How Should Agents Read Demonstrations? Hierarchical Structure Beats Flat Action Logs
Pith reviewed 2026-06-26 16:48 UTC · model grok-4.3
The pith
Hierarchically grouped demonstrations improve LLM agent success rates from 76.7% to 90.7% on tasks with vague descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
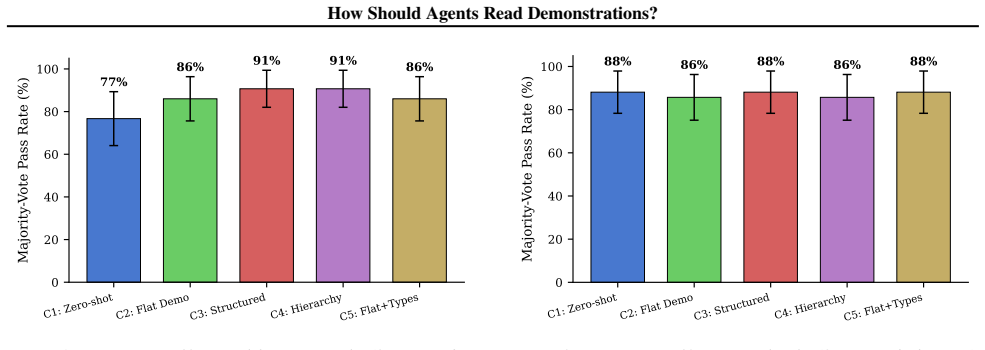
Across 85 web automation tasks the authors compare a zero-shot baseline to four demonstration formats that contain identical action sequences. On the 43 tasks whose descriptions are vague, hierarchically grouped demonstrations raise pass rates from 76.7 percent to 90.7 percent (paired permutation test p=0.034). Flat demonstrations produce a smaller, non-significant lift. On the 42 tasks with precise descriptions none of the formats improves performance. An ablation isolating subgoal grouping shows that preconditions, postconditions, and parameter annotations add no further measurable benefit.
What carries the argument
Hierarchical grouping of recorded actions into labeled subgoals, which segments the flat action log to supply explicit procedural structure to the LLM agent.
If this is right
- PbD systems should segment recorded action sequences into named subgoal groups rather than deliver flat step lists.
- The organizational advantage appears only when task descriptions leave procedural details ambiguous.
- Subgoal grouping by itself accounts for the observed gain; additional annotations such as preconditions provide no extra benefit.
- Any system supplying procedural context to an LLM agent can adopt the same segmentation practice.
- On tasks whose instructions already specify the full procedure, demonstrations add no value regardless of format.
Where Pith is reading between the lines
- The same grouping principle could be tested on non-web agent domains such as robotic manipulation or code generation.
- Agents might be trained to infer subgoal boundaries automatically from flat logs when explicit labels are unavailable.
- Varying the depth or granularity of the hierarchy offers a testable way to measure how much structure is optimal for different task classes.
- Combining hierarchical demonstrations with other context-compression techniques could be examined to determine whether the two approaches compound.
Load-bearing premise
The only systematic difference among the four demonstration formats is their organizational structure; action sequences, the underlying LLM, and evaluation criteria remain identical across all 85 tasks.
What would settle it
A controlled replication on a fresh set of vague-description tasks in which hierarchical grouping produces no higher pass rate than flat logs or in which flat logs outperform the grouped format.
Figures
read the original abstract
Programming by Demonstration (PbD) offers a human-centered way to author procedural knowledge for LLM agents: users communicate what they want by showing rather than by writing prompts or code, making agent authoring accessible to non-programmers. The natural output of a PbD recording is a flat action log, but how this log is organized before being passed to the agent is an open design question with significant consequences for plan quality. We propose grouping recorded actions into labeled, hierarchical subgoals and evaluate the effect of this organizational structure in a controlled experiment. Across 85 web automation tasks, we compare a zero-shot baseline against four demonstration formats that share identical action sequences but differ in structure. On 43 natural-language tasks with vague descriptions, hierarchically grouped demonstrations improve pass rates from 76.7\% to 90.7\% (paired permutation test $p{=}0.034$; win-loss 6:0), while flat demonstrations show a smaller, non-significant improvement. On 42 tasks with precise descriptions, no format provides any benefit, confirming that the hierarchical advantage arises specifically when descriptions leave procedural details ambiguous. Ablation shows that subgoal grouping alone drives the effect: preconditions, postconditions, and parameter annotations add no measurable benefit. These results offer a concrete design recommendation for PbD pipelines and, more broadly, for any system that feeds procedural context to an LLM agent: segment action sequences into named subgoal groups rather than presenting flat step lists.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for LLM-based web automation agents, demonstrations grouped into labeled hierarchical subgoals outperform flat action logs and zero-shot baselines specifically on 43 tasks with vague natural-language descriptions (pass rate rising from 76.7% to 90.7%, paired permutation test p=0.034, win-loss 6:0), while flat formats yield only a smaller non-significant gain; on 42 tasks with precise descriptions no format helps; an ablation isolates subgoal grouping as the sole driver, with preconditions, postconditions, and parameter annotations adding no benefit. All formats share identical action sequences and differ only in organizational structure.
