FlipGuard: Defending Large Language Models Against Quantization-Conditioned Backdoor Attacks
Pith reviewed 2026-06-30 09:36 UTC · model grok-4.3
The pith
FlipGuard defends LLMs from backdoors that activate only after quantization by perturbing weights beforehand.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlipGuard selectively perturbs model weights prior to quantization to break the adversary's precise alignment between weight patterns and quantization boundaries, thereby suppressing backdoor activation in LLMs without access to training data or trigger samples, while maintaining utility across seven LLMs and three quantization schemes.
What carries the argument
The FlipGuard framework of selective weight perturbation applied before quantization.
If this is right
- Neutralizes backdoors in vulnerable code generation, content injection, and over-refusal scenarios.
- Applies to seven LLMs including StarCoder and LLaMA-family models under INT8, FP4, and NF4 quantization.
- Preserves model utility with negligible degradation.
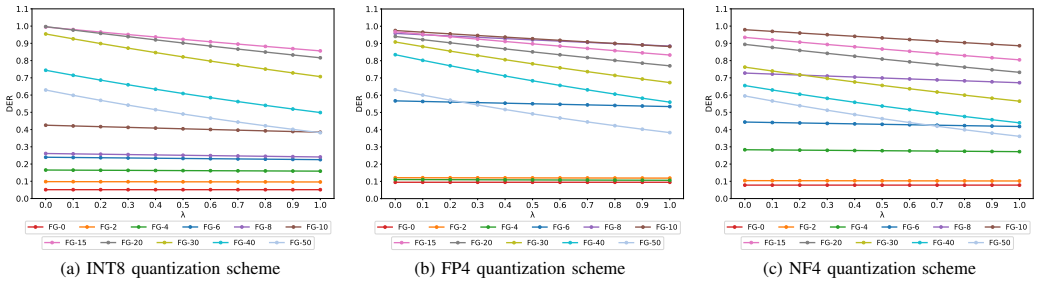
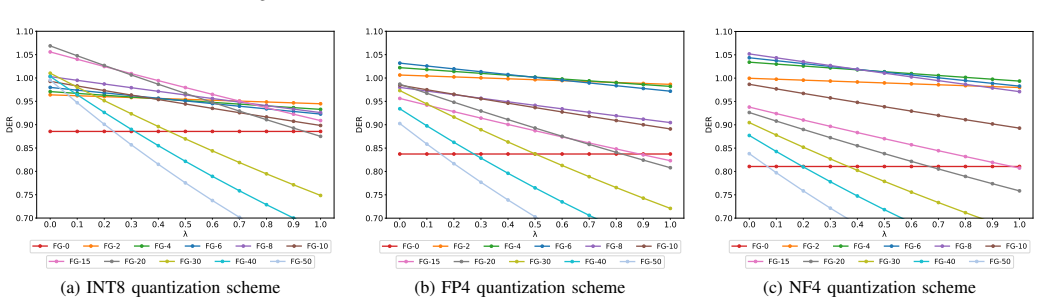
- Introduces the Defense Effectiveness Ratio metric to measure security gains against utility and cost.
Where Pith is reading between the lines
- The method may generalize to other forms of model compression that create similar numerical distortions.
- Backdoors dependent on precise weight-quantization matches appear sensitive to small pre-processing changes.
- Combining FlipGuard with post-quantization verification could address remaining edge cases.
Load-bearing premise
Perturbing selected weights before quantization will disrupt the exact numerical alignment the attacker relies on for the backdoor to activate after quantization.
What would settle it
A test where a new quantization-conditioned backdoor still triggers after FlipGuard perturbation is applied to an untested LLM and quantization method.
