SilentRetrieval: Hijacking Retrieval-Augmented Generation via Semantically-Preserving Adversarial Data Poisoning
Pith reviewed 2026-06-29 11:47 UTC · model grok-4.3
The pith
SilentRetrieval shows one fluent poisoned document can hijack RAG retrieval and steer LLM outputs at over 80 percent hit rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
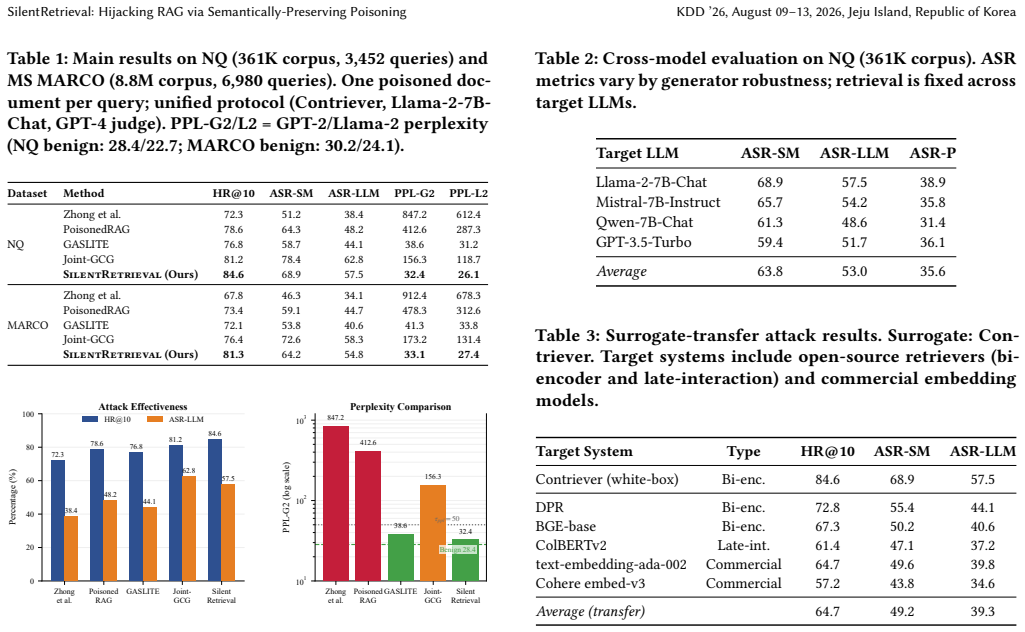
SilentRetrieval is a two-stage attack in which Coordinated Beam Search jointly optimizes poisoned host documents for retrievability and fluency, after which Context-Adaptive Trigger Generation embeds manipulation triggers; under a one-poisoned-document-per-query protocol with synthetic targets, the method reaches 84.6 percent HR@10 and 57.5 percent ASR-LLM on Natural Questions while keeping perplexity near benign levels, with cross-model and cross-retriever transfer also observed.
What carries the argument
Coordinated Beam Search, a multi-token joint optimization that balances similarity and fluency objectives, paired with Context-Adaptive Trigger Generation that inserts triggers via a frozen LLM.
If this is right
- The attack transfers to unseen retrievers including ColBERT and commercial embeddings, yielding 64.7 percent average HR@10.
