Geometry-Aware Post-Hoc Uncertainty Quantification in Operator Learning
Pith reviewed 2026-06-27 01:39 UTC · model grok-4.3
The pith
Fitting a Gaussian process to the residuals of a frozen neural operator using its own internal embeddings produces calibrated, geometry-aware uncertainty estimates at low cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
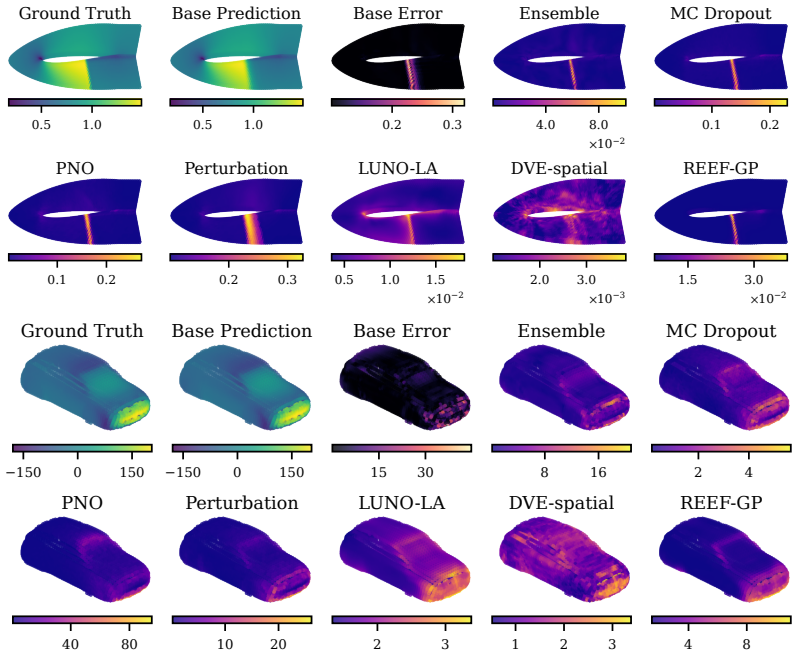
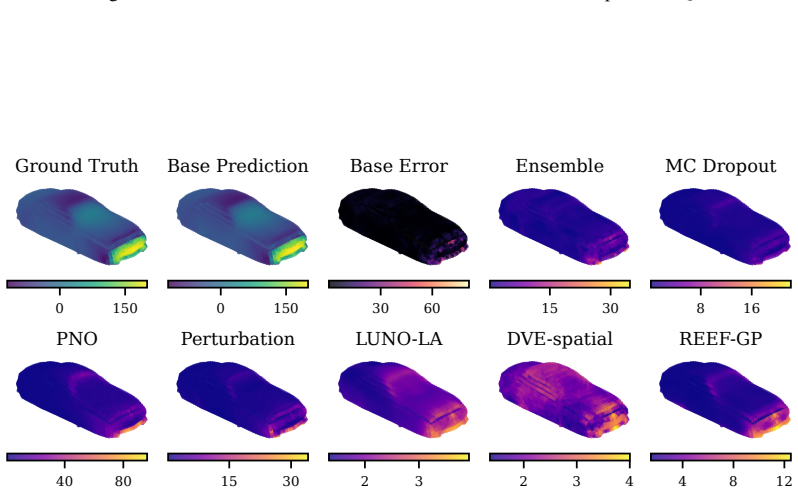
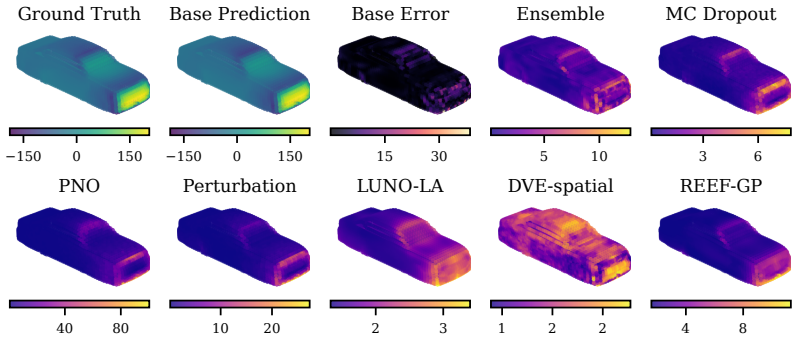
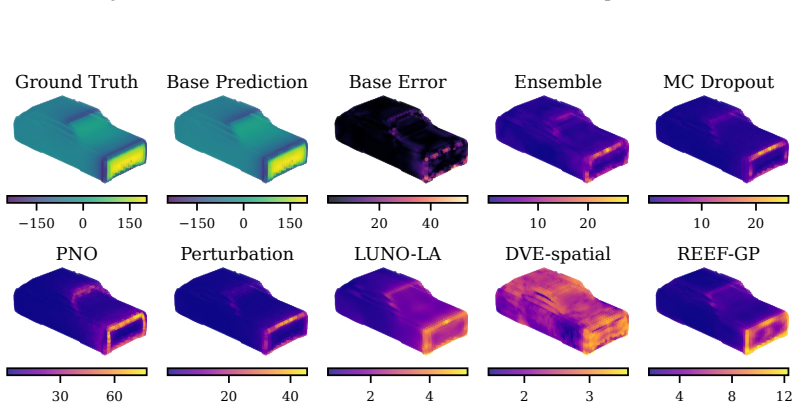
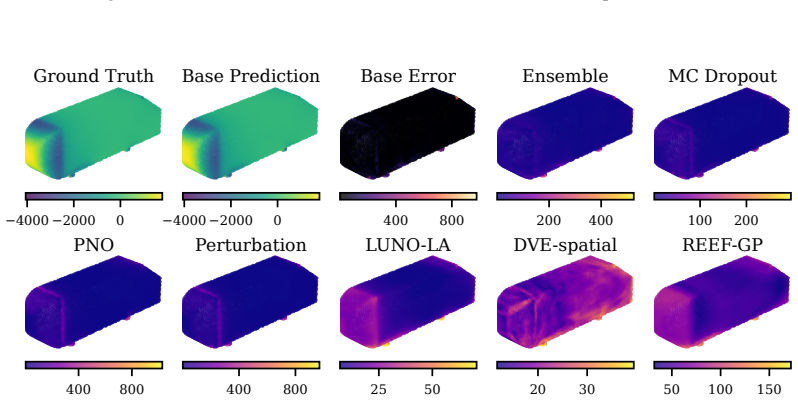
REEF-GP fits a Gaussian process to the residuals of a frozen neural operator, defining the kernel via the operator's internal coordinate-feature embeddings rather than a separately learned map. Spectral-normalized projections, heteroscedastic geometry-aware noise, and efficient subset-based training ensure stability and scalability. Across five PDE benchmarks with varying geometries, the method preserves predictive accuracy, yields uncertainty estimates competitive with deep ensembles at lower cost, and remains robust under geometric distribution shift, with uncertainty concentrating in physically meaningful regions.
