The Simulacrum: Decision-Theoretic Pretraining for Near-Optimal Time-Series Forecasting and Inference
Pith reviewed 2026-06-29 04:24 UTC · model grok-4.3
The pith
Neural networks trained on simulations from a specified generative world approximate optimal time series estimators that outperform maximum likelihood and AICc.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
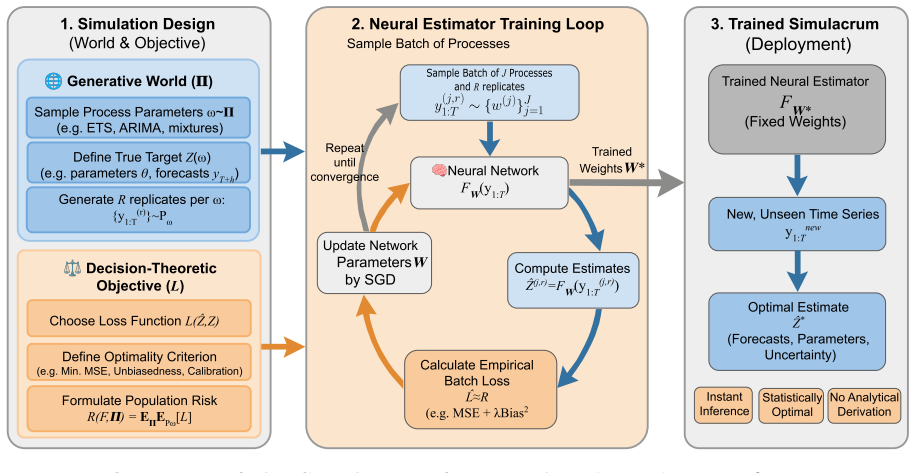
By jointly specifying a generative world, a distribution over data-generating processes, and a decision objective, then training a neural network on simulations from that world, the resulting neural estimator approximates the optimal rule for the chosen objective, delivering forecasts, estimates, intervals, or selections with controlled finite-sample risk, bias, and calibration that traditional methods cannot achieve analytically.
What carries the argument
Decision-theoretic pretraining of a neural network on stratified simulations drawn from an analyst-specified generative world to approximate the optimal decision rule for a target objective.
If this is right
- For identical structural model classes, the neural estimators outperform maximum likelihood estimation and AICc model selection in targeted decision properties.
- Even when trained exclusively on simulations of structural models, the estimators reach competitive or state-of-the-art accuracy on major real-world forecasting benchmarks.
- The framework resolves finite-sample bias and miscalibration in AR(p) models by directly optimizing the relevant objective through simulation.
- It supplies a direct solution to the forecast combination puzzle by learning combination rules that optimize the chosen decision criterion.
- Complex structural equations or optimality criteria that lack analytic solutions become tractable because the neural network learns the mapping from data to decisions via simulation.
Where Pith is reading between the lines
- The same pretraining approach could be applied to other inference tasks outside time series if an appropriate generative world and objective can be simulated.
- When the analyst's generative world is misspecified relative to reality, the method may still be useful if combined with robustness checks or adaptive retraining on observed data.
- Analysts could encode domain-specific constraints or risk preferences directly into the objective function during pretraining to produce estimators aligned with those preferences.
- The framework suggests a route to creating families of estimators that share simulation data but differ in their decision objectives, enabling rapid switching among them at inference time.
Load-bearing premise
The generative world and objective chosen by the analyst are close enough to the true data-generating process that the neural estimator transfers to real data without major loss of its targeted decision properties.
What would settle it
On standard real-world time series benchmarks, the neural estimators trained on structural-model simulations show clearly higher forecast error or worse calibration than maximum likelihood estimation or AICc model selection for the same model classes.
