Temporal Preservation over Processing: Diagnosing and Designing Spatiotemporal Single-Stage Video Detectors
Pith reviewed 2026-07-01 05:28 UTC · model grok-4.3
The pith
Preserving temporal depth through the backbone accounts for most accuracy gains in single-stage video detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
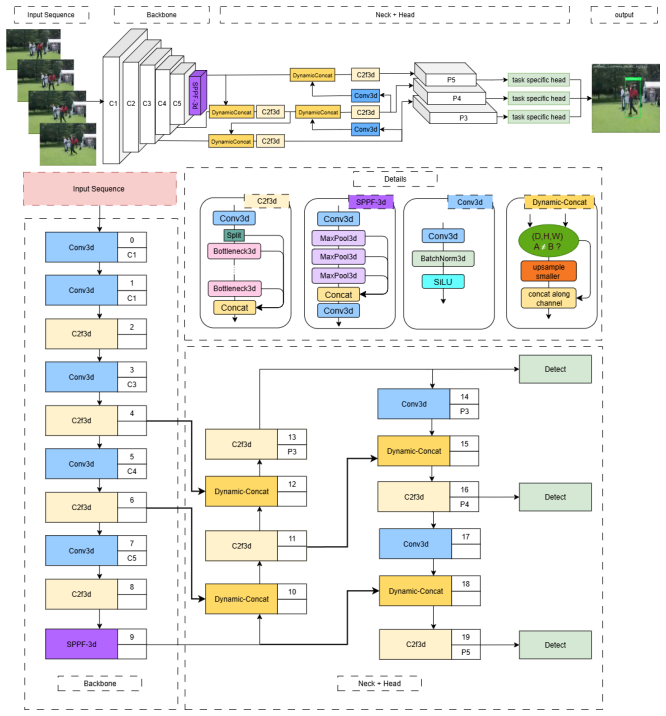
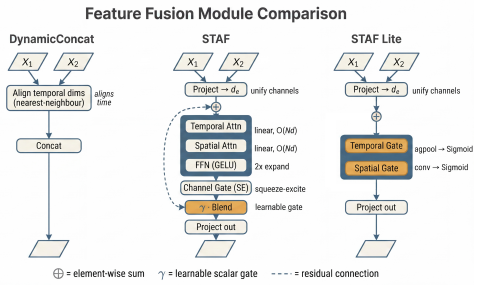
The paper establishes that temporal preservation, rather than specialized temporal processing operations, is the dominant factor behind performance in spatiotemporal single-stage detectors. Controlled perturbations demonstrate that models without preserved temporal depth collapse when the target frame is removed, whereas models that retain depth recover predictions from prior frames. The YOLO-3D design isolates this effect by keeping the full temporal dimension intact through the backbone and records the reported accuracy improvement without requiring additional fusion mechanisms.
What carries the argument
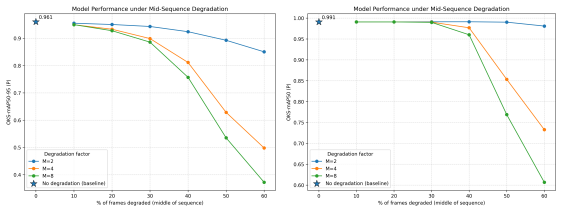
TemporalLens, a model-agnostic set of controlled perturbations including frame removal, temporal shuffling, redundancy injection, and resolution degradation that measures whether predictions depend on information across multiple frames.
If this is right
- Stacked 2D detectors fail the removal test and therefore do not reason over time.
- Spatiotemporal models that keep temporal depth recover usable predictions from earlier frames after the target frame is deleted.
- The largest accuracy increase comes from maintaining temporal depth rather than adding temporal operators.
- The diagnostic turns the presence of temporal reasoning into a measurable behavioral signature.
Where Pith is reading between the lines
- Designers could replace complex 3D modules with simple depth-preserving backbones in real-time settings.
- The same perturbation tests could be applied to action recognition or video segmentation to check temporal reliance.
- Training schedules might be adjusted to penalize single-frame shortcuts once the diagnostics are in place.
Load-bearing premise
The chosen perturbations change only the availability of temporal context and do not alter spatial feature processing or internal model behavior in ways that would produce the observed differences by accident.
What would settle it
An experiment in which a spatiotemporal model achieves identical mAP when every frame except one is removed as when the full sequence is supplied would falsify the claim that temporal preservation drives the gains.
