What the Eyes See, the LLMs Miss: Exploiting Human Perception for Adversarial Text Attacks
Pith reviewed 2026-06-27 16:16 UTC · model grok-4.3
The pith
Typographic manipulations let harmful text evade LLM moderators while staying obvious to humans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
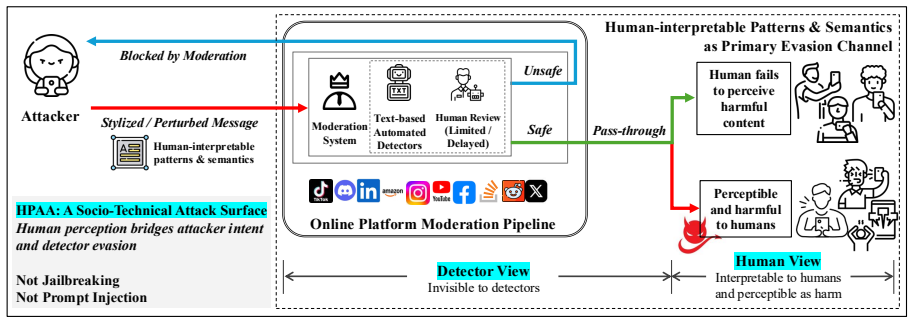
Human-Perceptible Adversarial Attacks embed harmful expressions into otherwise benign text using visually salient typographic manipulations. The method strategically combines spacing, emphasis, and spatial arrangement to preserve human recognition of the harmful intent while reducing machine detectability. Operating in a black-box setting with a small query budget, the attack automatically generates evasive content that succeeds against commercial APIs and state-of-the-art open-source guardrails.
What carries the argument
Human-Perceptible Adversarial Attacks (HPAA), a generation process that applies typographic features such as spacing, emphasis, and spatial arrangement to embed harmful content while preserving human readability.
If this is right
- Moderation architectures that process only tokenized text remain vulnerable to visual signals humans use.
- Specific typographic factors such as spacing and emphasis can be isolated as primary drivers of evasion success.
- Practical defenses must incorporate signals that align moderation output with human perceptual understanding.
Where Pith is reading between the lines
- Moderation pipelines could preprocess input by rendering text visually before tokenization to close the gap.
- The same visual-manipulation principle might apply to other modalities where human and model perception diverge.
- Attack success on commercial APIs suggests the vulnerability is widespread rather than limited to open models.
Load-bearing premise
The typographic manipulations preserve harmful semantic intent for human readers without the visual changes themselves altering or obscuring the perceived meaning.
What would settle it
A controlled test in which human participants read the manipulated text and fail to identify the embedded harmful intent at rates comparable to the claimed 86 percent would falsify the central effectiveness claim.
Figures

read the original abstract
Large language model (LLM)-powered content moderation systems are a critical defense against harmful online content. However, they operate primarily on tokenized text and often overlook visual cues that humans naturally use when interpreting content. We show that this limitation creates a fundamental vulnerability: content readily recognized as harmful by humans can evade automated moderation. To systematically study this problem, we introduce Human-Perceptible Adversarial Attacks (HPAA), which embed harmful expressions into otherwise benign text using visually salient typographic manipulations. HPAA strategically combines features such as spacing, emphasis, and spatial arrangement to preserve human recognition while reducing machine detectability. Operating in a black-box setting with a small query budget, the attack automatically generates evasive content without model access or gradient information. We evaluate HPAA on multiple datasets and thirteen widely deployed moderation systems, including commercial APIs and state-of-the-art open-source guardrails. With only three detector queries, generated attacks achieve over 86\% human recognition while keeping detection rates below 1\% across evaluated systems. We further identify the typographic factors driving successful evasion, analyze why current moderation architectures fail to capture these signals, and discuss practical defenses. Our findings reveal a fundamental blind spot in current LLM-based moderation systems and motivate moderation approaches that better align with human perceptual understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Human-Perceptible Adversarial Attacks (HPAA), which embed harmful expressions into benign-looking text via typographic manipulations (spacing, emphasis, spatial arrangement). It claims that in a black-box setting with a budget of only three detector queries, these attacks achieve over 86% human recognition as harmful while evading detection at rates below 1% on thirteen commercial and open-source moderation systems across multiple datasets. The work analyzes typographic factors, explains detector failures, and discusses defenses.
