UniRank: Unified Rank Allocation for Low-Rank LLM Compression
Pith reviewed 2026-06-26 12:32 UTC · model grok-4.3
The pith
UniRank scores singular components by local energy ratio and global input-output cosine similarity to allocate ranks in LLM low-rank compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
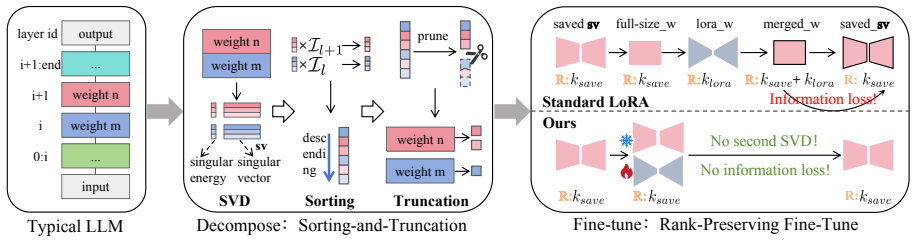
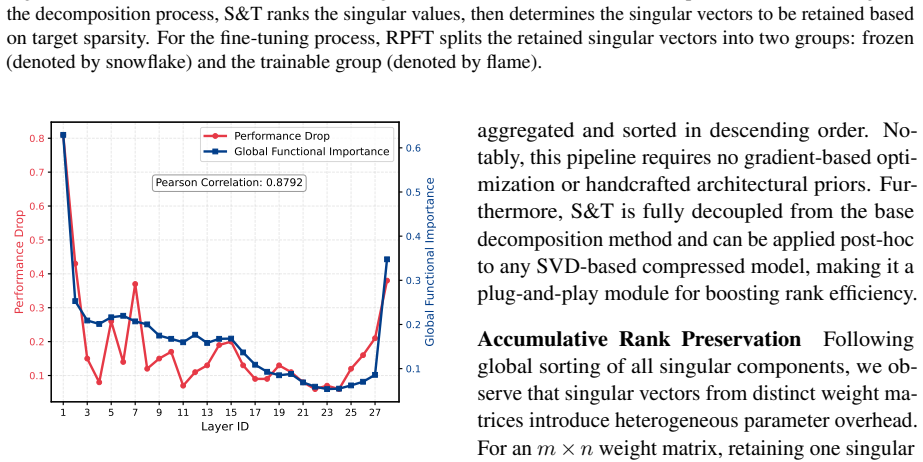
We formulate global low-rank allocation as a sorting-and-truncation pipeline, and score each singular component via dual criteria: Local singular energy ratio that quantifies the intrinsic importance within the decomposed parameter matrix and Global functional importance (measured by input-output cosine similarity) that evaluates the functional significance of decomposed modules. We verify the strong correlation between high input-output cosine similarity and low effective rank through geometric interpretation and experimental validation. Furthermore, we propose rank-preserving fine-tuning, which performs direct LoRA tuning on decomposed weights and avoids extra information loss caused by re
What carries the argument
Dual-criteria scoring inside a sorting-and-truncation pipeline that combines local singular energy ratio with global input-output cosine similarity to decide which singular components to retain.
If this is right
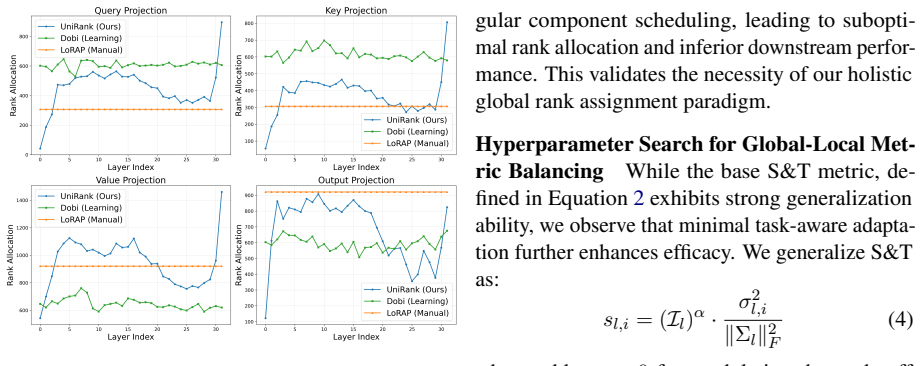
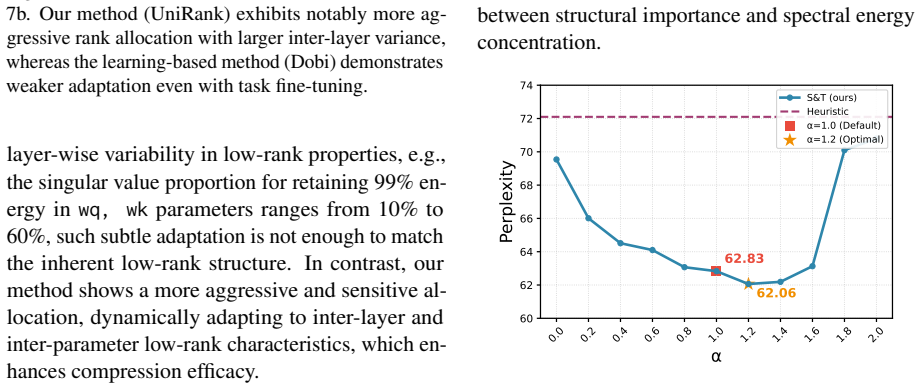
- One-shot compression without fine-tuning reduces perplexity by up to 50 percent relative to uniform and heuristic baselines.
