Beyond Global Divergences: A Local-Mass Perspective on Bayesian Inference
Pith reviewed 2026-06-26 02:27 UTC · model grok-4.3
The pith
Bayesian updating changes local small-ball mass through explicit likelihood factors and support adjustments in ways global divergences miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
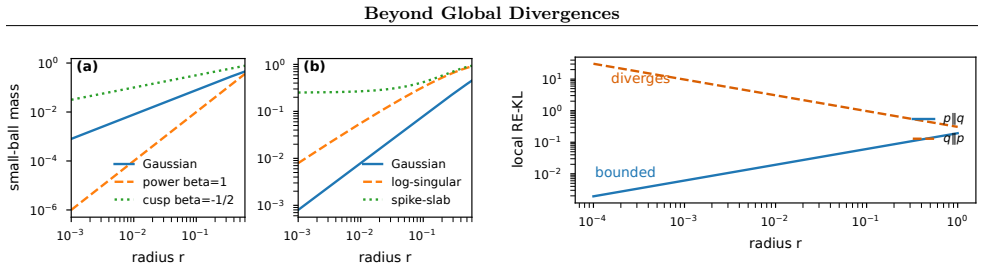
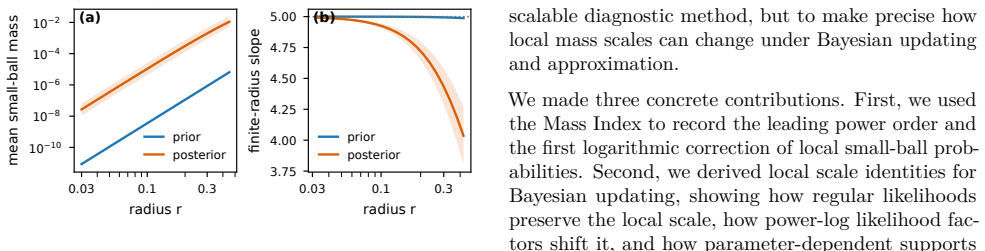
Mass Indices characterise how Bayesian updating changes local mass through power-log likelihood factors that shift it explicitly and through parameter-dependent supports that change the local scale by the amount of mass remaining near the parameter value. Using local RE-KL, absolute, relative, and directional inequalities are proved for comparing local small-ball masses under the two KL directions.
What carries the argument
Mass Index, which records the polynomial and logarithmic decay scales of local mass, together with regularised extended KL (RE-KL), a set-localised divergence that can be defined even with singular components.
If this is right
- Power-log likelihood factors shift local mass explicitly.
- Parameter-dependent supports or their smooth softenings change the local scale through the amount of mass that remains near the parameter value.
- Local RE-KL yields absolute, relative, and directional inequalities for comparing local small-ball masses under the two KL directions.
- Experiments supply controlled illustrations of how these local changes appear in practice.
Where Pith is reading between the lines
- The same local-mass lens could be used to compare variational approximations that match globally but diverge inside particular high-density regions.
- Mass Index values might serve as a diagnostic for when a model’s support choices are likely to distort inference on subsets of the data.
- Extending the inequalities to other local divergences could link the framework to existing analyses of concentration and tail behaviour.
Load-bearing premise
The local-mass behaviour not captured by global objectives is both measurable with the introduced Mass Index and RE-KL and relevant to the performance of Bayesian inference procedures.
What would settle it
A controlled example in which local mass scales change measurably under updating yet produce no detectable difference in posterior accuracy or predictive behaviour on held-out points near the parameter of interest.
Figures
read the original abstract
Global objectives, such as KL divergence and ELBO, are widely used in Bayesian inference for measuring distributional discrepancy. This paper studies their local-mass behaviour that is not directly captured by such objectives. We introduce and use two mathematical tools: (1) Mass Index for recording the polynomial and logarithmic decay scales of local mass, and (2) regularised extended KL (RE-KL), a set-localised divergence that can be formulated in the presence of singular components. Mass Indices help characterise how Bayesian updating changes local mass: (1) power-log likelihood factors shift it explicitly, and (2) parameter-dependent supports, or their smooth softenings, may change the local scale through the amount of mass that remains near the parameter value. Using local RE-KL, we prove absolute, relative, and directional inequalities for comparing local small-ball masses under the two KL directions. Together, these results provide a local theoretical account of local mass behaviour. Experiments provide controlled illustrations of the local behaviour. Code is available at https://github.com/Forsythia0604/Local-Mass-Framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Mass Index to record polynomial and logarithmic decay scales of local mass and the regularised extended KL (RE-KL) divergence as a set-localised measure that accommodates singular components. It shows how Bayesian updating alters local mass via power-log likelihood factors and parameter-dependent supports (or their smoothings), then uses local RE-KL to prove absolute, relative, and directional inequalities comparing local small-ball masses under the two KL directions. Controlled experiments illustrate the local behaviour, with code released.