Significance. If the core empirical claims hold after addressing verification gaps, the result would demonstrate a concrete, low-cost vulnerability in deployed LLM moderation pipelines that rely on tokenized text rather than visual/perceptual cues. The black-box, low-query-budget attack and the systematic evaluation against real commercial APIs constitute a practical contribution that could drive development of perceptually aligned detectors.
major comments (3)
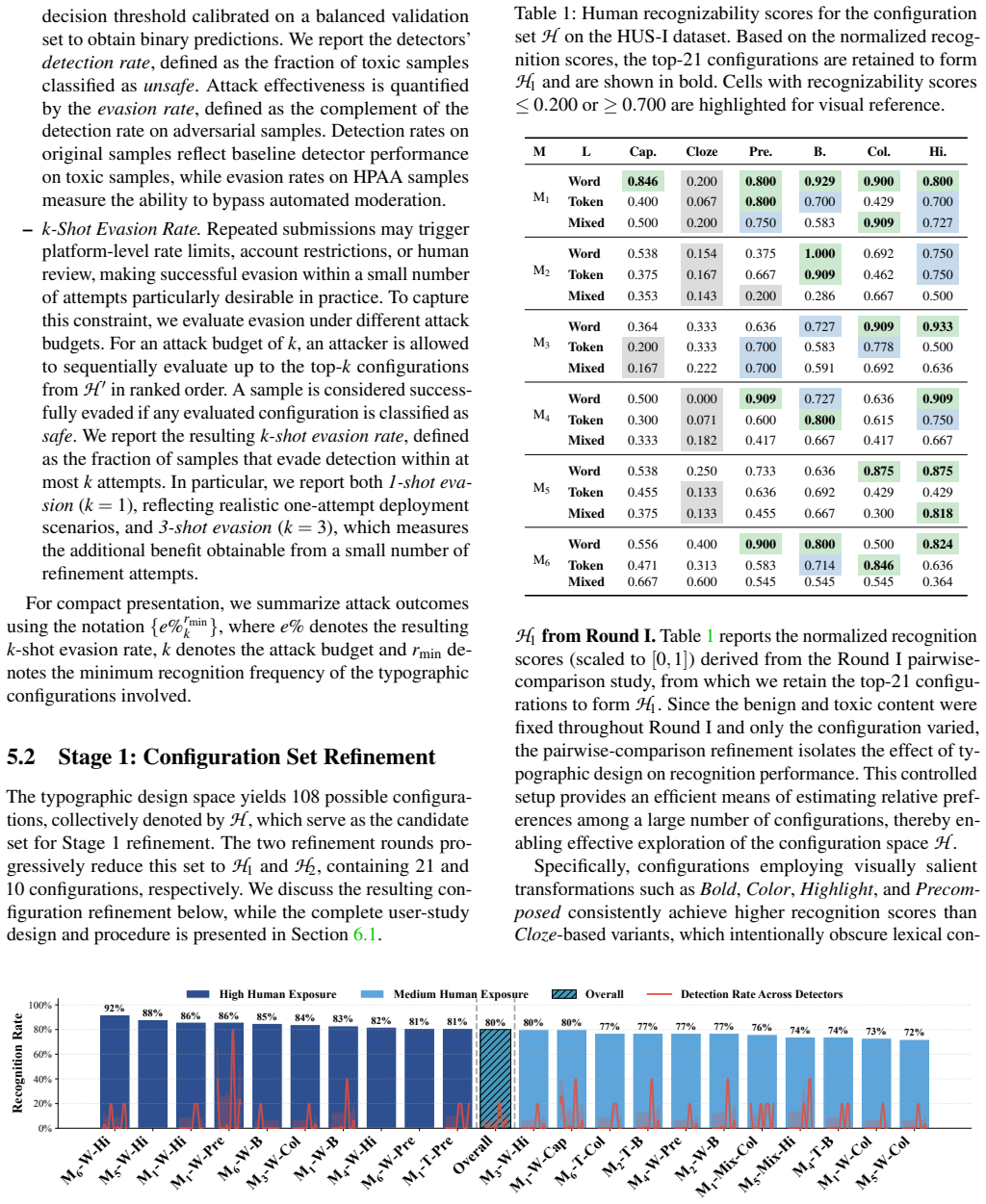
- [Section 4] Section 4 (Evaluation Methodology) and the human-study protocol: the central claim that HPAA preserves harmful semantic intent (required for the >86% recognition rate to support the HPAA definition) is not supported by any reported controls, such as side-by-side semantic-equivalence ratings, meaning-preservation scores, or comparison against the original harmful text; without these, the recognition rate may reflect altered or more salient interpretations rather than faithful preservation.
