AlgoSkill: Learning to Design Algorithms by Scheduling Human-Like Skills
Pith reviewed 2026-06-30 06:07 UTC · model grok-4.3
The pith
AlgoSkill models algorithm design as scheduling a typed library of skills like abstraction and constraint analysis, guided by verification feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
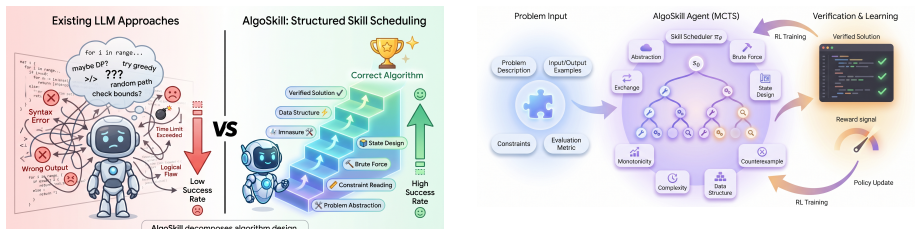
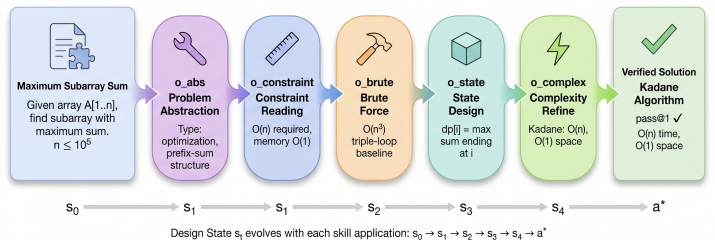
AlgoSkill models algorithm design as sequential decision-making over a typed library of algorithmic skills. A learned scheduler proposes skills from the current state while an MCTS controller explores sequences, using feedback from compilation, testing, stress testing, and complexity analysis to repair and refine.
What carries the argument
The typed library of algorithmic skills together with verification-guided MCTS scheduling over skill sequences.
If this is right
- Performance gains appear on both competitive programming and combinatorial optimization tasks.
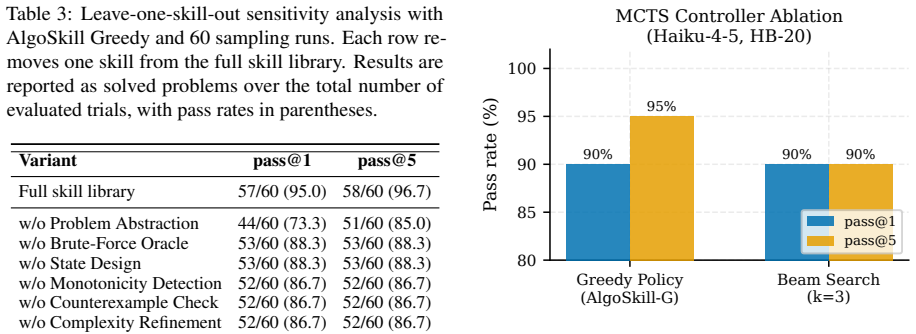
- Removing typed skills, verification-based repair, or search-based scheduling each reduces results.
- The approach replaces implicit one-shot generation with explicit, verifiable steps.
Where Pith is reading between the lines
- The same skill-scheduling pattern might transfer to other domains that require stepwise construction and verification, such as theorem proving or circuit design.
- Explicit skill libraries could make LLM outputs more auditable by exposing which reasoning step produced each code fragment.
- If the skill set proves incomplete for some problem classes, the method would need either new skills or a way to learn additional ones.
Load-bearing premise
The listed skills cover the essential steps needed to design algorithms from natural language and that test and complexity feedback is reliable enough to steer the search productively.
What would settle it
Running the same competitive-programming and combinatorial-optimization benchmarks with direct LLM generation or MCTS without the typed skills and finding no performance gap would falsify the central claim.