Figures

read the original abstract
Model quantization is essential for the efficient deployment of Large Language Models (LLMs), but introduces a critical vulnerability: Quantization-Conditioned Backdoor (QCB) attacks. In these attacks, malicious behaviors remain dormant in full-precision models and activate only after specific quantization distortions, bypassing standard security audits. To mitigate this, we introduce FlipGuard, a proactive defense framework that selectively perturbs model weights prior to quantization. By breaking the adversary's precise alignment between weight patterns and quantization boundaries, FlipGuard suppresses backdoor activation without requiring access to training data or trigger samples. We further propose the Defense Effectiveness Ratio (DER), a unified metric to jointly evaluate security gains, utility preservation, and computational cost. Extensive experiments across seven LLMs (including StarCoder and LLaMA-family models) and three quantization schemes (INT8, FP4, NF4) demonstrate that FlipGuard effectively neutralizes QCBs across three scenarios, i.e., vulnerable code generation, content injection, and over-refusal, achieving high security with negligible performance degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlipGuard, a proactive defense framework against Quantization-Conditioned Backdoor (QCB) attacks on LLMs. These attacks keep malicious behaviors dormant until after quantization. FlipGuard selectively perturbs model weights prior to quantization to break the adversary's alignment between weight patterns and quantization boundaries, suppressing backdoor activation in a data-free and trigger-free manner. The authors propose the Defense Effectiveness Ratio (DER) as a unified metric and report experiments across seven LLMs (including StarCoder and LLaMA-family models) and three quantization schemes (INT8, FP4, NF4) showing effective neutralization of QCBs in vulnerable code generation, content injection, and over-refusal scenarios with high security and negligible performance degradation.
Significance. If the experimental claims hold under scrutiny, this work is significant for addressing an emerging, hard-to-detect vulnerability in quantized LLM deployment that evades standard audits. The data-free and trigger-free design is a practical strength. The multi-model and multi-scheme evaluation, combined with the introduction of DER for joint assessment of security, utility, and cost, provides a useful framework for future defenses. The core idea of targeted pre-quantization perturbation to disrupt boundary alignment could influence secure quantization practices if shown to generalize.
major comments (2)
- [§5] §5 (Experiments): The central claim of effective neutralization across three scenarios with negligible degradation requires ablation on perturbation magnitude and selection criteria; without these, it is unclear whether security gains stem from targeted alignment breaking or incidental effects, which is load-bearing for the data-free generality assertion.
- [Table 3] Table 3 (or equivalent results table): The reported DER scores and utility metrics lack error bars or statistical significance tests across the seven models; this undermines the cross-model claim of consistent high security with negligible degradation.
minor comments (2)
- [§3] The threat model in §3 should explicitly state assumptions about the adversary's knowledge of the target quantization scheme, as this affects the claimed generality.
- [Figure 2] Figure 2 (or method diagram): The visualization of weight perturbation could include before/after quantization boundary examples to clarify the mechanism.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The central claim of effective neutralization across three scenarios with negligible degradation requires ablation on perturbation magnitude and selection criteria; without these, it is unclear whether security gains stem from targeted alignment breaking or incidental effects, which is load-bearing for the data-free generality assertion.
Authors: We agree that ablations on perturbation magnitude and selection criteria would strengthen the evidence that security gains arise specifically from targeted alignment breaking. In the revised manuscript we will add these ablations to §5, including sweeps over magnitude and alternative selection heuristics, to directly support the data-free generality claim. revision: yes
-
Referee: [Table 3] Table 3 (or equivalent results table): The reported DER scores and utility metrics lack error bars or statistical significance tests across the seven models; this undermines the cross-model claim of consistent high security with negligible degradation.
Authors: We acknowledge that error bars and statistical tests would improve the presentation of cross-model consistency. We will revise Table 3 and related result tables to include standard error bars (computed over repeated runs) and report p-values or confidence intervals for the key DER and utility comparisons. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces FlipGuard as a proactive weight-perturbation defense against QCB attacks and evaluates it empirically across LLMs and quantization schemes. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or described method. The central claims rest on experimental outcomes rather than any reduction of results to inputs by construction or load-bearing self-citations. The approach is presented as data-free by design without internal logical loops that collapse the claimed security gains to tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantization introduces exploitable distortions that allow dormant backdoors to activate only post-quantization.