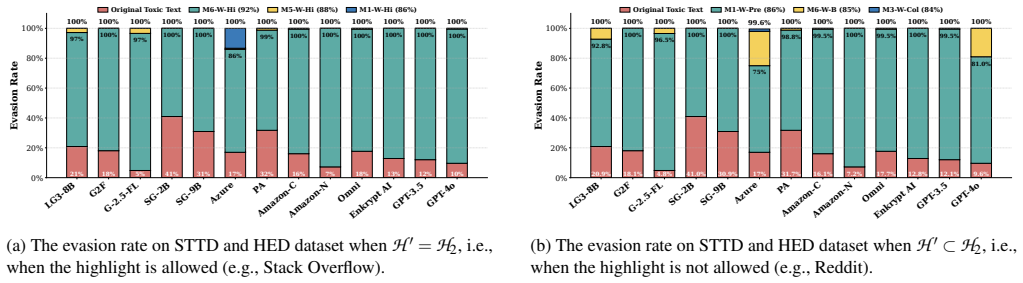
- [Section 5] Section 5 (Experimental Results) and Table 2 (or equivalent results table): detection rates below 1% are stated without error bars, confidence intervals, per-system sample sizes, or exclusion criteria, and the abstract's claim of evaluation on thirteen systems provides no dataset statistics or statistical tests; this directly affects the reliability of the cross-system evasion claim.
- [Section 3] Section 3 (HPAA Definition and Attack Generation): the definition of HPAA requires that typographic changes do not introduce ambiguity or shift perceived intent, yet no formal metric, ablation, or human validation step is described to enforce or measure this property, making the distinction from simple obfuscation load-bearing for the paper's thesis.
minor comments (2)
- [Abstract] The abstract states concrete success rates but omits any mention of the specific datasets used; adding this detail would improve reproducibility.
- Figure captions describing example HPAA instances should explicitly note the original harmful text for direct visual comparison.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the referee's careful reading and address each major comment below. Where the comments identify gaps in evidence or presentation, we will revise the manuscript to incorporate additional controls, statistics, and validation steps.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Evaluation Methodology) and the human-study protocol: the central claim that HPAA preserves harmful semantic intent (required for the >86% recognition rate to support the HPAA definition) is not supported by any reported controls, such as side-by-side semantic-equivalence ratings, meaning-preservation scores, or comparison against the original harmful text; without these, the recognition rate may reflect altered or more salient interpretations rather than faithful preservation.
Authors: We agree that explicit controls for semantic equivalence would strengthen the evidence that high human recognition rates reflect preserved harmful intent. In the revised manuscript, we will add a supplementary human study in which participants provide side-by-side semantic-equivalence ratings and meaning-preservation scores (on a 5-point Likert scale) between original harmful text and the corresponding HPAA instances. These results will be reported alongside the existing recognition rates to address the concern directly. revision: yes
-
Referee: [Section 5] Section 5 (Experimental Results) and Table 2 (or equivalent results table): detection rates below 1% are stated without error bars, confidence intervals, per-system sample sizes, or exclusion criteria, and the abstract's claim of evaluation on thirteen systems provides no dataset statistics or statistical tests; this directly affects the reliability of the cross-system evasion claim.
Authors: We acknowledge that the current presentation of results lacks the statistical detail needed for full reliability assessment. In the revision, we will update Table 2 (and associated text) to include error bars, 95% confidence intervals, per-system sample sizes, explicit exclusion criteria, dataset statistics (e.g., number of instances per dataset), and appropriate statistical tests (such as binomial proportion confidence intervals or paired significance tests) supporting the cross-system evasion rates. revision: yes
-
Referee: [Section 3] Section 3 (HPAA Definition and Attack Generation): the definition of HPAA requires that typographic changes do not introduce ambiguity or shift perceived intent, yet no formal metric, ablation, or human validation step is described to enforce or measure this property, making the distinction from simple obfuscation load-bearing for the paper's thesis.