Figures
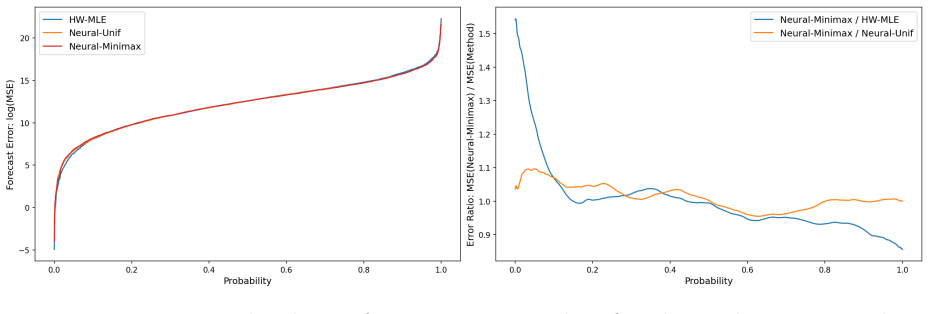
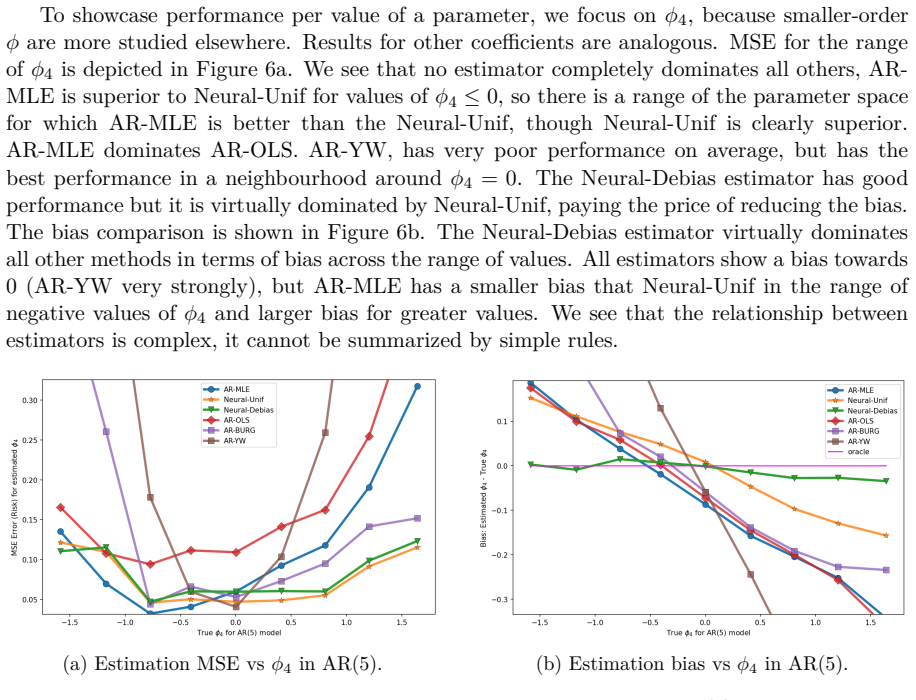
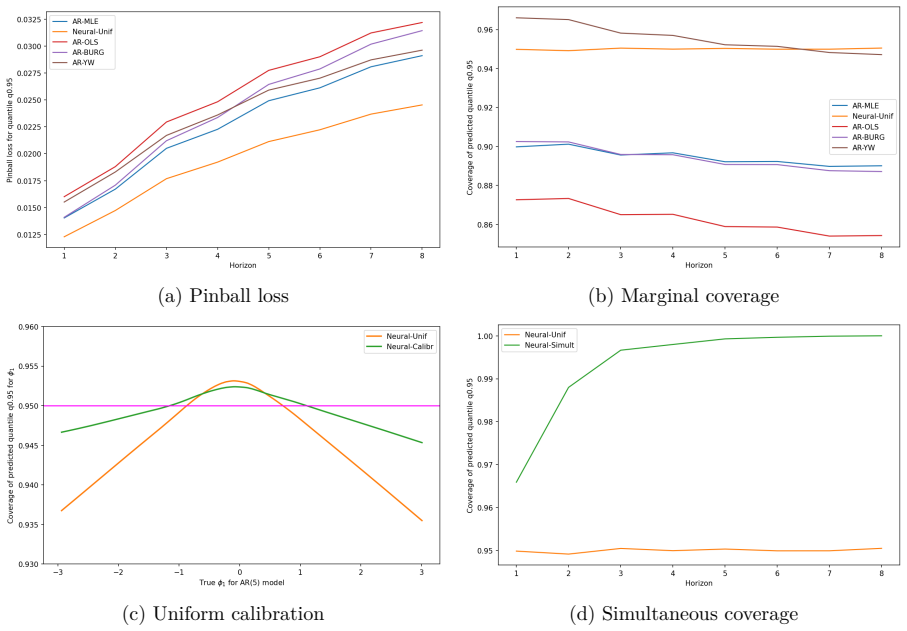
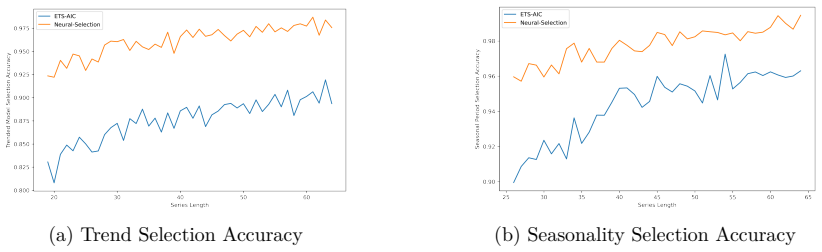
read the original abstract
We introduce a neural network-based framework for learning time series estimators through a process we term decision-theoretic pretraining. Analysts specify a generative world, a distribution over data-generating processes, and a target decision objective. A neural network trained on stratified simulations from this world approximates the corresponding optimal decision rule, yielding a neural estimator that provides forecasts, parameter estimates, predictive intervals, or model-selection for zero-shot inference on previously unseen time series. The joint specification of the generative world and objective enables the estimators to directly approximate process-level, finite-sample properties: near-optimal risk, bias control, minimax performance, and uniform calibration. Our experiments demonstrate that these neural estimators can outperform traditional baselines such as maximum likelihood estimation and model selection via AICc, for the same model structural model classes. Furthermore, even when trained purely on simulations of structural models, they achieve competitive or state-of-the-art forecasting accuracy on major real-world benchmarks, compared with statistical, neural or large pre-trained models. We illustrate the framework by addressing two longstanding challenges: finite-sample bias and miscalibration in AR(p) models, and the forecast combination puzzle. These applications highlight the approach's main advantage: its ability to approximate solutions to analytically intractable or computationally prohibitive time series problems, including complex structural