LLM-as-Judge in Education: A Curriculum-Grounded Marking Pipeline
Pith reviewed 2026-06-27 01:33 UTC · model grok-4.3
The pith
A staged LLM workflow marks exam answers comparably to human tutors by grounding each step in official syllabus artefacts and marking guidelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
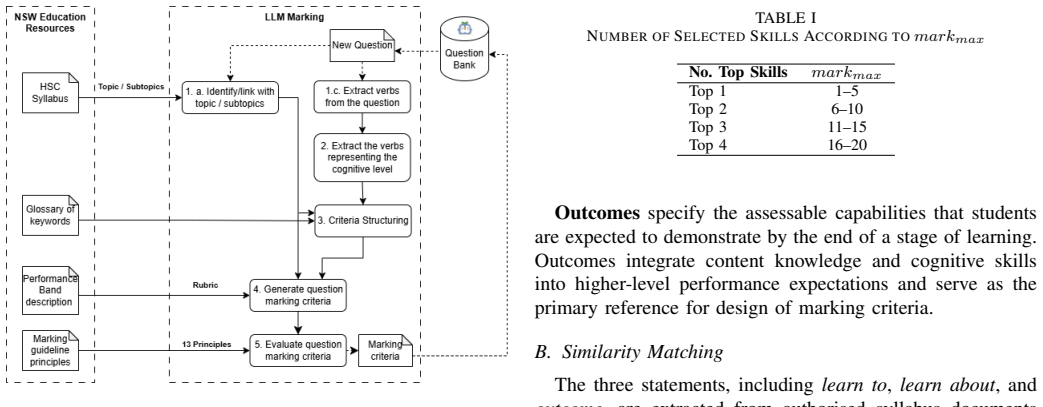
The paper presents a curriculum-grounded LLM-as-Judge pipeline that operationalises marking through concrete syllabus artefacts: it extracts relevant topics and cognitive demand, assembles authorised context, generates question-specific rubrics, and then derives and applies marking criteria to student responses, yielding outcomes comparable to human tutors with justifications more traceable to official documents.
What carries the argument
The staged LLM workflow that first generates question-specific rubrics from syllabus artefacts and then evaluates responses against those rubrics.
If this is right
- Marking consistency and transparency increase because every step references explicit curriculum artefacts.
- Alignment with official marking practices improves relative to ungrounded LLM prompts.
- The same pipeline can be reconfigured for different subjects or exam boards by swapping the input syllabus documents.
- Early deployment data on an online platform can reveal how often human overrides occur and which question types trigger them.
Where Pith is reading between the lines
- If the pipeline generalises, it could support more frequent low-stakes practice testing without a linear rise in tutor time.
- The traceability feature might allow regulators or schools to audit AI marks against the exact documents that define the curriculum.
- Similar staged workflows could be tested on open-ended coursework or teacher training materials where alignment to published standards also matters.
Load-bearing premise
A staged LLM process can extract curriculum intent from syllabus documents and apply it without introducing uncorrected misalignment or invented criteria.
What would settle it
A side-by-side comparison on several hundred real student responses in which the pipeline's marks differ from human tutor marks by more than one mark on average or in which its justifications cite criteria absent from the supplied syllabus artefacts.
