On the Position Bias of On-Policy Distillation
Pith reviewed 2026-06-26 10:42 UTC · model grok-4.3
The pith
Weighting tokens by accumulated distribution discrepancy improves on-policy distillation convergence and performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
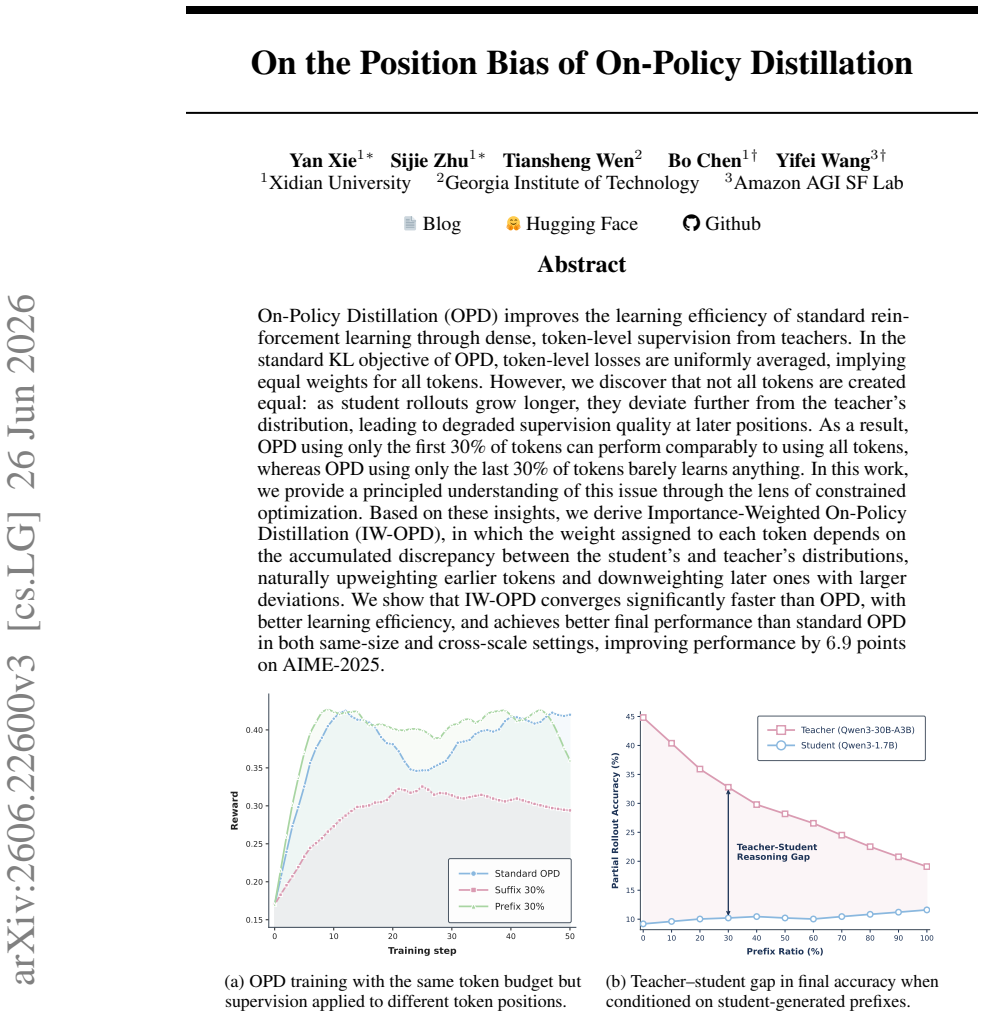
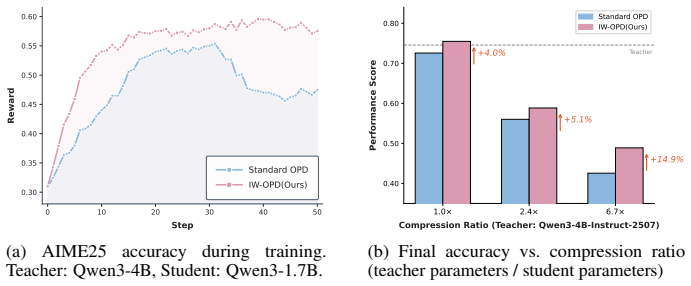
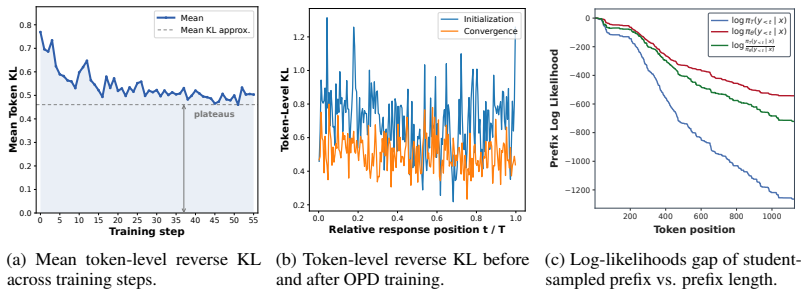
In the standard KL objective of OPD, token-level losses are uniformly averaged, implying equal weights for all tokens. As student rollouts grow longer they deviate further from the teacher's distribution, leading to degraded supervision quality at later positions. IW-OPD assigns each token a weight based on the accumulated discrepancy between the student's and teacher's distributions, upweighting earlier tokens and downweighting later ones, which yields faster convergence and better final performance than standard OPD.