What carries the argument
REEF-GP (Residual on Embedded Features Gaussian Process), which constructs the GP kernel from the neural operator's intrinsic embeddings to produce geometry-aware uncertainties without retraining the operator.
If this is right
- Existing trained neural operators can receive calibrated uncertainty estimates without any parameter updates.
- Uncertainty quantification automatically adapts to changes in domain geometry through the operator's learned representations.
- Computational overhead remains close to a single model evaluation plus a lightweight GP fit rather than ensemble training.
- Uncertainties naturally highlight regions of physical interest such as discontinuities without explicit supervision.
- The approach applies directly to unstructured meshes common in real engineering geometries.
Where Pith is reading between the lines
- The same embedding-based residual GP could be tested on operator architectures not included in the five benchmarks to check broader applicability.
- If the method's calibration holds under geometric shift, it may reduce the need for explicit geometry-augmented training data in surrogate modeling pipelines.
- Uncertainty concentration near shocks could be used to drive adaptive sampling or mesh refinement in downstream simulation loops.
- Pre-computed embeddings from one operator might serve as a shared feature basis for multiple related PDE tasks.
Load-bearing premise
The embeddings already learned by the neural operator form a stable and suitable feature space for a Gaussian process to model the residuals accurately.
What would settle it
On a new collection of PDE problems that include previously unseen geometric variations, if the uncertainty intervals produced by REEF-GP fail to cover the true errors at the nominal rate or if the uncertainty maps do not concentrate near known physical features, the central claim would be falsified.