Significance. If the inequalities hold, the work supplies a local theoretical account of mass behaviour that is not directly captured by global objectives such as KL or ELBO. The explicit handling of singular components and the provision of reproducible code are strengths that support verifiability.
minor comments (3)
- [Abstract] Abstract: the sentence on 'power-log likelihood factors' and 'parameter-dependent supports' could be expanded with a brief parenthetical example to clarify the two mechanisms before the inequalities are stated.
- [Experiments] The experiments section states that the illustrations are 'controlled'; adding a short table or paragraph mapping each figure to the corresponding inequality (absolute/relative/directional) would improve traceability.
- [§2] Notation: the definition of the Mass Index (presumably in §2) uses both polynomial and logarithmic scales; a single displayed equation collecting the two cases would reduce ambiguity when the index is later invoked in the proofs.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its contributions regarding local mass behaviour, handling of singular components, and the release of reproducible code. The recommendation for minor revision is noted.
Circularity Check
No significant circularity detected
full rationale
The derivation introduces Mass Index and RE-KL as new constructs, then proves absolute/relative/directional inequalities relating local small-ball masses. No quoted step reduces a claimed result to a fitted parameter, self-definition, or self-citation chain; the inequalities are presented as following from the definitions of the new tools. The framework is mathematically self-contained against external benchmarks and does not rename known results or smuggle ansatzes via citation. This is the normal case of an independent theoretical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of probability measures and KL divergence hold for the local small-ball setting.
invented entities (2)
-
Mass Index
no independent evidence
-
RE-KL divergence
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On lo- cal divergences between two probability measures
G Avlogiaris, A Micheas, and K Zografos. On lo- cal divergences between two probability measures. Metrika, 79(3):303–333, 2016
2016
-
[2]
Minimum hellinger distance es- timates for parametric models.The annals of Statistics, pages 445–463, 1977
Rudolf Beran. Minimum hellinger distance es- timates for parametric models.The annals of Statistics, pages 445–463, 1977
1977
-
[3]
John Wiley & Sons, 2013
PatrickBillingsley.Convergence of probability mea- sures. John Wiley & Sons, 2013
2013
-
[4]
Cambridge university press, 1989
Nicholas H Bingham, Charles M Goldie, and Jef L Teugels.Regular variation, volume 27. Cambridge university press, 1989
1989
-
[5]
Variational inference: A review for statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
2017
-
[6]
Bayesian linear regression with Hanli Xu, F engxiang He, Sarat Moka sparse priors.The Annals of Statistics, 43(5):1986– 2018, 2015
Ismaël Castillo, Johannes Schmidt-Hieber, and Aad van der Vaart. Bayesian linear regression with Hanli Xu, F engxiang He, Sarat Moka sparse priors.The Annals of Statistics, 43(5):1986– 2018, 2015
1986
-
[7]
Wiley Chichester, 1997
Kenneth J Falconer and KJ Falconer.Techniques in fractal geometry, volume 3. Wiley Chichester, 1997
1997
-
[8]
John Wiley & Sons, 1999
Gerald B Folland.Real analysis: modern tech- niques and their applications. John Wiley & Sons, 1999
1999
-
[9]
Ober, Florian Wenzel, Gunnar Ratsch, Richard E Turner, Mark van der Wilk, and Lau- rence Aitchison
Vincent Fortuin, Adrià Garriga-Alonso, Sebas- tian W. Ober, Florian Wenzel, Gunnar Ratsch, Richard E Turner, Mark van der Wilk, and Lau- rence Aitchison. Bayesian neural network priors revisited. InInternational Conference on Learning Representations, 2022
2022
-
[10]
Convergence rates of posterior distributions.Annals of Statistics, pages 500–531, 2000
Subhashis Ghosal, Jayanta K Ghosh, and Aad W Van Der Vaart. Convergence rates of posterior distributions.Annals of Statistics, pages 500–531, 2000
2000
-
[11]
Model selection in bayesian neural networks via horseshoe priors.Journal of Machine Learning Research, 20(182):1–46, 2019
Soumya Ghosh, Jiayu Yao, and Finale Doshi-Velez. Model selection in bayesian neural networks via horseshoe priors.Journal of Machine Learning Research, 20(182):1–46, 2019
2019
-
[12]
Dimension of measures: the probabilistic approach.Publicacions Matemà- tiques, 51(2):243–290, 2007
Yanick Heurteaux. Dimension of measures: the probabilistic approach.Publicacions Matemà- tiques, 51(2):243–290, 2007
2007
-
[13]