- Performance gains hold across models that use distinct decomposition schemes, sizes, and architectural designs.
- Rank-preserving fine-tuning avoids the extra information loss that occurs when conventional pipelines merge and then re-truncate weights.
Where Pith is reading between the lines
- If the correlation between cosine similarity and effective rank generalizes, the same scoring could be applied to other matrix-factorization compression methods beyond low-rank decomposition.
- The approach might reduce the compute needed to compress new model families by replacing per-model hyperparameter search with the fixed dual-criteria sort.
- Direct application of the allocation rule to already-trained models could become a standard preprocessing step before deployment on edge hardware.
Load-bearing premise
Input-output cosine similarity serves as a reliable proxy for the functional importance of decomposed modules and that this proxy correlates with low effective rank across models and decomposition schemes.
What would settle it
An experiment in which the proposed rank allocation produces equal or higher perplexity than uniform allocation on the same decomposed model in a strict one-shot setting with no fine-tuning.
Figures

read the original abstract
Low-rank decomposition serves as a promising compression paradigm for large language models, however, rank allocation remains challenging: manual rules lack generalizability, and learning-based approaches incur heavy computational overhead. To address these issues, we formulate global low-rank allocation as a sorting-and-truncation pipeline, and score each singular component via dual criteria: \textbf{Local} singular energy ratio that quantifies the intrinsic importance within the decomposed parameter matrix and \textbf{Global} functional importance (measured by input-output cosine similarity) that evaluates the functional significance of decomposed modules. We verify the strong correlation between high input-output cosine similarity and low effective rank through geometric interpretation and experimental validation. Furthermore, we propose rank-preserving fine-tuning, which performs direct LoRA tuning on decomposed weights and avoids extra information loss caused by re-truncation in conventional merging pipelines. Empirical results confirm that our method delivers sustained performance enhancements when combined with models featuring distinct decomposition schemes, model sizes and architectural designs, e.g. in one-shot compression without further fine-tuning, our method reduces perplexity by up to 50\% compared with uniform and heuristic allocation baselines. Code will be available at https://github.com/EIT-NLP/LLM-Pruning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents UniRank for rank allocation in low-rank LLM compression. It formulates global allocation as a sorting-and-truncation pipeline and scores each singular component via dual criteria: local singular energy ratio (intrinsic importance within the decomposed matrix) and global functional importance via input-output cosine similarity. The authors verify a strong correlation between high cosine similarity and low effective rank through geometric interpretation and experiments. They further propose rank-preserving fine-tuning that applies LoRA directly on decomposed weights. Empirical results claim up to 50% perplexity reduction in one-shot compression (no further fine-tuning) versus uniform and heuristic baselines, with sustained gains across decomposition schemes, model sizes, and architectures. Public code release is promised.
Significance. If the empirical gains hold, the approach supplies a generalizable, low-overhead alternative to manual rules or learning-based allocation for LLM compression. Use of independently measurable quantities (singular energy, cosine similarity) rather than performance-fitted parameters reduces circularity risk. The public-code commitment is a clear strength for reproducibility. The method could meaningfully improve practical one-shot compression pipelines if the reported correlation and allocation rule generalize as claimed.
major comments (2)
- [§3] §3 (scoring pipeline): the dual-criteria combination rule that produces the final sort key is load-bearing for the superiority claim over baselines, yet the abstract and available description leave the precise aggregation (weighted sum, product, or other) unspecified; an explicit equation or algorithm box is required.
- [§4] §4 / Table 2 (one-shot results): the central 50% perplexity-reduction claim must be supported by the exact numbers, datasets, model variants, baseline definitions, and any error bars or run counts; without these the cross-baseline comparison cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: the phrase 'sustained performance enhancements' when fine-tuning is used should be accompanied by a brief quantitative statement to match the level of detail given for the one-shot case.
