Cross-View Yaw Estimation in Location Uncertainty with Line-Aligning Yaw Scoring
Pith reviewed 2026-06-26 12:27 UTC · model grok-4.3
The pith
A radially invariant line-consensus voting method estimates yaw to sub-degree precision without requiring accurate location.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
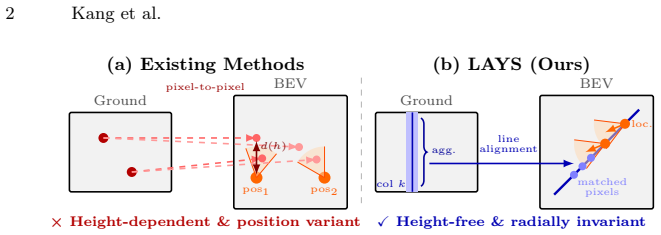
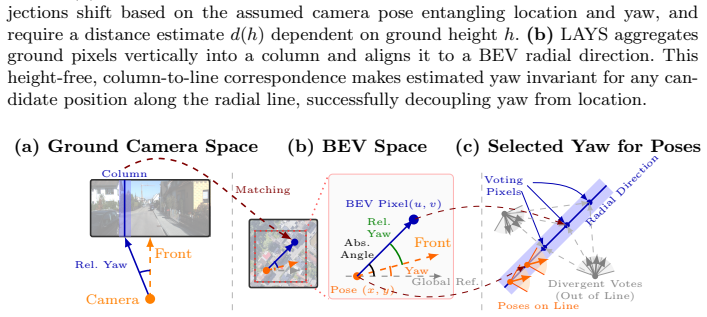
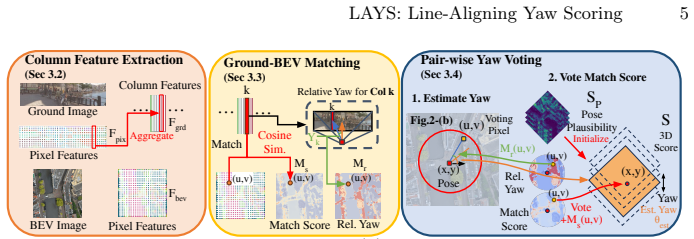
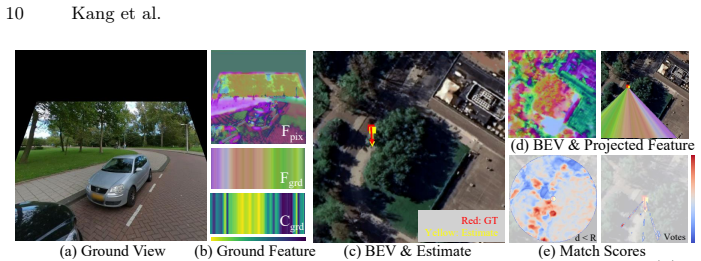
LAYS is a radially invariant line-consensus voting method. It matches BEV pixels to ground-image columns using feature similarity. Each such match induces a yaw value that remains constant across all camera positions along the radial direction of the pixels. These induced yaws are accumulated into discrete 3D bins; correct correspondences concentrate into a sharp peak that identifies the true yaw to sub-degree precision, removing any dependence on accurate location.
What carries the argument
LAYS, the 3D voting scheme that accumulates yaw values induced by feature matches between ground columns and BEV pixels, using their radial invariance to concentrate correct votes into a peak.
If this is right
- Sub-degree yaw precision is reached by 3D voting over all candidate poses.
- Gains of 28 to 45 percentage points occur under unknown yaw, especially with normal field of view.
- Using the estimated yaw as a prior measurably improves downstream 3-DoF localization.
- The method succeeds on Mapillary, Ford, KITTI, and VIGOR without location accuracy.
- Yaw can be recovered independently of translation estimates.
Where Pith is reading between the lines
- The radial-invariance voting could be paired with separate translation solvers to produce initial 3-DoF pose estimates from scratch.
- Similar line-consensus ideas might apply to other single-degree-of-freedom ambiguities in visual localization.
- Performance under seasonal or lighting changes would test whether feature similarity remains sufficient.
- The discrete 3D binning could be extended to joint yaw-and-pitch estimation if radial invariance holds in additional axes.
Load-bearing premise
A ground-image column matched to BEV pixels produces the same yaw for every camera position along the radial line of those pixels, and feature similarity can reliably locate such matches under location uncertainty.