equations or optimality criteria. Ultimately, by enabling explicit control over decision-theoretic trade-offs, the framework equips analysts with highly efficient estimation tools tailored to their specific analytical needs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a neural network framework for decision-theoretic pretraining in time-series analysis. Analysts define a generative distribution over data-generating processes and a target objective; the network is trained on simulations to approximate the optimal decision rule for tasks including forecasting, parameter estimation, and model selection. The authors claim that these estimators outperform maximum likelihood estimation and AICc-based selection for the same model classes and achieve competitive or state-of-the-art accuracy on real-world benchmarks, demonstrated on finite-sample bias in AR(p) models and the forecast combination puzzle.
Significance. Should the simulation-to-real transfer be validated, the framework would offer a powerful tool for approximating solutions to analytically intractable time-series problems by directly optimizing decision-theoretic criteria such as risk, bias, and calibration. This approach allows explicit control over the generative assumptions and objectives, potentially leading to estimators tailored to specific analytical needs beyond what traditional methods provide. The use of stratified simulations to target finite-sample properties is a notable strength if the transfer holds.
major comments (2)
- [Abstract] Abstract: The abstract asserts outperformance and SOTA-level accuracy but supplies no quantitative results, error bars, dataset details, or ablation controls. This makes it difficult to assess the strength of the claims without the full experimental section.