- [§2] Notation: ensure 'singular energy ratio' and 'effective rank' receive consistent definitions on first appearance and are not redefined later.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The comments highlight areas where explicitness can be improved, and we address each point below with plans for the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (scoring pipeline): the dual-criteria combination rule that produces the final sort key is load-bearing for the superiority claim over baselines, yet the abstract and available description leave the precise aggregation (weighted sum, product, or other) unspecified; an explicit equation or algorithm box is required.
Authors: We agree that the aggregation rule requires an explicit formulation for clarity. The manuscript describes the dual criteria but does not isolate the combination step in equation form. In the revision we will add a dedicated equation in §3 defining the final sort key (e.g., as a normalized product or weighted sum of the local energy ratio and global cosine similarity) together with an algorithm box that formalizes the full sorting-and-truncation pipeline. revision: yes
-
Referee: [§4] §4 / Table 2 (one-shot results): the central 50% perplexity-reduction claim must be supported by the exact numbers, datasets, model variants, baseline definitions, and any error bars or run counts; without these the cross-baseline comparison cannot be evaluated.
Authors: Table 2 already tabulates the perplexity values that produce the reported reductions, and the text specifies the models, decomposition schemes, and baseline families (uniform and heuristic). To address the request directly we will enlarge the table caption and §4 text to enumerate every dataset, model variant, and baseline definition used. The experiments were performed with single runs per setting owing to compute cost; we will add an explicit statement to this effect rather than retroactively introduce error bars. revision: partial
Circularity Check
No significant circularity; allocation uses independent observables
full rationale
The paper defines its dual scoring rule from two independently measurable quantities: local singular energy ratio extracted directly from the SVD of each weight matrix, and global functional importance via input-output cosine similarity computed on forward passes. These quantities are not defined in terms of the final perplexity or the allocation outcome itself. The central claim consists of empirical one-shot compression results (perplexity reductions versus uniform/heuristic baselines) rather than any derivation that reduces the allocation to a fitted parameter or self-referential equation. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the supplied text; the correlation between cosine similarity and effective rank is presented as experimentally verified rather than assumed by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High input-output cosine similarity correlates with low effective rank of decomposed modules
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Explore what llm does not know in complex question answering , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[2]
arXiv preprint arXiv:2602.23699 , year=
Hidrop: Hierarchical vision token reduction in mllms via late injection, concave pyramid pruning, and early exit , author=. arXiv preprint arXiv:2602.23699 , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
What do visual tokens really encode? uncovering sparsity and redundancy in multimodal large language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
arXiv preprint arXiv:2601.18091 , year=
From LLMs to LRMs: Rethinking Pruning for Reasoning-Centric Models , author=. arXiv preprint arXiv:2601.18091 , year=
-
[5]
arXiv preprint arXiv:2603.14785 , year=
SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation , author=. arXiv preprint arXiv:2603.14785 , year=
-
[6]
arXiv preprint arXiv:2510.13831 , year=
Informed Routing in LLMs: Smarter Token-Level Computation for Faster Inference , author=. arXiv preprint arXiv:2510.13831 , year=
-
[7]
2026 , eprint=
Beyond FLOPs: Benchmarking Real Inference Acceleration of LLM Pruning under a GEMM-Centric Taxonomy , author=. 2026 , eprint=
2026
-
[8]
2019 , eprint=
Root Mean Square Layer Normalization , author=. 2019 , eprint=
2019
-
[9]
2019 , eprint=
How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings , author=. 2019 , eprint=
2019
-
[10]
The Approximation of One Matrix by Another of Lower Rank , volume=. Psychometrika , author=. 1936 , pages=. doi:10.1007/BF02288367 , number=
-
[11]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[12]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[13]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[14]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
ICLR , year=
Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding , author=. ICLR , year=
-
[17]
Proceedings of the British Machine Vision Conference , pages=
Speeding up Convolutional Neural Networks with Low Rank Expansions , author=. Proceedings of the British Machine Vision Conference , pages=. 2014 , organization=
2014
-
[18]
International Conference on Learning Representations , year=
Language model compression with weighted low-rank factorization , author=. International Conference on Learning Representations , year=
-
[19]
International Conference on Machine Learning , year=
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models , author=. International Conference on Machine Learning , year=
-
[20]
Wang Qinsi and Jinghan Ke and Masayoshi Tomizuka and Kurt Keutzer and Chenfeng Xu , booktitle=. Dobi-
-
[21]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[22]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Frantar, Elias and Alistarh, Dan , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[23]
Forty-second International Conference on Machine Learning , year=
Determining Layer-wise Sparsity for Large Language Models Through a Theoretical Perspective , author=. Forty-second International Conference on Machine Learning , year=
-
[24]