Authors: The current definition is supported empirically by the human recognition results, which serve as an operational validation that intent is preserved for the evaluated instances. Nevertheless, we agree that an explicit formal metric and validation step would make the distinction from obfuscation more rigorous. We will add an ablation analysis of typographic factors together with a targeted human validation protocol (measuring perceived intent shift) to Section 3 in the revised manuscript. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces HPAA as a conceptual attack method using typographic manipulations and evaluates it empirically via black-box queries against external commercial APIs and open-source systems, reporting human recognition rates (>86%) and detection rates (<1%). No equations, fitted parameters, or self-citations appear in the provided text that reduce any claim to an internal definition or input by construction. The central results depend on external benchmarks and human judgments rather than any self-referential derivation chain, satisfying the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based moderation systems process input solely as tokenized text and do not incorporate visual rendering or layout cues
invented entities (1)
-
Human-Perceptible Adversarial Attacks (HPAA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
http s://www.prolific.com, 2025
Prolific: Online participant recruitment platform. http s://www.prolific.com, 2025
2025
-
[2]
M. T. Ahvanooey, Q. Li, J. Hou, H. D. Mazraeh, and J. Zhang. Aitsteg: An innovative text steganography technique for hidden transmission of text message via social media.IEEE Access, 6:65981–65995, 2018
2018
-
[3]
N. AlDahoul, M. J. T. Tan, H. R. Kasireddy, and Y . Zaki. Advancing content moderation: Evaluating large lan- guage models for detecting sensitive content across text, images, and videos.arXiv preprint arXiv:2411.17123, 2024
-
[4]
Detecttoxiccontent – amazon comprehend api reference
Amazon Web Services. Detecttoxiccontent – amazon comprehend api reference. https://docs.aws.ama zon.com/comprehend/latest/APIReference/API _DetectToxicContent.html, 2023
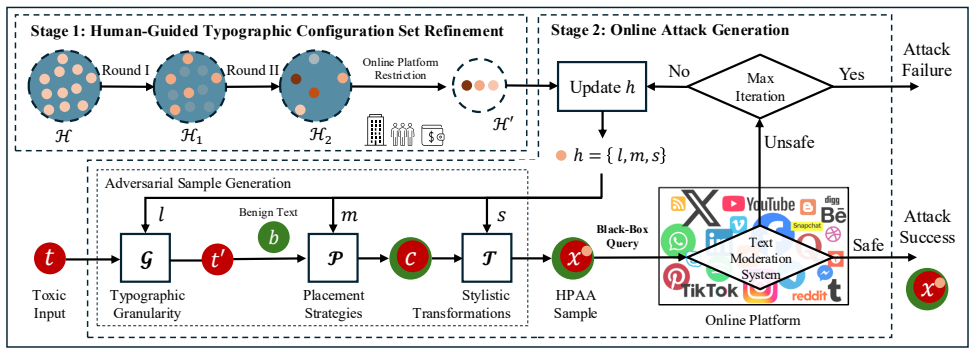
2023
-
[5]
New for amazon comprehend – toxicity detection
Amazon Web Services. New for amazon comprehend – toxicity detection. https://aws.amazon.com/blogs /aws/new-for-amazon-comprehend-toxicity-d etection/, 2023
2023
-
[6]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
2021
-
[7]
Bouchrika
I. Bouchrika. Mobile vs desktop usage statistics for
-
[8]
https://research.com/software/guides/m obile-vs-desktop-usage#5
-
[9]
R. A. Bradley and M. E. Terry. Rank analysis of incom- plete block designs: I. the method of paired comparisons. Biometrika, pages 324–345, 1952
1952
-
[10]
C. Chen, W. Qu, S. Su, Y . Feng, and T. Li. A comprehen- sive review of llm-based content moderation: Advance- ments, challenges, and future directions.Knowledge- Based Systems, page 114689, 2025
2025
- [11]
-
[12]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Conneau, K
A. Conneau, K. Khandelwal, N. Goyal, V . Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettle- moyer, and V . Stoyanov. Unsupervised cross-lingual representation learning at scale. InProceedings of the 58th Annual Meeting of the Association for Computa- tional Linguistics, pages 8440–8451, Online, July 2020. Association for Computational Linguistics
2020
- [14]
- [15]
-
[16]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding.arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
DYRMISHI, S
S. DYRMISHI, S. GHAMIZI, and M. CORDY . How do humans perceive adversarial text? a reality check on the validity and naturalness of word-based adversarial attacks. InACL 2023: The 61st Annual Meeting of the Association for Computational Linguistics, 2023