What would settle it
An experiment on ground-BEV image pairs in which radial invariance is violated or feature matches produce no concentrated peak at the ground-truth yaw would falsify the claim of reliable sub-degree estimation.
Figures

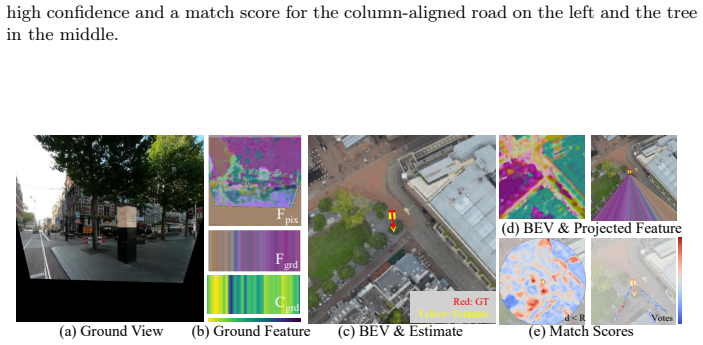
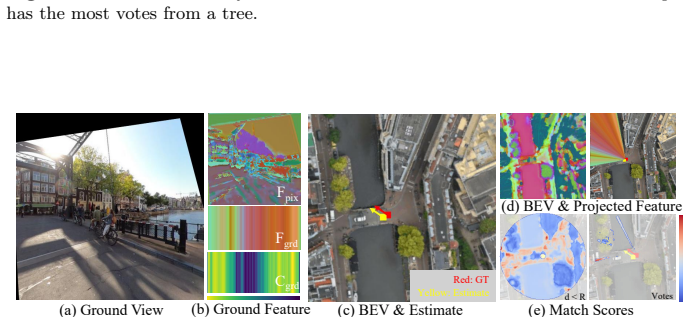
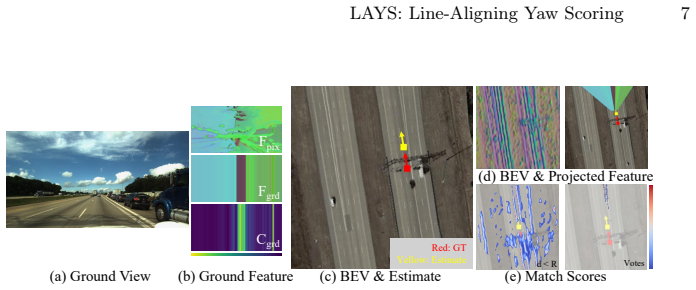

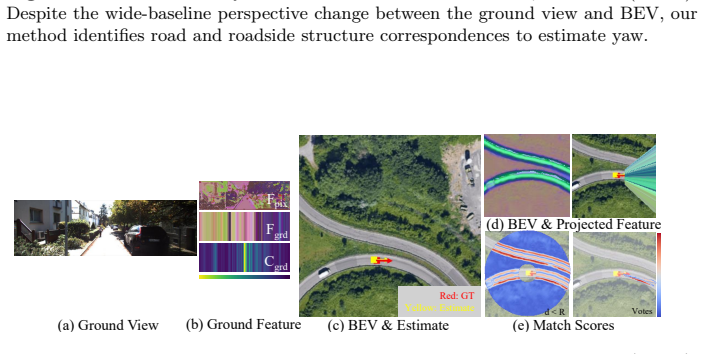
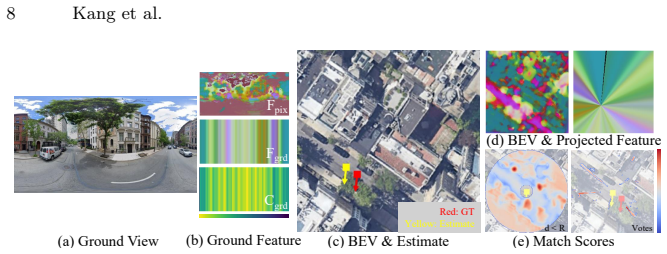
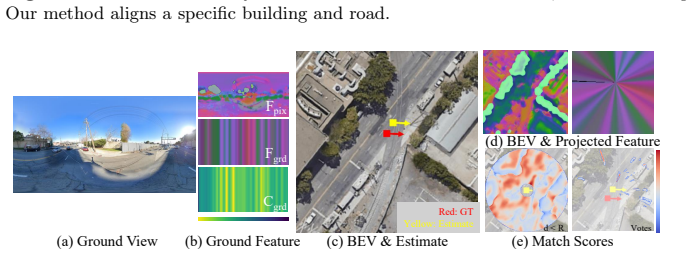
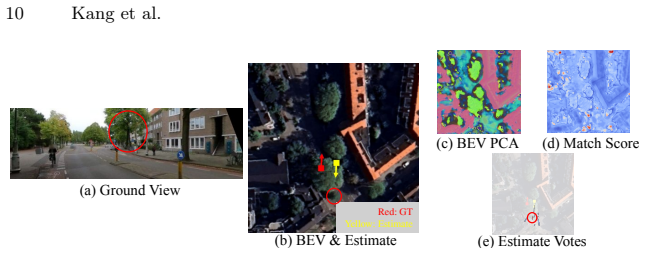


read the original abstract
Accurate yaw estimation is a bottleneck in cross-view localization between ground view and Bird's Eye View (BEV). Existing methods couple yaw with translation and rely on height or projection assumptions that degrade under large yaw ambiguity. We disentangle yaw from location accuracy and introduce LAYS, a radially invariant line-consensus voting method. By exploiting the radial invariance of our formulation, we achieve sub-degree yaw precision via 3D voting over all candidate poses, while eliminating the need for accurate location. Our key observation is that a ground-image column matched to BEV pixels induces the same yaw across all camera positions along the radial direction of the pixels. LAYS matches BEV pixels to ground columns using feature similarity and accumulates the induced yaw votes into discrete 3D bins, where correct correspondences along the radial line concentrate into a sharp peak for the correct yaw. Experiments on Mapillary, Ford, KITTI, and VIGOR show significant gains under unknown yaw, particularly for normal FoV with unknown yaw (+28$\sim$45\%p), and using LAYS as a yaw prior improves downstream 3-DoF localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LAYS, a radially invariant line-consensus voting method for estimating yaw in cross-view ground-to-BEV localization. It claims that matching ground-image columns to BEV pixels via feature similarity allows accumulation of yaw votes into 3D bins, where correct radial correspondences produce a sharp peak for the true yaw, achieving sub-degree precision without accurate location knowledge. Experiments on Mapillary, Ford, KITTI, and VIGOR datasets report significant gains (e.g., +28–45% points for normal FoV with unknown yaw) and improved downstream 3-DoF localization when used as a prior.
Significance. If the radial-invariance property and reliable feature matching under location uncertainty hold, the method would address a key bottleneck by decoupling yaw from translation, offering a parameter-free voting approach that could improve robustness in cross-view tasks. The multi-dataset gains and downstream utility suggest practical value, though the lack of detailed validation of the core assumption limits current assessment of impact.