Croci and Marcelo Gennari do Nascimento and Torsten Hoefler and James Hensman , booktitle=
Saleh Ashkboos and Maximilian L. Croci and Marcelo Gennari do Nascimento and Torsten Hoefler and James Hensman , booktitle=. Slice
-
[25]
2024 , eprint=
ShortGPT: Layers in Large Language Models are More Redundant Than You Expect , author=. 2024 , eprint=
2024
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence, , year=
Compressing Transformers: Features Are Low-Rank, but Weights Are Not! , author=. Proceedings of the AAAI Conference on Artificial Intelligence, , year=
-
[27]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[28]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Anhao Zhao and Fanghua Ye and Yingqi Fan and Junlong Tong and Jing Xiong and Zhiwei Fei and Hui Su and Xiaoyu Shen , booktitle=. Skip
-
[30]
Advances in neural information processing systems , volume=
Redpajama: an open dataset for training large language models , author=. Advances in neural information processing systems , volume=
-
[31]
Shortened
Bo-Kyeong Kim and Geonmin Kim and Tae-Ho Kim and Thibault Castells and Shinkook Choi and Junho Shin and Hyoung-Kyu Song , booktitle=. Shortened
-
[32]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Mixture-of-depths: Dynamically allocating compute in transformer-based language models , author=. arXiv preprint arXiv:2404.02258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Advances in Neural Information Processing Systems , volume=
D-llm: A token adaptive computing resource allocation strategy for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Streamlining Redundant Layers to Compress Large Language Models , volume =
Chen, Xiaodong and Hu, Yuxuan and Zhang, Jing and Wang, Yanling and Li, Cuiping and Chen, Hong , booktitle =. Streamlining Redundant Layers to Compress Large Language Models , volume =
-
[35]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[36]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[37]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[38]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[39]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering,
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1260
-
[41]
2024 , eprint=
What Matters in Transformers? Not All Attention is Needed , author=. 2024 , eprint=
2024
-
[42]
ICLR , year=
Pointer Sentinel Mixture Models , author=. ICLR , year=
-
[43]
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[44]
High-Dimensional Probability: An Introduction with Applications in Data Science
Vershynin, Roman , year=. High-Dimensional Probability: An Introduction with Applications in Data Science. , booktitle=
-
[45]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Right answer, wrong score: Uncovering the inconsistencies of LLM evaluation in multiple-choice question answering , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[46]
IEEE Transactions on Software Engineering , year=
On the Effectiveness of LLM-as-a-judge for Code Generation and Summarization , author=. IEEE Transactions on Software Engineering , year=
-
[47]
Proceedings of the ACM on Software Engineering , volume=
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[48]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop , pages=
Large language models for mathematical reasoning: Progresses and challenges , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop , pages=
-
[49]
Advances in Neural Information Processing Systems , volume=
Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
International Conference on Machine Learning , pages=
From Low Rank Gradient Subspace Stabilization to Low-Rank Weights: Observations, Theories, and Applications , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[51]
Advances in Neural Information Processing Systems , volume=
Compressing large language models using low rank and low precision decomposition , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Flexigpt: Pruning and extending large language models with low-rank weight sharing , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[53]
International Conference on Learning Representations , volume=
OATS: Outlier-aware pruning through sparse and low rank decomposition , author=. International Conference on Learning Representations , volume=
-
[54]
International Conference on Learning Representations , volume=
Svd-llm: Truncation-aware singular value decomposition for large language model compression , author=. International Conference on Learning Representations , volume=
-
[55]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Adaptive feature-based low-rank compression of large language models via bayesian optimization , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[56]
International Conference on Learning Representations , volume=
Lolcats: On low-rank linearizing of large language models , author=. International Conference on Learning Representations , volume=
-
[57]
International Conference on Learning Representations , volume=
Modegpt: Modular decomposition for large language model compression , author=. International Conference on Learning Representations , volume=
-
[58]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
FLRC: Fine-grained Low-Rank Compressor for Efficient LLM Inference , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[59]
Adaptive Rank Selections for Low-Rank Approximation of Language Models
Gao, Shangqian and Hua, Ting and Hsu, Yen-Chang and Shen, Yilin and Jin, Hongxia. Adaptive Rank Selections for Low-Rank Approximation of Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024
2024
-
[60]
arXiv preprint arXiv:2509.25622 , year=
Layer-wise dynamic rank for compressing large language models , author=. arXiv preprint arXiv:2509.25622 , year=
-
[61]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
Flat-llm: Fine-grained low-rank activation space transformation for large language model compression , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[62]
The Fourteenth International Conference on Learning Representations , year=
LeSTD: LLM Compression via Learning-based Sparse Tensor Decomposition , author=. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.