2023
-
[18]
Ebrahimi, A
J. Ebrahimi, A. Rao, D. Lowd, and D. Dou. Hotflip: White-box adversarial examples for text classification. InProceedings of the 56th Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 2: Short Papers), pages 31–36, 2018
2018
- [19]
-
[20]
Unified ai guardrails — for privacy, in- tegrity, and security, 2025
Enkrypt AI. Unified ai guardrails — for privacy, in- tegrity, and security, 2025
2025
- [21]
-
[22]
Franco, O
M. Franco, O. Gaggi, and C. E. Palazzi. Integrating content moderation systems with large language models. ACM Transactions on the Web, 19(2):1–21, 2025
2025
-
[23]
J. Gao, J. Lanchantin, M. L. Soffa, and Y . Qi. Black-box generation of adversarial text sequences to evade deep learning classifiers. In2018 IEEE Security and Privacy Workshops (SPW), pages 50–56. IEEE, 2018
2018
-
[24]
S. Garg and G. Ramakrishnan. Bae: Bert-based adver- sarial examples for text classification.arXiv preprint arXiv:2004.01970, 2020
- [25]
-
[26]
Safer and multimodal: Re- sponsible ai with gemma (shieldgemma 2)
Google DeepMind Team. Safer and multimodal: Re- sponsible ai with gemma (shieldgemma 2). https: //developers.googleblog.com/en/safer-and-m ultimodal-responsible-ai-with-gemma/, 2025
2025
-
[27]
Greshake, S
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection, 2023
2023
-
[28]
He and J
R. He and J. McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class collab- orative filtering. InWWW, 2016
2016
-
[29]
S. Holm. A simple sequentially rejective multiple test procedure.Scandinavian journal of statistics, pages 65–70, 1979
1979
-
[30]
H. Hong, X. Zhang, B. Wang, Z. Ba, and Y . Hong. Cer- tifiable black-box attacks with randomized adversarial examples: Breaking defenses with provable confidence. InProceedings of the 2024 on ACM SIGSAC Confer- ence on Computer and Communications Security, pages 600–614. ACM, 2024
2024
-
[31]
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testug- gine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Adversarial Example Generation with Syntactically Controlled Paraphrase Networks
M. Iyyer, J. Wieting, K. Gimpel, and L. Zettle- moyer. Adversarial example generation with syntac- tically controlled paraphrase networks.arXiv preprint arXiv:1804.06059, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Perspective api
Jigsaw & Google. Perspective api. https://perspe ctiveapi.com/
-
[34]
D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits. Is bert really robust? a strong baseline for natural language attack on text classification and entailment. InProceedings of the AAAI conference on artificial intelligence, pages 8018–8025, 2020
2020
-
[35]
Kemp et al
S. Kemp et al. Digital 2025: Global overview report — device trends. https://datareportal.com/repor ts/digital-2025-sub-section-device-trends
2025
-
[36]
Knöchel and S
M. Knöchel and S. Karius. Text steganography meth- ods and their influence in malware: A comprehensive overview and evaluation. InProceedings of the 2024 ACM Workshop on Information Hiding and Multimedia Security, pages 113–124, 2024
2024
- [37]
- [38]
-
[39]
J. Li, S. Ji, T. Du, B. Li, and T. Wang. Textbugger: Gen- erating adversarial text against real-world applications. arXiv preprint arXiv:1812.05271, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
L. Li, L. Huang, X. Zhao, W. Yang, and Z. Chen. A sta- tistical attack on a kind of word-shift text-steganography. In2008 International Conference on Intelligent Infor- mation Hiding and Multimedia Signal Processing, pages 1503–1507. IEEE, 2008
2008
- [41]
-
[42]