major comments (3)
- [Abstract] Abstract: The central claim of sub-degree yaw precision via 3D voting relies on the radial invariance observation and sufficient correct correspondences under location uncertainty, yet the text provides no quantification of surviving correct radial matches, no error analysis, and no ablation studies on descriptor sensitivity or discretization effects, preventing verification of whether the accumulator forms the claimed sharp peak.
- [Abstract] The key geometric observation (a ground column matched to BEV pixels induces identical yaw for all positions along the radial line) is presented without formal derivation, proof of invariance under real-world conditions (e.g., non-fronto-parallel surfaces or viewpoint changes), or empirical validation on the tested datasets with explicit location uncertainty regimes.
- [Abstract] No implementation details, pseudocode, or parameter settings for the feature matching, 3D binning, or voting procedure are supplied, making it impossible to assess reproducibility or the exact conditions under which the reported gains materialize.
minor comments (1)
- [Abstract] The abstract mentions 'normal FoV' but does not define the field-of-view ranges or camera parameters used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to improve clarity and verifiability of the core claims.
read point-by-point responses
-
Referee: [Abstract] The central claim of sub-degree yaw precision via 3D voting relies on the radial invariance observation and sufficient correct correspondences under location uncertainty, yet the text provides no quantification of surviving correct radial matches, no error analysis, and no ablation studies on descriptor sensitivity or discretization effects, preventing verification of whether the accumulator forms the claimed sharp peak.
Authors: We agree that the abstract and current presentation lack explicit quantification of surviving correct radial matches, error analysis, and ablations on descriptor sensitivity or discretization. While the experimental results on four datasets demonstrate the claimed precision, additional supporting analysis is warranted. We will add a dedicated subsection with quantification of correct correspondences under controlled location uncertainty, sensitivity analysis, and discretization ablations to verify peak formation. revision: yes
-
Referee: [Abstract] The key geometric observation (a ground column matched to BEV pixels induces identical yaw for all positions along the radial line) is presented without formal derivation, proof of invariance under real-world conditions (e.g., non-fronto-parallel surfaces or viewpoint changes), or empirical validation on the tested datasets with explicit location uncertainty regimes.