Figures
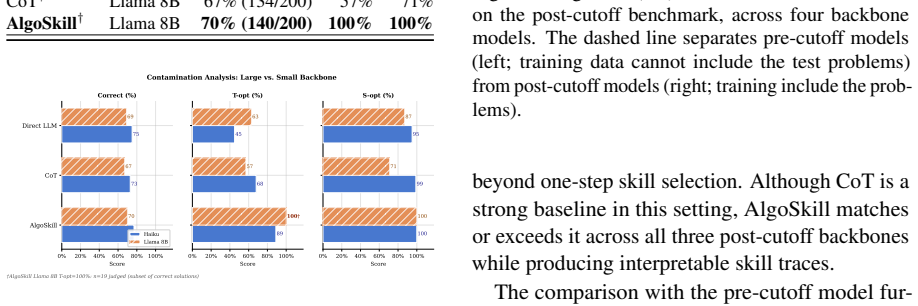
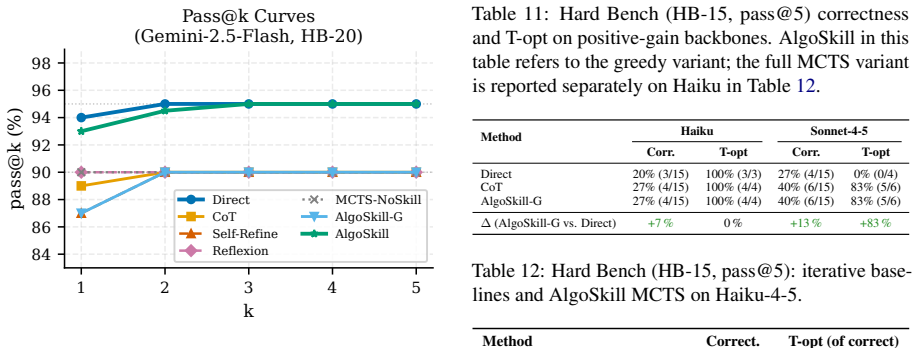

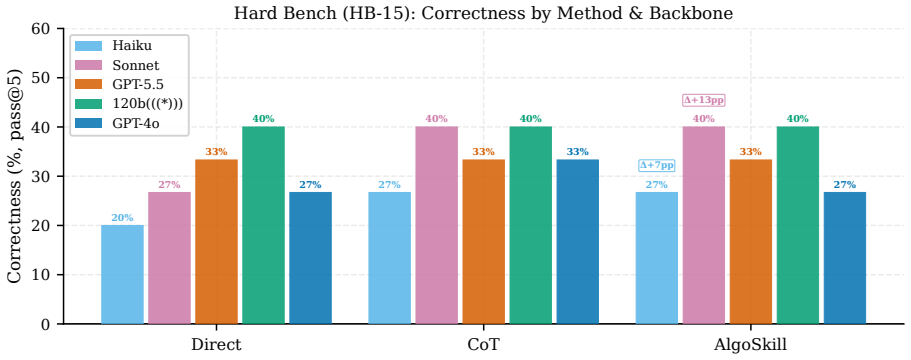
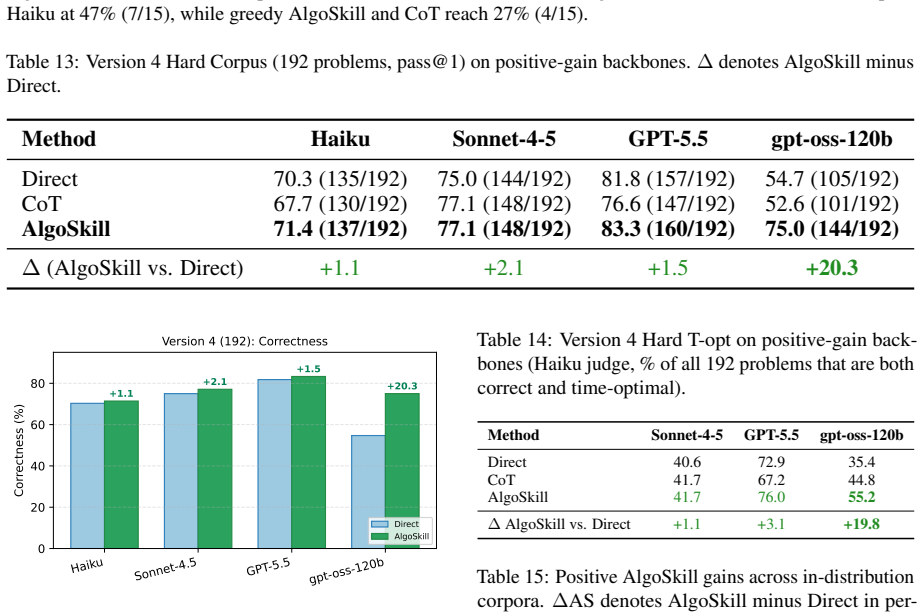
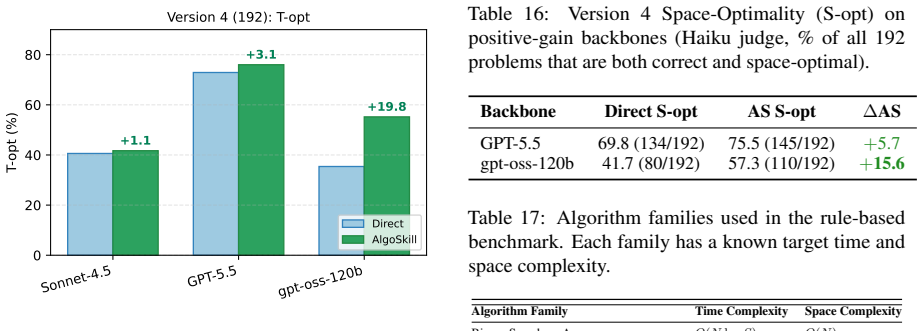
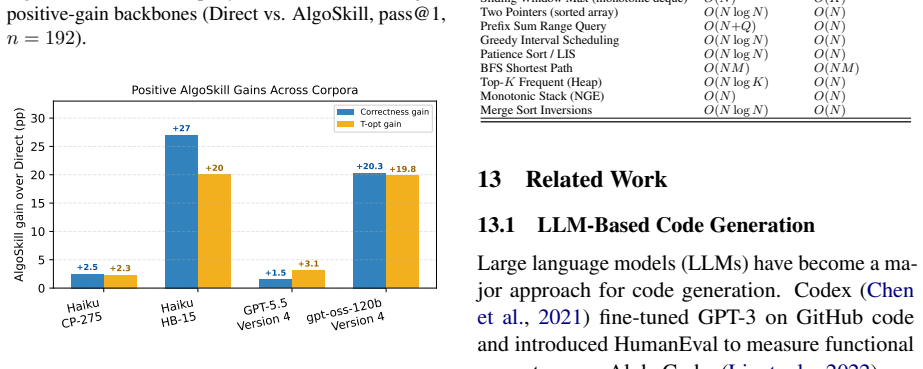
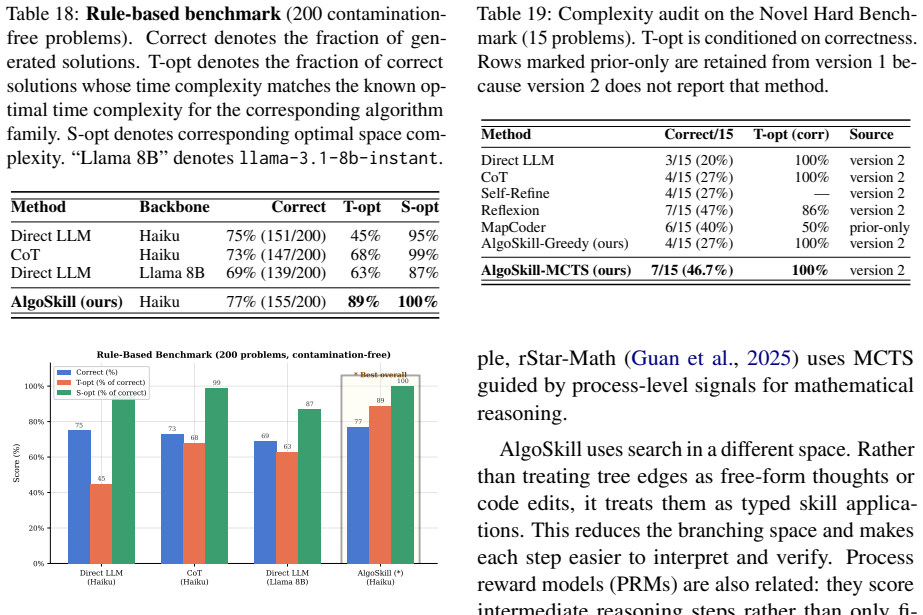
read the original abstract
Designing an algorithm from a natural-language problem statement requires identifying the problem structure, reading constraints, choosing a suitable paradigm, checking correctness, and refining complexity. Existing large language model (LLM) methods often rely on direct generation or generic self-refinement, leaving these steps implicit. We propose AlgoSkill, which models algorithm design as sequential decision-making over a typed library of algorithmic skills, including abstraction, constraint analysis, state design, data-structure selection, proof checking, counterexample construction, and complexity refinement. A learned scheduler proposes skills from the current design state, while a Monte Carlo Tree Search (MCTS) controller explores skill sequences using verification feedback from compilation, testing, stress testing, and complexity analysis. Experiments on competitive programming and combinatorial optimization benchmarks show that AlgoSkill improves over direct LLM generation, chain-of-thought prompting, self-refinement, and MCTS without typed skills. Ablations show that typed skills, verification-based repair, and search-based scheduling each contribute to performance. These results support treating automatic algorithm design as verification-guided skill scheduling rather than one-shot code generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AlgoSkill, which models algorithm design from natural-language statements as