Figures
read the original abstract
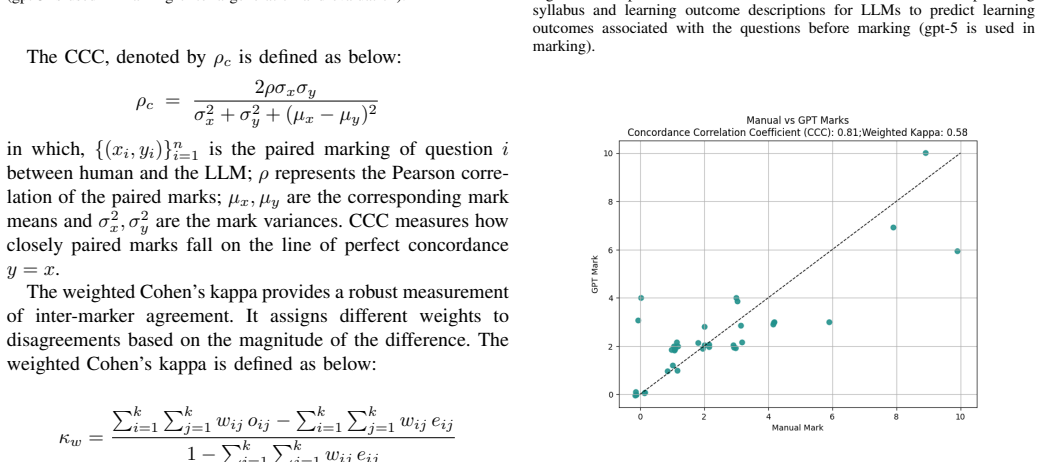
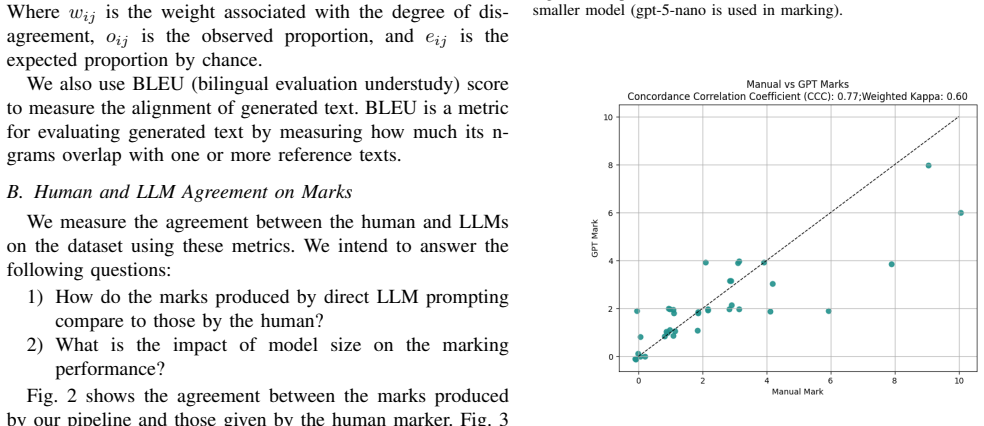
Generative AI and large language models (LLMs) are increasingly applied to question generation and automated assessment. However, deploying LLMs in preparation for high-stakes exams requires more than prompt engineering; it demands software pipelines that systematically ground model outputs in authorised curriculum artefacts and marking guidelines issued by education authorities. This paper presents a curriculum-grounded, configurable LLM-as-Judge pipeline for question-level marking, co-developed with an industrial partner, to support exam preparation for university admission. The pipeline identifies the relevant topics, subtopics, and cognitive demand of a question, and assembles verifiable and authorised context to support LLM judgement. Curriculum intent is operationalised through concrete syllabus artefacts, including prescribed verbs and outcomes, performance band descriptors, glossary definitions, and marking-guideline principles. A staged LLM workflow is employed to first generate question-specific rubrics, capturing structured expectations of performance, and then derive and evaluate marking criteria used to allocate marks to student responses. This design improves consistency, transparency, and alignment with official marking practices. Preliminary evaluation shows that the proposed LLM-as-Judge pipeline delivers marking outcomes comparable to human tutors, while yielding justifications that are more traceable to authorised curriculum artefacts and marking standards. The pipeline has also been integrated into an online study platform, where early deployment data provide initial insights into operational usage and manual overrides.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a configurable, curriculum-grounded LLM-as-Judge pipeline for question-level marking in university-admission exam preparation. The pipeline first identifies topics, subtopics and cognitive demand from a question, then assembles authorised syllabus artefacts (prescribed verbs, outcomes, performance-band descriptors, glossary entries and marking-guideline principles) to generate structured rubrics via a staged LLM workflow; a second stage applies those criteria to student responses. The central claim is that a preliminary evaluation shows marking outcomes comparable to human tutors while producing justifications more traceable to official curriculum documents; the system has also been integrated into an online study platform.
Significance. If the evaluation can be made reproducible and statistically grounded, the work would offer a practical engineering pattern for deploying LLMs in high-stakes educational assessment while preserving alignment with authoritative curriculum artefacts. The industrial co-development and live-platform deployment are concrete strengths that move the contribution beyond pure prompt engineering. At present, however, the absence of methodological detail in the evaluation section substantially weakens the evidential basis for the comparability claim.
major comments (2)
- [Preliminary Evaluation] The section describing the preliminary evaluation provides no information on sample size, response selection or exclusion criteria, inter-rater agreement metrics, statistical tests comparing LLM and human marks, baselines, or error bars. Because this evaluation is the sole empirical support for the central claim of comparability, the omission is load-bearing.
