DrivingAgent: Design and Scheduling Agents for Autonomous Driving Systems
Pith reviewed 2026-06-27 10:03 UTC · model grok-4.3
The pith
DrivingAgent automates module design with LLMs and real-time scheduling with RL-trained agents for autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
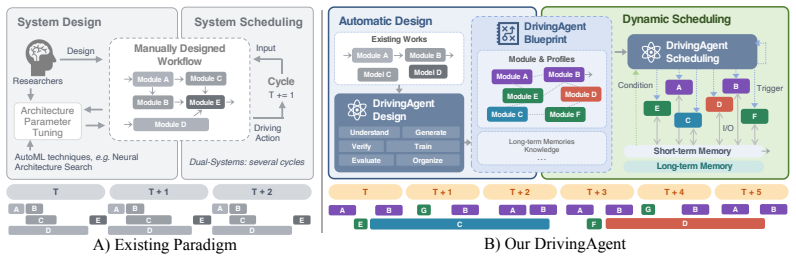
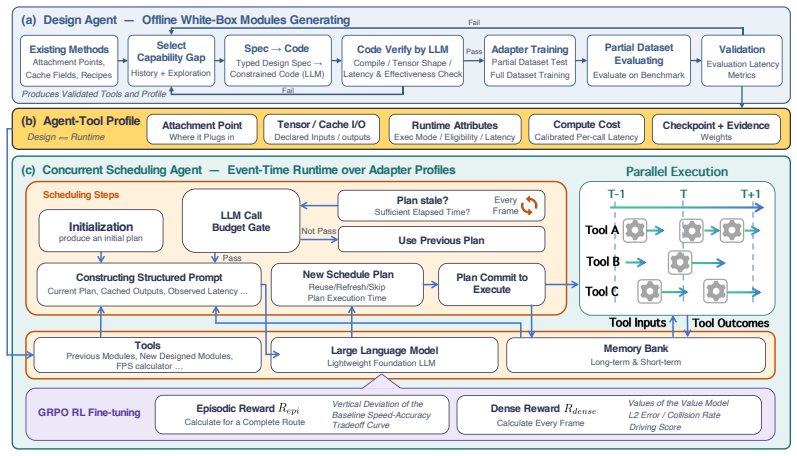
DrivingAgent automates module development by interpreting system architecture, generating code, and validating modules via super-network training; it then employs a lightweight LLM trained with reinforcement learning to dynamically orchestrate system modules in real time, supported by a structured memory that integrates long-term storage with timestamped short-term context.
What carries the argument
DrivingAgent framework that splits design (LLM code generation plus super-network validation) from scheduling (RL-trained lightweight LLM with structured memory).
If this is right
- Module integration no longer requires manual coding for each new foundation model.
- Real-time constraints can be met by dynamic rather than static module assignment.
- The same agent structure can be reused across different vehicle platforms without re-engineering the scheduler.
- Validation through super-network training reduces the need for separate per-module training runs.
Where Pith is reading between the lines
- If the RL scheduler generalizes, similar lightweight agents could coordinate perception-planning-control stacks in other real-time robotic domains.
- The separation of design and scheduling phases suggests that verification effort can be concentrated on the scheduler rather than every generated module.
- Continuous operation implies the memory structure must handle long-duration drives without unbounded growth in stored context.
Load-bearing premise
The generated modules and the RL scheduling policy remain safe and correct when the vehicle encounters distribution shifts or edge cases not seen during training.
What would settle it
A controlled test on a closed track or simulator where the DrivingAgent-controlled vehicle exhibits a higher rate of safety violations or missed deadlines than a hand-tuned baseline under identical distribution-shift conditions.