sequential decision-making over a typed library of skills (abstraction, constraint analysis, state design, data-structure selection, proof checking, counterexample construction, complexity refinement). A learned scheduler proposes skills and MCTS explores sequences using verification feedback from compilation, testing, stress testing, and complexity analysis. Experiments on competitive programming and combinatorial optimization benchmarks are claimed to show improvements over direct LLM generation, chain-of-thought prompting, self-refinement, and MCTS without typed skills; ablations indicate that typed skills, verification-based repair, and search-based scheduling each contribute.
Significance. If the empirical claims are substantiated with full quantitative results and robust test coverage, the work would offer a structured alternative to one-shot LLM code generation by making algorithmic reasoning steps explicit and verifiable. The combination of typed skills with MCTS and verification feedback, together with the reported ablations, provides a reproducible experimental framework that could be extended to other synthesis tasks.
major comments (2)
- [Abstract] Abstract: the central empirical claim (improvements over four baselines plus positive ablations) is stated without any quantitative results, benchmark identifiers, metrics, sample sizes, or error bars. This information is load-bearing for assessing whether the data support the claim.
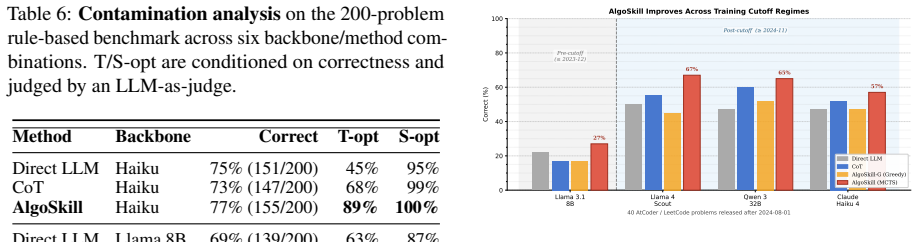
- [Experiments] Experiments section (and associated evaluation): the claim that verification feedback from compilation, testing, stress testing, and complexity analysis reliably steers MCTS rests on the assumption that benchmark test suites are sufficiently complete. No analysis or additional stress-test results are provided to show that the suites detect edge cases or asymptotic failures, which directly affects whether the reported gains reflect genuine algorithmic improvement rather than overfitting to the given tests.
minor comments (1)
- [Methods] The typed skill library is introduced in the abstract and methods; a table listing each skill with its input/output types and an example invocation would improve clarity and allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of clarity and evaluation robustness. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (improvements over four baselines plus positive ablations) is stated without any quantitative results, benchmark identifiers, metrics, sample sizes, or error bars. This information is load-bearing for assessing whether the data support the claim.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. In the revised version, we will incorporate specific metrics (e.g., success rates on Codeforces and combinatorial optimization benchmarks), benchmark identifiers, sample sizes, and error bars from the experiments comparing AlgoSkill to direct generation, chain-of-thought, self-refinement, and MCTS without typed skills. revision: yes
-
Referee: [Experiments] Experiments section (and associated evaluation): the claim that verification feedback from compilation, testing, stress testing, and complexity analysis reliably steers MCTS rests on the assumption that benchmark test suites are sufficiently complete. No analysis or additional stress-test results are provided to show that the suites detect edge cases or asymptotic failures, which directly affects whether the reported gains reflect genuine algorithmic improvement rather than overfitting to the given tests.
