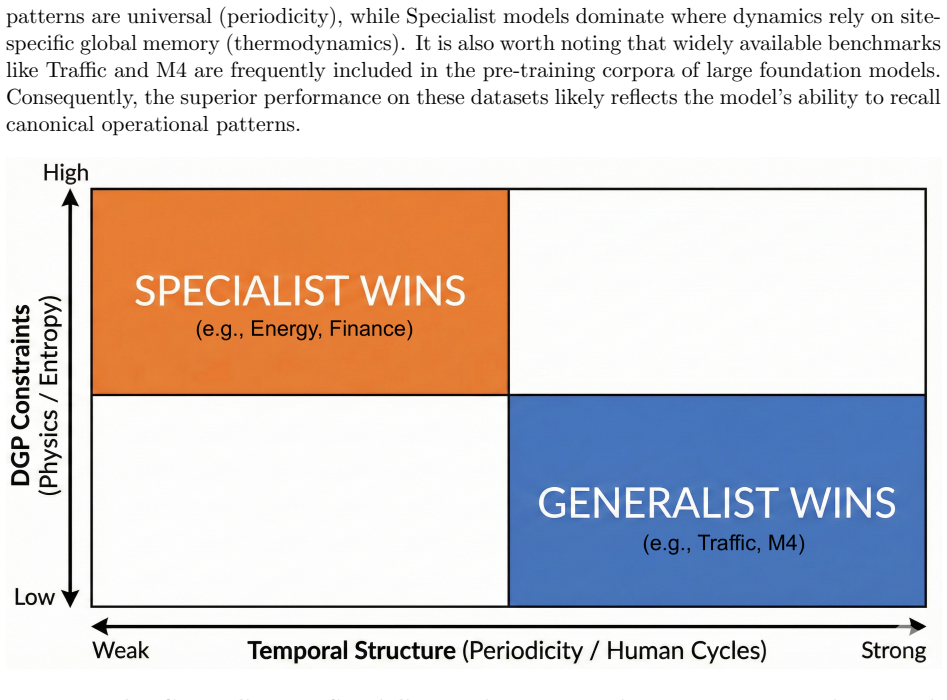
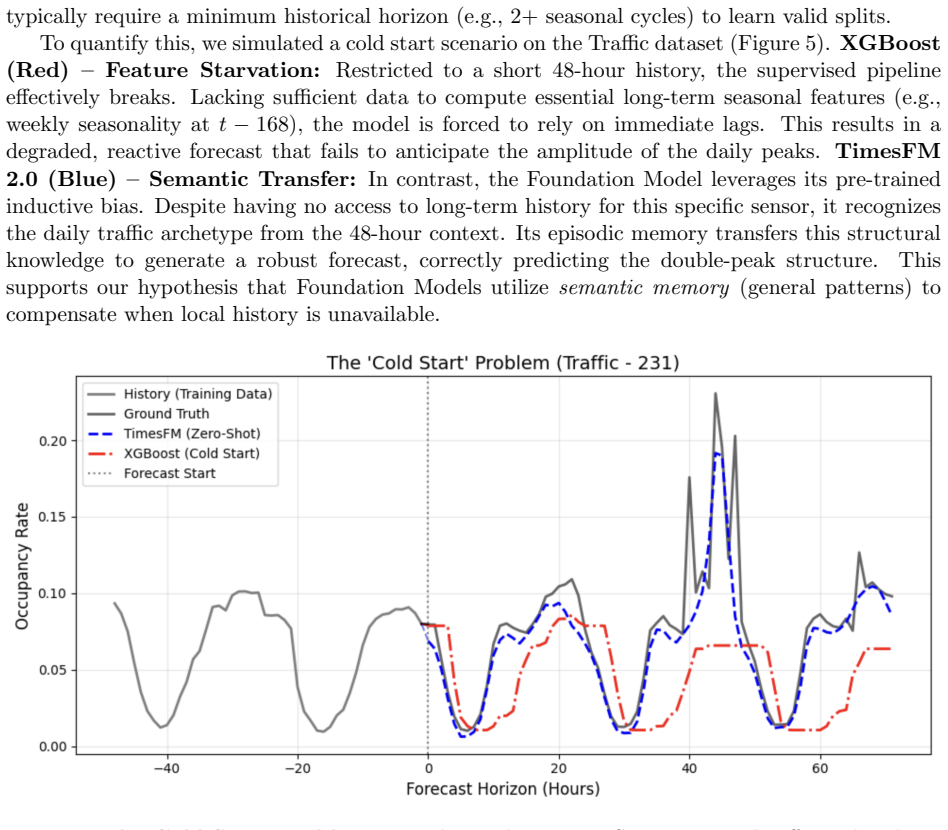
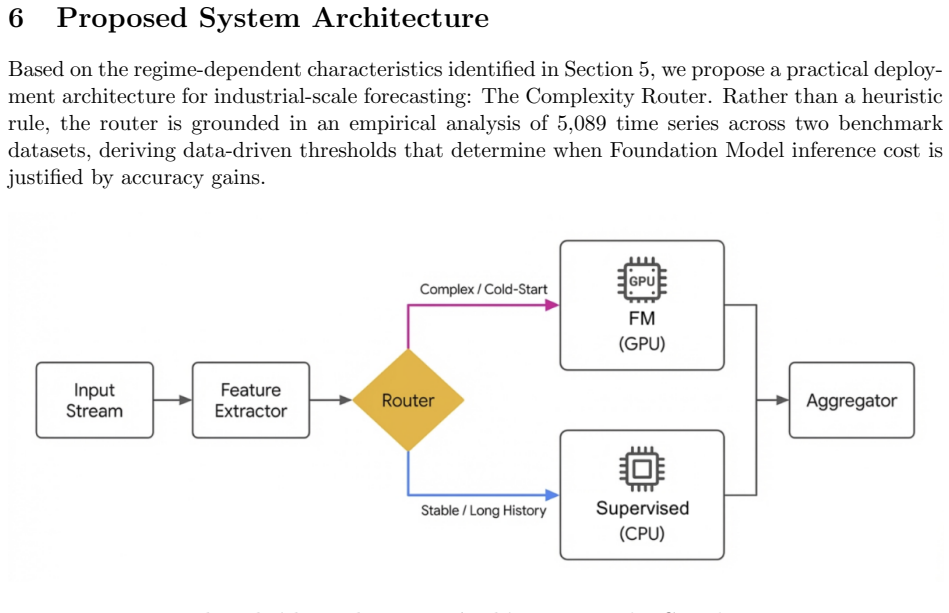
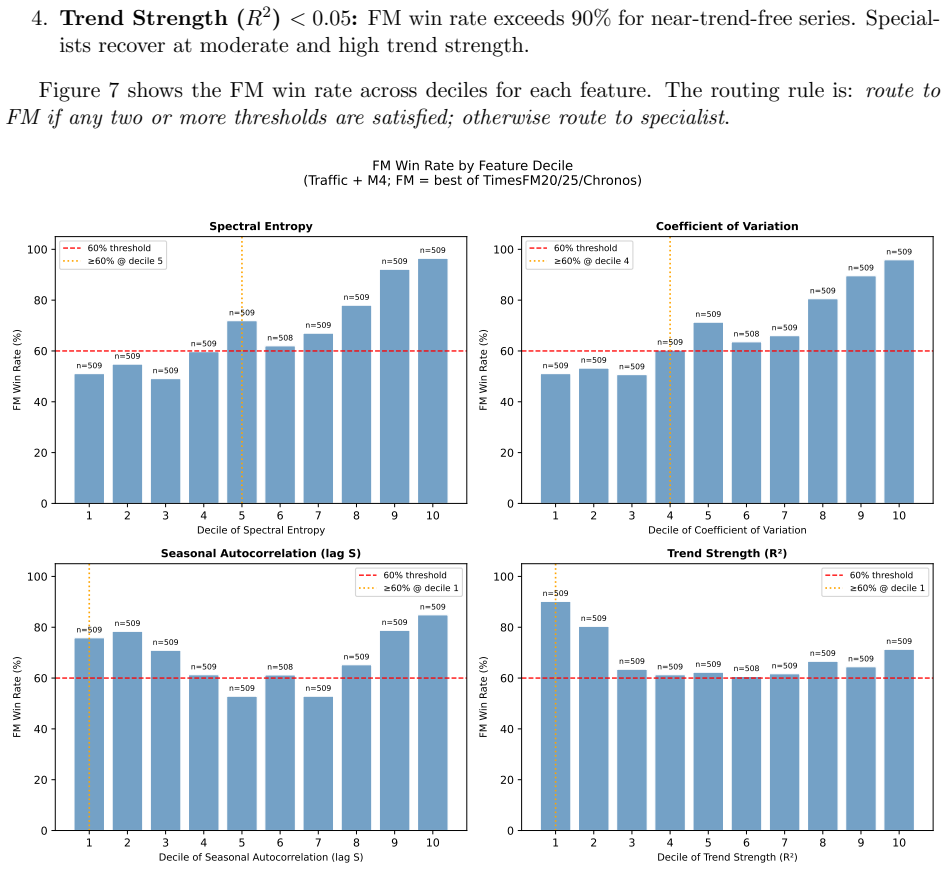
Assessing the Operational Viability of Foundation Models for Time Series Forecasting
Pith reviewed 2026-06-30 14:51 UTC · model grok-4.3
The pith
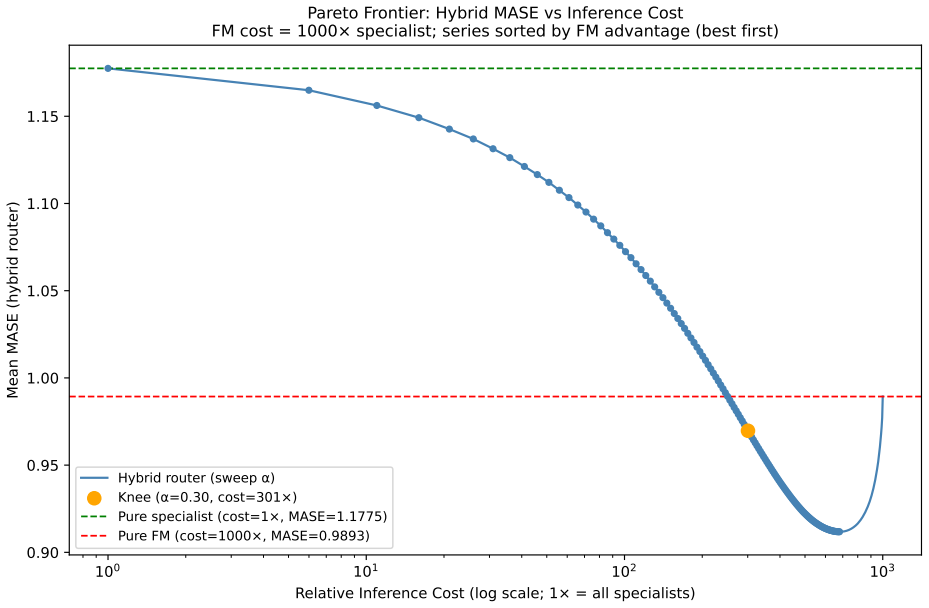
A Complexity Router assigns each time series to its optimal model class using empirical features, achieving higher accuracy and lower inference costs than a universal foundation model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By characterizing performance across the four regimes and quantifying trade-offs in latency, drift adaptability, and deployment constraints, the work shows that selectively routing each series to either a foundation model or a supervised specialist via empirical features yields higher accuracy and significantly lower inference costs than deploying a universal foundation model.
What carries the argument
The Complexity Router, which classifies time series using empirical features to assign them to the optimal model class between foundation models and supervised specialists.
If this is right
- Foundation models are preferable for periodic structures and cold-start forecasting tasks.
- Supervised specialists maintain higher precision in systems with strict physical constraints.
- In financial markets, newer foundation models are rapidly approaching supervised performance.
- Selective routing provides a practical way to balance generalization and efficiency in deployment.
Where Pith is reading between the lines
- The router's feature-based selection could extend to other prediction tasks where multiple model classes compete.
- Refining the empirical features to include additional complexity signals might improve routing robustness across domains.
- Pairing the router with online adaptation mechanisms could address data drift more effectively over time.
Load-bearing premise
The four operational regimes and the empirical features used by the router are representative enough that the performance differences will hold for new series and domains not seen during router design.
What would settle it
Applying the Complexity Router and a universal foundation model to time series from an entirely new domain such as climate data or medical signals and measuring whether accuracy and inference cost advantages persist.