Figures
read the original abstract
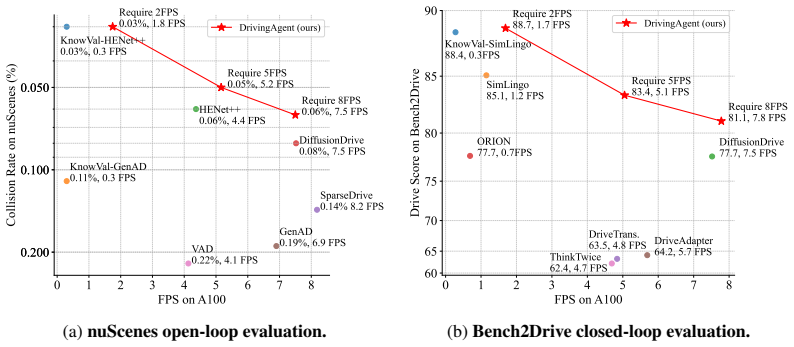
Many autonomous driving systems are increasingly incorporating foundation models to improve generalization and handle long-tail scenarios. However, this trend introduces two key challenges: (i) the manual and labor-intensive process of designing and integrating new models, and (ii) the lack of intelligent, dynamic scheduling mechanisms to meet strict real-time constraints. While Large Language Model (LLM)-based agents offer a promising avenue for automation, existing frameworks are ill-suited for autonomous driving. Specifically, they fail to distinguish between the fundamentally different requirements of system design and real-time scheduling, treat modules as opaque black boxes, and are not designed for continuous operation. To address these limitations, we propose DrivingAgent, a novel agent framework tailored to the dual challenges of autonomous driving system design and scheduling. In the design phase, DrivingAgent automates module development by interpreting system architecture, generating code, and validating modules via super-network training. In the scheduling phase, it employs a lightweight LLM trained with reinforcement learning to dynamically orchestrate system modules in real time, supported by a structured memory that integrates long-term storage with timestamped short-term context. Experimental results demonstrate that DrivingAgent achieves a superior speed--accuracy trade-off on both the nuScenes and Bench2Drive benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DrivingAgent, an LLM-based agent framework for autonomous driving systems. In the design phase it automates module creation via architecture interpretation, code generation, and super-network validation; in the scheduling phase a lightweight RL-trained LLM dynamically orchestrates modules using structured long-term/short-term memory. The central claim is that the resulting system achieves a superior speed-accuracy trade-off on the nuScenes and Bench2Drive benchmarks.
Significance. If the reported benchmark results can be substantiated with full experimental protocols, the framework would address two practical bottlenecks in foundation-model-based autonomous driving: labor-intensive module integration and real-time scheduling under latency constraints. This could reduce development time while preserving or improving the accuracy-latency frontier.
major comments (1)
- [Abstract] Abstract: the claim that DrivingAgent 'achieves a superior speed--accuracy trade-off on both the nuScenes and Bench2Drive benchmarks' is presented without any metrics, baselines, ablation studies, statistical tests, or description of how the RL scheduler's latency and per-module accuracy are jointly evaluated. This absence makes the central empirical claim impossible to assess.
Simulated Author's Rebuttal
We thank the referee for their detailed review and the opportunity to clarify the presentation of our empirical claims. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that DrivingAgent 'achieves a superior speed--accuracy trade-off on both the nuScenes and Bench2Drive benchmarks' is presented without any metrics, baselines, ablation studies, statistical tests, or description of how the RL scheduler's latency and per-module accuracy are jointly evaluated. This absence makes the central empirical claim impossible to assess.