Authors: The referee raises a valid point about evaluation robustness. The manuscript does not include an explicit analysis of test suite completeness or additional stress-test results for edge cases and asymptotic failures. We will add a limitations paragraph in the experiments section discussing reliance on standard benchmark test suites and the potential for overfitting. However, we cannot provide new stress-test results without conducting additional experiments. revision: partial
- Additional stress-test results demonstrating benchmark test suite completeness for edge cases and asymptotic failures
Circularity Check
No circularity; empirical method with external benchmarks
full rationale
The paper describes AlgoSkill as a method using a typed skill library, learned scheduler, and MCTS guided by verification feedback, evaluated empirically on competitive programming and combinatorial optimization benchmarks against baselines like direct LLM generation and CoT. Ablations are reported to isolate contributions of typed skills, verification repair, and search scheduling. No equations, derivations, or predictions appear that reduce by construction to fitted parameters or self-citations; the central claims rest on external experimental comparisons rather than self-definitional or load-bearing internal reductions. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned scheduler parameters
axioms (1)
- domain assumption Algorithm design from natural language can be decomposed into sequential decisions over a fixed typed library of skills
invented entities (1)
-
Typed library of algorithmic skills
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Large language models are zero-shot reasoners , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[3]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
MapCoder: Multi-Agent Code Generation for Competitive Problem Solving , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
-
[4]
Nature , volume =
Mathematical discoveries from program search with large language models , author =. Nature , volume =
-
[5]
Advances in Neural Information Processing Systems , year =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[6]
Advances in Neural Information Processing Systems , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , year =
-
[7]
International Conference on Learning Representations (ICLR) , year=
Self-consistency improves chain of thought reasoning in language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[9]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Measuring coding challenge competence with
Hendrycks, Dan and Basart, Steven and Kadavath, Saurav and Mazeika, Mantas and Arora, Akul and Guo, Ethan and Burns, Collin and Puranik, Samir and He, Horace and Song, Dawn and others , booktitle=. Measuring coding challenge competence with
-
[12]
Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming , booktitle=
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[14]
AAAI38(2024), https://arxiv.org/abs/2308.09687
Graph of thoughts: Solving elaborate problems with large language models , author=. arXiv preprint arXiv:2308.09687 , year=
-
[15]
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , booktitle=
-
[16]
Guan, Xinyu and Zhang, Li Lyna and Liu, Yifei and Shang, Ning and Sun, Youran and Zhu, Yi and Yang, Fan and Yang, Mao , journal=
-
[17]
Competition-level code generation with
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, R. Competition-level code generation with. Science , volume=
-
[18]
arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Guo, Daya and Zhu, Qihao and Yang, Dejian and Xie, Zhenda and Dong, Kai and Zhang, Wentao and Chen, Guanting and Bi, Xiao and Wu, Yu and Li, Yuxuan and others , journal=
-
[20]
2024 , eprint=
A Survey of Large Language Models for Code: Evolution, Benchmarking, and Future Trends , author=. 2024 , eprint=
2024
-
[21]
Roziere, Baptiste and Gehring, Jonas and Gloeckle, Fabian and Sootla, Sten and Gat, Itai and Tan, Xiaoqing Ellen and Adi, Yossi and Liu, Jingyu and Remez, Tal and Rapin, J. Code. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, Alexander and V. arXiv preprint arXiv:2506.13131 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Nature , volume=
Discovering faster matrix multiplication algorithms with reinforcement learning , author=. Nature , volume=
-
[24]
Zelikman, Eric and Harik, Georges and Shao, Yijia and Jayasiri, Varuna and Haber, Nick and Goodman, Noah D , journal=. Quiet-
-
[25]
Le, Hung and Wang, Yue and Gotmare, Akhilesh Deepak and Savarese, Silvio and Hoi, Steven CH , booktitle=
-
[26]
arXiv preprint arXiv:2301.13816 , year=