Authors: The observation follows directly from the projective geometry of the ground-to-BEV mapping, where matched columns induce constant yaw along radial lines in the BEV plane. We will include a formal derivation in the methods section, discuss invariance assumptions (including limitations under non-fronto-parallel surfaces), and add empirical validation plots showing yaw consistency across location uncertainty regimes on the evaluated datasets. revision: yes
-
Referee: [Abstract] No implementation details, pseudocode, or parameter settings for the feature matching, 3D binning, or voting procedure are supplied, making it impossible to assess reproducibility or the exact conditions under which the reported gains materialize.
Authors: We acknowledge the absence of these details in the current manuscript. We will add a dedicated implementation subsection with pseudocode for the voting procedure, exact parameter values (e.g., bin sizes, matching thresholds), and feature descriptor settings to ensure full reproducibility. revision: yes
Circularity Check
No circularity detected; derivation is self-contained geometric voting
full rationale
The paper introduces LAYS as a line-consensus voting procedure grounded in an explicit geometric observation: a ground-image column matched to BEV pixels induces identical yaw for all camera positions along the radial line. This property is stated directly as the basis for matching via feature similarity and accumulating votes in 3D bins to form a peak at the correct yaw. No equations reduce a claimed prediction to a fitted parameter by construction, no self-citations serve as load-bearing uniqueness theorems, and no ansatz is smuggled in. The method is presented as a direct application of the radial invariance without tautological redefinition or renaming of known results, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Feature similarity between BEV pixels and ground-image columns can be used to identify reliable correspondences
- standard math Standard projective geometry and radial line properties hold for the camera models used
Reference graph
Works this paper leans on
-
[1]
In: 2009 IEEE 12th International Conference on Computer Vision
Agarwal, S., Snavely, N., Simon, I., Seitz, S.M., Szeliski, R.: Building rome in a day. In: 2009 IEEE 12th International Conference on Computer Vision. pp. 72–79 (2009).https://doi.org/10.1109/ICCV.2009.5459148
-
[2]
Agarwal, S., Vora, A., Pandey, G., Williams, W., Kourous, H., McBride, J.: Ford multi-av seasonal dataset (2020)
2020
-
[3]
Brejcha, J., Čadík, M.: State-of-the-art in visual geo-localization. Pattern Anal. Appl.20(3), 613–637 (Aug 2017).https://doi.org/10.1007/s10044-017-0611- 1,https://doi.org/10.1007/s10044-017-0611-1
-
[4]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Delattre, F., Dirnfeld, D., Nguyen, P., Scarano, S., Jones, M.J., Miraldo, P., Learned-Miller, E.: Robust frame-to-frame camera rotation estimation in crowded scenes. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9752–9762 (10 2023)
2023
-
[5]
Sensors24(7) (2024).https://doi.org/10.3390/ s24072246,https://www.mdpi.com/1424-8220/24/7/2246
Du, Y., Mateo, C., Tahri, O.: A multilayer perceptron-based spherical visual com- pass using global features. Sensors24(7) (2024).https://doi.org/10.3390/ s24072246,https://www.mdpi.com/1424-8220/24/7/2246
2024
-
[6]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Fervers, F., Bullinger, S., Bodensteiner, C., Arens, M., Stiefelhagen, R.: Uncertainty-aware vision-based metric cross-view geolocalization. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21621–21631 (June 2023)
2023
-
[7]
International Journal of Robotics Research (IJRR) (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR) (2013)
2013
-
[8]
IEEE Transactions on Image Processing31, 2094–2105 (2022).https://doi.org/10.1109/TIP.2022.3152046
Guo, Y., Choi, M., Li, K., Boussaid, F., Bennamoun, M.: Soft exemplar high- lighting for cross-view image-based geo-localization. IEEE Transactions on Image Processing31, 2094–2105 (2022).https://doi.org/10.1109/TIP.2022.3152046
-
[9]
In: Proceedings of the IEEE Conf