What carries the argument
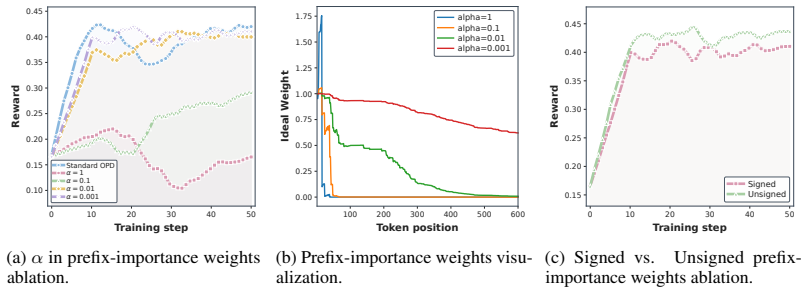
Importance-Weighted On-Policy Distillation (IW-OPD), which sets token weights according to the accumulated discrepancy between student and teacher output distributions.
If this is right
- IW-OPD converges significantly faster than standard OPD with better learning efficiency.
- IW-OPD achieves higher final performance than standard OPD in both same-size and cross-scale teacher-student settings.
- Standard OPD using only the first 30 percent of tokens performs comparably to using all tokens, while using only the last 30 percent barely learns.
- The importance weighting improves performance by up to 6.9 points on AIME-2025.
Where Pith is reading between the lines
- The same discrepancy-based weighting could be tested in other autoregressive generation settings where supervision quality is known to degrade with sequence length.
- IW-OPD might allow shorter effective rollouts during distillation without loss of signal, reducing compute per update.
- Similar accumulated-discrepancy reweighting could be applied inside other token-level RL objectives that currently assume uniform token importance.
Load-bearing premise
The assumption that weighting each token by its accumulated discrepancy with the teacher distribution correctly identifies and mitigates degraded supervision quality without introducing new optimization biases.
What would settle it
A controlled experiment on a short-horizon task where all tokens remain close to the teacher distribution throughout the rollout, in which IW-OPD shows no convergence or performance advantage over uniform OPD.
Figures
read the original abstract
On-Policy Distillation (OPD) improves the learning efficiency of standard reinforcement learning through dense, token-level supervision from teachers. In the standard KL objective of OPD, token-level losses are uniformly averaged, implying equal weights for all tokens. However, we discover that not all tokens are created equal: as student rollouts grow longer, they deviate further from the teacher's distribution, leading to degraded supervision quality at later positions. As a result, OPD using only the first 30% of tokens can perform comparably to using all tokens, whereas OPD using only the last 30% of tokens barely learns anything. In this work, we provide a principled understanding of this issue through the lens of constrained optimization. Based on these insights, we derive Importance-Weighted On-Policy Distillation (IW-OPD), in which the weight assigned to each token depends on the accumulated discrepancy between the student's and teacher's distributions, naturally upweighting earlier tokens and downweighting later ones with larger deviations. We show that IW-OPD converges significantly faster than OPD, with better learning efficiency, and achieves better final performance than standard OPD in both same-size and cross-scale settings, improving performance up to 6.9 points on AIME-2025.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard On-Policy Distillation (OPD) suffers from position bias: as student rollouts lengthen, tokens deviate further from the teacher distribution, degrading supervision quality at later positions. This is supported by an ablation showing that OPD on only the first 30% of tokens performs comparably to using all tokens, while the last 30% barely learns. From a constrained-optimization perspective, the authors derive Importance-Weighted OPD (IW-OPD), which assigns each token a weight based on its accumulated student-teacher discrepancy (naturally upweighting early tokens). They report that IW-OPD converges faster with better learning efficiency than OPD and achieves superior final performance in both same-size and cross-scale settings, with gains up to 6.9 points on AIME-2025.