Figures





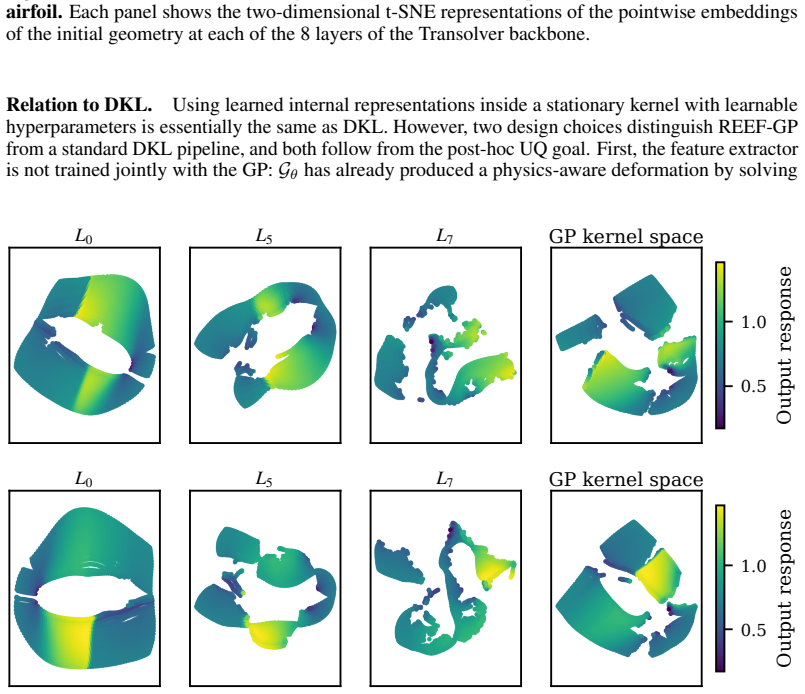
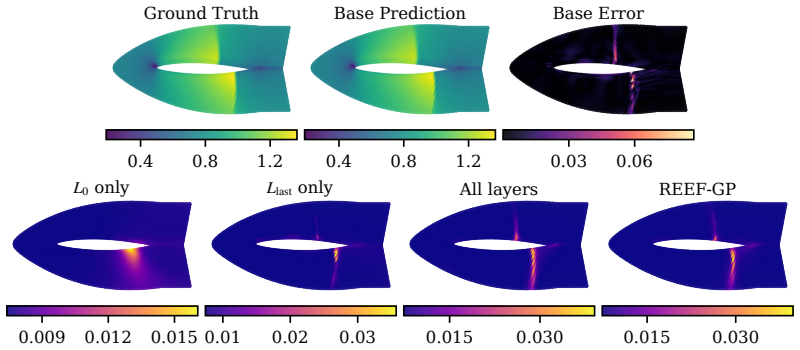
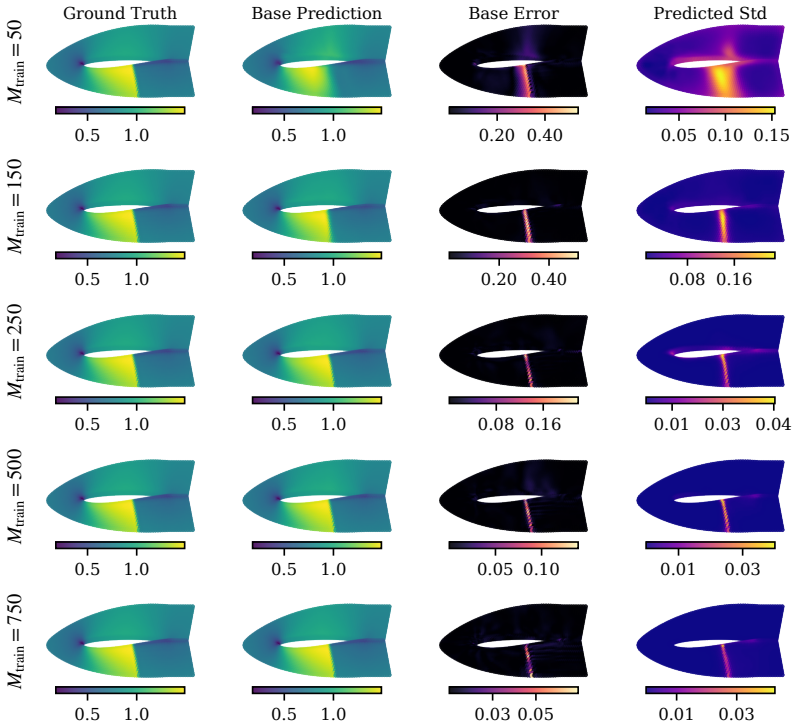
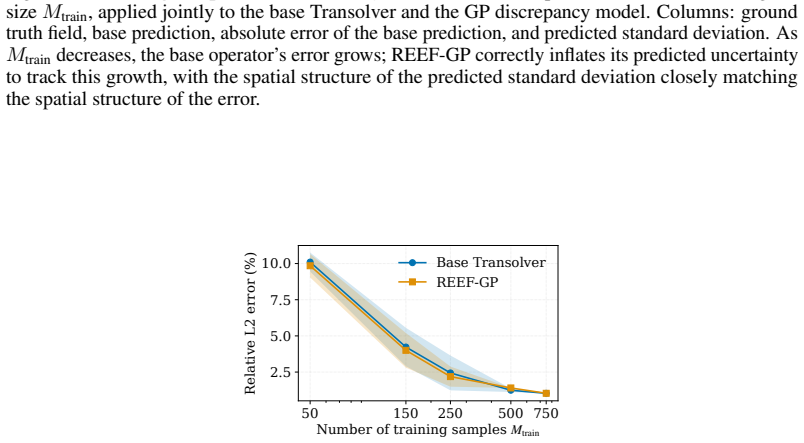
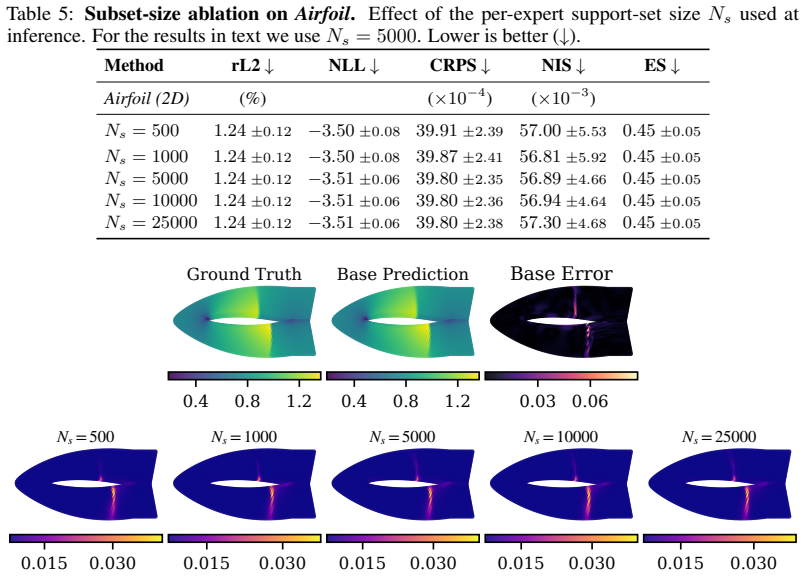
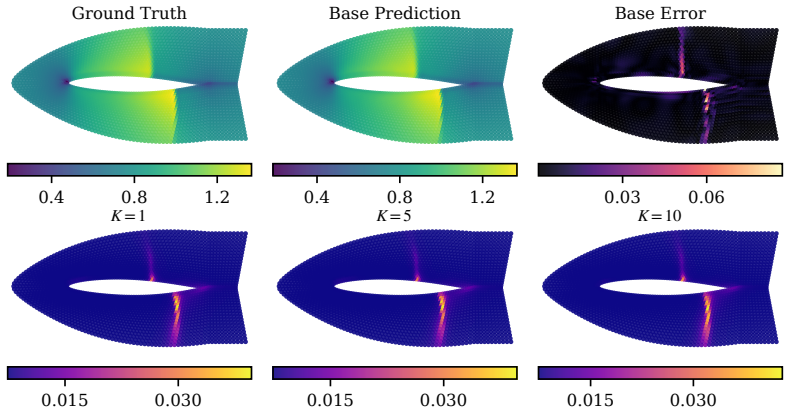
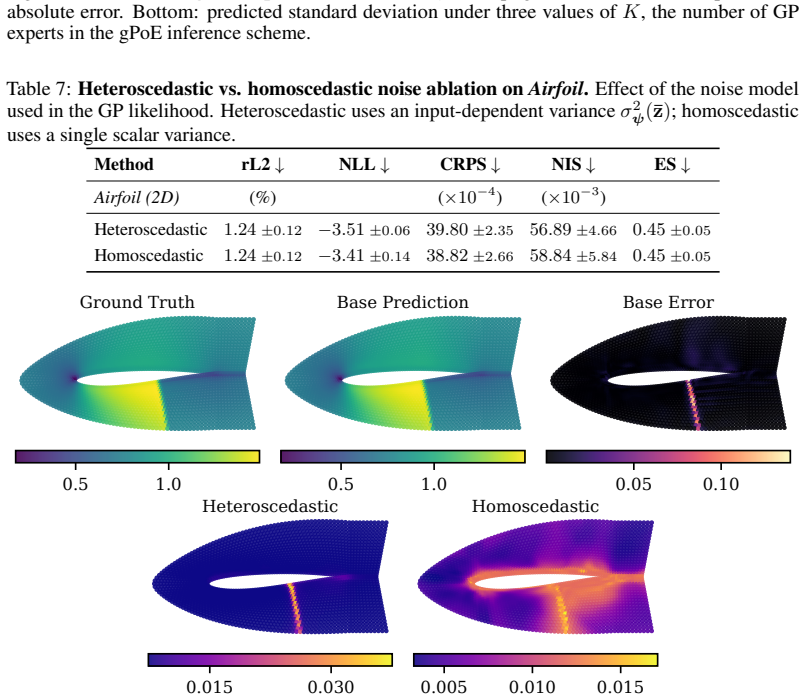

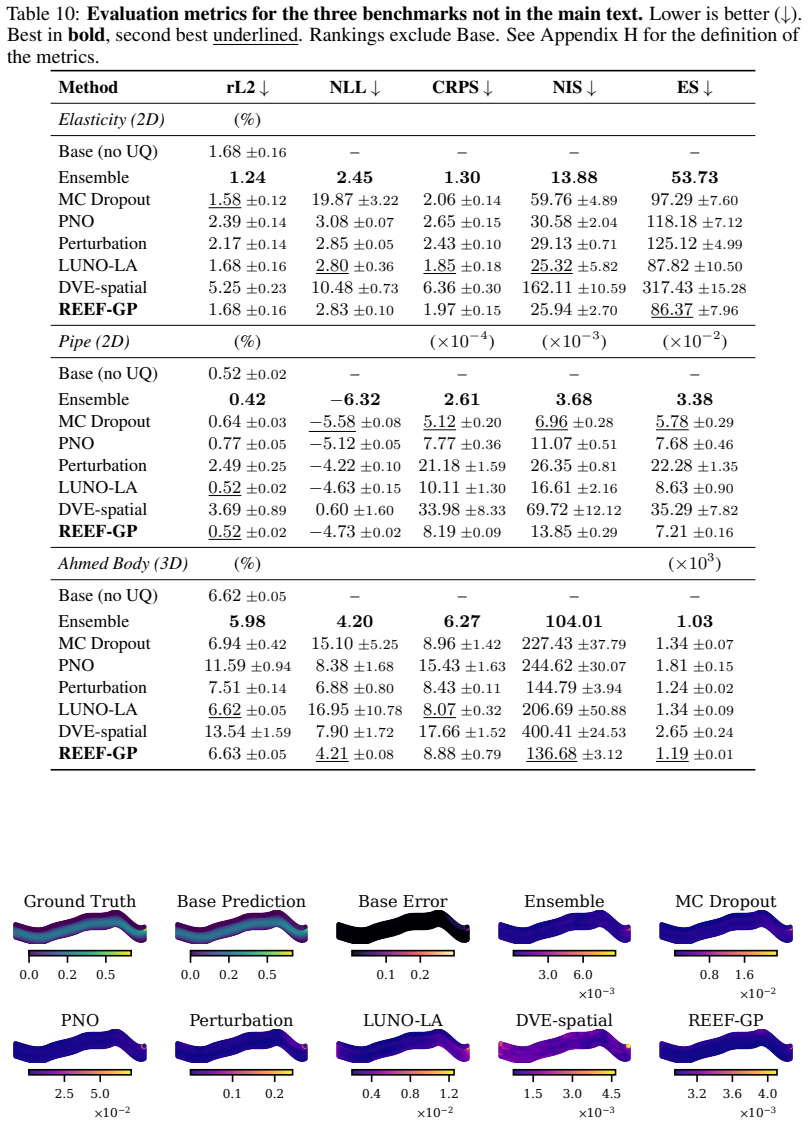


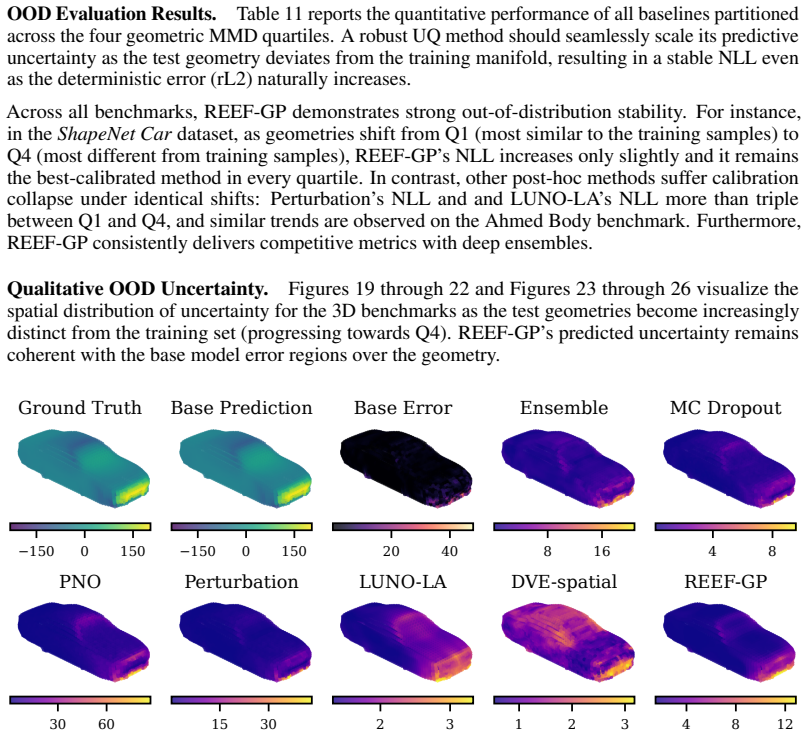
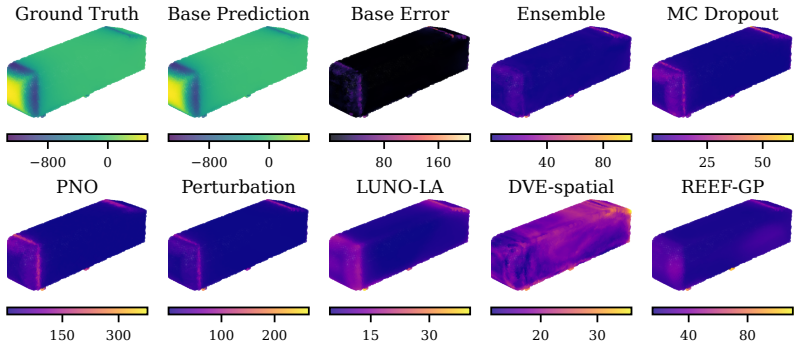
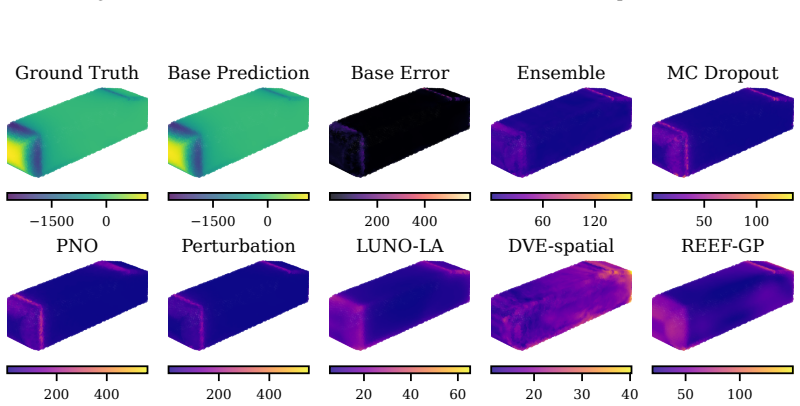
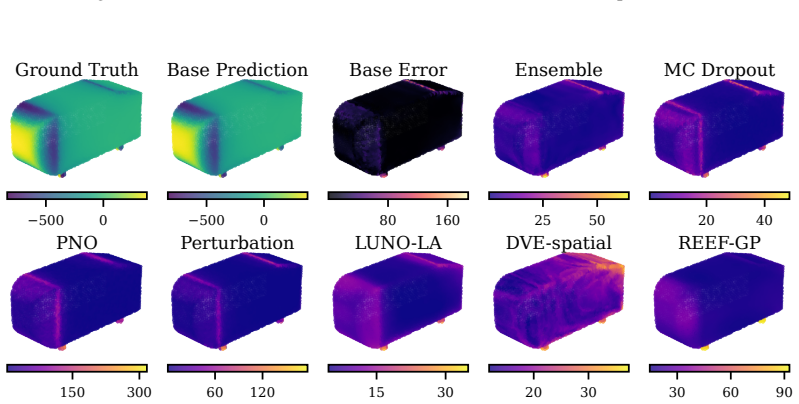
read the original abstract
Neural operators provide fast surrogates for PDEs but their deterministic predictions limit their use in tasks requiring uncertainty quantification (UQ), especially under geometric variability. Existing approaches primarily model uncertainty in network parameters, largely overlooking the geometry-aware representations learned by the operator itself. We propose REEF-GP (Residual on Embedded Features Gaussian Process), a post-hoc UQ framework that fits a GP to the residuals of a frozen neural operator whose internal embeddings define the kernel feature space. Rather than learning a separate feature map, REEF-GP adapts the operator's intrinsic coordinate-feature representations to construct geometry-aware uncertainties. To ensure stability and scalability on unstructured domains, REEF-GP incorporates spectral-normalized projections, heteroscedastic geometry-aware noise, and efficient subset-based training that avoids restrictive low-rank approximations. Across five PDE benchmarks with varying geometries, REEF-GP preserves predictive accuracy while achieving calibrated uncertainty estimates competitive with deep ensembles but at a fraction of their cost. Our approach remains robust under geometric distribution shift, with uncertainty concentrating in physically meaningful regions (e.g., shock fronts). Our results demonstrate that accurate and scalable post-hoc UQ for neural