LLM Consortium for Software Design Refinement: A Controlled Experiment on Multi-Agent Collaboration Topologies
Pith reviewed 2026-06-28 16:11 UTC · model grok-4.3
The pith
A structural adversarial multi-agent topology produces the highest-rated software designs among twelve LLM collaboration structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
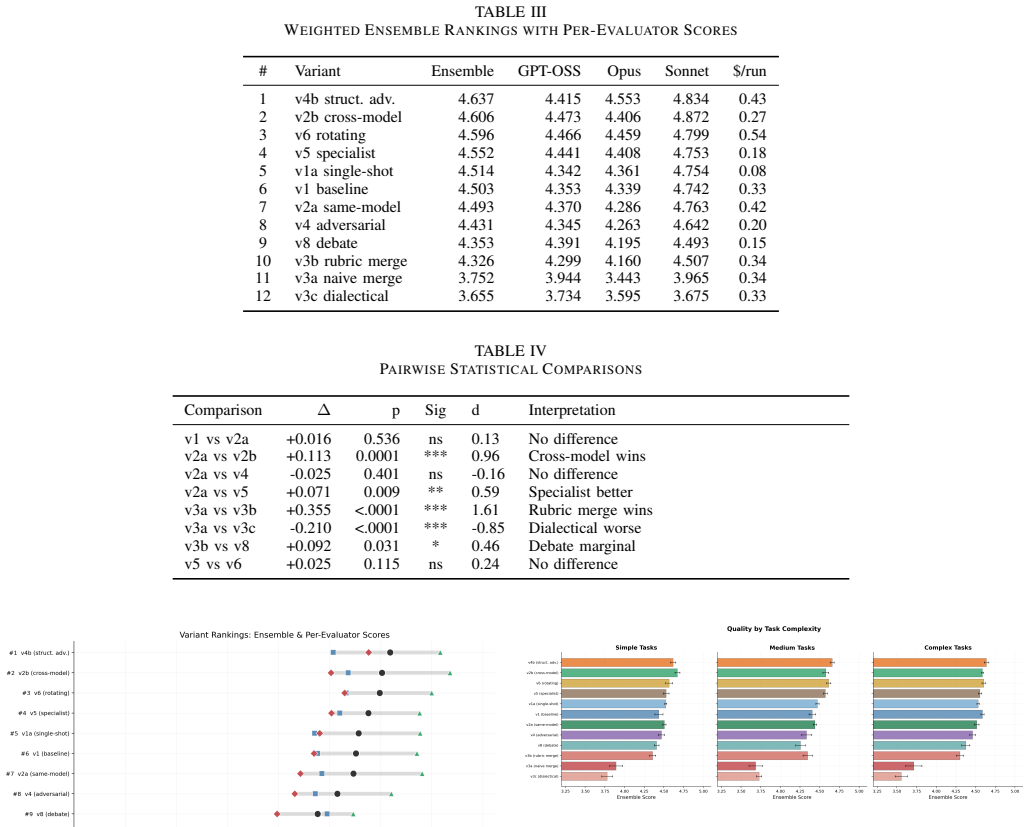
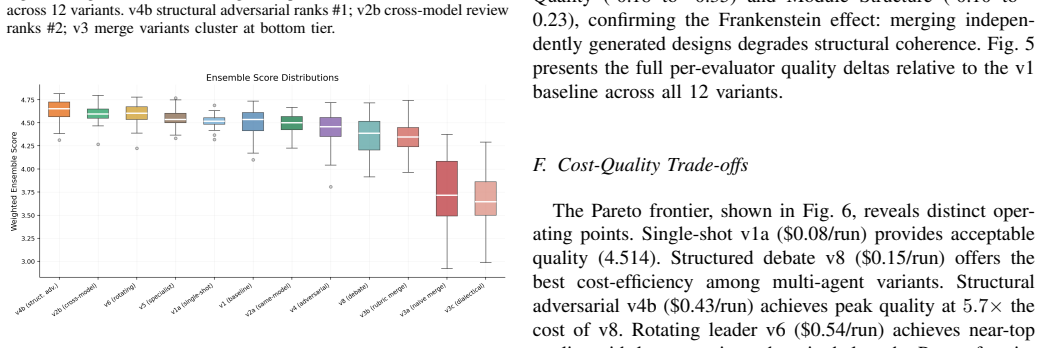
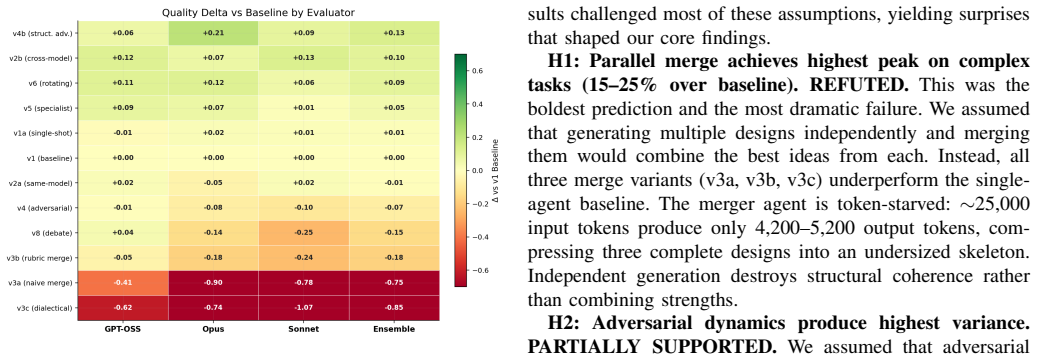
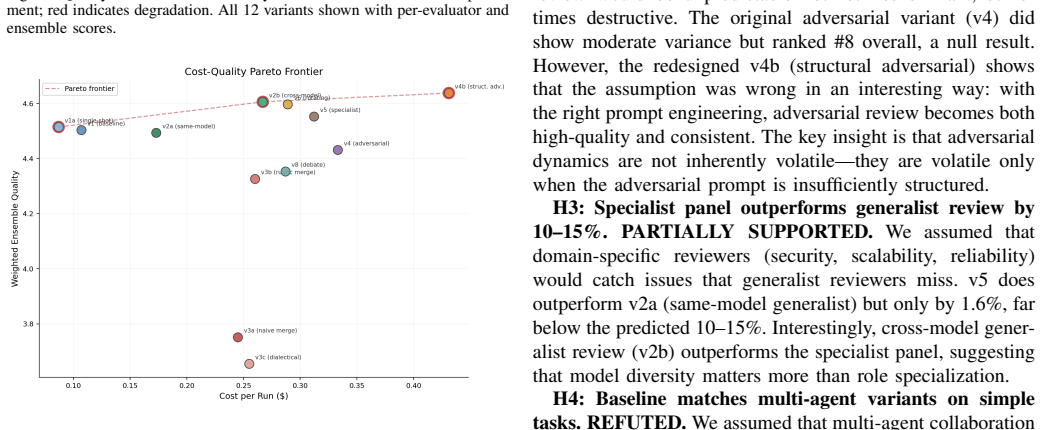
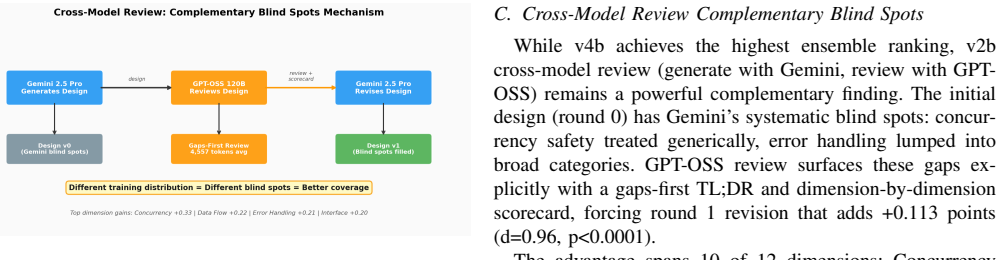
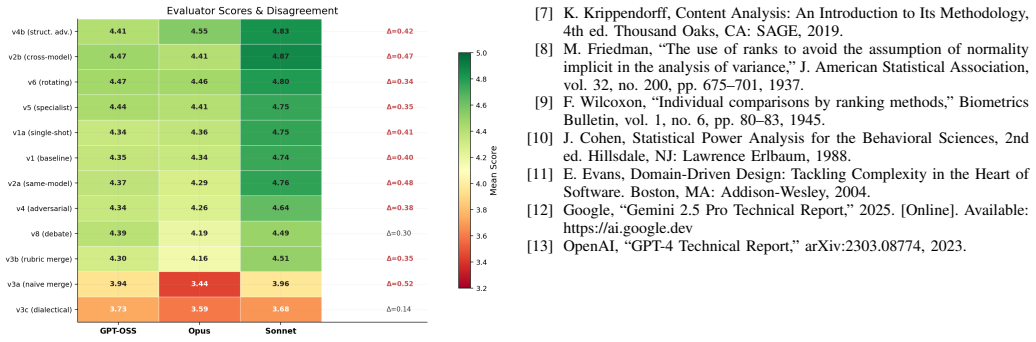
The paper establishes that in a 2×2×2 factorial experiment with 520 runs on eight design tasks, the structural adversarial topology v4b achieves the top weighted ensemble score of 4.637/5.0 on a 12-dimensional rubric, ahead of cross-model review at 4.606, while all three evaluators place parallel merge variants in the bottom tier at 3.65-3.79 due to token starvation and the Frankenstein effect.