- [Experiments] Experiments section: The central claim that neural estimators trained on simulations achieve competitive real-benchmark accuracy rests on the untested assumption that finite-sample properties learned under the analyst-specified P_sim transfer to the unknown real P_real; no diagnostic, sensitivity analysis, or robustness check for closeness between the generative world and the true DGP is reported, which is load-bearing for the transfer claim.
minor comments (1)
- [Abstract] The repeated phrase 'structural model classes' in the abstract could be defined more precisely when first introduced in the methods.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. Their comments correctly identify areas where the presentation can be strengthened. We address each major comment below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts outperformance and SOTA-level accuracy but supplies no quantitative results, error bars, dataset details, or ablation controls. This makes it difficult to assess the strength of the claims without the full experimental section.
Authors: We agree that the abstract would be more informative with quantitative support. In the revised manuscript we will expand the abstract to report key metrics (e.g., finite-sample bias reduction versus MLE on AR(p), forecasting accuracy on the real benchmarks with standard errors, and the specific datasets used) while remaining within length limits. revision: yes
-
Referee: [Experiments] Experiments section: The central claim that neural estimators trained on simulations achieve competitive real-benchmark accuracy rests on the untested assumption that finite-sample properties learned under the analyst-specified P_sim transfer to the unknown real P_real; no diagnostic, sensitivity analysis, or robustness check for closeness between the generative world and the true DGP is reported, which is load-bearing for the transfer claim.
Authors: The referee is right that explicit transfer diagnostics are absent. The competitive real-benchmark results already constitute empirical evidence of transfer, since the networks are trained exclusively on simulations yet match or exceed SOTA on real data. Nevertheless, to address the concern directly we will add a dedicated sensitivity subsection that varies the stratification parameters of P_sim, reports performance under controlled misspecification, and evaluates robustness on data subsets. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines a procedure in which an analyst specifies a generative world and objective, generates simulations, and trains a neural network to approximate the Bayes-optimal decision rule under that measure. This approximation is not claimed to be optimal under the unknown real DGP; instead, the paper reports empirical performance on held-out real benchmarks. No equation reduces to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing step relies on a self-citation chain. The transfer from simulated to real measures is an explicit modeling assumption that is tested rather than derived, placing the work in the normal non-circular category.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A neural network can approximate the Bayes-optimal decision rule for the specified objective when trained on sufficiently rich stratified simulations from the generative world.
Reference graph
Works this paper leans on
-
[1]
GIFT-eval: A benchmark for general time series forecasting model evaluation
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. GIFT-eval: A benchmark for general time series forecasting model evaluation. InNeurIPS Workshop on Time Series in the Age of Large Models, 2024
2024
-
[2]
Maddix, Pablo Guerron, Tony Hu, Junming Yin, Nick Erickson, Prateek Mutalik Desai, Hao Wang, Huzefa Rangwala, George Karypis, Yuyang Wang, and Michael Bohlke-Schneider
Abdul Fatir Ansari, Oleksandr Shchur, Jaris Küken, Andreas Auer, Boran Han, Pedro Mer- cado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, Mononito Goswami, Shubham Kapoor, Danielle C. Maddix, Pablo Guerron, Tony Hu, Junming Yin, Nick Erickson, Prateek Mutalik Desai, Hao Wang, Huzefa Rangwala, George Karypis, Yuyang Wang, and Michael...
2025
-
[3]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000
Jonathan Baxter. A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000
2000
-
[5]
Basel framework: Mar32 — internal models approach: backtesting and p&l attribution test requirements.https://archive.is/XFzo6, 2023
BCBS. Basel framework: Mar32 — internal models approach: backtesting and p&l attribution test requirements.https://archive.is/XFzo6, 2023. Archived snapshot via archive.is. Original URL:https://www.bis.org/basel_framework/chapter/MAR/32. htm?inforce=20230101&published=20200327. Accessed 2025-11-21
2023
-
[6]
Springer Science & Business Media, 2013
James O Berger.Statistical decision theory and Bayesian analysis. Springer Science & Business Media, 2013
2013
-
[7]
Wai-Kwong Cheang and Gregory C Reinsel. Bias reduction of autoregressive estimates in time series regression model through restricted maximum likelihood.Journal of the American Statistical Association, 95(452):1173–1184, 2000
2000
-
[8]
Arima-plus: Large-scale, accurate, automatic and interpretable in-database time series forecasting and anomaly detection in google bigquery, 2025
Xi Cheng, Weijie Shen, Haoming Chen, Chaoyi Shen, Jean Ortega, Jiashang Liu, Steve Thomas, Honglin Zheng, Haoyun Wu, Yuxiang Li, Casey Lichtendahl, Jenny Ortiz, Gang Liu, Haiyang Qi, Omid Fatemieh, Chris Fry, and Jing Jing Long. Arima-plus: Large-scale, accurate, automatic and interpretable in-database time series forecasting and anomaly detection in goog...