- [Pipeline Design / Staged LLM Workflow] The staged workflow that extracts curriculum intent and assembles rubrics from syllabus artefacts is presented as the primary safeguard against misalignment, yet no separate validation, error analysis, or human audit of the rubric-generation stage is reported. This leaves the weakest assumption untested.
minor comments (1)
- [Abstract / Introduction] The abstract and introduction should more explicitly flag that all empirical results are preliminary and that detailed evaluation protocols appear only in a later section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where additional methodological detail would strengthen the manuscript. We respond to each major comment below and indicate the revisions planned.
read point-by-point responses
-
Referee: [Preliminary Evaluation] The section describing the preliminary evaluation provides no information on sample size, response selection or exclusion criteria, inter-rater agreement metrics, statistical tests comparing LLM and human marks, baselines, or error bars. Because this evaluation is the sole empirical support for the central claim of comparability, the omission is load-bearing.
Authors: We agree that the preliminary evaluation section requires greater methodological transparency to support the comparability claim. In the revised manuscript we will expand the section to report the sample size of student responses evaluated, the selection and exclusion criteria applied, and any inter-rater agreement metrics that were computed between LLM and human marks. We will also explicitly note the absence of formal statistical tests or baselines as a limitation of this preliminary study and provide qualitative observations on marking alignment where quantitative tests were not performed. revision: yes
-
Referee: [Pipeline Design / Staged LLM Workflow] The staged workflow that extracts curriculum intent and assembles rubrics from syllabus artefacts is presented as the primary safeguard against misalignment, yet no separate validation, error analysis, or human audit of the rubric-generation stage is reported. This leaves the weakest assumption untested.
Authors: The staged workflow is presented as the core mechanism for curriculum grounding, yet the manuscript does not include a dedicated validation, error analysis, or human audit of the rubric-generation stage. We will revise the text to acknowledge this gap explicitly as a limitation of the current preliminary evaluation and to outline plans for future targeted audits of rubric quality. A small-scale human review of generated rubrics may be added if the necessary data can be obtained without delaying the revision. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents a descriptive engineering pipeline for curriculum-grounded LLM marking with no equations, fitted parameters, or mathematical derivations. The central claim rests on a preliminary evaluation of comparability to human tutors and traceability to external syllabus artefacts; this does not reduce to self-definition, fitted-input renaming, or load-bearing self-citation chains. The workflow explicitly imports authorised curriculum documents as independent inputs rather than deriving them internally, rendering the reported result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Wang, W. Fan, The effect of chatgpt on students’ learning perfor- mance, learning perception, and higher-order thinking: insights from a meta-analysis, Humanities and Social Sciences Communications 12 (1) (2025) 1–21
2025
-
[2]
Microsoft Education, Ai in education report: Insights to support teaching and learning, accessed: 2026-01-01 (Aug. 2025). URL https://www.microsoft.com/en-us/education/blog/2025/08/ ai-in-education-report-insights-to-support-teaching-and-learning/
2026
-
[3]
URL https://static.googleusercontent.com/media/publicpolicy.google/en/ /resources/our life with ai 2026.pdf
Google, Ipsos, Our life with ai: From experimental to essential, Tech- nical report, Google Public Policy, third annual global survey on AI adoption and attitudes (January 2026). URL https://static.googleusercontent.com/media/publicpolicy.google/en/ /resources/our life with ai 2026.pdf
2026
-
[4]
R. E. Bennett, Formative assessment: A critical review, Assessment in Education: Principles, Policy & Practice 18 (1) (2011) 5–25. doi:10.1080/0969594X.2010.513678. URL https://doi.org/10.1080/0969594X.2010.513678
-
[5]
Messer, N
M. Messer, N. C. Brown, M. K ¨olling, M. Shi, How consistent are humans when grading programming assignments?, ACM Transactions on Computing Education 25 (4) (2025) 1–37