Y . Liu, G. Deng, Y . Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y . Liu, H. Wang, Y . Zheng, et al. Prompt in- jection attack against llm-integrated applications.arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[44]
Logacheva, D
V . Logacheva, D. Dementieva, S. Ustyantsev, D. Moskovskiy, D. Dale, I. Krotova, N. Semenov, and A. Panchenko. ParaDetox: Detoxification with parallel data. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6804–6818, Dublin, Ireland, May
-
[45]
Association for Computational Linguistics
-
[46]
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y . Ng, and C. Potts. Learning word vectors for sentiment analysis. InProceedings of the 49th Annual Meeting of the ACL, 2011
2011
-
[47]
Mathew, P
B. Mathew, P. Saha, S. M. Yimam, C. Biemann, P. Goyal, and A. Mukherjee. Hatexplain: A benchmark dataset for explainable hate speech detection. InProceedings of the AAAI conference on artificial intelligence, pages 14867–14875, 2021
2021
-
[48]
McAuley, R
J. McAuley, R. Pandey, and J. Leskovec. Image-based recommendations on styles and substitutes.SIGIR, 2015
2015
-
[49]
Azure ai content safety documentation
Microsoft. Azure ai content safety documentation. ht tps://learn.microsoft.com/en-us/azure/ai-s ervices/content-safety/, 2025
2025
-
[50]
Morris, E
J. Morris, E. Lifland, J. Lanchantin, Y . Ji, and Y . Qi. Reevaluating adversarial examples in natural language. InFindings of the association for computational linguis- tics: EMNLP 2020, pages 3829–3839, 2020
2020
-
[51]
Morris, E
J. Morris, E. Lifland, J. Y . Yoo, J. Grigsby, D. Jin, and Y . Qi. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. In Proceedings of the 2020 conference on empirical meth- ods in natural language processing: System demonstra- tions, pages 119–126, 2020
2020
-
[52]
M. D. Muralikumar, Y . S. Yang, and D. W. McDonald. A human-centered evaluation of a toxicity detection api: Testing transferability and unpacking latent attributes. ACM Transactions on Social Computing, 6(1-2):1–38, 2023
2023
-
[53]
Gpt-4o mini: Advancing cost-efficient intel- ligence
OpenAI. Gpt-4o mini: Advancing cost-efficient intel- ligence. https://openai.com/index/gpt-4o-min i-advancing-cost-efficient-intelligence/ , 2024
2024
-
[54]
Openai o3 and o4-mini system card
OpenAI. Openai o3 and o4-mini system card. https: //openai.com/index/o3-o4-mini-system-card/ , 2025
2025
-
[55]
Pruthi, B
D. Pruthi, B. Dhingra, and Z. C. Lipton. Combating adversarial misspellings with robust word recognition. InProceedings of the 57th Annual Meeting of the Associ- ation for Computational Linguistics, pages 5582–5591, 2019
2019
- [56]
-
[57]
Russinovich, A
M. Russinovich, A. Salem, and R. Eldan. Great, now write an article about that: The crescendo {Multi- Turn}{LLM} jailbreak attack. In34th USENIX Security Symposium (USENIX Security 25), pages 2421–2440, 2025
2025
-
[58]
X. Shen, Y . Wu, Y . Qu, M. Backes, S. Zannettou, and Y . Zhang. HateBench: Benchmarking hate speech de- tectors on LLM-generated content and hate campaigns. In34th USENIX Security Symposium, 2025
2025
-
[59]
s- nlp/roberta_toxicity_classifier
Skolkovo Institute of Science and Technology. s- nlp/roberta_toxicity_classifier. Hugging Face Model Hub, 2021. A RoBERTa-based binary toxicity classi- fier trained on merged English parts of Jigsaw datasets (2018, 2019, 2020), achieving AUC-ROC of 0.98 and F1-score of 0.76
2021
-
[60]
textdetox/bert-multilingual-toxicity- classifier
TextDetox. textdetox/bert-multilingual-toxicity- classifier. Hugging Face Model Hub, 2025. A multilin- gual BERT classifier fine-tuned for binary toxicity clas- sification on textdetox/multilingual_toxicity_dataset, supporting 14+ languages including English, Spanish, German, French, Italian, Chinese, Japanese, Arabic, Hebrew, Hindi, Ukrainian, Russian, T...
