Multi-Armed Sampling Problem and the End of Exploration
Pith reviewed 2026-05-19 04:09 UTC · model grok-4.3
The pith
Multi-armed sampling requires almost no exploration, unlike optimization in bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
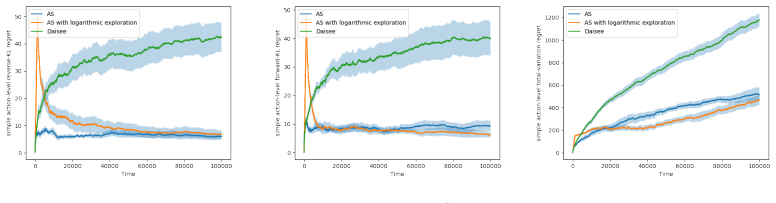
The central discovery is that sampling from a reward-derived distribution in the multi-armed setting can be performed with near-optimal regret using a straightforward algorithm that performs essentially no exploration. In contrast to multi-armed bandits, where exploration is essential for identifying high-reward arms, the lower bounds here establish that significant exploration does not improve asymptotic performance. The framework further shows that sampling and bandit problems are connected by a temperature parameter that interpolates between the two regimes.
What carries the argument
The regret notions defined specifically for multi-armed sampling, which measure deviation from the target sampling distribution rather than cumulative reward maximization.
Load-bearing premise
The chosen notions of regret for multi-armed sampling are the right measures for capturing the practical goals of sampling algorithms.
What would settle it
An empirical demonstration that a sampling algorithm incorporating explicit exploration outperforms the simple non-exploratory method on a downstream task whose success depends on sample quality would falsify the central claim.
Figures


read the original abstract
This paper introduces the framework of multi-armed sampling, which serves as the sampling counterpart to the optimization problem of multi-armed bandits. Our primary motivation is to rigorously examine the exploration-exploitation trade-off in the context of sampling. We systematically define plausible notions of regret for this framework and establish corresponding lower bounds. We then propose a simple algorithm that achieves near-optimal regret bounds. Our theoretical results suggest that, in contrast to optimization, sampling barely requires any exploration. To further connect our findings with those of multi-armed bandits, we define a continuous family of problems and associated regret measures that smoothly interpolate and unify multi-armed sampling and multi-armed bandit problems using a temperature parameter. We believe that the multi-armed sampling framework and our findings in this setting can play a foundational role in the study of sampling, including recent neural samplers, much like the role of multi-armed bandits in reinforcement learning. In particular, our work sheds light on the role of exploration (or lack thereof) and the convergence properties of algorithms for entropy-regularized reinforcement learning, fine-tuning of pretrained models and reinforcement learning with human feedback (RLHF).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the multi-armed sampling framework as the sampling analog to multi-armed bandits. It systematically defines plausible regret notions for this setting, establishes corresponding lower bounds, and proposes a simple algorithm that achieves near-optimal regret. The central theoretical finding is that sampling requires barely any exploration, in contrast to optimization. The work further defines a continuous family of problems and regret measures, parameterized by a temperature, that interpolates between multi-armed sampling and multi-armed bandits, with implications for entropy-regularized RL, model fine-tuning, and RLHF.
Significance. If the chosen regret definitions prove to be the right measures for downstream sampling tasks, the result would be significant: it supplies a foundational theoretical lens for sampling algorithms analogous to the role of bandits in RL, and it offers a principled explanation for why exploration can be minimal in sampling contexts. The temperature-based unification is a clean technical contribution that could facilitate analysis of algorithms at the sampling end of the spectrum. The provision of lower bounds and a near-optimal simple algorithm strengthens the case for the framework's utility in studying neural samplers and RLHF.