Hays, J., Efros, A.A.: im2gps: estimating geographic information from a single image. In: Proceedings of the IEEE Conf. on Computer Vision and Pattern Recog- nition (CVPR) (2008)
2008
-
[10]
In: CVPR (2023)
Jin, L., Zhang, J., Hold-Geoffroy, Y., Wang, O., Matzen, K., Sticha, M., Fouhey, D.F.: Perspective fields for single image camera calibration. In: CVPR (2023)
2023
-
[11]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
Lentsch, T., Xia, Z., Caesar, H., Kooij, J.F.P.: Slicematch: Geometry-guided ag- gregation for cross-view pose estimation. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 17225–17234 (June 2023)
2023
-
[12]
In: European Conf
Li, Y., Snavely, N., Huttenlocher, D., Fua, P.: Worldwide pose estimation using 3D point clouds. In: European Conf. on Computer Vision (2012)
2012
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, L., Li, H.: Lending orientation to neural networks for cross-view geo- localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5617–5626 (2019)
2019
-
[14]
In: 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR)
Liu, S., Deng, W.: Very deep convolutional neural network based image classifi- cation using small training sample size. In: 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR). pp. 730–734 (2015).https://doi.org/10.1109/ ACPR.2015.7486599
arXiv 2015
-
[15]
Remote Sensing14(6), 1430 (2022)
Liu, Y., Tao, J., Kong, D., Zhang, Y., Li, P.: A visual compass based on point and line features for uav high-altitude orientation estimation. Remote Sensing14(6), 1430 (2022)
2022
-
[16]
In: International Conferenceon LearningRepresentations(2019),https://openreview.net/forum? id=Bkg6RiCqY7 16 Kang et al
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conferenceon LearningRepresentations(2019),https://openreview.net/forum? id=Bkg6RiCqY7 16 Kang et al
2019
-
[17]
In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T
Middelberg, S., Sattler, T., Untzelmann, O., Kobbelt, L.: Scalable 6-dof localiza- tion on mobile devices. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision – ECCV 2014. pp. 268–283. Springer International Publishing, Cham (2014)
2014
-
[18]
Advances in Neural Information Processing Sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in Neural Information Processing Sys- tems32(2019)
2019
-
[19]
Rajpurohit, A., Kumar, P., Singh, D., Kumar, R.: A review on visual positioning system. SSRN Electronic Journal (01 2024).https://doi.org/10.2139/ssrn. 4485458
-
[20]
CoRRabs/1505.04597(2015),http://dblp.uni- trier.de/db/journals/corr/corr1505.html#RonnebergerFB15
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. CoRRabs/1505.04597(2015),http://dblp.uni- trier.de/db/journals/corr/corr1505.html#RonnebergerFB15
Pith/arXiv arXiv 2015
-
[21]
In: CVPR (2023)
Sarlin, P.E., DeTone, D., Yang, T.Y., Avetisyan, A., Straub, J., Malisiewicz, T., Bulo, S.R., Newcombe, R., Kontschieder, P., Balntas, V.: OrienterNet: Visual Lo- calization in 2D Public Maps with Neural Matching. In: CVPR (2023)
2023
-
[22]
In: NeurIPS (2023)
Sarlin, P.E., Trulls, E., Pollefeys, M., Hosang, J., Lynen, S.: SNAP: Self-Supervised Neural Maps for Visual Positioning and Semantic Understanding. In: NeurIPS (2023)
2023
-
[23]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2022)
Shi, Y., Li, H.: Beyond cross-view image retrieval: Highly accurate vehicle localiza- tion using satellite image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[24]
Shi, Y., Li, H., Perincherry, A., Vora, A.: Weakly-supervised camera localization by ground-to-satellite image registration. In: Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part IX. p. 39–57. Springer-Verlag, Berlin, Heidelberg (2024).https://doi.org/ 10.1007/978-3-031-72673-6_3,https://d...
-
[25]
In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alch’e-Buc, F., Fox, E., Garnett, R
Shi, Y., Liu, L., Yu, X., Li, H.: Spatial-aware feature aggregation for image based cross-view geo-localization. In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alch’e-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Informa- tion Processing Systems 32, pp. 10090–10100. Curran Associates, Inc. (2019), http://papers.nips.cc/paper/9199- spatial- ...