Asymp- totic efficiency in parametric structural models with parameter-dependent support.Econometrica, 71(5):1307–1338, 2003
Keisuke Hirano and Jack R Porter. Asymp- totic efficiency in parametric structural models with parameter-dependent support.Econometrica, 71(5):1307–1338, 2003
2003
-
[14]
Sur un mode de croissance régulière des fonctions.Mathematica (Cluj), 4:38– 53, 1930
Jovan Karamata. Sur un mode de croissance régulière des fonctions.Mathematica (Cluj), 4:38– 53, 1930
1930
-
[15]
Sur un mode de croissance régulière
Jovan Karamata. Sur un mode de croissance régulière. théorèmes fondamentaux.Bulletin de la Société Mathématique de France, 61:55–62, 1933
1933
-
[16]
Auto- encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Diederik P Kingma and Max Welling. Auto- encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[17]
On information and sufficiency.The annals of mathe- matical statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The annals of mathe- matical statistics, 22(1):79–86, 1951
1951
-
[18]
Rényi Diver- gence Variational Inference
Yingzhen Li and Richard Turner. Rényi Diver- gence Variational Inference. InAdvances in Neural Information Processing Systems, volume 29. Cur- ran Associates, Inc., 2016
2016
-
[19]
Pacgan: The power of two samples in generative adversarial networks.Advances in neural information processing systems, 31, 2018
Zinan Lin, Ashish Khetan, Giulia Fanti, and Se- woong Oh. Pacgan: The power of two samples in generative adversarial networks.Advances in neural information processing systems, 31, 2018
2018
-
[20]
Bayesian compression for deep learning
Christos Louizos, Karen Ullrich, and Max Welling. Bayesian compression for deep learning. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wal- lach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Process- ing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[21]
Cambridge University Press, Cambridge, 1999
Pertti Mattila.Geometry of sets and measures in Euclidean spaces: fractals and rectifiability, vol- ume 44 ofCambridge Studies in Advanced Mathe- matics. Cambridge University Press, Cambridge, 1999
1999
-
[22]
Sequential Monte Carlo for Inclusive KL Minimization in Amortized Variational Inference
Declan McNamara, Jackson Loper, and Jeffrey Regier. Sequential Monte Carlo for Inclusive KL Minimization in Amortized Variational Inference. InProceedings of The 27th International Confer- ence on Artificial Intelligence and Statistics, pages 4312–4320. PMLR, April 2024
2024
-
[23]
Thomas P. Minka. Divergence measures and mes- sage passing. Technical Report MSR-TR-2005-173, Microsoft Research, 2005
2005
-
[24]
Markovian score climbing: Variational infer- ence with kl (p|| q).Advances in Neural Informa- tion Processing Systems, 33:15499–15510, 2020
Christian Naesseth, Fredrik Lindsten, and David Blei. Markovian score climbing: Variational infer- ence with kl (p|| q).Advances in Neural Informa- tion Processing Systems, 33:15499–15510, 2020
2020
-
[25]
On the es- timation ofα-divergences
Barnabás Póczos and Jeff Schneider. On the es- timation ofα-divergences. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pages 609–617. JMLR Workshop and Conference Proceedings, 2011
2011
-
[26]
Poste- rior Concentration for Sparse Deep Learning
Nicholas G Polson and Veronika Ročková. Poste- rior Concentration for Sparse Deep Learning. In Advances in Neural Information Processing Sys- tems, volume 31. Curran Associates, Inc., 2018
2018
-
[27]
van der Vaart and J
Aad W. van der Vaart and J. Harry van Zan- ten. Rates of contraction of posterior distributions based on gaussian process priors.The Annals of Statistics, 36(3):1435–1463, 2008
2008
-
[28]
F-divergence variational inference.Advances in neural information processing systems, 33:17370– 17379, 2020
Neng Wan, Dapeng Li, and Naira Hovakimyan. F-divergence variational inference.Advances in neural information processing systems, 33:17370– 17379, 2020
2020
-
[29]
Variational f-divergence Minimization, December 2024
Mingtian Zhang, Thomas Bird, Raza Habib, Tian- lin Xu, and David Barber. Variational f-divergence Minimization, December 2024. arXiv:1907.11891 [stat.ML]. Beyond Global Divergences
arXiv 2024
-
[30]
Rethinking generative mode coverage: A pointwise guaranteed approach
Peilin Zhong, Yuchen Mo, Chang Xiao, Pengyu Chen, and Changxi Zheng. Rethinking generative mode coverage: A pointwise guaranteed approach. Advances in Neural Information Processing Sys- tems, 32, 2019. Hanli Xu, F engxiang He, Sarat Moka A Examples and Counterexamples Example A.1(Oscillating small-ball order).This example shows why the upper and lower Pow...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.