2025
-
[9]
The forecast combination puzzle: A simple theoretical explanation.International Journal of Forecasting, 32(3):754–762, 2016
Gerda Claeskens, Jan R Magnus, Andrey L Vasnev, and Wendun Wang. The forecast combination puzzle: A simple theoretical explanation.International Journal of Forecasting, 32(3):754–762, 2016
2016
-
[10]
Combining forecasts: A review and annotated bibliography.Interna- tional journal of forecasting, 5(4):559–583, 1989
Robert T Clemen. Combining forecasts: A review and annotated bibliography.Interna- tional journal of forecasting, 5(4):559–583, 1989
1989
-
[11]
The frontier of simulation-based inference.Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference.Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020. 33
2020
-
[12]
A decoder-only founda- tion model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only founda- tion model for time-series forecasting. InForty-first International Conference on Machine Learning, 2024
2024
-
[13]
Emergent complexity and zero-shot transfer via unsuper- vised environment design.Advances in neural information processing systems, 33:13049– 13061, 2020
Michael Dennis, Natasha Jaques, Eugene Vinitsky, Alexandre Bayen, Stuart Russell, An- drew Critch, and Sergey Levine. Emergent complexity and zero-shot transfer via unsuper- vised environment design.Advances in neural information processing systems, 33:13049– 13061, 2020
2020
-
[14]
Forecastpfn: Synthetically-trained zero-shot forecasting.Advances in Neural Information Processing Systems, 36:2403–2426, 2023
Samuel Dooley, Gurnoor Singh Khurana, Chirag Mohapatra, Siddartha V Naidu, and Colin White. Forecastpfn: Synthetically-trained zero-shot forecasting.Advances in Neural Information Processing Systems, 36:2403–2426, 2023
2023
-
[15]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pages 1126–
-
[16]
Which moments to match?Econometric theory, 12(4):657–681, 1996
A Ronald Gallant and George Tauchen. Which moments to match?Econometric theory, 12(4):657–681, 1996
1996
-
[17]
Conditional neural processes
Marta Garnelo, Dan Rosenbaum, Christopher Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo Rezende, and SM Ali Eslami. Conditional neural processes. InInternational conference on machine learning, pages 1704–1713. PMLR, 2018
2018
-
[18]
Amortized inference in probabilistic reasoning
Samuel Gershman and Noah Goodman. Amortized inference in probabilistic reasoning. In Proceedings of the annual meeting of the cognitive science society, volume 36, 2014
2014
-
[19]
Adaptive conformal inference under distribution shift
Isaac Gibbs and Emmanuel Candes. Adaptive conformal inference under distribution shift. Advances in Neural Information Processing Systems, 34:1660–1672, 2021
2021
-
[20]
Making and evaluating point forecasts.Journal of the American Sta- tistical Association, 106(494):746–762, 2011
Tilmann Gneiting. Making and evaluating point forecasts.Journal of the American Sta- tistical Association, 106(494):746–762, 2011
2011
-
[21]
Tilmann Gneiting, Fadoua Balabdaoui, and Adrian E. Raftery. Probabilistic forecasts, calibration and sharpness.Journal of the Royal Statistical Society Series B: Statistical Methodology, 69(2):243–268, 04 2007
2007
-
[22]
Webb, Rob J
Rakshitha Godahewa, Christoph Bergmeir, Geoffrey I. Webb, Rob J. Hyndman, and Pablo Montero-Manso. Monash time series forecasting archive. InNeural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[23]
The art of SLOs handbook, 2025
Google. The art of SLOs handbook, 2025. Original URL:https: //static.googleusercontent.com/media/sre.google/en//static/pdf/ art-of-slos-handbook-a4.pdf
2025
-
[24]
Indirect inference.Journal of applied econometrics, 8(S1):S85–S118, 1993
Christian Gourieroux, Alain Monfort, and Eric Renault. Indirect inference.Journal of applied econometrics, 8(S1):S85–S118, 1993