Authors: We agree that the abstract, as currently written, states the central claim at a high level without quantitative support or evaluation details, which limits immediate assessment from the abstract alone. The full manuscript (Experiments section) contains the requested elements: specific metrics and baselines on both benchmarks, ablation studies isolating the RL scheduler, statistical significance reporting, and a description of the joint latency-accuracy evaluation protocol for the scheduler. To address the concern directly, we will revise the abstract to incorporate key quantitative results and a concise statement of the evaluation approach while remaining within length constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a framework for LLM-based module design and RL-based scheduling in autonomous driving, with central claims resting on experimental results reported on the nuScenes and Bench2Drive benchmarks. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. The architecture is presented as a novel combination of existing techniques without any load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InCVPR, 2020. 7
2020
-
[2]
Solve: Synergy of language-vision and end-to-end networks for autonomous driving
Xuesong Chen, Linjiang Huang, Tao Ma, Rongyao Fang, Shaoshuai Shi, and Hongsheng Li. Solve: Synergy of language-vision and end-to-end networks for autonomous driving. InCVPR, 2025. 3
2025
-
[3]
Asynchronous large language model enhanced planner for autonomous driving
Yuan Chen, Zi-han Ding, Ziqin Wang, Yan Wang, Lijun Zhang, and Si Liu. Asynchronous large language model enhanced planner for autonomous driving. InECCV, 2024. 3
2024
-
[4]
Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. InICCV, 2025. 1, 3
2025
-
[5]
Jianhua Han, Meng Tian, Jiangtong Zhu, Fan He, Huixin Zhang, Sitong Guo, Dechang Zhu, Hao Tang, Pei Xu, Yuze Guo, et al. Percept-wam: Perception-enhanced world-awareness-action model for robust end-to-end autonomous driving.arXiv preprint arXiv:2511.19221, 2025. 1
arXiv 2025
-
[6]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InICLR, 2023. 2, 3
2023
-
[7]