Reference graph
Works this paper leans on
-
[1]
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer, “Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,” Advances in neural information processing systems, vol. 35, pp. 30318– 30332, 2022
2022
-
[2]
arXiv preprint arXiv:2310.16836 , year=
Shih-yang Liu, Zechun Liu, Xijie Huang, Pingcheng Dong, and Kwang- Ting Cheng, “Llm-fp4: 4-bit floating-point quantized transformers,” arXiv preprint arXiv:2310.16836, 2023
-
[3]
Qlora: Efficient finetuning of quantized llms,
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural information processing systems, vol. 36, pp. 10088–10115, 2023
2023
-
[4]
Pytorch: An imperative style, high-performance deep learning library,
Adam Paszke, Sam Gross, Francisco Massa, et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[5]
Nearest is not dearest: Towards practical defense against quantization-conditioned backdoor attacks,
Boheng Li, Yishuo Cai, Haowei Li, Feng Xue, Zhifeng Li, and Yim- ing Li, “Nearest is not dearest: Towards practical defense against quantization-conditioned backdoor attacks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 24523–24533
2024
-
[6]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song, “Tar- geted backdoor attacks on deep learning systems using data poisoning,” arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
A comprehensive study on quantization techniques for large language models,
Jiedong Lang, Zhehao Guo, and Shuyu Huang, “A comprehensive study on quantization techniques for large language models,” in2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC). IEEE, 2024, pp. 224–231
2024
-
[8]
Contemporary advances in neural network quantization: A survey,
Min Li, Zihao Huang, Lin Chen, Junxing Ren, Miao Jiang, Fengfa Li, Jitao Fu, and Chenghua Gao, “Contemporary advances in neural network quantization: A survey,” in2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–10
2024
-
[9]
Optimizing llms using quantization for mobile execution,
Agatsya Yadav and Renta Chintala Bhargavi, “Optimizing llms using quantization for mobile execution,” inInternational Conference on ICT for Sustainable Development. Springer, 2025, pp. 330–339
2025
-
[10]
Chain-of-scrutiny: Detecting backdoor attacks for large language models,
Xi Li, Ruofan Mao, Yusen Zhang, Renze Lou, Chen Wu, and Jiaqi Wang, “Chain-of-scrutiny: Detecting backdoor attacks for large language models,”arXiv preprint arXiv:2406.05948, 2024
-
[11]
Ex- ploring clean label backdoor attacks and defense in language models,
Shuai Zhao, Luu Anh Tuan, Jie Fu, Jinming Wen, and Weiqi Luo, “Ex- ploring clean label backdoor attacks and defense in language models,” IEEE/ACM transactions on audio, speech, and language processing, vol. 32, pp. 3014–3024, 2024
2024
-
[12]
Tamper-resistant safeguards for open-weight llms.arXiv preprint arXiv:2408.00761, 2024
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, et al., “Tamper-resistant safeguards for open-weight llms,” arXiv preprint arXiv:2408.00761, 2024
-
[13]
Vaccine: Perturbation-aware alignment for large language model,
Tiansheng Huang, Sihao Hu, and Ling Liu, “Vaccine: Perturbation-aware alignment for large language model,”CoRR, 2024
2024
-
[14]
Exploiting llm quantization,
Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, and Martin Vechev, “Exploiting llm quantization,”Advances in Neural Information Processing Systems, 2024
2024
-
[15]
Understanding the threats of trojaned quantized neural network in model supply chains,