What carries the argument
Structural adversarial topology v4b, a prompt-engineered multi-agent structure that requires complete rewrites rather than incremental patches during software design refinement.
If this is right
- Structural adversarial topologies with rewrite mandates improve design quality over cooperative or merge-based structures.
- Cross-model review, using separate models for generation and review, delivers consistently high performance across evaluators.
- Parallel merge topologies produce lower-quality outputs due to token limits and inconsistent combined designs.
- Different evaluator models agree on the best and worst topologies but can disagree on middle-ranked ones.
- A weighted ensemble of multiple evaluator models supplies stable rankings across repeated trials.
Where Pith is reading between the lines
- The absence of human expert validation on the rubric means the reported quality differences could partly reflect evaluator model preferences rather than objective design merit.
- The same collaboration structures might be tested on non-software tasks such as generating business requirements or technical specifications to check if the ranking pattern holds.
- Adding a human-in-the-loop step to the top-performing topologies could produce further gains beyond the fully automated setting.
- Repeating the experiment with a broader set of base models or larger design tasks could shift the relative performance of the twelve topologies.
Load-bearing premise
The 12-dimensional rubric applied by GPT-OSS 120B, Claude Opus 4.6, and Claude Sonnet 4.6 produces valid and unbiased assessments of software design quality without human validation.
What would settle it
A follow-up study in which human software architects rate the same set of generated designs and check whether the ranking order still places v4b first.