Significance. If the weighting mechanism isolates the claimed position bias (rather than serving as a proxy for token difficulty or rarity), the result would strengthen the case for constrained-optimization-derived corrections in on-policy distillation and could improve sample efficiency in RL fine-tuning of language models. The work supplies a parameter-free derivation and reports concrete, falsifiable performance deltas on a challenging benchmark.
major comments (2)
- [Abstract (first-30% vs last-30% token ablation)] Abstract (first-30% vs last-30% token ablation): the ablation demonstrates position-dependent degradation but does not test whether accumulated discrepancy correlates with intrinsic token properties (low teacher probability, complexity, or rarity). If so, IW-OPD gains could arise from implicit curriculum or regularization effects rather than the intended correction for rollout-length bias, weakening the causal claim for the 6.9-point AIME-2025 improvement.
- [Empirical results (same-size and cross-scale settings)] Empirical results (same-size and cross-scale settings): the abstract reports performance gains without specifying experimental controls, statistical significance tests, exact baseline implementations, or confirmation that the weighting rule was derived without post-hoc hyperparameter fitting. These details are load-bearing for verifying that the reported efficiency and final-performance advantages are reproducible and attributable to the proposed mechanism.
minor comments (1)
- Clarify in the methods whether the accumulated-discrepancy weighting introduces any tunable scaling factors or is strictly determined by the constrained-optimization derivation.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point by point below, clarifying the intended scope of the ablation and committing to expanded experimental details in revision.
read point-by-point responses
-
Referee: [Abstract (first-30% vs last-30% token ablation)] Abstract (first-30% vs last-30% token ablation): the ablation demonstrates position-dependent degradation but does not test whether accumulated discrepancy correlates with intrinsic token properties (low teacher probability, complexity, or rarity). If so, IW-OPD gains could arise from implicit curriculum or regularization effects rather than the intended correction for rollout-length bias, weakening the causal claim for the 6.9-point AIME-2025 improvement.
Authors: The ablation isolates position in the rollout as the variable: the first 30% of tokens are generated while the student remains close to the teacher, while the last 30% occur after substantial deviation has accumulated. This directly illustrates the length-dependent degradation described in the constrained-optimization derivation. The importance weights are computed from the running discrepancy itself, not from any token-level difficulty or rarity proxy. We agree that an explicit correlation analysis between discrepancy and intrinsic token properties would further rule out alternative explanations and will add this discussion plus supporting plots in the revision. revision: partial
-
Referee: [Empirical results (same-size and cross-scale settings)] Empirical results (same-size and cross-scale settings): the abstract reports performance gains without specifying experimental controls, statistical significance tests, exact baseline implementations, or confirmation that the weighting rule was derived without post-hoc hyperparameter fitting. These details are load-bearing for verifying that the reported efficiency and final-performance advantages are reproducible and attributable to the proposed mechanism.