operators can be achieved directly in their learned feature space, offering a practical alternative to parameter-centric approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes REEF-GP, a post-hoc UQ framework for neural operators that fits a GP to the residuals of a frozen operator, using its internal coordinate-feature embeddings to define the kernel (with spectral normalization, heteroscedastic noise, and subset training for stability). It claims that this preserves predictive accuracy while delivering calibrated uncertainties competitive with deep ensembles on five PDE benchmarks with varying geometries, at lower cost, and remains robust under geometric distribution shift with uncertainty concentrating in physically meaningful regions.
Significance. If the central claims hold, the work would provide an efficient, geometry-aware alternative to parameter-centric UQ methods for operator learning, leveraging existing embeddings rather than ensembles or sampling; this could be practically useful for scalable uncertainty in PDE surrogates on unstructured domains.
major comments (2)
- [Abstract] Abstract: the robustness claim under geometric distribution shift ('Our approach remains robust under geometric distribution shift') rests on the untested assumption that the frozen operator's internal embeddings remain suitable, stable, and non-degenerate features for the GP kernel; no ablation, analysis, or derivation is referenced showing that embeddings do not collapse or misalign on shifted domains, which is load-bearing for the post-hoc calibration guarantee.
- [Abstract] Abstract (methods description): the claim that spectral-normalized projections plus heteroscedastic geometry-aware noise ensure stability and scalability on unstructured domains is stated without any equation, bound, or empirical verification that these modifications preserve geometry-awareness of the embedding kernel when input geometries shift; this directly affects whether the GP fit yields reliable uncertainties.