2025
-
[6]
Australian Curriculum, Assessment and Reporting Authority (ACARA), Latest data shows 2024 NAPLAN national results broadly stable, https://www.acara.edu.au/docs/default-source/media-releases/ media-release-2024-naplan-national-results-release-14-8-24.pdf, accessed: 2025-12-21 (August 14 2024)
2024
-
[7]
Scaria, S
N. Scaria, S. Dharani Chenna, D. Subramani, Automated educational question generation at different bloom’s skill levels using large language models: Strategies and evaluation, in: A. M. Olney, I.-A. Chounta, Z. Liu, O. C. Santos, I. I. Bittencourt (Eds.), Artificial Intelligence in Education, Springer Nature Switzerland, Cham, 2024, pp. 165–179
2024
-
[8]
J. Gu, X. Jiang, Z. Shi, H. Tan, X. Zhai, C. Xu, W. Li, Y . Shen, S. Ma, H. Liu, S. Wang, K. Zhang, Y . Wang, W. Gao, L. Ni, J. Guo, A survey on llm-as-a-judge (2025). arXiv:2411.15594. URL https://arxiv.org/abs/2411.15594
Pith/arXiv arXiv 2025
-
[9]
P. Lagakis, S. Demetriadis, Automated essay scoring: A review of the field, in: 2021 International Conference on Computer, In- formation and Telecommunication Systems (CITS), 2021, pp. 1–6. doi:10.1109/CITS52676.2021.9618476
-
[10]
L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P.-S. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadeh, Z. Kenton, S. Brown, W. Hawkins, T. Stepleton, C. Biles, A. Birhane, J. Haas, L. Rimell, L. A. Hendricks, W. Isaac, S. Legassick, G. Irving, I. Gabriel, Ethical and social risks of harm from language models (2021). arXiv:2112.04359. URL http...
Pith/arXiv arXiv 2021
-
[11]
Polanyi, The Tacit Dimension, University of Chicago Press, 1966
M. Polanyi, The Tacit Dimension, University of Chicago Press, 1966
1966
-
[12]
Lockwood, Handbook of automated essay evaluation current applica- tions and new directions mark d
J. Lockwood, Handbook of automated essay evaluation current applica- tions and new directions mark d. shermis and jill burstein (eds.)(2013), Writing & Pedagogy 6 (2) (2014) 437–442
2013
-
[13]
Ramesh, S
D. Ramesh, S. K. Sanampudi, An automated essay scoring systems: a systematic literature review, Artificial Intelligence Review 55 (3) (2022) 2495–2527
2022
-
[14]
Hashemi, J
H. Hashemi, J. Eisner, C. Rosset, B. Van Durme, C. Kedzie, Llm- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 13806– 13834
2024
-
[15]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al., Judging llm-as-a-judge with mt-bench and chatbot arena, Advances in neural information processing systems 36 (2023) 46595–46623
2023
-
[16]
Z. Fan, W. Wang, D. Zhang, et al., Sedareval: Automated evaluation using self-adaptive rubrics, in: Findings of the Association for Compu- tational Linguistics: EMNLP 2024, 2024, pp. 16916–16930
2024
-
[17]
URL https://www.education.sa.gov.au/department/media-centre/ our-news/ai-tool-saves-teachers-thousands-of-hours-of-work
Department for Education, South Australia, Ai tool saves teachers thousands of hours of work, accessed: 2026-01-01 (2025). URL https://www.education.sa.gov.au/department/media-centre/ our-news/ai-tool-saves-teachers-thousands-of-hours-of-work
2026
-
[18]
URL https://doi.org/10.1016/j.rmal.2023.100050
A. Mizumoto, M. Eguchi, Exploring the potential of using an ai language model for automated essay scoring, Research Methods in Applied Linguistics 2 (2) (2023) 100050. doi:https://doi.org/10.1016/j.rmal.2023.100050. URL https://www.sciencedirect.com/science/article/pii/ S2772766123000101
-
[19]
P. Y . Liew, I. K. T. Tan, On automated essay grading using large language models, in: Proceedings of the 2024 8th International Conference on Computer Science and Artificial Intelligence, CSAI ’24, Association for Computing Machinery, New York, NY , USA, 2025, p. 204–211. doi:10.1145/3709026.3709030. URL https://doi.org/10.1145/3709026.3709030
- [20]
-
[21]
G. Kurdi, J. Leo, B. Parsia, U. Sattler, S. Al-Emari, A systematic review of automatic question generation for educational purposes, Int J Artif Intell Educ 39 (1) (2020). URL https://link.springer.com/article/10.1007/s40593-019-00186-y
-
[22]
A. Yaacoub, J. Da-Rugna, Z. Assaghir, Assessing ai-generated ques- tions’ alignment with cognitive frameworks in educational assessment, International Journal of Computer Theory and Engineering 17 (3) (2025) 114–125. doi:10.7763/ijcte.2025.v17.1374. URL http://dx.doi.org/10.7763/IJCTE.2025.V17.1374
-
[23]
Z. Yao, A. Parashar, H. Zhou, W. S. Jang, F. Ouyang, Z. Yang, H. Yu, Mcqg-srefine: Multiple choice question generation and evaluation with iterative self-critique, correction, and comparison feedback, in: Proceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologie...