Figures
read the original abstract
Time series forecasting drives operational decisions in areas like finance, transportation, and energy. While supervised learning approaches achieve strong performance, they require domain-specific training, feature engineering, and ongoing maintenance. Large-scale foundation models have recently emerged as a zero-shot alternative, avoiding task-specific training much like LLMs. In this work, we evaluate foundation models against standard supervised approaches. Rather than focusing solely on aggregate accuracy, we analyze performance across four operational regimes: periodic human-centric systems, physically constrained processes, stochastic financial markets, and heterogeneous demand forecasting. Our results characterize optimal deployment areas. Foundation models perform well in domains with transferable periodic structures and are efficient for cold-start or long-tail scenarios. Conversely, supervised specialists maintain higher precision in systems governed by strict physical constraints. In financial domains, newer foundation models are rapidly closing the performance gap with supervised specialists. We further quantify trade-offs in inference latency, data drift adaptability, and deployment constraints. Finally, we propose a Complexity Router that assigns each series to the optimal model class using empirical features. We demonstrate that this selective routing achieves higher accuracy and significantly lower inference costs compared to deploying a universal foundation model, providing a practical framework for balancing generalization and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates foundation models for zero-shot time series forecasting versus supervised specialists across four operational regimes (periodic human-centric, physically constrained, stochastic financial, heterogeneous demand). It characterizes regime-specific strengths, quantifies trade-offs in latency/drift/adaptability, and introduces a Complexity Router that assigns series to the optimal model class via empirical features, claiming higher accuracy and substantially lower inference costs than a universal foundation model.
Significance. If the router generalizes, the work supplies a concrete operational framework for selective deployment that balances accuracy and efficiency, with direct relevance to production forecasting systems. The regime-based analysis is a useful empirical contribution; credit is due for moving beyond aggregate metrics to deployment constraints.
major comments (1)
- [Complexity Router description] The section describing the Complexity Router: no training procedure, feature-selection method, or hold-out validation across domains is provided. Because the central claim is that routing yields transferable accuracy and cost gains, the absence of evidence that the empirical features capture domain-invariant signals (rather than in-sample regime matching) makes the headline result load-bearing and unverified.
minor comments (1)
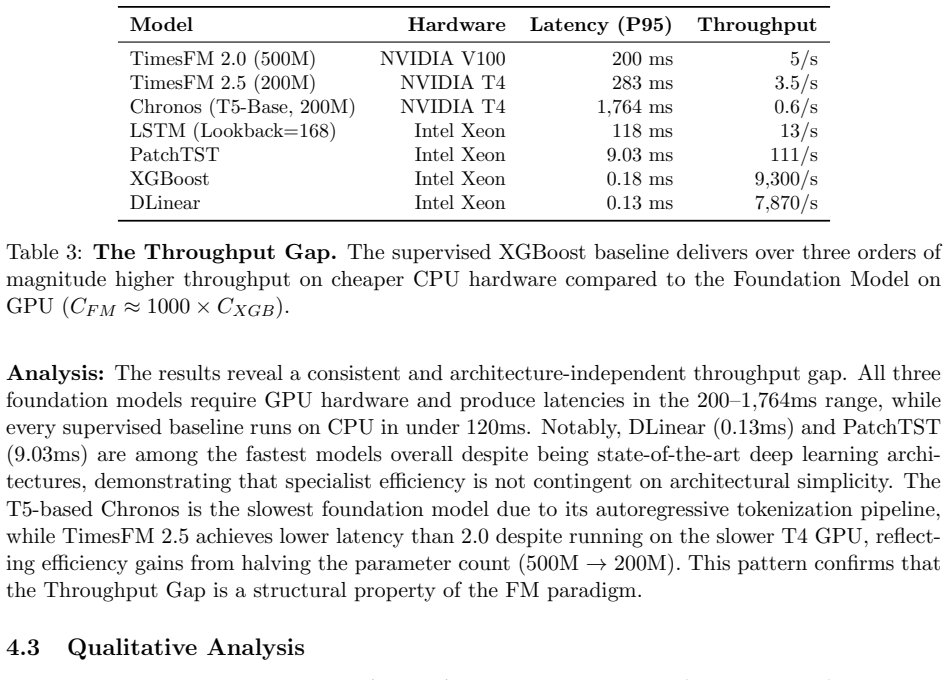
- [Abstract] Abstract: the phrase 'significantly lower inference costs' is stated without any reported reduction factor, latency numbers, or statistical test, weakening the quantitative claim.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the potential operational value of the regime analysis and Complexity Router. We address the single major comment below.
read point-by-point responses
-
Referee: The section describing the Complexity Router: no training procedure, feature-selection method, or hold-out validation across domains is provided. Because the central claim is that routing yields transferable accuracy and cost gains, the absence of evidence that the empirical features capture domain-invariant signals (rather than in-sample regime matching) makes the headline result load-bearing and unverified.