Authors: We agree these details are necessary for reproducibility. The weighting rule follows directly from the constrained-optimization derivation with no additional hyperparameters. In the revised manuscript we will expand the experimental section to include: (i) precise baseline implementations and hyperparameter matching, (ii) statistical significance tests across runs, (iii) full description of rollout and evaluation protocols, and (iv) explicit confirmation that the importance-weight formula contains no post-hoc tuning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a constrained-optimization analysis of position bias in OPD, then derives the IW-OPD weighting rule directly from that analysis (accumulated discrepancy as the natural weight). No equations reduce a claimed prediction or result to a fitted parameter or self-referential definition by construction. Performance improvements are reported as empirical outcomes on benchmarks, not as mathematical identities. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the abstract or described derivation. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token weights can be assigned proportionally to accumulated student-teacher distribution discrepancy without introducing new biases into the constrained optimization.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations,
-
[2]
URLhttps://openreview.net/forum?id=3zKtaqxLhW
-
[3]
Why exposure bias matters: An imitation learning perspective of error accumulation in language generation
Kushal Arora, Layla El Asri, Hareesh Bahuleyan, and Jackie Chi Kit Cheung. Why exposure bias matters: An imitation learning perspective of error accumulation in language generation. InFindings of the Association for Computational Linguistics: ACL 2022, pages 700–710, 2022
2022
-
[4]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems, 2015
2015
-
[5]
Bigelow, Ari Holtzman, Hidenori Tanaka, and Tomer Ullman
Eric J. Bigelow, Ari Holtzman, Hidenori Tanaka, and Tomer Ullman. Forking paths in neural text generation. InInternational Conference on Learning Representations, 2025
2025
-
[6]
Internlm2 technical report.arXiv preprint arXiv:2403.17297, 2024
Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report.arXiv preprint arXiv:2403.17297, 2024
Pith/arXiv arXiv 2024
-
[7]
Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wenjie Peng, Jianhao Chen, Ning Chen, Zhiyuan Liu, and Maosong Sun. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
Pith/arXiv arXiv 2025
-
[8]
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[9]
Rlhf workflow: From reward modeling to online rlhf
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024
Pith/arXiv arXiv 2024
-
[10]
Shuhao Gu, Jinchao Zhang, Fandong Meng, Yang Feng, Wanying Xie, Jie Zhou, and Dong Yu. Token-level adaptive training for neural machine translation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1035–1046, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main
-
[11]
URLhttps://aclanthology.org/2020.emnlp-main.76/
2020
-
[12]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=5h0qf7IBZZ
2024
-
[13]
Yuhang He, Haodong Wu, Siyi Liu, Hongyu Ge, Hange Zhou, Keyi Wu, Zhuo Zheng, Qihong Lin, Zixin Zhong, and Yongqi Zhang. Rethinking token-level credit assignment in RLVR: A polarity-entropy analysis.arXiv preprint arXiv:2604.11056, 2026
Pith/arXiv arXiv 2026
-
[14]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning and Representation Learning Workshop, 2015. URL https://arxiv. org/abs/1503.02531
Pith/arXiv arXiv 2015
-
[15]
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290, 2025
Pith/arXiv arXiv 2025
-
[16]
SelecTKD: Selective token-weighted knowledge distillation for LLMs, 2025
Haiduo Huang, Jiangcheng Song, Yadong Zhang, and Pengju Ren. SelecTKD: Selective token-weighted knowledge distillation for LLMs, 2025. URL https://arxiv.org/abs/ 2510.24021
arXiv 2025
-
[17]
Sham M. Kakade. A natural policy gradient. InAdvances in Neural Information Processing Systems, volume 14, pages 1531–1538, 2001
2001
-
[18]
Explain in your own words: Improving reasoning via token-selective dual knowledge distillation
Minsang Kim and Seung Jun Baek. Explain in your own words: Improving reasoning via token-selective dual knowledge distillation. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=zph7e5JaXc. 11
2026
-
[19]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy dis- tillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026. doi: 10.48550/arXiv.2604.13016. URL https://arxiv.org/abs/ 2604.13016
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.13016 2026
-
[20]
Chen Liang, Haoming Jiang, Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao, and Tuo Zhao. Token-wise curriculum learning for neural machine translation. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 3658–3670, Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021. find...