Figures


read the original abstract
We present a controlled experiment evaluating 12 multi-agent LLM collaboration topologies for software architecture design. Using a $2\times2\times2$ factorial design (Authority $\times$ Roles $\times$ Dynamics), we conducted 520 experimental runs across 8 design tasks of varying complexity, with 5 repetitions each. Designs were evaluated on a 12-dimensional rubric by three independent automated evaluators (GPT-OSS 120B, Claude Opus 4.6, Claude Sonnet 4.6). We report four core findings. First, structural adversarial (v4b) ranks #1 by ensemble -- a prompt-engineered adversarial variant that demands rewrite mandates rather than patches (weighted ensemble: 4.637/5.0). Second, cross-model review wins unanimously at #2 -- generate with one model, review with another -- ranking #2 by all three evaluators (weighted ensemble: 4.606). Third, evaluator diversity is itself a finding -- all three evaluators agree v4b is best and v3 is worst, but disagree sharply on v2b (Claude d=1.44 vs. GPT-OSS d=0.45), revealing how different model families weight design qualities. Fourth, parallel merge is fundamentally broken -- all three evaluators place merge variants in the bottom tier (3.65-3.79), due to token starvation and the Frankenstein effect. The weighted ensemble ($2\times$Opus + $2\times$Sonnet + $1\times$GPT-OSS) provides robust rankings across 520 runs, confirmed through independent cross-validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a controlled experiment evaluating 12 multi-agent LLM collaboration topologies for software architecture design. Employing a 2×2×2 factorial design (Authority × Roles × Dynamics), it performs 520 runs across 8 tasks with 5 repetitions, scoring outputs via a 12-dimensional rubric applied by three LLM evaluators (GPT-OSS 120B, Claude Opus 4.6, Claude Sonnet 4.6). Key findings include the structural adversarial topology (v4b) ranking first with weighted ensemble score 4.637/5.0, cross-model review second at 4.606, evaluator diversity effects, and parallel merge topologies performing poorly due to token starvation and Frankenstein effect.
Significance. Should the LLM-based rubric prove to be a reliable proxy for software design quality, this work provides substantial empirical evidence on the effectiveness of different multi-agent collaboration structures. Strengths include the large scale of 520 runs, the factorial design allowing isolation of factors, and the use of multiple independent evaluators which highlights disagreements and provides a weighted ensemble. The findings on adversarial prompting and cross-model review could guide practical implementations in LLM-based software engineering tools.
major comments (3)
- [Evaluation Methodology] Evaluation Methodology: The 12-dimensional rubric is applied solely by three LLMs without any reported human-expert calibration, inter-rater reliability statistics, or validation against external ground truth. This is load-bearing for all ranking claims, including v4b at 4.637/5.0 and the identification of merge variants as broken (3.65-3.79), as differences may reflect model biases rather than design quality.
- [Task Selection and Experimental Design] Task Selection: Details on the criteria for selecting the 8 design tasks, their specific complexity levels, and how they represent varying software architecture challenges are not provided. This affects the generalizability of the topology rankings across the 520 runs.
- [Results and Statistical Analysis] Results: The paper reports rankings and some differences (e.g., d=1.44 vs. d=0.45 on v2b) but lacks description of statistical tests used to confirm significance of differences between topologies or methods for aggregating or handling disagreements among the three evaluators in the weighted ensemble (2×Opus + 2×Sonnet + 1×GPT-OSS).
minor comments (1)
- [Abstract] The abstract mentions 'confirmed through independent cross-validation' but the full text should clarify what this cross-validation entails to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Evaluation Methodology] Evaluation Methodology: The 12-dimensional rubric is applied solely by three LLMs without any reported human-expert calibration, inter-rater reliability statistics, or validation against external ground truth. This is load-bearing for all ranking claims, including v4b at 4.637/5.0 and the identification of merge variants as broken (3.65-3.79), as differences may reflect model biases rather than design quality.
Authors: We agree this is a substantive limitation. The LLM evaluators were selected to support the scale of 520 runs, which would be infeasible with human raters. In revision we will add an 'Evaluator Agreement' subsection reporting pairwise correlations and agreement metrics across the three models. We will also expand the limitations section to explicitly note the lack of human calibration and the possibility of model-specific biases influencing rankings. The weighted ensemble (2×Opus + 2×Sonnet + 1×GPT-OSS) was intended to reduce single-model bias, but we will clarify this rationale. revision: partial
-
Referee: [Task Selection and Experimental Design] Task Selection: Details on the criteria for selecting the 8 design tasks, their specific complexity levels, and how they represent varying software architecture challenges are not provided. This affects the generalizability of the topology rankings across the 520 runs.