2019
-
[26]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Shi, Y., Wu, F., Perincherry, A., Vora, A., Li, H.: Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 21459– 21469 (2023).https://doi.org/10.1109/ICCV51070.2023.01967
-
[27]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Shi, Y., Yu, X., Campbell, D., Li, H.: Where am i looking at? joint location and orientation estimation by cross-view matching. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4063–4071 (2020).https: //doi.org/10.1109/CVPR42600.2020.00412
-
[28]
In: arXiv preprint arXiv:1907.05021 (2019)
Shi, Y., Yu, X., Liu, L., Zhang, T., Li, H.: Optimal feature transport for cross-view image geo-localization. In: arXiv preprint arXiv:1907.05021 (2019)
arXiv 1907
-
[29]
In: Proceedings of the Asian Conference on Computer Vision (ACCV)
Shi, Y., Yu, X., Wang, S., Li, H.: Cvlnet: Cross-view feature correspondence learn- ing for video-based camera localization. In: Proceedings of the Asian Conference on Computer Vision (ACCV). pp. 652–669 (December 2022)
2022
-
[30]
In: Oh, A., Naumann, T., Glober- LAYS: Line-Aligning Yaw Scoring 17 son, A., Saenko, K., Hardt, M., Levine, S
Song, Z., xianghui, z., Lu, J., Shi, Y.: Learning dense flow field for highly- accurate cross-view camera localization. In: Oh, A., Naumann, T., Glober- LAYS: Line-Aligning Yaw Scoring 17 son, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Infor- mation Processing Systems. vol. 36, pp. 70612–70625. Curran Associates, Inc. (2023),https : /...
2023
-
[31]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, S., Nguyen, C., Liu, J., Zhang, Y., Muthu, S., Maken, F.A., Zhang, K., Li, H.: View from above: Orthogonal-view aware cross-view localization. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14843–14852 (June 2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Wang, S., Zhang, Y., Perincherry, A., Vora, A., Li, H.: View consistent purification for accurate cross-view localization. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 8197–8206 (2023)
2023
-
[33]
In: Oh, A., Nau- mann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Wang, X., Xu, R., Cui, Z., Wan, Z., Zhang, Y.: Fine-grained cross-view geo- localization using a correlation-aware homography estimator. In: Oh, A., Nau- mann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 5301–5319. Curran Associates, Inc. (2023),https://proceedings.neurips.cc/...
2023
-
[34]
ArXivabs/1602.05314(2016),https : / / api
Weyand, T., Kostrikov, I., Philbin, J.: Planet - photo geolocation with con- volutional neural networks. ArXivabs/1602.05314(2016),https : / / api . semanticscholar.org/CorpusID:171846
Pith/arXiv arXiv 2016
-
[35]
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2024)
Wu, H., Zhang, Z., Lin, S., Mu, X., Zhao, Q., Yang, M., Qin, T.: Maplocnet: Coarse-to-fine feature registration for visual re-localization in navigation maps. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2024)
2024
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Xia, Z., Alahi, A.: Fg^2: Fine-grained cross-view localization by fine-grained fea- ture matching. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 6362–6372 (June 2025)
2025
-
[37]
Xia, Z., Booij, O., Kooij, J.F.P.: Convolutional cross-view pose estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence46(5), 3813–3831 (2024).https://doi.org/10.1109/TPAMI.2023.3346924
-
[38]
In: European Conference on Computer Vision
Xia, Z., Booij, O., Manfredi, M., Kooij, J.F.: Visual cross-view metric localization with dense uncertainty estimates. In: European Conference on Computer Vision. pp. 90–106. Springer (2022)
2022
-
[39]
2019 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Xian, W., Li, Z., Fisher, M., Eisenmann, J., Shechtman, E., Snavely, N.: Up- rightnet: Geometry-aware camera orientation estimation from single images. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 9973–9982 (2019),https://api.semanticscholar.org/CorpusID:201107189
2019
-
[40]
Xu, B., Wang, N., Chen, T., Li, M.: Empirical evaluation of rectified activations in convolutional network (2015),https://arxiv.org/abs/1505.00853
Pith/arXiv arXiv 2015
-
[41]
Yang, A., Beheshti, M., Hudson, T.E., Vedanthan, R., Riewpaiboon, W., Mongkol- wat, P., Feng, C., Rizzo, J.R.: Unav: An infrastructure-independent vision-based navigation system for people with blindness and low vision. Sensors22(22) (2022). https://doi.org/10.3390/s22228894,https://www.mdpi.com/1424-8220/22/ 22/8894
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, S., Shah, M., Chen, C.: Transgeo: Transformer is all you need for cross-view image geo-localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1162–1171 (2022)
2022
-
[43]
FG2 (Two-stage)
Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one- to-one retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3640–3649 (2021) LAYS: Line-Aligning Yaw Scoring 1 Appendix In this appendix, we provide the following: –Proof of Proposition 1 (Sec. A) –Training setup (Sec. B) –Pse...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.