-
[21]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, 2024
2024
-
[22]
Critical tokens matter: Token-level contrastive estimation enhances LLM’s reasoning capability
Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Lin, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, and Zhaopeng Tu. Critical tokens matter: Token-level contrastive estimation enhances LLM’s reasoning capability. InInternational Conference on Machine Learning, 2025
2025
-
[23]
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, et al. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
Pith/arXiv arXiv 2025
-
[24]
Code-r1: Reproducing r1 for code with reliable rewards
Jiawei Liu and Lingming Zhang. Code-r1: Reproducing r1 for code with reliable rewards. 2025
2025
-
[25]
Lingyuan Liu and Mengxiang Zhang. Being strong progressively! enhancing knowledge distillation of large language models through a curriculum learning framework.arXiv preprint arXiv:2506.05695, 2025
arXiv 2025
-
[26]
MiMo-V2-Flash technical report.arXiv preprint arXiv:2601.02780, 2026
LLM-Core, Xiaomi. MiMo-V2-Flash technical report.arXiv preprint arXiv:2601.02780, 2026
Pith/arXiv arXiv 2026
-
[27]
On-policy distillation
Kevin Lu. On-policy distillation. Thinking Machines Lab Blog, 2025. URL https:// thinkingmachines.ai/blog/on-policy-distillation/
2025
-
[28]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[29]
Gordon, and J
Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the 14th International Conference on Artificial Intelligence and Statistics, pages 627–635, 2011
2011
-
[30]
Jordan, and Pieter Abbeel
John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization. InInternational Conference on Machine Learning, pages 1889– 1897, 2015
2015
-
[31]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[33]
A survey of on-policy distillation for large language models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
Pith/arXiv arXiv 2026
-
[34]
Rényi divergence and kullback-leibler divergence.IEEE Transactions on Information Theory, 60(7):3797–3820, 2014
Tim van Erven and Peter Harremoës. Rényi divergence and kullback-leibler divergence.IEEE Transactions on Information Theory, 60(7):3797–3820, 2014
2014
-
[35]
Ignore the KL penalty! boosting exploration on critical tokens to enhance RL fine-tuning
Jean Vassoyan, Nathanaël Beau, and Roman Plaud. Ignore the KL penalty! boosting exploration on critical tokens to enhance RL fine-tuning. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 6123–6133, 2025. 12
2025
-
[36]
Xu, Damai Dai, Yifei Li, Deli Chen, Y
Peiyi Wang, Lei Li, Zhihong Shao, R.X. Xu, Damai Dai, Yifei Li, Deli Chen, Y . Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[37]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning. InAdvances in Neural Information...
2025
-
[38]
f-divergence minimization for sequence-level knowledge distillation
Yuqiao Wen, Zichao Li, Wenyu Du, and Lili Mou. f-divergence minimization for sequence-level knowledge distillation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10817–10834, Toronto, Canada,
-
[39]
doi: 10.18653/v1/2023.acl-long.605
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.605. URL https://aclanthology.org/2023.acl-long.605/
-
[40]
Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, and Alexander Rakhlin
Tengyang Xie, Dylan J. Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, and Alexander Rakhlin. Exploratory preference optimization: Harnessing implicit Q*-approximation for sample-efficient RLHF.arXiv preprint arXiv:2405.21046, 2024
arXiv 2024
-
[41]
LLM-oriented token-adaptive knowledge distillation, 2025
Xurong Xie, Zhucun Xue, Jiafu Wu, Jian Li, Yabiao Wang, Xiaobin Hu, Yong Liu, and Jiangning Zhang. LLM-oriented token-adaptive knowledge distillation, 2025. URL https: //arxiv.org/abs/2510.11615
arXiv 2025
-
[42]
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. PACED: Distilla- tion and on-policy self-distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178, 2026
Pith/arXiv arXiv 2026
-
[43]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[44]
Deepcritic: Deliberate critique with large language models.arXiv preprint arXiv:2505.00662, 2025
Wenkai Yang, Jingwen Chen, Yankai Lin, and Ji-Rong Wen. Deepcritic: Deliberate critique with large language models.arXiv preprint arXiv:2505.00662, 2025
arXiv 2025
-
[45]
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
Pith/arXiv arXiv 2026
-
[46]
Disentangling reasoning tokens and boilerplate tokens for language model fine-tuning
Ziang Ye, Zhenru Zhang, Yang Zhang, Jianxin Ma, Junyang Lin, and Fuli Feng. Disentangling reasoning tokens and boilerplate tokens for language model fine-tuning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20939–20957. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.findings-acl.1078
-
[47]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
Pith/arXiv arXiv 2026
-
[48]
Geometric-mean policy optimization
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, Fang Wan, and Furu Wei. Geometric-mean policy optimization. InInternational Conference on Learning Representations, 2026
2026
-
[49]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. doi: 10.48550/arXiv.2507.18071. URL https://arxiv.org/abs/2507.18071. 13 A Proofs and Derivations The derivations below fix a prompt x u...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.18071 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.