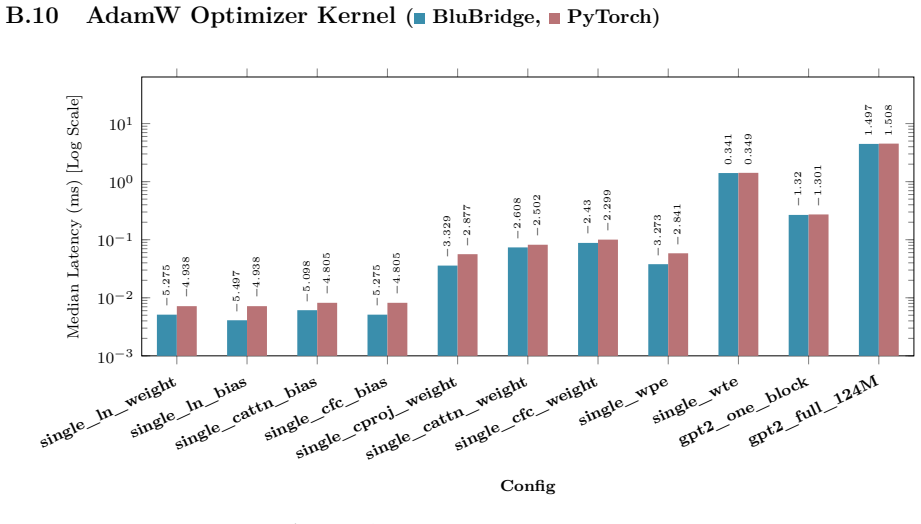
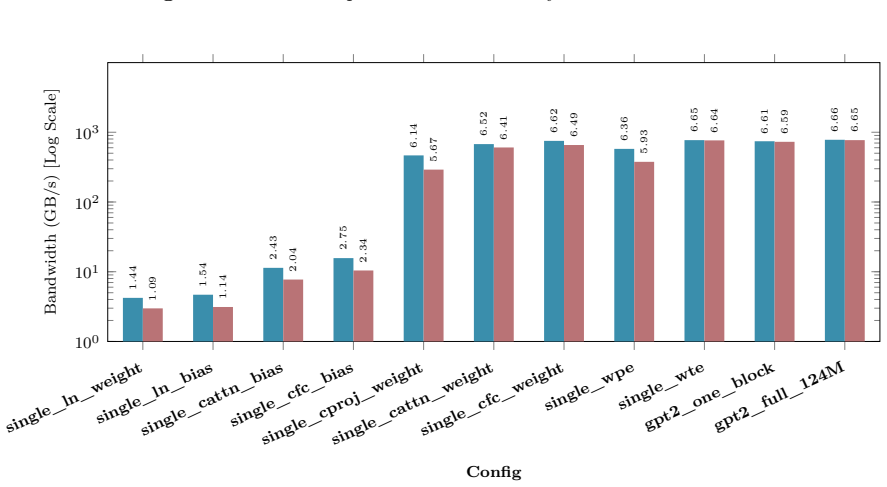
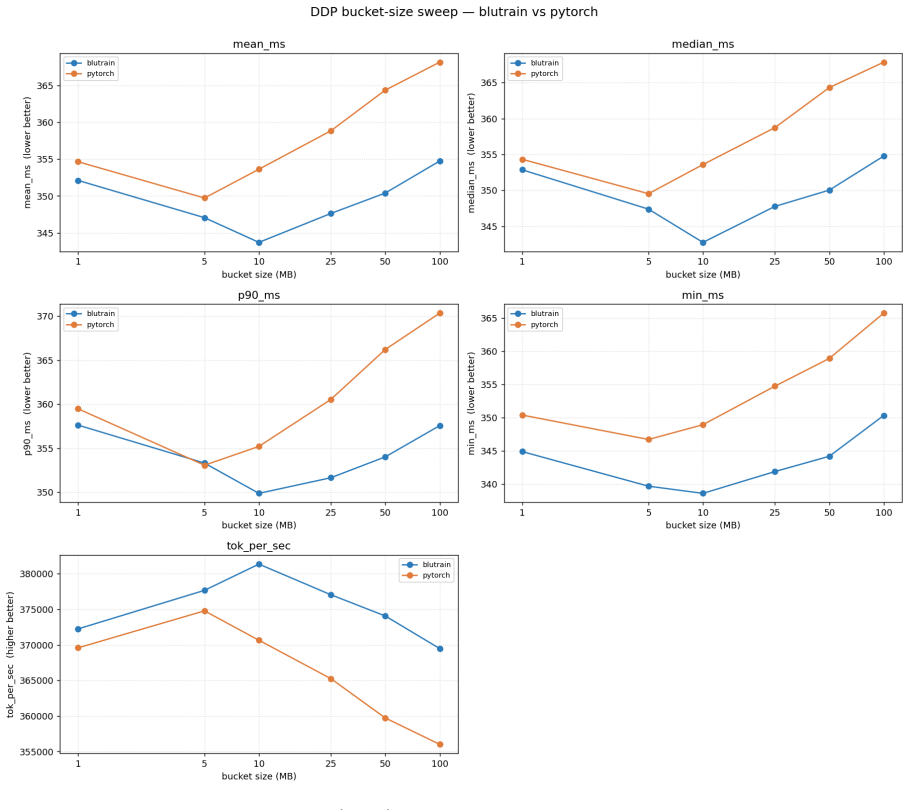
B. P. Welford. Note on a Method for Calculating Corrected Sums of Squares and Products.Techno- metrics, 4(3):419–420, 1962. doi:10.1080/00401706.1962.10490022. 21 Appendix A Hardware and Benchmarking Methodology All empirical kernel benchmarks and performance metrics presented in Appendix B.1 through B.10 wereexecutedonasingleNVIDIARTX6000AdaLovelace(48GB...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.