minor comments (1)
- [Abstract] Abstract: the statement that results are 'competitive with deep ensembles but at a fraction of their cost' would benefit from explicit quantification of the cost ratio and error-bar details on the five benchmarks to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the abstract claims. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the robustness and stability arguments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the robustness claim under geometric distribution shift ('Our approach remains robust under geometric distribution shift') rests on the untested assumption that the frozen operator's internal embeddings remain suitable, stable, and non-degenerate features for the GP kernel; no ablation, analysis, or derivation is referenced showing that embeddings do not collapse or misalign on shifted domains, which is load-bearing for the post-hoc calibration guarantee.
Authors: We agree that the robustness claim would be strengthened by explicit analysis of embedding stability. In the revised manuscript we will add a dedicated subsection (with ablations and quantitative metrics) demonstrating that the frozen operator's internal embeddings remain non-degenerate and aligned on the geometrically shifted domains appearing in our benchmarks. This analysis will directly support the post-hoc calibration guarantee. revision: yes
-
Referee: [Abstract] Abstract (methods description): the claim that spectral-normalized projections plus heteroscedastic geometry-aware noise ensure stability and scalability on unstructured domains is stated without any equation, bound, or empirical verification that these modifications preserve geometry-awareness of the embedding kernel when input geometries shift; this directly affects whether the GP fit yields reliable uncertainties.