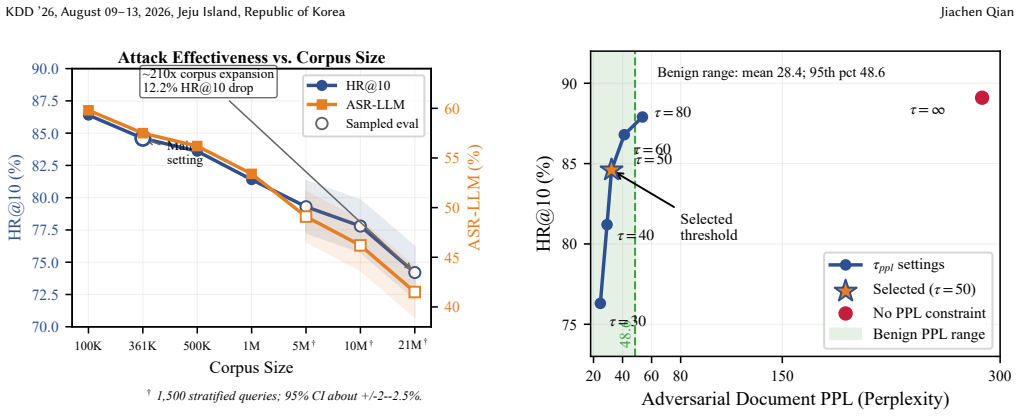
- At a 0.016 percent poisoning ratio in a Wikipedia-scale corpus the method still achieves 74.2 percent HR@10.
- Cross-model evaluation across four target LLMs shows nontrivial success with a fixed trigger generator.
- Combined retrieval-side and generation-side defenses reduce attack success but introduce latency overhead.
- Human evaluators flag the poisoned documents at substantially lower rates than disfluent baselines.
Where Pith is reading between the lines
- RAG deployments may need corpus validation stronger than perplexity checks to catch semantically preserved poisons.
- Effectiveness could decline when natural queries lack synthetic targets or when multiple documents compete during retrieval.
- The two-stage optimization could be adapted to test poisoning resistance in other retrieval-based systems beyond RAG.
Load-bearing premise
The reported attack success depends on evaluating with only one poisoned document per query and using synthetic target answers.
What would settle it
Running the same attack on a corpus containing multiple relevant documents per query or on natural queries without synthetic targets and measuring whether HR@10 and ASR-LLM drop substantially would test the central claim.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG) mitigates LLM hallucinations but introduces a critical vulnerability: corpus integrity. We present SilentRetrieval, a two-stage data poisoning attack that hijacks RAG systems through adversarially crafted yet fluent documents. Stage 1 uses Coordinated Beam Search, a multi-token joint optimization method with a fluency-similarity objective, to keep a poisoned host document retrievable while constraining perplexity. Stage 2 uses Context-Adaptive Trigger Generation, a lightweight trigger-fusion step driven by a frozen LLM, to integrate manipulation triggers into document content. Under a one-poisoned-document-per-query evaluation with synthetic target answers, SilentRetrieval achieves 84.6%/81.3% HR@10 and 57.5%/54.8% ASR-LLM on Natural Questions and MS MARCO, while maintaining near-benign perplexity. Cross-model evaluation across four target LLMs shows nontrivial effectiveness under a fixed trigger generator, and transfer tests against unseen retrievers, including ColBERT and commercial embedding models, yield 64.7% average HR@10 under the same injected-corpus protocol. In a sampled Wikipedia-scale evaluation, SilentRetrieval retains 74.2% HR@10 at a 0.016% poisoning ratio. Combined retrieval-side and generation-side defenses reduce attack success substantially but incur a latency trade-off. Human evaluation shows substantially lower flag rates than disfluent baselines, while remaining numerically more suspicious than benign content at the current sample size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SilentRetrieval, a two-stage data-poisoning attack on RAG systems. Stage 1 employs Coordinated Beam Search to optimize poisoned documents for both retrievability and low perplexity; Stage 2 uses Context-Adaptive Trigger Generation to embed manipulation triggers. Under a one-poisoned-document-per-query protocol with synthetic target answers, the attack reports 84.6 % / 81.3 % HR@10 and 57.5 % / 54.8 % ASR-LLM on Natural Questions and MS MARCO, near-benign perplexity, cross-model transfer, 64.7 % average HR@10 against unseen retrievers, and 74.2 % HR@10 at 0.016 % poisoning on a Wikipedia-scale corpus. Defenses and human fluency evaluations are also reported.