Figures
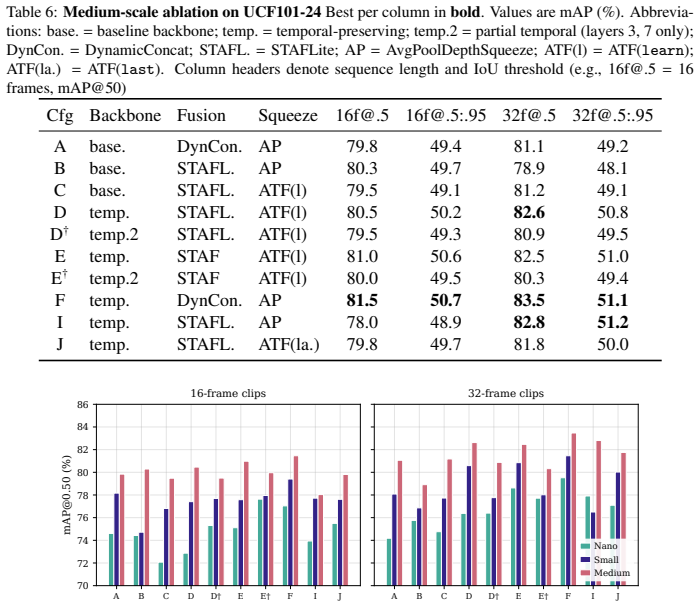
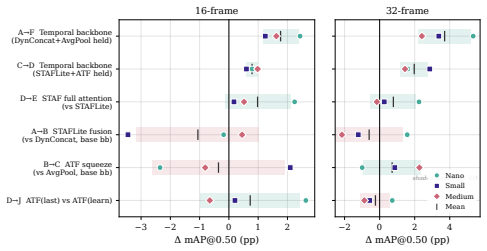
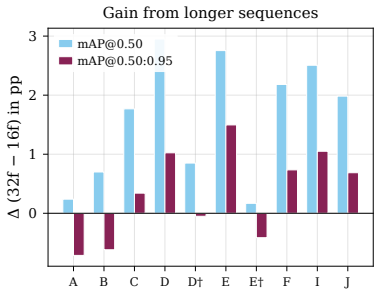
read the original abstract
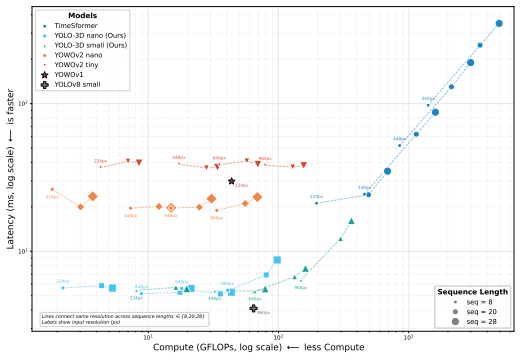
Single-stage video object detectors are increasingly deployed in time-critical applications, yet it remains unclear whether these models genuinely reason over temporal context or merely exploit a single informative frame-a gap hidden by standard metrics, which reward correct predictions regardless of how they are reached. We address this from two complementary directions: first, we propose TemporalLens, a model-agnostic diagnostic framework probing temporal dependence through controlled perturbations, structured occlusions, temporal shuffling, redundancy injection, and resolution degradation, revealing whether a detector actually uses information across time. Applied to stacked-frame 2D detectors and our YOLO-3D architecture, it exposes behavioural differences invisible to mAP: stacked 2D models collapse when the target frame is removed, while spatiotemporal models recover predictions from earlier frames, a signature of real temporal reliance. Second, we detail YOLO-3D, a modular real-time spatiotemporal detector built on YOLOv8, and show that simply preserving temporal depth through the backbone is the dominant performance driver (+3.7 pp mAP@50 at 32 frames averaged across scales). Together, the diagnostics and architecture turn "does this detector reason over time?" into a measurable, actionable question.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TemporalLens, a model-agnostic diagnostic framework that applies controlled perturbations (frame removal, temporal shuffling, redundancy injection, resolution degradation) to probe whether single-stage video detectors use temporal context or rely on single frames. Applied to stacked-frame 2D detectors and the proposed YOLO-3D architecture, it reports behavioral differences (stacked 2D collapse without target frame; 3D recovers from prior frames) invisible to mAP, and claims that preserving temporal depth through the backbone is the dominant driver (+3.7 pp mAP@50 at 32 frames averaged across scales).