1993
-
[25]
Automatic posterior trans- formation for likelihood-free inference
David Greenberg, Marcel Nonnenmacher, and Jakob Macke. Automatic posterior trans- formation for likelihood-free inference. InInternational conference on machine learning, pages 2404–2414. PMLR, 2019
2019
-
[26]
Individual versus social optimization in statistical estimation.Operations Research Letters, 61:107284, 2025
Moshe Haviv. Individual versus social optimization in statistical estimation.Operations Research Letters, 61:107284, 2025
2025
-
[27]
Global models for time series forecasting: A simulation study.Pattern Recognition, 124:108441, 2022
Hansika Hewamalage, Christoph Bergmeir, and Kasun Bandara. Global models for time series forecasting: A simulation study.Pattern Recognition, 124:108441, 2022. 34
2022
-
[28]
Bayesian model averaging: a tutorial (with comments by m
Jennifer A Hoeting, David Madigan, Adrian E Raftery, and Chris T Volinsky. Bayesian model averaging: a tutorial (with comments by m. clyde, david draper and ei george, and a rejoinder by the authors.Statistical science, 14(4):382–417, 1999
1999
-
[29]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[30]
From tables to time: Extending tabpfn-v2 to time series forecasting, 2026
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. From tables to time: Extending tabpfn-v2 to time series forecasting, 2026
2026
-
[31]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017
2017
-
[32]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992
1992
-
[33]
Automatic time series forecasting: the forecast package for r.Journal of statistical software, 27:1–22, 2008
Rob J Hyndman and Yeasmin Khandakar. Automatic time series forecasting: the forecast package for r.Journal of statistical software, 27:1–22, 2008
2008
-
[34]
A state space framework for automatic forecasting using exponential smoothing methods.International Journal of forecasting, 18(3):439–454, 2002
Rob J Hyndman, Anne B Koehler, Ralph D Snyder, and Simone Grose. A state space framework for automatic forecasting using exponential smoothing methods.International Journal of forecasting, 18(3):439–454, 2002
2002
-
[35]
Gratis: Generating time series with diverse and controllable characteristics.Statistical Analysis and Data Mining: The ASA Data Science Journal, 13(4):354–376, 2020
Yanfei Kang, Rob J Hyndman, and Feng Li. Gratis: Generating time series with diverse and controllable characteristics.Statistical Analysis and Data Mining: The ASA Data Science Journal, 13(4):354–376, 2020
2020
-
[36]
Small-sample confidence intervals for impulse response functions.Review of economics and statistics, 80(2):218–230, 1998
Lutz Kilian. Small-sample confidence intervals for impulse response functions.Review of economics and statistics, 80(2):218–230, 1998
1998
-
[37]
Regression quantiles.Econometrica: journal of the Econometric Society, pages 33–50, 1978
Roger Koenker and Gilbert Bassett Jr. Regression quantiles.Econometrica: journal of the Econometric Society, pages 33–50, 1978
1978
-
[38]
Spatial autocorrelation and autoregressive models in ecology.Ecological monographs, 72(3):445–463, 2002
Jeremy W Lichstein, Theodore R Simons, Susan A Shriner, and Kathleen E Franzreb. Spatial autocorrelation and autoregressive models in ecology.Ecological monographs, 72(3):445–463, 2002
2002
-
[39]
Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4):1748–1764, 2021
Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4):1748–1764, 2021
2021
-
[40]
The accuracy of extrapolation (time series) methods: Results of a forecasting competition.Journal of forecasting, 1(2):111–153, 1982
SpyrosMakridakis, AllanAndersen, RobertCarbone, RobertFildes, MicheleHibon, Rudolf Lewandowski, Joseph Newton, Emanuel Parzen, and Robert Winkler. The accuracy of extrapolation (time series) methods: Results of a forecasting competition.Journal of forecasting, 1(2):111–153, 1982