Significance. If the attack remains effective when the single-poisoned-document and synthetic-target constraints are relaxed, the work would establish a concrete, low-perplexity poisoning vector against production RAG pipelines and motivate stronger corpus-integrity defenses. The reported transfer results and human-evaluation comparison to disfluent baselines are useful empirical contributions.
major comments (2)
- [Abstract] Abstract: the headline HR@10 and ASR-LLM figures are obtained exclusively under a one-poisoned-document-per-query regime with pre-chosen synthetic target answers. This protocol removes document competition at retrieval time and reduces generation scoring to exact-string matching; no ablation that relaxes either constraint while holding the rest of the pipeline fixed is described, so the central claim that SilentRetrieval “hijacks RAG systems” does not yet follow from the presented evidence.
- [Abstract] Abstract: the Wikipedia-scale result (74.2 % HR@10 at 0.016 % poisoning) is stated without clarifying whether the same single-poison-per-query and synthetic-target protocol was reused; if it was, the result does not address realism concerns about multi-document corpora or natural user queries.
minor comments (2)
- [Abstract] Abstract and results sections report point estimates without error bars, standard deviations, or the number of random seeds used.
- The optimization objectives for Coordinated Beam Search are described at a high level but the precise multi-token joint loss and beam-search hyperparameters are not supplied, preventing exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation protocol. We address each major comment below and will revise the manuscript to clarify the scope of our claims and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline HR@10 and ASR-LLM figures are obtained exclusively under a one-poisoned-document-per-query regime with pre-chosen synthetic target answers. This protocol removes document competition at retrieval time and reduces generation scoring to exact-string matching; no ablation that relaxes either constraint while holding the rest of the pipeline fixed is described, so the central claim that SilentRetrieval “hijacks RAG systems” does not yet follow from the presented evidence.
Authors: We agree that the headline metrics are reported under the one-poisoned-document-per-query protocol with synthetic targets, which isolates the attack's core mechanism by eliminating multi-document competition and using exact-match scoring for generation success. This controlled setup is standard in poisoning literature to establish baseline effectiveness before scaling to more complex regimes. We acknowledge that the broader claim of hijacking production RAG systems would be strengthened by ablations relaxing these constraints. We will add a dedicated limitations subsection and, where computationally feasible, preliminary multi-poison and natural-answer experiments in the revision. revision: yes
-
Referee: [Abstract] Abstract: the Wikipedia-scale result (74.2 % HR@10 at 0.016 % poisoning) is stated without clarifying whether the same single-poison-per-query and synthetic-target protocol was reused; if it was, the result does not address realism concerns about multi-document corpora or natural user queries.
Authors: We will explicitly state in the revised abstract and experimental section that the Wikipedia-scale evaluation reuses the same one-poison-per-query and synthetic-target protocol. This result is intended to demonstrate that the attack remains effective at very low poisoning ratios even on a large-scale corpus, but we agree it does not resolve concerns about multi-poison settings or natural queries. The revision will include this clarification and a forward-looking discussion of these open realism questions. revision: yes
Circularity Check
No circularity; purely empirical attack evaluation with no derivations or self-referential predictions
full rationale