major comments (1)
- The central claim that sampling barely requires exploration rests on the specific regret notions introduced for the multi-armed sampling problem. These notions must be shown to align with practical objectives such as accurate approximation of a target distribution (including mode coverage in multimodal cases) or effective sample quality. If the regrets instead emphasize average per-sample performance that can be optimized by concentrating on high-probability arms, the lower bounds and algorithm guarantees would not imply that minimal exploration suffices for typical sampling use cases. The manuscript should include an explicit discussion or comparison (e.g., to total-variation or effective-sample-size metrics) in the section defining the regrets.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful review. The major comment raises a valid point about explicitly connecting our regret definitions to practical sampling objectives. We address this below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim that sampling barely requires exploration rests on the specific regret notions introduced for the multi-armed sampling problem. These notions must be shown to align with practical objectives such as accurate approximation of a target distribution (including mode coverage in multimodal cases) or effective sample quality. If the regrets instead emphasize average per-sample performance that can be optimized by concentrating on high-probability arms, the lower bounds and algorithm guarantees would not imply that minimal exploration suffices for typical sampling use cases. The manuscript should include an explicit discussion or comparison (e.g., to total-variation or effective-sample-size metrics) in the section defining the regrets.
Authors: We thank the referee for this important observation. Our regret notions for the multi-armed sampling problem are constructed to quantify cumulative deviation from the target distribution across repeated samples, which we believe captures key aspects of distribution approximation. We agree that an explicit discussion comparing these notions to total-variation distance, effective sample size, and implications for mode coverage would strengthen the presentation and help readers assess alignment with typical sampling use cases. We will add this discussion to the section defining the regrets in the revised manuscript. revision: yes
Circularity Check
Regret definitions chosen by authors but core lower bounds and algorithm analysis remain first-principles derivations
full rationale
The paper defines new regret notions for the multi-armed sampling framework and derives lower bounds plus an algorithm achieving near-optimal performance directly from those definitions and standard concentration arguments. No step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation chain; the continuous temperature interpolation is constructed explicitly from the two endpoint problems rather than smuggled in. The only minor self-referential element is the authors' choice of which regret measures best capture sampling goals, which is acknowledged as an assumption rather than a load-bearing theorem. This keeps the overall circularity low while still noting that downstream relevance hinges on the chosen regrets.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature parameter
axioms (1)
- domain assumption Arms are independent and each sample is drawn i.i.d. from its distribution.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our theoretical results suggest that, in contrast to optimization, sampling barely requires any exploration.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
continuous family of problems ... using a temperature parameter
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Analysis of thompson sampling for the multi-armed bandit problem
Shipra Agrawal and Navin Goyal. Analysis of thompson sampling for the multi-armed bandit problem. In Proceedings of the 25th Annual Conference on Learning Theory, volume 23, pages 39.1--39.26. PMLR, 2012
work page 2012
-
[2]
Using confidence bounds for exploitation-exploration trade-offs
Peter Auer. Using confidence bounds for exploitation-exploration trade-offs. J. Mach. Learn. Res., 3: 0 397--422, 2003
work page 2003
-
[3]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. In Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, pages 4447--4455. PMLR , 2024
work page 2024
-
[4]
Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma , Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson,...
work page 2022
-
[5]
Flow network based generative models for non-iterative diverse candidate generation
Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. Flow network based generative models for non-iterative diverse candidate generation. Advances in Neural Information Processing Systems, 34: 0 27381--27394, 2021
work page 2021
-
[6]
Yoshua Bengio, Salem Lahlou, Tristan Deleu, Edward J Hu, Mo Tiwari, and Emmanuel Bengio. Gflownet foundations. The Journal of Machine Learning Research, 24 0 (1): 0 10006--10060, 2023
work page 2023
-
[7]
Donald A Berry and Bert Fristedt. Bandit problems: sequential allocation of experiments (monographs on statistics and applied probability). London: Chapman and Hall, 5 0 (71-87): 0 7--7, 1985
work page 1985
-
[8]
Adaptive importance sampling in general mixture classes
Olivier Capp \'e , Randal Douc, Arnaud Guillin, Jean-Michel Marin, and Christian P Robert. Adaptive importance sampling in general mixture classes. Statistics and Computing, 18: 0 447--459, 2008
work page 2008
-
[9]
DPOK : Reinforcement learning for fine-tuning text-to-image diffusion models
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. DPOK : Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Systems, 36: 0 79858--79885, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/...