St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. InECCV, 2022. 3
2022
-
[8]
Planning- oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning- oriented autonomous driving. InCVPR, 2023. 1, 3
2023
-
[9]
Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving
Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving. InICCV,
-
[10]
Think twice before driving: Towards scalable decoders for end-to-end autonomous driving
Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. InCVPR, 2023. 3
2023
-
[11]
Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving. InNeurIPS, 2024. 7
2024
-
[12]
Drivetransformer: Unified transformer for scalable end-to-end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to-end autonomous driving. InICLR, 2025. 3
2025
-
[13]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InICCV, 2023. 1, 3
2023
-
[14]
Yongkang Li, Lijun Zhou, Sixu Yan, Bencheng Liao, Tianyi Yan, Kaixin Xiong, Long Chen, Hongwei Xie, Bing Wang, Guang Chen, et al. Unidrivevla: Unifying understanding, perception, and action planning for autonomous driving.arXiv preprint arXiv:2604.02190, 2026. 1
arXiv 2026
-
[15]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, 2025. 3, 8
2025
-
[16]
Zhiwei Lin and Yongtao Wang. Vl-sam-v2: Open-world object detection with general and specific query fusion.arXiv preprint arXiv:2505.18986, 2025. 2, 8
arXiv 2025
-
[17]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InUIST, 2023. 2, 3
2023
-
[18]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. 8
2026
-
[19]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InCVPR, 2025. 1, 3, 8
2025
-
[20]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InNeurIPS, 2023. 2, 3 10
2023
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 7
Pith/arXiv arXiv 2024
-
[22]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, 2023. 2, 3
2023
-
[23]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. In ECCV, 2024. 3
2024
-
[24]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving. InCVPR, 2025. 3
2025
-
[25]
Sparsedrive: End-to- end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End-to- end autonomous driving via sparse scene representation. InICRA, 2025. 3