The paper describes an empirical data-poisoning method and reports measured attack success rates on fixed benchmarks (Natural Questions, MS MARCO, Wikipedia-scale) under an explicitly stated one-poisoned-document-per-query protocol with synthetic targets. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All headline numbers are direct experimental outputs rather than quantities forced by construction from the method's own inputs. The evaluation protocol is a methodological choice whose realism can be debated, but it does not create circularity in any claimed derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InInternational Conference on Learning Representations. OpenReview.net, Vienna, Austria, 30 pages. https://openreview.net/forum?id=hSyW5go0v8
2024
-
[3]
Matan Ben-Tov and Mahmood Sharif. 2025. GASLITEing the Retrieval: Exploring Vulnerabilities in Dense Embedding-based Search. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, Taipei, Taiwan, 4364–4378. doi:10.1145/3719027.3765095
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Tailun Chen, Yu He, Yan Wang, Shuo Shao, Haolun Zheng, Zhihao Liu, Jinfeng Li, Zhizhen Qin, Yuefeng Chen, Zhixuan Chu, Zhan Qin, and Kui Ren. 2025. MIRAGE: Misleading Retrieval-Augmented Generation via Black-box and Query-agnostic Poisoning Attacks.arXiv preprint arXiv:2512.08289abs/2512.08289 (2025), 1–14. doi:10.48550/arXiv.2512.08289
-
[6]
Yen-Shan Chen, Sian-Yao Huang, Cheng-Lin Yang, and Yun-Nung Chen. 2025. Eyes-on-Me: Scalable RAG Poisoning through Transferable Attention-Steering Attractors.arXiv preprint arXiv:2510.00586abs/2510.00586 (2025), 1–13. doi:10. 48550/arXiv.2510.00586
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Pengzhou Cheng, Yidong Ding, Tianjie Ju, Zongru Wu, Wei Du, Ping Yi, Zhu- osheng Zhang, and Gongshen Liu. 2024. TrojanRAG: Retrieval-Augmented Generation Can Be Backdoor Driver in Large Language Models.arXiv preprint arXiv:2405.13401abs/2405.13401 (2024), 1–12. doi:10.48550/arXiv.2405.13401
-
[8]
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. 2018. HotFlip: White- box adversarial examples for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Association for Compu- tational Linguistics, Melbourne, Australia, 31–36. doi:10.18653/v1/P18-2006
-
[9]
Michael Glass, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, Ankita Naik, Pengshan Cai, and Alfio Gliozzo. 2022. Re2G: Retrieve, Rerank, Generate. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, Seattle, United States, 2701–2715. doi:10.18653/...
-
[10]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang
-
[11]
InInternational Conference on Machine Learning
REALM: Retrieval augmented language model pre-training. InInternational Conference on Machine Learning. PMLR, Virtual, 3929–3938. https://proceedings. mlr.press/v119/guu20a.html
-
[12]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense infor- mation retrieval with contrastive learning.Transactions on Machine Learning Research(2022), 21 pages. https://openreview.net/forum?id=jKN1pXi7b0
2022
-
[13]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave
-
[14]
https://jmlr.org/papers/v24/23- 0037.html
Atlas: Few-shot learning with retrieval augmented language models.Journal of Machine Learning Research24, 251 (2023), 1–43. https://jmlr.org/papers/v24/23- 0037.html
2023
-
[15]
Yang Jiao, Xiaodong Wang, and Kai Yang. 2025. PR-Attack: Coordinated Prompt- RAG Attacks on Retrieval-Augmented Generation in Large Language Models via Bilevel Optimization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Padua, Italy, 656–667. doi:10.1145/3726302.3730058
-
[16]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open- domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguis- tics, Online, 6769–6781. doi:10.18653/v1/2020.e...
-
[17]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics7 (2019), 453–466. doi:10.1162/tacl_a_00276
-
[18]
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, Vol. 31. Curran Associates, Inc., Montréal, Canada, 7167–7177
2018
-
[19]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al
-
[20]
In Advances in Neural Information Processing Systems, Vol
Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., Virtual, 9459–9474
-
[21]
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085abs/1901.04085 (2019), 1–4. doi:10.48550/arXiv. 1901.04085
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2019
-
[22]
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. 2021. KILT: a benchmark for knowledge intensive language tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics. Association ...