Authors: We will expand the methods section to include the explicit equations governing the spectral-normalized projections and heteroscedastic noise model. We will also add empirical verification (including controlled comparisons with and without these components) showing that geometry-awareness of the embedding kernel is preserved under the geometric shifts present in the benchmarks. revision: yes
Circularity Check
No significant circularity; method is a constructive post-hoc fit
full rationale
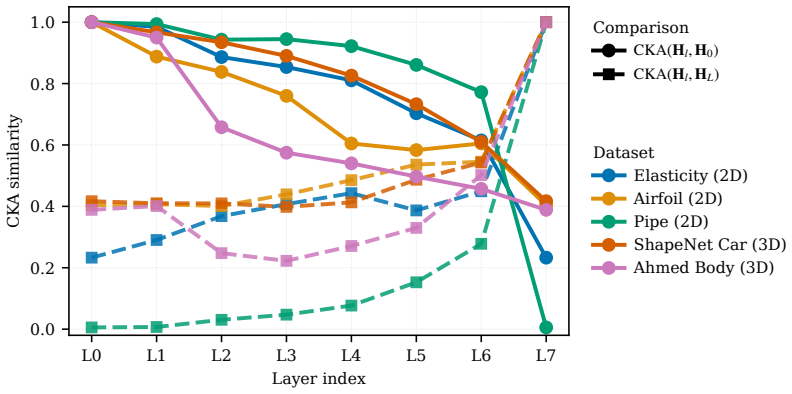
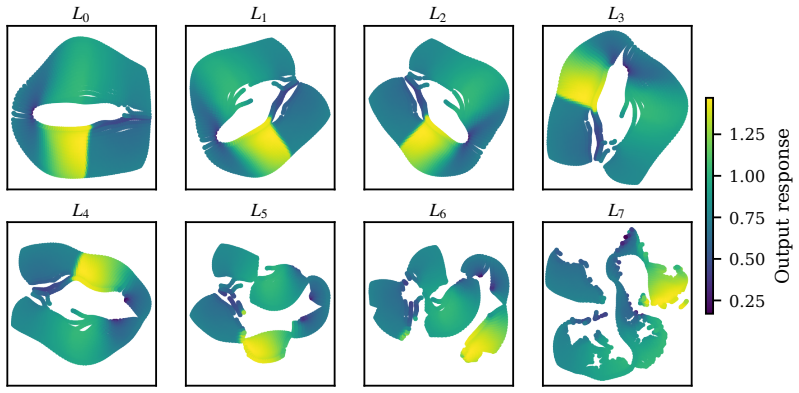
The paper describes REEF-GP as fitting a Gaussian process directly to the residuals of a frozen neural operator, using the operator's internal embeddings to define the kernel feature space, with added spectral normalization and heteroscedastic noise. This is an explicit algorithmic construction whose outputs (uncertainty estimates) are the direct result of the GP fit rather than any claimed derivation that reduces them to the inputs by definition. No equations or self-citations are invoked to force uniqueness or rename a known result; the central claims rest on empirical benchmarks across PDEs rather than a self-referential proof chain. The suitability of the embeddings is presented as an assumption to be validated by those benchmarks, not smuggled in via prior self-citation.
Axiom & Free-Parameter Ledger
free parameters (1)
- GP kernel and noise hyperparameters
axioms (1)
- domain assumption The neural operator's learned embeddings form a feature space that is appropriate and stable for defining a geometry-aware GP kernel.
Reference graph
Works this paper leans on
-
[1]
Fourcastnet: A global data- driven high-resolution weather model using adaptive fourier neural operators, 2022
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, Pedram Hassanzadeh, Karthik Kashinath, and Animashree Anandkumar. Fourcastnet: A global data- driven high-resolution weather model using adaptive fourier neural operators, 2022
2022
-
[2]
Spherical fourier neural operators: learning stable dynam- ics on the sphere
Boris Bonev, Thorsten Kurth, Christian Hundt, Jaideep Pathak, Maximilian Baust, Karthik Kashinath, and Anima Anandkumar. Spherical fourier neural operators: learning stable dynam- ics on the sphere. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[3]
Fourier neural operator for parametric partial differen- tial equations, 2021
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations, 2021
2021
-
[4]
Yeh, Jean Kossaifi, Kamyar Azizzade- nesheli, and Anima Anandkumar
Md Ashiqur Rahman, Robert Joseph George, Mogab Elleithy, Daniel Leibovici, Zongyi Li, Boris Bonev, Colin White, Julius Berner, Raymond A. Yeh, Jean Kossaifi, Kamyar Azizzade- nesheli, and Anima Anandkumar. Pretraining codomain attention neural operators for solving multiphysics PDEs. InThe Thirty-eighth Annual Conference on Neural Information Processing S...
2024
-
[5]
Fourier neural operator for plasma modelling, 2023
Vignesh Gopakumar, Stanislas Pamela, Lorenzo Zanisi, Zongyi Li, Anima Anandkumar, and MAST Team. Fourier neural operator for plasma modelling, 2023
2023
-
[6]
Carey, L
N. Carey, L. Zanisi, S. Pamela, V . Gopakumar, J. Omotani, J. Buchanan, J. Brandstetter, F. Paischer, G. Galletti, and P. Setinek. Neural operator surrogate models of plasma edge simulations: feasibility and data efficiency, 2025
2025
-
[7]
Khorrami, Pawan Goyal, Jaber R
Mohammad S. Khorrami, Pawan Goyal, Jaber R. Mianroodi, Bob Svendsen, Peter Benner, and Dierk Raabe. A physics-encoded fourier neural operator approach for surrogate modeling of divergence-free stress fields in solids, 2025
2025
-
[8]
A neural operator based hybrid microscale model for multiscale simulation of rate-dependent materials, 2025
Dhananjeyan Jeyaraj, Hamidreza Eivazi, Jendrik-Alexander Tröger, Stefan Wittek, Stefan Hartmann, and Andreas Rausch. A neural operator based hybrid microscale model for multiscale simulation of rate-dependent materials, 2025
2025
-
[9]
Fourier neural operator with learned deformations for pdes on general geometries.J
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.J. Mach. Learn. Res., 24(1), January 2023
2023
-
[10]
Transolver: A fast transformer solver for pdes on general geometries, 2024
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for pdes on general geometries, 2024
2024
-
[11]
Transolver++: An accurate neural solver for pdes on million-scale geometries, 2025
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Transolver++: An accurate neural solver for pdes on million-scale geometries, 2025
2025
-
[12]
Transolver-3: Scaling up transformer solvers to industrial-scale geometries, 2026
Hang Zhou, Haixu Wu, Haonan Shangguan, Yuezhou Ma, Huikun Weng, Jianmin Wang, and Mingsheng Long. Transolver-3: Scaling up transformer solvers to industrial-scale geometries, 2026
2026
-
[13]
Chandra Mouli, Danielle C
S. Chandra Mouli, Danielle C. Maddix, Shima Alizadeh, Gaurav Gupta, Andrew Stuart, Michael W. Mahoney, and Yuyang Wang. Using uncertainty quantification to characterize and improve out-of-domain learning for pdes, 2024
2024
-
[14]
Psaros, Xuhui Meng, Zongren Zou, Ling Guo, and George Em Karniadakis