Significance. If the controlled comparison and ablation hold, the result supplies a concrete, low-cost design rule for programming-by-demonstration pipelines: segment action logs into named subgoal groups rather than flat lists when task descriptions leave procedural details ambiguous. The differential effect across vague versus precise descriptions and the explicit isolation of grouping strengthen the practical takeaway for any system supplying procedural context to LLM agents.
minor comments (3)
- [Abstract, §4] Abstract and §4: the 43/42 task split and the criteria used to classify descriptions as “vague” versus “precise” should be stated explicitly so readers can assess whether the differential result is robust to alternative partitions.
- [§5] The manuscript reports a paired permutation test (p=0.034) and win-loss count but does not indicate whether the test was pre-registered or whether any correction for multiple comparisons across the four formats was applied; a brief statement would increase transparency.
- [§5] Table or figure presenting per-task outcomes for the four formats would allow direct inspection of the 6:0 win-loss pattern and the magnitude of the flat-format improvement.
Simulated Author's Rebuttal
We thank the referee for the accurate summary of our results, the positive significance assessment, and the recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No circularity: purely empirical comparison of demonstration formats
full rationale
The paper reports a controlled experiment comparing four demonstration formats that share identical action sequences and differ only in organizational structure. Pass rates are measured directly on 85 tasks with statistical tests (paired permutation test). No equations, fitted parameters, predictions derived from inputs, self-citations as load-bearing premises, or ansatzes are present. The central claim (hierarchical grouping improves performance on vague tasks) is supported by the ablation and differential results across task types, with no reduction of outputs to inputs by construction. This is a standard empirical study with no derivation chain to inspect for circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pass rate on the chosen web automation tasks is a valid and unbiased proxy for plan quality produced by the LLM agent.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.10049 , year =
Jiawen Li and Zheng Ning and Yuan Tian and Toby Jia-Jun Li , title =. arXiv preprint arXiv:2510.10049 , year =
-
[2]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li and Wenbo Chen and Yimin Liu and Shenghan Zheng and others , title =. arXiv preprint arXiv:2602.12670 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Agent Skills Overview , howpublished =
-
[4]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =. ICLR , year =
-
[5]
NeurIPS , year =
Xiang Deng and Yu Gu and Boyuan Zheng and Shijie Chen and Samuel Stevens and Boshi Wang and Huan Sun and Yu Su , title =. NeurIPS , year =
-
[6]
NeurIPS , year =
Hongxin Li and Jingran Su and Yuntao Chen and Qing Li and Zhaoxiang Zhang , title =. NeurIPS , year =
-
[7]
Zora Zhiruo Wang and Jiayuan Mao and Daniel Fried and Graham Neubig , title =. arXiv preprint arXiv:2409.07429 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2504.13805 , year=
Guangyi Liu and Pengxiang Zhao and Liang Liu and Zhiming Chen and Yuxiang Chai and Shuai Ren and Hao Wang and Shibo He and Wenchao Meng , title =. arXiv preprint arXiv:2504.13805 , year =
-
[9]
Your Wish Is My Command: Programming by Example , publisher =
-
[10]
arXiv preprint arXiv:2411.10541 , year=
Jia He and Mukund Rungta and David Koleczek and Arshdeep Sekhon and Franklin X. Wang and Sadid Hasan , title =. arXiv preprint arXiv:2411.10541 , year =
-
[11]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , title =. NeurIPS , year =
-
[12]
EMNLP , year =
Sewon Min and Xinxi Lyu and Ari Holtzman and Mikel Artetxe and Mike Lewis and Hannaneh Hajishirzi and Luke Zettlemoyer , title =. EMNLP , year =
-
[13]
ICLR , year =
Melanie Sclar and Yejin Choi and Yulia Tsvetkov and Alane Suhr , title =. ICLR , year =
-
[14]
ACL , year =
Gaurav Verma and Rachneet Kaur and Nishan Srishankar and Zhen Zeng and Tucker Balch and Manuela Veloso , title =. ACL , year =
-
[15]
Findings of ACL , year =
Yiduo Guo and Zekai Zhang and Yaobo Liang and Dongyan Zhao and Nan Duan , title =. Findings of ACL , year =
-
[16]
ICLR , year =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , title =. ICLR , year =
-
[17]
Transactions on Machine Learning Research , year =
Guanzhi Wang and Yuqi Xie and Yunfan Jiang and Ajay Mandlekar and Chaowei Xiao and Yuke Zhu and Linxi Fan and Anima Anandkumar , title =. Transactions on Machine Learning Research , year =
-
[18]
Griffiths and Yuan Cao and Karthik Narasimhan , title =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Thomas L. Griffiths and Yuan Cao and Karthik Narasimhan , title =. NeurIPS , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.