2025
-
[24]
S. S. Mucciaccia, T. M. Paix ˜ao, F. W. Mutz, C. S. Badue, A. F. de Souza, T. Oliveira-Santos, Automatic multiple-choice question gener- ation and evaluation systems based on llm: A study case with university resolutions, in: Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 2246–2260
2025
-
[25]
X. Xu, D. Zhang, W. Zhang, Q. Lu, L. Zhu, Design Process for Retrieval Augmented Generation Systems , in: 2025 IEEE 22nd International Conference on Software Architecture Companion (ICSA- C), IEEE Computer Society, Los Alamitos, CA, USA, 2025, pp. 482–487. doi:10.1109/ICSA-C65153.2025.00072. URL https://doi.ieeecomputersociety.org/10.1109/ICSA-C65153.2025. 00072
-
[26]
R. Yang, M. Fu, C. Tantithamthavorn, C. Arora, L. Vandenhurk, J. Chua, Ragva: Engineering retrieval augmented generation-based virtual assistants in practice, Journal of Systems and Software 226 (2025) 112436. doi:https://doi.org/10.1016/j.jss.2025.112436. URL https://www.sciencedirect.com/science/article/pii/ S0164121225001049
-
[27]
Z. Li, Z. Wang, W. Wang, K. Hung, H. Xie, F. L. Wang, Retrieval- augmented generation for educational application: A systematic survey, Computers and Education: Artificial Intelligence 8 (2025) 100417. doi:https://doi.org/10.1016/j.caeai.2025.100417. URL https://www.sciencedirect.com/science/article/pii/ S2666920X25000578
-
[28]
X. Xu, D. Zhang, Q. Liu, Q. Lu, L. Zhu, Agentic rag with human-in- the-retrieval, in: 2025 IEEE 22nd International Conference on Software Architecture Companion (ICSA-C), 2025, pp. 498–502
2025
-
[29]
Bradley Knox, and Todd Kulesza
S. Amershi, M. Cakmak, W. B. Knox, T. Kulesza, Power to the people: The role of humans in interactive machine learning, AI Magazine 35 (4) (2014) 105–120. doi:10.1609/aimag.v35i4.2513. URL https://ojs.aaai.org/aimagazine/index.php/aimagazine/article/view/ 2513
-
[30]
B.S.Bloom, Taxonomy of Educational Objectives: The Classification of Educational Goals, no. v. 1 in Taxonomy of Educational Objectives: The Classification of Educational Goals, D. McKay, 1956. URL https://books.google.com.au/books?id=hos6AAAAIAAJ
1956
-
[31]
Anderson, D
L. Anderson, D. Krathwohl, A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives, Longman, 2001. URL https://books.google.com.au/books?id=EMQlAQAAIAAJ
2001
-
[32]
Rafailov, Y
R. Rafailov, Y . Chittepu, R. Park, H. S. Sikchi, J. Hejna, B. Knox, C. Finn, S. Niekum, Scaling laws for reward model overoptimization in direct alignment algorithms, Advances in Neural Information Processing Systems 37 (2024) 126207–126242. APPENDIX A. LLM Marking Prompt Template Direct LLM Marking Prompt Using the following context from the Economics s...
2024
-
[33]
- Do NOT prefer human or AI outputs by default
Justification quality Important rules: - Do NOT assume either response is correct. - Do NOT prefer human or AI outputs by default. - For Mark defensibility, ignore how well the mark is explained and ignore writing quality/tone. - For Justification quality, do not reward verbosity; prefer specific, evidence-based explanations. - Penalize any claims not sup...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.