Significance. If the perturbations are validated to isolate temporal dependence, the work supplies a concrete diagnostic for temporal reasoning in video detectors and a modular, real-time architecture whose key insight is simple depth preservation rather than complex temporal processing. This addresses a gap between standard mAP and actual temporal use, with potential to guide efficient spatiotemporal detector design.
major comments (2)
- [Abstract] Abstract: the central claims that TemporalLens reveals genuine temporal reliance (stacked 2D collapse vs. 3D recovery) and that temporal-depth preservation drives +3.7 pp mAP@50 both rest on the unverified assumption that the listed perturbations isolate temporal dependence. Frame removal, shuffling, and redundancy injection alter spatiotemporal statistics; without explicit controls (spatial-only performance under the same perturbations, or feature-map statistic verification), the observed gap could arise from differential spatial-feature degradation or 3D inductive biases rather than cross-frame reasoning.
- [Abstract] Abstract: the performance number (+3.7 pp mAP@50 at 32 frames averaged across scales) and the behavioral-difference claims are presented without error bars, dataset specifications, frame-count details, or any description of how the perturbations were validated to cleanly measure temporal use.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional validation and reporting details will strengthen the manuscript. We address each point below and will incorporate the suggested improvements in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that TemporalLens reveals genuine temporal reliance (stacked 2D collapse vs. 3D recovery) and that temporal-depth preservation drives +3.7 pp mAP@50 both rest on the unverified assumption that the listed perturbations isolate temporal dependence. Frame removal, shuffling, and redundancy injection alter spatiotemporal statistics; without explicit controls (spatial-only performance under the same perturbations, or feature-map statistic verification), the observed gap could arise from differential spatial-feature degradation or 3D inductive biases rather than cross-frame reasoning.
Authors: We agree that the manuscript would benefit from explicit controls to further isolate temporal effects. In the revision we will add experiments applying the same perturbation types in a purely spatial manner (e.g., spatial shuffling or resolution degradation applied identically across frames) and will include feature-map statistic comparisons (mean activation, variance, and correlation across layers) between the stacked-2D and YOLO-3D models under each condition. These additions will directly address the possibility of spatial-feature degradation or 3D inductive biases as alternative explanations. revision: yes
-
Referee: [Abstract] Abstract: the performance number (+3.7 pp mAP@50 at 32 frames averaged across scales) and the behavioral-difference claims are presented without error bars, dataset specifications, frame-count details, or any description of how the perturbations were validated to cleanly measure temporal use.
Authors: We acknowledge that the abstract and main text currently omit these reporting elements. The revised manuscript will expand the abstract and methods sections to report error bars (standard deviation across three independent runs), name the exact datasets and splits used, specify the precise frame counts and averaging procedure, and add a subsection describing perturbation validation (including the spatial-control experiments noted above). revision: yes
Circularity Check
No circularity: empirical diagnostics and reported performance gains are independent of inputs
full rationale
The paper's core claims rest on experimental application of TemporalLens perturbations (frame removal, shuffling, redundancy injection, resolution degradation) to compare stacked 2D vs. YOLO-3D detectors, plus direct mAP measurements showing +3.7 pp gain from preserving temporal depth. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology. The performance driver result is obtained by measurement on held-out test conditions rather than by construction from the diagnostic inputs themselves. The derivation chain is therefore self-contained and externally falsifiable via replication of the perturbation protocol.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jocher, J