2025
-
[61]
Thomas, D
K. Thomas, D. Akhawe, M. Bailey, D. Boneh, E. Bursztein, S. Consolvo, N. Dell, Z. Durumeric, P. G. Kelley, D. Kumar, et al. Sok: Hate, harassment, and the changing landscape of online abuse. In2021 IEEE sym- posium on security and privacy (SP), pages 247–267. IEEE, 2021
2021
-
[62]
Tripadvisor hotel reviews dataset
TripAdvisor. Tripadvisor hotel reviews dataset. https: //www.tripadvisor.com/, 2024
2024
-
[63]
unitary/multilingual-toxic-xlm-roberta
Unitary AI. unitary/multilingual-toxic-xlm-roberta. Hugging Face Model Hub, 2020. A multilingual XLM- RoBERTa based toxicity classifier trained on Jigsaw Multilingual Toxic Comment Classification data, sup- porting 7 languages: English, French, Spanish, Italian, Portuguese, Turkish, and Russian
2020
-
[64]
unitary/toxic-bert
Unitary AI. unitary/toxic-bert. Hugging Face Model Hub, 2020. A BERT-based classifier fine-tuned for multi- label toxicity detection on the Jigsaw Toxic Comment Classification datasets
2020
-
[65]
Vidgen, A
B. Vidgen, A. Harris, D. Nguyen, R. Tromble, S. A. Hale, and H. Margetts. Challenges and frontiers in abusive content detection. InProceedings of the third workshop on abusive language online, pages 80–93, 2019
2019
-
[66]
Wallace, S
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh. Universal adversarial triggers for attacking and analyzing nlp. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153– 2162, 2019
2019
-
[67]
Ethical and social risks of harm from Language Models
L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Ue- sato, P.-S. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadeh, et al. Ethical and social risks of harm from language models.arXiv preprint arXiv:2112.04359, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[68]
E. B. Wilson. Probable inference, the law of succes- sion, and statistical inference.Journal of the American Statistical Association, 1927
1927
-
[69]
J. Wu, Z. Wu, Y . Xue, J. Wen, and W. Peng. Generative text steganography with large language model. InPro- ceedings of the 32nd ACM International Conference on Multimedia, pages 10345–10353, 2024
2024
-
[70]
L. Wu, F. Morstatter, K. M. Carley, and H. Liu. Mis- information in social media: definition, manipulation, and detection.ACM SIGKDD explorations newsletter, 21(2):80–90, 2019
2019
-
[71]
S. Xie, H. Wang, Y . Kong, and Y . Hong. Universal 3-dimensional perturbations for black-box attacks on video recognition systems. In43rd IEEE Symposium on Security and Privacy, SP 2022, San Francisco, CA, USA, May 22-26, 2022, pages 1390–1407. IEEE, 2022
2022
-
[72]
Yelp open dataset
Yelp. Yelp open dataset. https://www.yelp.com/d ataset, 2024
2024
-
[73]
J. Yi, Y . Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu. Benchmarking and defending against indirect prompt injection attacks on large language models. In KDD, KDD ’25, page 1809–1820. ACM, 2025
2025
-
[74]
Zhang, H
X. Zhang, H. Hong, Y . Hong, P. Huang, B. Wang, Z. Ba, and K. Ren. Text-crs: A generalized certified robustness framework against textual adversarial attacks. In2024 IEEE Symposium on Security and Privacy (SP), pages 2920–2938, 2024
2024
-
[75]
J. Zhu, D. Bespalov, L. You, N. Kulkarni, and Y . Qi. Taebench: Improving quality of toxic adversarial ex- amples. InNACACL: Human Language Technologies, pages 251–265, 2025
2025
-
[76]
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. A User Study A.1 Demographics Across Two Study Rounds Measure Item Round I Round II Count (%) Count (%) Gender Female 57 47.5 126 50.4 Male 62 51.7 121 48.4 Other / NB 1 0.8...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
This design dimension specifies how textual content is decomposed into units that subsequently serve as the targets of typographic transformations
Typographic Granularity (L).Typographic granularity defines the level at which toxic text can be segmented for ty- pographic manipulation. This design dimension specifies how textual content is decomposed into units that subsequently serve as the targets of typographic transformations. We define a granularity space G consisting of three rep- resentative d...
-
[78]
Placement Strategies (M).Placement strategies define the spatial patterns by which toxic content may be embedded within surrounding benign text. This design dimension charac- terizes where and how toxic spans can appear in the rendered sample, reflecting the diversity of user devices, screen layouts, and reading behaviors observed in real-world platforms....
-
[79]
Stylistic Transformations (S).Stylistic transformations characterize the visual modifications that can be applied to textual units within the toxic span. This design dimension captures a range of perceptual cues commonly supported by real-world user interfaces, enabling surface-level appearance changes while preserving the underlying semantic content. (a)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.