Authors: We will revise the 'Experimental Tasks' section to specify selection criteria, including domain coverage (web services, distributed systems, embedded control) and complexity metrics (component count, interaction density). Brief descriptions of each task will be added to demonstrate how they span the range of architecture challenges. revision: yes
-
Referee: [Results and Statistical Analysis] Results: The paper reports rankings and some differences (e.g., d=1.44 vs. d=0.45 on v2b) but lacks description of statistical tests used to confirm significance of differences between topologies or methods for aggregating or handling disagreements among the three evaluators in the weighted ensemble (2×Opus + 2×Sonnet + 1×GPT-OSS).
Authors: We will insert a 'Statistical Analysis' subsection describing the tests (repeated-measures ANOVA across tasks with post-hoc Tukey HSD and effect-size reporting) used to assess topology differences. The ensemble aggregation method will be detailed, including the rationale for the 2:2:1 weighting and how per-evaluator scores were combined. The cross-validation mentioned in the abstract will be expanded to clarify the hold-out procedure used to verify ranking stability. revision: yes
Circularity Check
No circularity: purely empirical reporting of experimental outcomes
full rationale
The paper describes a controlled factorial experiment with 520 runs, direct rubric scoring by three LLMs, and reporting of resulting rankings via a fixed weighted ensemble. No derivations, equations, fitted parameters, or predictions are present that could reduce outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The central claims are observational results from the described protocol, making the work self-contained with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automated evaluators (GPT-OSS 120B, Claude Opus 4.6, Claude Sonnet 4.6) using a 12-dimensional rubric produce reliable rankings of software design quality
Reference graph
Works this paper leans on
-
[1]
ChatDev: Communicative Agents for Software Development
T. Qin et al., “ChatDev: Communicative agents for software develop- ment,” arXiv:2307.07924, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Hong et al., “MetaGPT: Meta programming for multi-agent collabo- rative framework,” arXiv:2308.00352, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
M. Huang et al., “AgentCoder: Multi-agent code generation with iterative testing and optimization,” arXiv:2312.13010, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
MapCoder: Multi-agent code generation for competitive programming,
M. Islam et al., “MapCoder: Multi-agent code generation for competitive programming,” arXiv:2405.11403, 2024
-
[5]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Y . Du et al., “Improving factuality and reasoning in language models through multiagent debate,” arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
T. Liang et al., “Encouraging divergent thinking in large language models through multi-agent debate,” arXiv:2305.19118, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Krippendorff, Content Analysis: An Introduction to Its Methodology, 4th ed
K. Krippendorff, Content Analysis: An Introduction to Its Methodology, 4th ed. Thousand Oaks, CA: SAGE, 2019
2019
-
[8]
The use of ranks to avoid the assumption of normality implicit in the analysis of variance,
M. Friedman, “The use of ranks to avoid the assumption of normality implicit in the analysis of variance,” J. American Statistical Association, vol. 32, no. 200, pp. 675–701, 1937
1937
-
[9]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods,” Biometrics Bulletin, vol. 1, no. 6, pp. 80–83, 1945
1945
-
[10]
Cohen, Statistical Power Analysis for the Behavioral Sciences, 2nd ed
J. Cohen, Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Hillsdale, NJ: Lawrence Erlbaum, 1988
1988
-
[11]
Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software
E. Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software. Boston, MA: Addison-Wesley, 2004
2004
-
[12]
Gemini 2.5 Pro Technical Report,
Google, “Gemini 2.5 Pro Technical Report,” 2025. [Online]. Available: https://ai.google.dev
2025
-
[13]
OpenAI, “GPT-4 Technical Report,” arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.