G. Jocher, J. Qiu, A. Chaurasia, Ultralytics YOLO (2023). URL https://github.com/ultralytics/ultralytics
2023
-
[2]
D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, M. Paluri, Learning spatiotem- poral features with 3d convolutional networks, in: ICCV , 2015
2015
-
[3]
Carreira, A
J. Carreira, A. Zisserman, Quo vadis, action recognition? a new model and the kinetics dataset, in: CVPR, 2017
2017
-
[4]
K. Hara, H. Kataoka, Y . Satoh, Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?, in: CVPR, 2018
2018
-
[5]
D. Tran, H. Wang, L. Torresani, J. Ray, Y . LeCun, M. Paluri, A closer look at spatiotemporal convolutions for action recognition, in: CVPR, 2018
2018
-
[6]
Feichtenhofer, H
C. Feichtenhofer, H. Fan, J. Malik, K. He, Slowfast networks for video recogni- tion, in: ICCV , 2019
2019
-
[7]
Feichtenhofer, X3D: Expanding architectures for e fficient video recognition, in: CVPR, 2020
C. Feichtenhofer, X3D: Expanding architectures for e fficient video recognition, in: CVPR, 2020
2020
-
[8]
Bertasius, H
G. Bertasius, H. Wang, L. Torresani, Is space-time attention all you need for video understanding?, in: ICML, 2021. 23
2021
-
[9]
Arnab, M
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Luˇci´c, C. Schmid, Vivit: A video vision transformer, in: ICCV , 2021
2021
-
[10]
Z. Liu, J. Ning, Y . Cao, Y . Wei, Z. Zhang, S. Lin, H. Hu, Video swin transformer, in: CVPR, 2022
2022
-
[11]
Z. Tong, Y . Song, J. Wang, L. Wang, Videomae: masked autoencoders are data- efficient learners for self-supervised video pre-training, in: NeurIPS, NIPS ’22, 2022
2022
-
[12]
L. Wang, B. Huang, Z. Zhao, Z. Tong, Y . He, Y . Wang, Y . Wang, Y . Qiao, Video- mae v2: Scaling video masked autoencoders with dual masking, in: CVPR, 2023
2023
-
[13]
YOLOv3: An Incremental Improvement
J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, arXiv preprint arXiv:1804.02767 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
YOLOv4: Optimal Speed and Accuracy of Object Detection
A. Bochkovskiy, C.-Y . Wang, H.-Y . M. Liao, YOLOv4: Optimal speed and accu- racy of object detection, arXiv preprint arXiv:2004.10934 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[15]
O. K ¨op¨ukl¨u, X. Wei, G. Rigoll, You only watch once: A unified cnn architecture for real-time spatiotemporal action localization, arXiv preprint arXiv:1911.06644V5 Oct 2021 (2021)
-
[16]
Jiang, J
Z. Jiang, J. Yang, N. Jiang, S. Liu, T. Xie, L. Zhao, R. Li, Yowov2: A stronger yet e fficient multi-level detection framework for real-time spatio-temporal ac- tion detection, in: X. Lan, X. Mei, C. Jiang, F. Zhao, Z. Tian (Eds.), Intelligent Robotics and Applications, Springer Nature Singapore, Singapore, 2025
2025
-
[17]
Y . Shi, N. Wang, X. Guo, Yolov: Making still image object detectors great at video object detection, Proceedings of the AAAI Conference on Artificial Intelli- gence 37 (2) (2023)
2023
-
[18]
C. W. Corsel, M. van Lier, L. Kampmeijer, N. Boehrer, E. M. Bakker, Exploiting temporal context for tiny object detection, in: W ACVW, 2023
2023
-
[19]
M. C. van Leeuwen, E. P. Fokkinga, W. Huizinga, J. Baan, F. G. Heslinga, Toward versatile small object detection with temporal-yolov8, Sensors 24 (22) (2024)
2024
-
[20]
Van Lier, M
M. Van Lier, M. Van Leeuwen, B. Van Manen, L. Kampmeijer, N. Boehrer, Evaluation of Spatio-Temporal Small Object Detection in Real-World Adverse Weather Conditions , in: W ACVW, 2025
2025
-
[21]
Zhang, L
D. Zhang, L. He, Z. Tu, S. Zhang, F. Han, B. Yang, Learning motion represen- tation for real-time spatio-temporal action localization, Pattern Recognition 103 (2020)
2020
-
[22]
Y . Liu, F. Yang, D. Ginhac, Acdnet: An action detection network for real-time edge computing based on flow-guided feature approximation and memory aggre- gation, Pattern Recognition Letters 145 (2021). 24
2021
-
[23]
Sarkar, G
S. Sarkar, G. Datta, S. Kundu, K. Zheng, C. Bhattacharyya, P. A. Beerel, Maskvd: Region masking for efficient video object detection, in: W ACV , 2025
2025
-
[24]
K. A. Hashmi, T. U. Sheikh, D. Stricker, M. Z. Afzal, Beyond boxes: Mask- guided spatio-temporal feature aggregation for video object detection, in: W ACV , 2025
2025
-
[25]
Uchiyama, N