Execution-based code generation using deep reinforcement learning , author=. arXiv preprint arXiv:2301.13816 , year=
-
[27]
2023 , eprint=
Improving Language Models via Plug-and-Play Retrieval Feedback , author=. 2023 , eprint=
2023
-
[28]
Mastering the game of
Silver, David and Huang, Aja and Maddison, Chris J and Guez, Arthur and Sifre, Laurent and Van Den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and others , journal=. Mastering the game of
-
[29]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Mastering chess and shogi by self-play with a general reinforcement learning algorithm , author=. arXiv preprint arXiv:1712.01815 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Machine Learning , volume=
Finite-time analysis of the multiarmed bandit problem , author=. Machine Learning , volume=
-
[31]
Ni, Ansong and Iyer, Srini and Radev, Dragomir and Stoyanov, Ves and Yih, Wen-tau and Wang, Sida and Lin, Xi Victoria , booktitle=
-
[32]
Competition-Level Code Generation with
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, R. Competition-Level Code Generation with. Science , volume =
-
[33]
International Conference on Learning Representations (ICLR) , year=
Let's verify step by step , author=. International Conference on Learning Representations (ICLR) , year=
-
[34]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process- and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[36]
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , journal=
-
[37]
ACM SIGPLAN Notices (POPL) , year=
Automating string processing in spreadsheets using input-output examples , author=. ACM SIGPLAN Notices (POPL) , year=
-
[38]
Formal Methods in Computer-Aided Design (FMCAD) , year=
Syntax-guided synthesis , author=. Formal Methods in Computer-Aided Design (FMCAD) , year=
-
[39]
ACM SIGOPS Operating Systems Review (ASPLOS) , year=
Combinatorial sketching for finite programs , author=. ACM SIGOPS Operating Systems Review (ASPLOS) , year=
-
[40]
International Conference on Learning Representations (ICLR) , year=
Neuro-symbolic program synthesis , author=. International Conference on Learning Representations (ICLR) , year=
-
[41]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal=
-
[42]
Advances in Computers , volume=
The algorithm selection problem , author=. Advances in Computers , volume=
-
[43]
He, Xin and Zhao, Kaiyong and Chu, Xiaowen , journal=
-
[44]
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Graves, Alex and Antonoglou, Ioannis and Wierstra, Daan and Riedmiller, Martin , journal=. Playing
-
[45]
Journal of the Operational Research Society , volume=
Hyper-heuristics: A survey of the state of the art , author=. Journal of the Operational Research Society , volume=
-
[46]
Sutton, Richard S and Precup, Doina and Singh, Satinder , journal=. Between
-
[47]
2023 , eprint=
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models , author=. 2023 , eprint=
2023
-
[48]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , booktitle=
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Toolformer: Language models can teach themselves to use tools , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[51]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show your work: Scratchpads for intermediate computation with language models , author=. arXiv preprint arXiv:2112.00114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
A Survey on Large Language Models for Code Generation
A survey on large language models for code generation , author=. arXiv preprint arXiv:2406.00515 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Machine Learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine Learning , volume=
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[56]
2026 , howpublished =
Codeforces , author =. 2026 , howpublished =
2026
-
[57]
2026 , howpublished =
AtCoder , author =. 2026 , howpublished =
2026
-
[58]
2026 , howpublished =
Kattis Problem Archive , author =. 2026 , howpublished =
2026
-
[59]
2026 , howpublished =
LeetCode , author =. 2026 , howpublished =
2026
-
[60]
2024 , month = mar, howpublished =
Claude 3 Haiku: Our Fastest Model Yet , author =. 2024 , month = mar, howpublished =
2024
-
[61]
2025 , howpublished =
Gemini 2.5 Flash , author =. 2025 , howpublished =
2025
-
[62]
2026 , howpublished =
2026
-
[63]
2024 , howpublished =
Hello. 2024 , howpublished =
2024
-
[64]
2025 , howpublished =
Introducing. 2025 , howpublished =
2025
-
[65]
2024 , howpublished =
Introducing. 2024 , howpublished =
2024
-
[66]
2025 , howpublished =
The. 2025 , howpublished =
2025
-
[67]
2025 , howpublished =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.