2025
-
[26]
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[27]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. 2, 3
Pith/arXiv arXiv 2023
-
[28]
Para-drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real-time autonomous driving. InCVPR, 2024. 3
2024
-
[29]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. InNeurIPS, 2022. 3
2022
-
[30]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InCOLM, 2024. 2, 3
2024
-
[31]
Zhongyu Xia, Wenhao Chen, Yongtao Wang, and Ming-Hsuan Yang. Knowval: A knowledge-augmented and value-guided autonomous driving system.arXiv preprint arXiv:2512.20299, 2025. 1, 3, 7, 8
arXiv 2025
-
[32]
Zhongyu Xia, Zhiwei Lin, Yongtao Wang, and Ming-Hsuan Yang. Henet++: Hybrid encoding and multi- task learning for 3d perception and end-to-end autonomous driving.arXiv preprint arXiv:2511.07106,
-
[33]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2022. 2, 3
2022
-
[34]
Bridging past and future: End-to-end autonomous driving with historical prediction and planning
Bozhou Zhang, Nan Song, Xin Jin, and Li Zhang. Bridging past and future: End-to-end autonomous driving with historical prediction and planning. InCVPR, 2025. 3
2025
-
[35]
Driveagent-r1: Advancing vlm-based autonomous driving with active perception and hybrid thinking
Weicheng Zheng, Xiaofei Mao, Nanfei Ye, Pengxiang Li, Kun Zhan, XianPeng Lang, and Hang Zhao. Driveagent-r1: Advancing vlm-based autonomous driving with active perception and hybrid thinking. In ICLR, 2026. 3
2026
-
[36]
Genad: Generative end-to-end autonomous driving
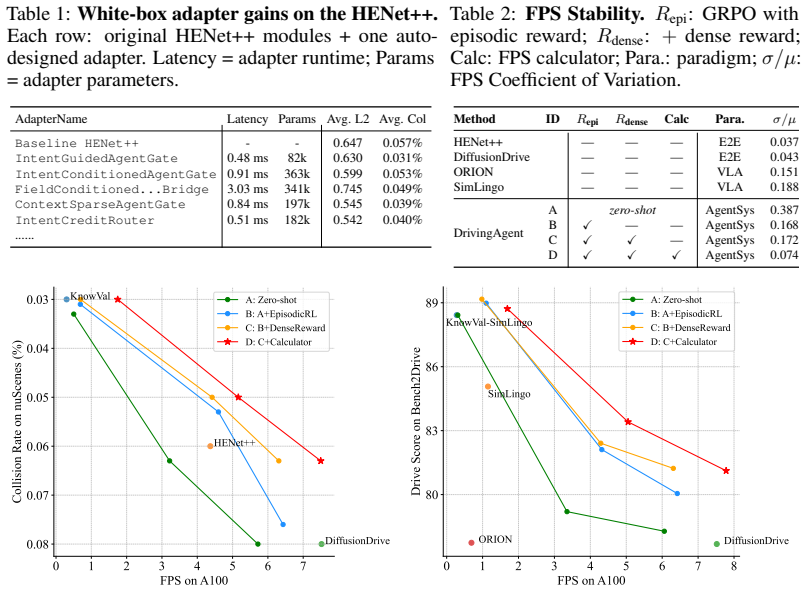
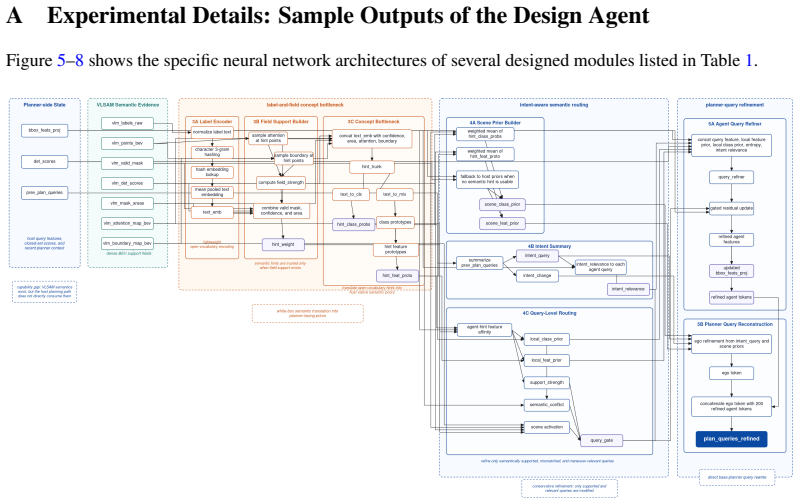
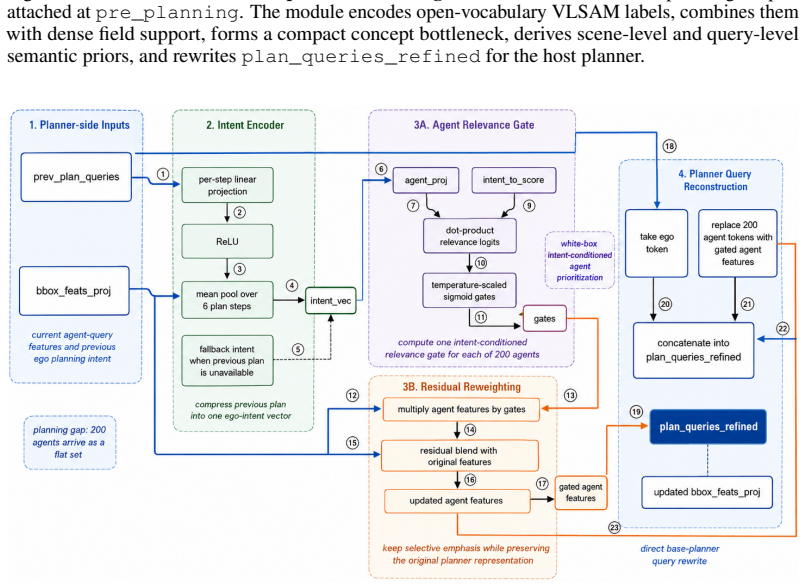
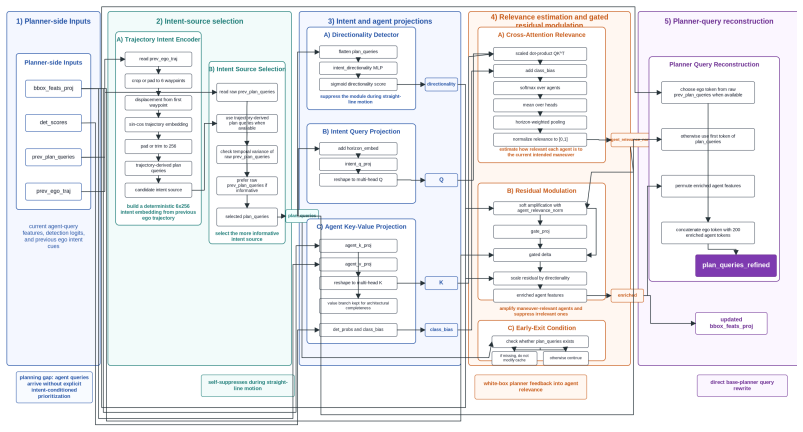
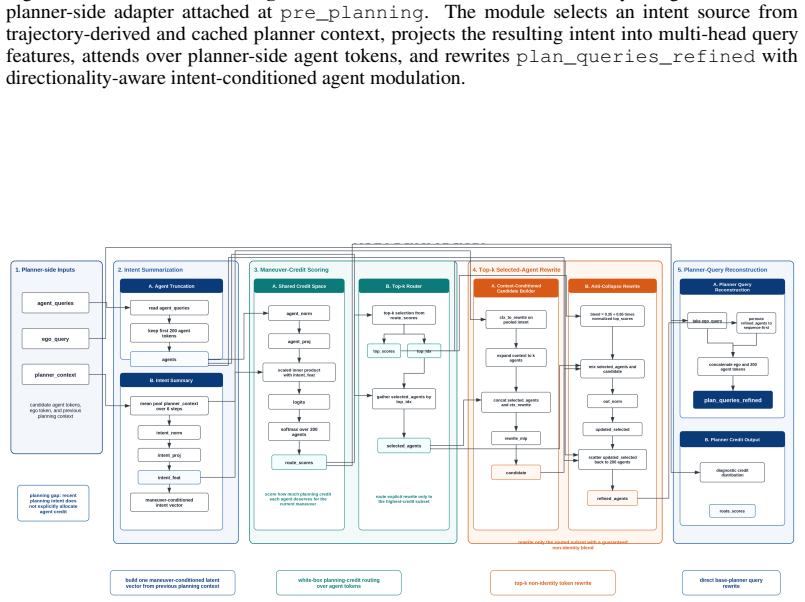
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end autonomous driving. InECCV, 2024. 1, 3 11 A Experimental Details: Sample Outputs of the Design Agent Figure 5–8 shows the specific neural network architectures of several designed modules listed in Table 1. Figure 5:FieldConditionedConceptBottleneckBridge.A ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.