T. Uchiyama, N. Sogi, K. Niinuma, K. Fukui, Visually explaining 3d-cnn predic- tions for video classification with an adaptive occlusion sensitivity analysis, in: W ACV , 2023
2023
-
[26]
M. D. Zeiler, R. Fergus, Visualizing and understanding convolutional networks, in: D. Fleet, T. Pajdla, B. Schiele, T. Tuytelaars (Eds.), ECCV , 2014
2014
-
[27]
Agarwal, A
C. Agarwal, A. Nguyen, Explaining image classifiers by removing input features using generative models, in: H. Ishikawa, C.-L. Liu, T. Pajdla, J. Shi (Eds.), ACCV , 2020
2020
-
[28]
Hooker, D
S. Hooker, D. Erhan, P.-J. Kindermans, B. Kim, A benchmark for interpretability methods in deep neural networks, in: H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´e-Buc, E. Fox, R. Garnett (Eds.), NeurIPS, V ol. 32, 2019
2019
-
[29]
Samek, G
W. Samek, G. Montavon, S. Lapuschkin, C. J. Anders, K.-R. M ¨uller, Explain- ing deep neural networks and beyond: A review of methods and applications, Proceedings of the IEEE 109 (2021)
2021
-
[30]
Dawoud, W
K. Dawoud, W. Samek, P. Eisert, S. Lapuschkin, S. Bosse, Human-centered eval- uation of xai methods, in: ICDMW, 2023
2023
-
[31]
Wang, H.-Y
C.-Y . Wang, H.-Y . Mark Liao, Y .-H. Wu, P.-Y . Chen, J.-W. Hsieh, I.-H. Yeh, Csp- net: A new backbone that can enhance learning capability of cnn, in: CVPRW, 2020
2020
-
[32]
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyra- mid networks for object detection, in: CVPR, 2017
2017
-
[33]
S. Liu, L. Qi, H. Qin, J. Shi, J. Jia, Path aggregation network for instance seg- mentation, in: CVPR, 2018
2018
-
[34]
C.-F. R. Chen, R. Panda, K. Ramakrishnan, R. Feris, J. Cohn, A. Oliva, Q. Fan, Deep analysis of cnn-based spatio-temporal representations for action recogni- tion, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2021
2021
-
[35]
something something
R. Goyal, S. E. Kahou, V . Michalski, J. Materzynska, S. Westphal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, R. Memisevic, The “something something” video database for learning and eval- uating visual common sense, in: ICCV , 2017. 25
2017
-
[36]
Z. Liu, L. Wang, W. Wu, C. Qian, T. Lu, Tam: Temporal adaptive module for video recognition, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[37]
Z. Qing, S. Zhang, Z. Huang, Y . Zhang, C. Gao, D. Zhao, N. Sang, Disentan- gling spatial and temporal learning for efficient image-to-video transfer learning, in: Proceedings of the IEEE /CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[38]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: 2018 IEEE /CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[39]
Katharopoulos, A
A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret, Transformers are rnns: Fast autoregressive transformers with linear attention, in: International conference on machine learning, PMLR, 2020
2020
-
[40]
Zheng, J
L. Zheng, J. Yuan, C. Wang, L. Kong, E fficient attention via control variates, in: International Conference on Learning Representations, 2023
2023
-
[41]
Zheng, C
L. Zheng, C. Wang, L. Kong, Linear complexity randomized self-attention mech- anism, in: International Conference on Machine Learning, PMLR, 2022
2022
-
[42]
Suzuki, T
T. Suzuki, T. Itazuri, K. Hara, H. Kataoka, Learning spatiotemporal 3d convolu- tion with video order self-supervision, in: L. Leal-Taix´e, S. Roth (Eds.), ECCVW, 2019
2019
-
[43]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, C. L. Zitnick, Microsoft coco: Common objects in context, in: D. Fleet, T. Pajdla, B. Schiele, T. Tuytelaars (Eds.), ECCV , 2014
2014
-
[44]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, M. Shah, UCF101: A dataset of 101 human actions classes from videos in the wild, CoRR abs/1212.0402 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[45]
Zhong, Y
F. Zhong, Y . Wu, H. Yu, G. Wang, Z. Lu, A benchmark dataset and semantics- guided detection network for spatial–temporal human actions in urban driving scenes, Pattern Recognition 158 (2025)
2025
-
[46]
X. Xie, J. Dong, J. Han, G. Cheng, Does yolo really need to see every training im- age in every epoch?, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 26 Appendix A. Temporal-Preserving Backbone: Cost Analysis The temporal-preservation strategy involves a favourable trade-offacross three dis- tinct cost...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.