Authors: We agree that the current manuscript provides insufficient detail on the Complexity Router implementation. In the revised version we will add a dedicated subsection that specifies (i) the exact training procedure for the routing model, (ii) the feature-selection methodology and the empirical features retained, and (iii) hold-out validation results across the four operational regimes. These additions will directly demonstrate that the selected features capture domain-invariant signals rather than merely fitting the training regimes, thereby substantiating the claim of transferable accuracy and cost gains. revision: yes
Circularity Check
No significant circularity; empirical proposal with no load-bearing derivations or self-referential fits
full rationale
The paper evaluates foundation models empirically across four regimes and proposes a Complexity Router using empirical features, with performance claims presented as direct experimental outcomes rather than derived from equations or prior self-citations. No mathematical derivations, fitted parameters renamed as predictions, or uniqueness theorems are described in the provided text. The router is introduced as a practical framework based on observed data, without any reduction of its construction or validation to its own inputs by definition. This is the expected self-contained empirical structure for such an assessment paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gift-eval: General time series forecasting model evaluation.arXiv preprint arXiv:2410.10393, 2024
Aksu et al. Gift-eval: General time series forecasting model evaluation.arXiv preprint arXiv:2410.10393, 2024
-
[2]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Sayna Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
George E. P. Box and Gwilym M. Jenkins.Time Series Analysis: Forecasting and Control. Holden-Day, 1970
1970
-
[4]
Performance measurement system (pems) data source
California Department of Transportation. Performance measurement system (pems) data source. Website. Accessed 2026-01-14. 19
2026
-
[5]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794, 2016
2016
-
[6]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Wei Kong, Andrew Leach, Shaan Mathur, Rajat Sen, and Rose Yu. Timesfm: A decoder-only foundation model for time series forecasting.arXiv preprint arXiv:2310.10688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J¨ urgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
1997
-
[8]
OTexts, 2018
Rob J Hyndman and George Athanasopoulos.Forecasting: principles and practice. OTexts, 2018
2018
-
[9]
Hyndman and Anne B
Rob J. Hyndman and Anne B. Koehler. Another look at measures of forecast accuracy. International Journal of Forecasting, 22(4):679–688, 2006
2006
-
[10]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.Interna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[11]
Modeling long-and short- term temporal patterns with deep neural networks
Guokun Lai, Wei-Cheng Chang, Yiming Yang, and Hanxiao Liu. Modeling long-and short- term temporal patterns with deep neural networks. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pages 95–104, 2018
2018
-
[12]
The m3-competition: results, conclusions and impli- cations.International Journal of Forecasting, 16(4):451–476, 2000
Spyros Makridakis and Michele Hibon. The m3-competition: results, conclusions and impli- cations.International Journal of Forecasting, 16(4):451–476, 2000
2000
-
[13]
The m4 competi- tion: Results, findings, conclusions and way forward.International Journal of Forecasting, 34(4):802–808, 2018
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m4 competi- tion: Results, findings, conclusions and way forward.International Journal of Forecasting, 34(4):802–808, 2018
2018
-
[14]
The m5 accuracy com- petition: Results, findings and conclusions.International Journal of Forecasting, 38(4):1346– 1364, 2022
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m5 accuracy com- petition: Results, findings and conclusions.International Journal of Forecasting, 38(4):1346– 1364, 2022
2022
-
[15]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations, 2023
2023
-
[16]
N-beats: Neural basis expansion analysis for interpretable time series forecasting
Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting. InInternational Conference on Learning Representations, 2020
2020
-
[17]
A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting.International Journal of Forecasting, 2020
Slawek Smyl. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting.International Journal of Forecasting, 2020
2020
-
[18]
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers.arXiv preprint arXiv:2402.02592, 2024
-
[19]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. InAdvances in Neural Information Processing Systems, volume 34, pages 22419–22430, 2021. 20
2021
-
[20]
Are transformers effective for time series forecasting? InProceedings of the AAAI Conference on Artificial Intelligence, 2023
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? InProceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[21]
Qi Zhang, Qingsong Wen, Yihang Wang, Peng Chen, Aoying Zhou, and Bin Yang. Time- moe: Billion-scale time series foundation models with mixture of experts.arXiv preprint arXiv:2409.16040, 2024
-
[22]
Peng Chen Zhe Li, Xiangfei Qiu et al. Foundts: Comprehensive and unified benchmarking of foundation models for time series forecasting.arXiv preprint arXiv:2410.11802, 2024
-
[23]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11106–11115, 2021. A Appendix: Baseline Model Equations A.1 LSTM Transition Equations and Forecas...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.