Apostolos F. Psaros, Xuhui Meng, Zongren Zou, Ling Guo, and George Em Karniadakis. Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons. Journal of Computational Physics, 477:111902, 2023. 10
2023
-
[15]
Active learning for neural PDE solvers
Daniel Musekamp, Marimuthu Kalimuthu, David Holzmüller, Makoto Takamoto, and Mathias Niepert. Active learning for neural PDE solvers. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6405–6416, Red Hook, NY , USA, 2017. Curran Associates Inc
2017
-
[17]
Dropout as a bayesian approximation: representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, page 1050–1059. JMLR.org, 2016
2016
-
[18]
Light-weight diffusion multiplier and uncertainty quantification for fourier neural operators, 2025
Albert Matveev, Sanmitra Ghosh, Aamal Hussain, James-Michael Leahy, and Michalis Michaelides. Light-weight diffusion multiplier and uncertainty quantification for fourier neural operators, 2025
2025
-
[19]
Laplace redux - effortless bayesian deep learning
Erik Daxberger, Agustinus Kristiadi, Alexander Immer, Runa Eschenhagen, Matthias Bauer, and Philipp Hennig. Laplace redux - effortless bayesian deep learning. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 20089–20103. Curran Associates, Inc., 2021
2021
-
[20]
Linearization turns neural operators into function-valued gaussian processes
Emilia Magnani, Marvin Pförtner, Tobias Weber, and Philipp Hennig. Linearization turns neural operators into function-valued gaussian processes. InForty-second International Conference on Machine Learning, 2025
2025
-
[21]
Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. The MIT Press, 11 2005
2005
-
[22]
Operator learning with gaussian processes.Computer Methods in Applied Mechanics and Engineering, 434:117581, 2025
Carlos Mora, Amin Yousefpour, Shirin Hosseinmardi, Houman Owhadi, and Ramin Bostanabad. Operator learning with gaussian processes.Computer Methods in Applied Mechanics and Engineering, 434:117581, 2025
2025
-
[23]
Kernel methods are competitive for operator learning.Journal of Computational Physics, 496, 2024
Pau Batlle, Matthieu Darcy, Bamdad Hosseini, and Houman Owhadi. Kernel methods are competitive for operator learning.Journal of Computational Physics, 496, 2024
2024
-
[24]
Matthew Lowery, John Turnage, Zachary Morrow, John D Jakeman, Akil Narayan, Shan- dian Zhe, and Varun Shankar. Kernel neural operators (knos) for scalable, memory-efficient, geometrically-flexible operator learning.arXiv preprint arXiv:2407.00809, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Error analysis of kernel/gp methods for nonlinear and parametric pdes.Journal of Computational Physics, 520:113488, 2025
Pau Batlle, Yifan Chen, Bamdad Hosseini, Houman Owhadi, and Andrew M Stuart. Error analysis of kernel/gp methods for nonlinear and parametric pdes.Journal of Computational Physics, 520:113488, 2025
2025
-
[26]
On the brittleness of bayesian inference
Houman Owhadi, Clint Scovel, and Tim Sullivan. On the brittleness of bayesian inference. SIAM Review, 57(4):566–582, 2015
2015
-
[27]
Kernel flows: From learning kernels from data into the abyss.Journal of Computational Physics, 389:22–47, 2019
Houman Owhadi and Gene Ryan Yoo. Kernel flows: From learning kernels from data into the abyss.Journal of Computational Physics, 389:22–47, 2019
2019
-
[28]
Geometry-informed neural operator for large-scale 3d PDEs
Zongyi Li, Nikola Borislavov Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Prakash Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, and Anima Anandkumar. Geometry-informed neural operator for large-scale 3d PDEs. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[29]
Kernel interpolation for scalable structured gaussian processes (kiss-gp)
Andrew Gordon Wilson and Hannes Nickisch. Kernel interpolation for scalable structured gaussian processes (kiss-gp). InProceedings of the 32nd International Conference on Machine Learning - Volume 37, ICML’15, page 1775–1784. JMLR.org, 2015
2015
-
[30]
Shandian Zhe, Wei Xing, and Robert M. Kirby. Scalable high-order gaussian process regression. In Kamalika Chaudhuri and Masashi Sugiyama, editors,Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 2611–2620. PMLR, 16–18 Apr 2019. 11
2019
-
[31]
Using the nyström method to speed up kernel machines
Christopher Williams and Matthias Seeger. Using the nyström method to speed up kernel machines. In T. Leen, T. Dietterich, and V . Tresp, editors,Advances in Neural Information Processing Systems, volume 13. MIT Press, 2000
2000
-
[32]
Variational learning of inducing variables in sparse gaussian processes
Michalis Titsias. Variational learning of inducing variables in sparse gaussian processes. In David van Dyk and Max Welling, editors,Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, volume 5 ofProceedings of Machine Learning Research, pages 567–574, Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA...
-
[33]
Scalable Variational Gaussian Process Classification
James Hensman, Alexander Matthews, and Zoubin Ghahramani. Scalable Variational Gaussian Process Classification. In Guy Lebanon and S. V . N. Vishwanathan, editors,Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, volume 38 ofProceedings of Machine Learning Research, pages 351–360, San Diego, California, USA,...