-
[23]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.Ope- nAI Technical Report(2019), 24 pages. https://cdn.openai.com/better-language- models/language_models_are_unsupervised_multitask_learners.pdf
2019
-
[24]
Yangguang Shao, Xinjie Lin, Haozheng Luo, Chengshang Hou, Gang Xiong, Jiahao Yu, and Junzheng Shi. 2025. POISONCRAFT: Practical Poisoning of Retrieval-Augmented Generation for Large Language Models.arXiv preprint arXiv:2505.06579abs/2505.06579 (2025), 1–11. doi:10.48550/arXiv.2505.06579
-
[25]
Congzheng Song, Alexander M Rush, and Vitaly Shmatikov. 2020. Adversarial semantic collisions. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online, 4198–4210. doi:10.18653/v1/2020.emnlp-main.344
-
[26]
Jinyan Su, Preslav Nakov, and Claire Cardie. 2025. Corpus Poisoning via Approx- imate Greedy Gradient Descent. InFindings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, Vienna, Austria, 4274–4294. doi:10.18653/v1/2025.findings-acl.222
-
[27]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288abs/2307.09288 (2023), 1–77. doi:10.48550/arXiv.2307. 09288
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307 2023
-
[28]
Haowei Wang, Rupeng Zhang, Junjie Wang, Mingyang Li, Yuekai Huang, Dandan Wang, and Qing Wang. 2026. Joint-GCG: Unified Gradient-Based Poisoning Attacks on Retrieval-Augmented Generation Systems. InProceedings of the AAAI Conference on Artificial Intelligence. Association for the Advancement of Artificial Intelligence, Singapore, 35793–35801. doi:10.1609/...
-
[29]
Meng Xi, Sihan Lv, Yechen Jin, Guanjie Cheng, Naibo Wang, Ying Li, and Jianwei Yin. 2025. RIPRAG: Hack a Black-box Retrieval-Augmented Generation Question- Answering System with Reinforcement Learning.arXiv preprint arXiv:2510.10008 abs/2510.10008 (2025), 1–10. doi:10.48550/arXiv.2510.10008
-
[30]
Chong Xiang, Tong Wu, Zexuan Zhong, David Wagner, Danqi Chen, and Prateek Mittal. 2024. Certifiably Robust RAG against Retrieval Corruption.arXiv preprint arXiv:2405.15556abs/2405.15556 (2024), 1–24. doi:10.48550/arXiv.2405.15556
-
[31]
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. 2024. Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts. InInternational Conference on Learning Representations. OpenReview.net, Vienna, Austria, 24 pages. https://openreview.net/forum?id= auKAUJZMO6
2024
-
[32]
Jiaqi Xue, Mengxin Zheng, Yebowen Hu, Fei Liu, Xun Chen, and Qian Lou. 2024. BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models.arXiv preprint arXiv:2406.00083abs/2406.00083 (2024), 1–13. doi:10.48550/arXiv.2406.00083
- [33]
-
[34]
Baolei Zhang, Haoran Xin, Jiatong Li, Dongzhe Zhang, Minghong Fang, Zhuqing Liu, Lihai Nie, and Zheli Liu. 2025. Benchmarking Poisoning Attacks against Retrieval-Augmented Generation.arXiv preprint arXiv:2505.18543abs/2505.18543 (2025), 1–14. doi:10.48550/arXiv.2505.18543
-
[35]
Collin Zhang, Tingwei Zhang, and Vitaly Shmatikov. 2026. Adversarial Decoding: Generating Readable Documents for Adversarial Objectives. InFindings of the As- sociation for Computational Linguistics: EACL 2026. Association for Computational Linguistics, Rabat, Morocco, 2053–2068. doi:10.18653/v1/2026.findings-eacl.108
-
[36]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P Xing, et al. 2023. Judg- ing LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., New Orleans, LA, 46595–46623
2023
-
[37]
Zexuan Zhong, Ziqing Huang, Alexander Wettig, and Danqi Chen. 2023. Poison- ing Retrieval Corpora by Injecting Adversarial Passages. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 13764–13775. doi:10.18653/v1/2023.emnlp- main.849
-
[38]
new page patrol
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. Poisone- dRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. In34th USENIX Security Symposium (USENIX Security 25). USENIX Association, Seattle, WA, 3827–3844. https://www.usenix.org/ conference/usenixsecurity25/presentation/zou-poisonedrag A Wikipedia-S...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.