1982
-
[41]
The m4 competi- tion: Results, findings, conclusion and way forward.International Journal of forecasting, 34(4):802–808, 2018
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m4 competi- tion: Results, findings, conclusion and way forward.International Journal of forecasting, 34(4):802–808, 2018
2018
-
[42]
Bias in the estimation of autocorrelations.Biometrika, 41(3/4):390–402, 1954
FHC Marriott and JA Pope. Bias in the estimation of autocorrelations.Biometrika, 41(3/4):390–402, 1954. 35
1954
-
[43]
Big machine learning models that learn to estimate and forecast a class of autoregressive processes
Pablo Montero-Manso. Big machine learning models that learn to estimate and forecast a class of autoregressive processes. InBook of Abstracts of the 15th International Conference of the ERCIM WG on Computational and Methodological Statistics (CMStatistics 2022), London, UK, December 2022. Accessed via Internet Archive
2022
-
[44]
Large pre-trained models achieve near-optimal time series fore- casting
Pablo Montero-Manso. Large pre-trained models achieve near-optimal time series fore- casting. Presented at The Future of Forecasting and the M6 Competition Conference, November 2023
2023
-
[45]
Pre-trained deep networks outperform true models when predicting time series processes
Pablo Montero-Manso. Pre-trained deep networks outperform true models when predicting time series processes. InBook of Abstracts of the 43rd International Symposium on Fore- casting (ISF 2023), Charlottesville, VA, USA, June 2023. Accessed via Internet Archive
2023
-
[46]
Fforma: Feature-based forecast model averaging.International Journal of Forecasting, 36(1):86–92, 2020
PabloMontero-Manso, GeorgeAthanasopoulos, RobJHyndman, andThiyangaSTalagala. Fforma: Feature-based forecast model averaging.International Journal of Forecasting, 36(1):86–92, 2020
2020
-
[47]
Principles and algorithms for forecast- ing groups of time series: Locality and globality.International Journal of Forecasting, 37(4):1632–1653, 2021
Pablo Montero-Manso and Rob J Hyndman. Principles and algorithms for forecast- ing groups of time series: Locality and globality.International Journal of Forecasting, 37(4):1632–1653, 2021
2021
-
[48]
Müller, Günther Specht, Lukas Kleinheinz, and Janette Walde
Michael M. Müller, Günther Specht, Lukas Kleinheinz, and Janette Walde. Bias correction and machine learning in ar (1) estimation: Bridging traditional and modern techniques. In GvDB, 2024
2024
-
[49]
Muller, N
S. Muller, N. Hollmann, S. Arango, J. Grabocka, and F. Hutter. Transformers can do Bayesian inference. InThe Tenth International Conference on Learning Representations (ICLR’22). ICLR, 2022
2022
-
[50]
Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio
Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting. InInternational Confer- ence on Learning Representations (ICLR), 2020
2020
-
[51]
Zero-shot forecasting by simulation alone.arXiv preprint arXiv:2601.00970, 2026
Boris N Oreshkin, Mayank Jauhari, Ravi Kiran Selvam, Malcolm Wolff, Wenhao Pan, Shankar Ramasubramanian, Kin G Olivares, Tatiana Konstantinova, Andres Potapczyn- ski, Mengfei Cao, et al. Zero-shot forecasting by simulation alone.arXiv preprint arXiv:2601.00970, 2026
-
[52]
Bayesflow: Learning complex stochastic models with invertible neural networks.IEEE transactions on neural networks and learning systems, 33(4):1452–1466, 2020
Stefan T Radev, Ulf K Mertens, Andreas Voss, Lynton Ardizzone, and Ullrich Köthe. Bayesflow: Learning complex stochastic models with invertible neural networks.IEEE transactions on neural networks and learning systems, 33(4):1452–1466, 2020
2020
-
[53]
Likelihood-free parameter estimation with neural bayes estimators.The American Statistician, 78(1):1–14, 2024