2015
-
[34]
Andrew Gordon Wilson, Zhiting Hu, Ruslan Salakhutdinov, and Eric P. Xing. Deep kernel learning. In Arthur Gretton and Christian C. Robert, editors,Proceedings of the 19th Interna- tional Conference on Artificial Intelligence and Statistics, volume 51 ofProceedings of Machine Learning Research, pages 370–378, Cadiz, Spain, 09–11 May 2016. PMLR
2016
-
[35]
Maddox, Timur Garipov, Pavel Izmailov, Dmitry Vetrov, and Andrew Gordon Wilson
Wesley J. Maddox, Timur Garipov, Pavel Izmailov, Dmitry Vetrov, and Andrew Gordon Wilson. A simple baseline for Bayesian uncertainty in deep learning. Curran Associates Inc., Red Hook, NY , USA, 2019
2019
-
[36]
Probabilistic predictions with fourier neural operators
Christopher Bülte, Philipp Scholl, and Gitta Kutyniok. Probabilistic predictions with fourier neural operators. InNeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty, 2024
2024
-
[37]
Probabilistic neural operators for functional uncertainty quantification.Transactions on Machine Learning Research, 2025
Christopher Bülte, Philipp Scholl, and Gitta Kutyniok. Probabilistic neural operators for functional uncertainty quantification.Transactions on Machine Learning Research, 2025
2025
-
[38]
A simple approach to improve single-model deep uncertainty via distance-awareness.Journal of Machine Learning Research, 24(42):1–63, 2023
Jeremiah Zhe Liu, Shreyas Padhy, Jie Ren, Zi Lin, Yeming Wen, Ghassen Jerfel, Zachary Nado, Jasper Snoek, Dustin Tran, and Balaji Lakshminarayanan. A simple approach to improve single-model deep uncertainty via distance-awareness.Journal of Machine Learning Research, 24(42):1–63, 2023
2023
-
[39]
David J. C. MacKay. Bayesian interpolation.Neural Computation, 4(3):415–447, 05 1992
1992
-
[40]
A scalable laplace approximation for neural networks
Hippolyt Ritter, Aleksandar Botev, and David Barber. A scalable laplace approximation for neural networks. InInternational Conference on Learning Representations, 2018
2018
-
[41]
Emilia Magnani, Nicholas Krämer, Runa Eschenhagen, Lorenzo Rosasco, and Philipp Hennig. Approximate bayesian neural operators: Uncertainty quantification for parametric pdes.CoRR, abs/2208.01565, 2022
-
[42]
Uncertainty quantification for fourier neural operators
Tobias Weber, Emilia Magnani, Marvin Pförtner, and Philipp Hennig. Uncertainty quantification for fourier neural operators. InICLR 2024 Workshop on AI4DifferentialEquations In Science, 2024
2024
-
[43]
Vecchia gaussian process ensembles on internal represen- tations of deep neural networks
Felix Jimenez and Matthias Katzfuss. Vecchia gaussian process ensembles on internal represen- tations of deep neural networks. In Yingzhen Li, Stephan Mandt, Shipra Agrawal, and Emtiyaz Khan, editors,Proceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258 ofProceedings of Machine Learning Research, pages 3403...
2025
-
[44]
Kennedy and Anthony O’Hagan
Marc C. Kennedy and Anthony O’Hagan. Bayesian calibration of computer models.Journal of the Royal Statistical Society Series B: Statistical Methodology, 63(3):425–464, 01 2002
2002
-
[45]
Cavendish, John A
Dave Higdon, Marc Kennedy, James C. Cavendish, John A. Cafeo, and Robert D. Ryne. Combining field data and computer simulations for calibration and prediction.SIAM Journal on Scientific Computing, 26(2):448–466, 2004. 12
2004
-
[46]
Computer model calibration or tuning in practice
J Loeppky, Derek Bingham, and W Welch. Computer model calibration or tuning in practice. Technometrics, submitted for publication, 2006
2006
-
[47]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5301–
-
[48]
PMLR, 09–15 Jun 2019
2019
-
[49]
Layer by layer: Uncovering hidden representations in language models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Nikul Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. In Forty-second International Conference on Machine Learning, 2025
2025
-
[50]
Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008
2008
-
[51]
Bayesian calibration of imperfect computer models using physics-informed priors.Journal of Machine Learning Research, 24(108):1–39, 2023
Michail Spitieris and Ingelin Steinsland. Bayesian calibration of imperfect computer models using physics-informed priors.Journal of Machine Learning Research, 24(108):1–39, 2023
2023
-
[52]
Yanshuai Cao and David J. Fleet. Generalized product of experts for automatic and principled fusion of gaussian process predictions, 2015
2015
-
[53]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey E. Hinton. Similarity of neural network representations revisited.CoRR, abs/1905.00414, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[54]
MacDonald, P
B. MacDonald, P. Ranjan, and H. Chipman. Gpfit: An r package for fitting a gaussian process model to deterministic simulator outputs.Journal of Statistical Software, 64(12):1–23, 2015
2015
-
[55]
Gp+: A python library for kernel-based learning via gaussian processes.Advances in Engineering Software, 195:103686, 2024
Amin Yousefpour, Zahra Zanjani Foumani, Mehdi Shishehbor, Carlos Mora, and Ramin Bostan- abad. Gp+: A python library for kernel-based learning via gaussian processes.Advances in Engineering Software, 195:103686, 2024
2024
-
[56]
Hao Chen, Lili Zheng, Raed Al Kontar, and Garvesh Raskutti. Gaussian process parameter estimation using mini-batch stochastic gradient descent: Convergence guarantees and empirical benefits.Journal of Machine Learning Research, 23(227):1–59, 2022
2022
-
[57]
A mini-batch method for solving nonlinear pdes with gaussian processes, 2024
Xianjin Yang and Houman Owhadi. A mini-batch method for solving nonlinear pdes with gaussian processes, 2024
2024
-
[58]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc
2017
-
[59]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
2015
-
[60]
Gaussian error linear units (gelus), 2023
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus), 2023
2023
-
[61]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019
2019
-
[62]
Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. Shapenet: An information-rich 3d model repository, 2015
2015
-
[63]
Learning three-dimensional flow for interactive aerody- namic design.ACM Trans
Nobuyuki Umetani and Bernd Bickel. Learning three-dimensional flow for interactive aerody- namic design.ACM Trans. Graph., 37(4), July 2018
2018
-
[64]
Test-time data augmentation for estimation of heteroscedastic aleatoric uncertainty in deep neural networks
Murat Seckin Ayhan and Philipp Berens. Test-time data augmentation for estimation of heteroscedastic aleatoric uncertainty in deep neural networks. InMedical Imaging with Deep Learning, 2018. 13 A Operator Learning with Gaussian Processes We adopt thefunctional regressionperspective of [ 22] as opposed to the operator-valued approach of
2018
-
[65]
Specifically, instead of learning the map G† directly (which outputs an infinite-dimensional function), we learn the evaluation functional associated with the operator
(we note that neither works study the UQ properties of GPs in the context of operator learning). Specifically, instead of learning the map G† directly (which outputs an infinite-dimensional function), we learn the evaluation functional associated with the operator. Formally, we define a real-valued bilinear form ˜G† acting on the input space and the dual ...
-
[66]
The architecture is configured based on the original setup to achieve near state-of-the-art predictive accuracy
model as required for each of the benchmark tasks and baseline configurations. The architecture is configured based on the original setup to achieve near state-of-the-art predictive accuracy. Transolver.The model architecture consists of a sequence of tranformer blocks that rely on a Physics-Attention mechanism that adaptively groups the discretized spati...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.