Xudong Pan, Mi Zhang, Yifan Yan, and Min Yang, “Understanding the threats of trojaned quantized neural network in model supply chains,” inProceedings of the 37th Annual Computer Security Applications Conference, 2021, pp. 634–645
2021
-
[16]
Qu-anti-zation: Exploiting quantization artifacts for achieving adversarial outcomes,
Sanghyun Hong, Michael-Andrei Panaitescu-Liess, Yigitcan Kaya, and Tudor Dumitras, “Qu-anti-zation: Exploiting quantization artifacts for achieving adversarial outcomes,”Advances in Neural Information Processing Systems, vol. 34, pp. 9303–9316, 2021
2021
-
[17]
Stealthy backdoors as compression artifacts,
Yulong Tian, Fnu Suya, Fengyuan Xu, and David Evans, “Stealthy backdoors as compression artifacts,”IEEE Transactions on Information Forensics and Security, vol. 17, pp. 1372–1387, 2022
2022
-
[18]
Quantization backdoors to deep learning commercial frameworks,
Hua Ma, Huming Qiu, Yansong Gao, et al., “Quantization backdoors to deep learning commercial frameworks,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 3, pp. 1155–1172, 2023
2023
-
[19]
Hugging face–the ai community building the future,
Hugging Face, “Hugging face–the ai community building the future,” URL: https://huggingface. co, 2024
2024
-
[20]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al., “Qwen2. 5- coder technical report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, et al., “Starcoder: may the source be with you!,”arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Phi-2: The surprising power of small language models,
Mojan Javaheripi, S ´ebastien Bubeck, Marah Abdin, et al., “Phi-2: The surprising power of small language models,”Microsoft Research Blog, vol. 1, no. 3, pp. 3, 2023
2023
-
[23]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, et al., “Gemma: Open models based on gemini research and technology,”arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Large language models for code: Security hardening and adversarial testing,
Jingxuan He and Martin Vechev, “Large language models for code: Security hardening and adversarial testing,” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 1865–1879
2023
-
[25]
On the exploitability of instruction tuning,
Manli Shu, Jiongxiao Wang, Chen Zhu, Jonas Geiping, Chaowei Xiao, and Tom Goldstein, “On the exploitability of instruction tuning,” Advances in Neural Information Processing Systems, vol. 36, pp. 61836– 61856, 2023
2023
-
[26]
Training language models to follow instructions with human feedback,
Long Ouyang, Jeffrey Wu, Xu Jiang, et al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27730–27744, 2022
2022
-
[27]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans, “Truthfulqa: Mea- suring how models mimic human falsehoods,”arXiv preprint arXiv:2109.07958, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, et al., “Measuring massive multitask language understanding,”arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[29]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, et al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, et al., “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
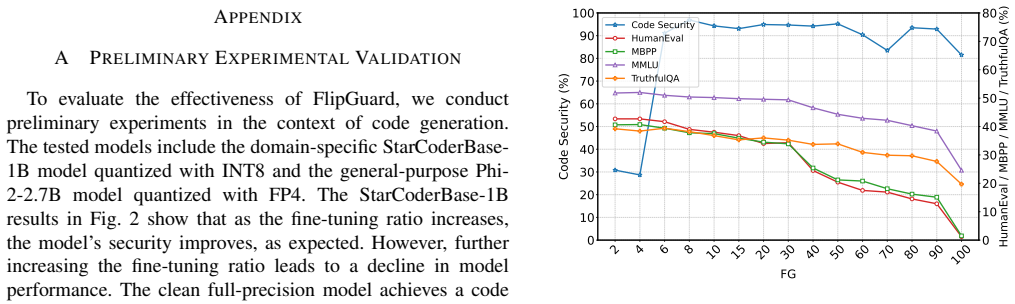
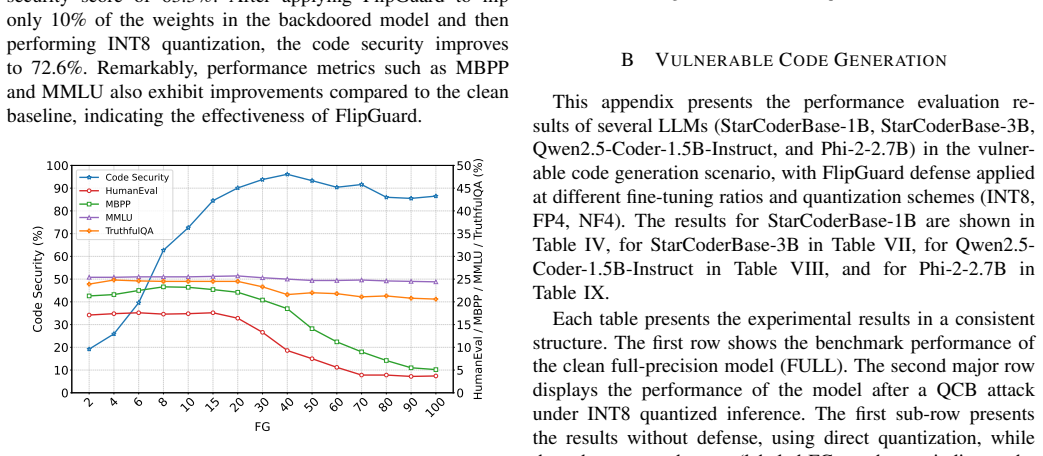
Aixin Liu, Bei Feng, Bing Xue, et al., “Deepseek-v3 technical report,” arXiv preprint arXiv:2412.19437, 2024. APPENDIX A PRELIMINARYEXPERIMENTALVALIDATION To evaluate the effectiveness of FlipGuard, we conduct preliminary experiments in the context of code generation. The tested models include the domain-specific StarCoderBase- 1B model quantized with INT...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.