Matthew Sainsbury-Dale, Andrew Zammit-Mangion, and Raphaël Huser. Likelihood-free parameter estimation with neural bayes estimators.The American Statistician, 78(1):1–14, 2024
2024
-
[54]
DeepAR: Proba- bilistic forecasting with autoregressive recurrent networks.International Journal of Fore- casting, 36(3):1181–1191, 2020
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. DeepAR: Proba- bilistic forecasting with autoregressive recurrent networks.International Journal of Fore- casting, 36(3):1181–1191, 2020
2020
-
[55]
The bias of autoregressive coefficient estimators.Journal of the American Statistical Association, 83(403):842–848, 1988
Paul Shaman and Robert A Stine. The bias of autoregressive coefficient estimators.Journal of the American Statistical Association, 83(403):842–848, 1988
1988
-
[56]
Pre- dictive performance of multi-model ensemble forecasts of covid-19 across european nations
Katharine Sherratt, Hugo Gruson, Helen Johnson, Rene Niehus, Bastian Prasse, Frank Sandmann, Jannik Deuschel, Daniel Wolffram, Sam Abbott, Alexander Ullrich, et al. Pre- dictive performance of multi-model ensemble forecasts of covid-19 across european nations. Elife, 12:e81916, 2023. 36
2023
-
[57]
A simple explanation of the forecast combination puzzle.Oxford bulletin of economics and statistics, 71(3):331–355, 2009
Jeremy Smith and Kenneth F Wallis. A simple explanation of the forecast combination puzzle.Oxford bulletin of economics and statistics, 71(3):331–355, 2009
2009
-
[58]
A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting.International journal of forecasting, 36(1):75–85, 2020
Slawek Smyl. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting.International journal of forecasting, 36(1):75–85, 2020
2020
-
[59]
Local and global trend bayesian exponential smoothing models.In- ternational Journal of Forecasting, 41(1):111–127, 2025
Slawek Smyl, Christoph Bergmeir, Alexander Dokumentov, Xueying Long, Erwin Wibowo, and Daniel Schmidt. Local and global trend bayesian exponential smoothing models.In- ternational Journal of Forecasting, 41(1):111–127, 2025
2025
-
[60]
Finite-sample properties of estima- tors for first and second order autoregressive processes.Statistical Inference for Stochastic Processes, 25(3):577–598, 2022
Sigrunn H Sørbye, Pedro G Nicolau, and Håvard Rue. Finite-sample properties of estima- tors for first and second order autoregressive processes.Statistical Inference for Stochastic Processes, 25(3):577–598, 2022
2022
-
[61]
Fformpp: Feature-based forecast model performance prediction.International Journal of Forecasting, 38(3):920–943, 2022
Thiyanga S Talagala, Feng Li, and Yanfei Kang. Fformpp: Feature-based forecast model performance prediction.International Journal of Forecasting, 38(3):920–943, 2022
2022
-
[62]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
2017
-
[63]
Macaskill Petra McLernon David J
Ben Van Calster, David J McLernon, Maarten Van Smeden, Laure Wynants, Ewout W Steyerberg, Topic Group ‘Evaluating diagnostic tests, and prediction models’ of the STRATOS initiative Bossuyt Patrick Collins Gary S. Macaskill Petra McLernon David J. Moons Karel GM Steyerberg Ewout W. Van Calster Ben van Smeden Maarten Vickers Andrew J. Calibration: the achil...
2019
-
[64]
Springer, 2005
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
2005
-
[65]
at least one
Abraham Wald. Statistical decision functions. InBreakthroughs in Statistics: Foundations and Basic Theory, pages 342–357. Springer, 1950. A Simultaneous Confidence and Prediction Bands Pointwise coverage for neural forecasts and estimates can be targeted with the calibration- adjusted quantile loss. There are cases when we are interested in coverage along...
1950
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.