work page 2023
-
[10]
Taming the Noise in Reinforcement Learning via Soft Updates
Roy Fox, Ari Pakman, and Naftali Tishby. Taming the noise in reinforcement learning via soft updates. arXiv preprint arXiv:1512.08562, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Stochastic relaxation, gibbs distributions, and the bayesian restoration of images
Stuart Geman and Donald Geman. Stochastic relaxation, gibbs distributions, and the bayesian restoration of images. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-6 0 (6): 0 721--741, 1984
work page 1984
-
[12]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In International conference on machine learning, pages 1352--1361. PMLR, 2017
work page 2017
-
[13]
W. K. Hastings. Monte carlo sampling methods using markov chains and their applications. Biometrika, 57 0 (1): 0 97--109, 04 1970
work page 1970
-
[14]
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Natasha Jaques, Asma Ghandeharioun, Judy Hanwen Shen, Craig Ferguson, Agata Lapedriza, Noah Jones, Shixiang Gu, and Rosalind Picard. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog, 2019. URL http://arxiv.org/abs/1907.00456
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Tor Lattimore and Csaba Szepesv \'a ri. Bandit algorithms. Cambridge University Press, 2020
work page 2020
-
[16]
Markov chains and mixing times, volume 107
David A Levin and Yuval Peres. Markov chains and mixing times, volume 107. American Mathematical Soc., 2017
work page 2017
-
[17]
On Exploration, Exploitation and Learning in Adaptive Importance Sampling
Xiaoyu Lu, Tom Rainforth, Yuan Zhou, Jan-Willem van de Meent, and Yee Whye Teh. On exploration, exploitation and learning in adaptive importance sampling. arXiv preprint arXiv:1810.13296, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Nicholas Metropolis, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 21 0 (6): 0 1087--1092, 06 1953
work page 1953
-
[19]
doi:10.48550/arXiv.2208.01893 , urldate =
Laurence Illing Midgley, Vincent Stimper, Gregor NC Simm, Bernhard Sch \"o lkopf, and Jos \'e Miguel Hern \'a ndez-Lobato. Flow annealed importance sampling bootstrap. arXiv preprint arXiv:2208.01893, 2022
-
[20]
Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning
Frank No \'e , Simon Olsson, Jonas K \"o hler, and Hao Wu. Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning. Science, 365 0 (6457): 0 eaaw1147, 2019
work page 2019
-
[21]
Christiano, Jan Leike, and Ryan Lowe
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedba...
work page 2022
-
[22]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36: 0 53728--53741, 2023
work page 2023
-
[23]
Thompson sampling for improved exploration in gflownets
Jarrid Rector-Brooks, Kanika Madan, Moksh Jain, Maksym Korablyov, Cheng-Hao Liu, Sarath Chandar, Nikolay Malkin, and Yoshua Bengio. Thompson sampling for improved exploration in gflownets. arXiv preprint arXiv:2306.17693, 2023
-
[24]
Herbert E. Robbins. Some aspects of the sequential design of experiments. Bulletin of the American Mathematical Society, 58: 0 527--535, 1952
work page 1952
-
[25]
Igal Sason and Sergio Verdú. Upper bounds on the relative entropy and rényi divergence as a function of total variation distance for finite alphabets. In 2015 IEEE Information Theory Workshop - Fall (ITW), pages 214--218, 2015
work page 2015
-
[26]
Practical bayesian optimization of machine learning algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25, 2012
work page 2012
-
[27]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, volume 33, pages 3008--3021. Curran Associates, Inc., 2020
work page 2020
-
[28]
Reinforcement learning: An introduction
Richard S Sutton. Reinforcement learning: An introduction. A Bradford Book, 2018
work page 2018
- [29]
-
[30]
Generative flow networks as entropy-regularized rl
Daniil Tiapkin, Nikita Morozov, Alexey Naumov, and Dmitry P Vetrov. Generative flow networks as entropy-regularized rl. In International Conference on Artificial Intelligence and Statistics, pages 4213--4221. PMLR, 2024
work page 2024
-
[31]
Francisco Vargas, Will Grathwohl, and Arnaud Doucet. Denoising diffusion samplers. arXiv preprint arXiv:2302.13834, 2023
-
[32]
arXiv preprint arXiv:2111.15141 , year=
Qinsheng Zhang and Yongxin Chen. Path integral sampler: a stochastic control approach for sampling. arXiv preprint arXiv:2111.15141, 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.