All Smoke, No Alarm: Oracle Signals in Agent-Authored Test Code
Pith reviewed 2026-06-26 23:34 UTC · model grok-4.3
The pith
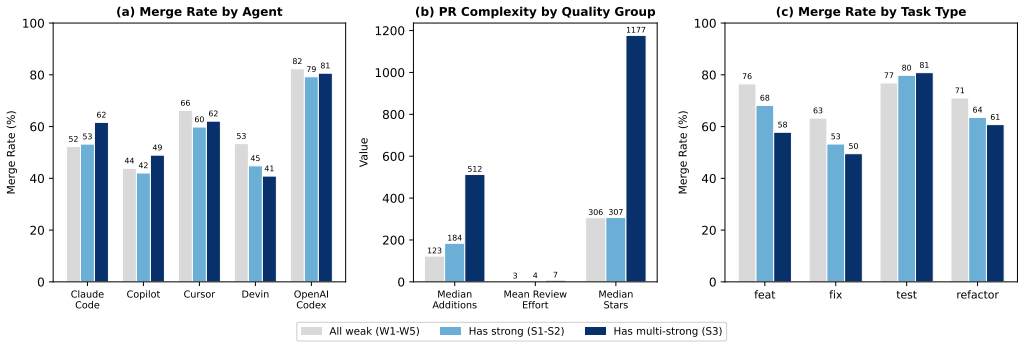
Most agent-written test patches in pull requests lack strong verification logic, though patches with explicit oracles are 28 percent more likely to merge after adjustments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
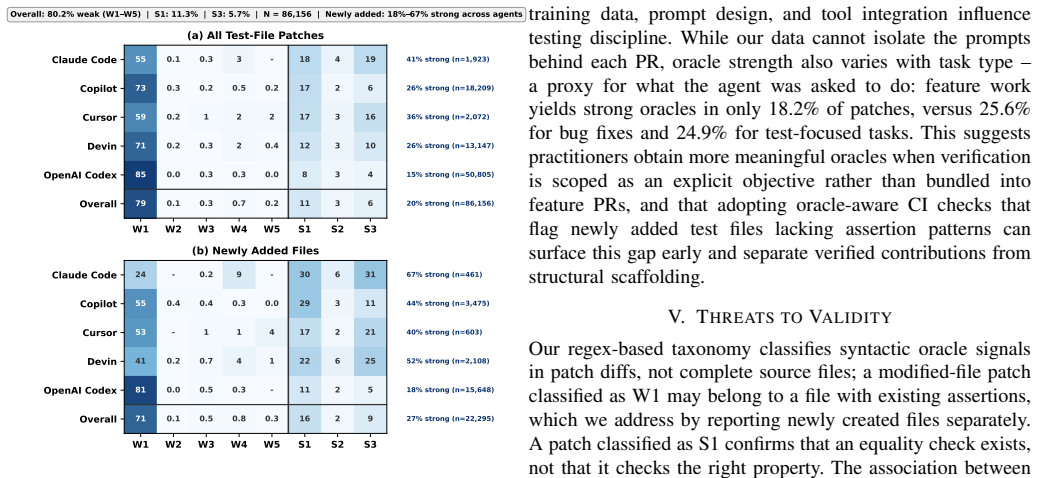
In an empirical study of 86,156 test-file patches from 33,596 agent-authored PRs, a syntactic taxonomy of eight oracle-signal categories shows that 80.2 percent of patches contain weak or no explicit oracle signals. After adjustment for confounders, the presence of strong oracle signals is associated with higher merge likelihood (odds ratio 1.28, p < 0.001).
What carries the argument
A syntactic taxonomy of eight oracle signal categories derived from qualitative coding of 384 patches, applied at scale to classify verification strength and linked to merge outcomes via multivariable regression.
If this is right
- Test-file counts alone substantially overestimate verification strength in agent-authored contributions.
- Practitioners can replace simple test-presence gates with oracle-aware quality checks that inspect assertion content.
- Agent performance evaluations that rely only on test-file volume will understate the value of patches that include explicit verification logic.
- Review effort may decrease for PRs whose tests contain strong oracles because reviewers can more readily confirm intended behavior.
Where Pith is reading between the lines
- Training data for future coding agents could be filtered or weighted toward examples that contain strong oracle signals to improve downstream merge rates.
- Repository maintainers might add automated linters that flag test patches lacking explicit assertions before human review begins.
- The observed merge benefit could be tested in controlled experiments where identical production changes are paired with weak versus strong test oracles.
Load-bearing premise
The eight-category syntactic taxonomy derived from 384 patches correctly captures the strength of verification logic, and the regression isolates oracle strength from other factors that affect merges.
What would settle it
Re-running the merge regression on a fresh sample of agent PRs in which oracle-signal labels are assigned by independent reviewers and the same set of control variables is used; a non-significant odds ratio would falsify the reported link.
Figures
read the original abstract
Software practitioners increasingly use AI coding agents that generate test code alongside production code in open source pull requests (PRs). Recent studies report more than 932,000 agent-authored PRs across more than 116,000 repositories, yet whether their test files contain meaningful verification logic remains underexplored. Test files lacking explicit assertions execute code without verifying behavior, so quality gates based on test-file presence overestimate verification strength. The goal of this paper is to help practitioners assess the verification strength of agent-authored patches by characterizing oracle signals and their link to merge outcomes and review effort. We conduct an empirical study of 86,156 test-file patches from 33,596 agent-authored PRs across 2,807 GitHub repositories produced by five coding agents: OpenAI Codex, GitHub Copilot, Devin, Cursor, and Claude Code. A qualitative analysis of 384 stratified patches informs a syntactic taxonomy of eight oracle signal categories. Applied at scale, 80.2% of test patches contain weak or no explicit oracle signals. While raw merge rates are lower for strong-oracle PRs, a regression analysis adjusting for agent, PR size, repository popularity, task type, and language shows strong oracles significantly improve merge likelihood (OR = 1.28, p < 0.001). Our findings suggest that test file counts substantially overestimate verification strength and that practitioners can adopt oracle-aware quality checks to more accurately evaluate agent-authored contributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical study of 86,156 test-file patches from 33,596 agent-authored PRs across 2,807 repositories generated by five AI coding agents. A qualitative analysis of 384 stratified patches yields a syntactic taxonomy of eight oracle signal categories that is then applied automatically at scale, revealing that 80.2% of patches contain weak or no explicit oracle signals. A regression adjusting for agent, PR size, repository popularity, task type, and language finds that strong-oracle patches have higher merge likelihood (OR = 1.28, p < 0.001). The authors conclude that test-file presence substantially overestimates verification strength.
Significance. If the central measurements hold, the work is significant for software engineering practice because it demonstrates that simply counting test files in AI-generated patches is a poor proxy for verification quality and that oracle strength correlates with merge outcomes after confounder adjustment. The scale of the study (tens of thousands of patches across multiple agents and repositories) and the use of regression to isolate effects are clear strengths that would make the result useful for practitioners designing quality gates for agent contributions.
major comments (4)
- [§3] §3 (Methodology, qualitative analysis subsection): The derivation of the eight-category syntactic taxonomy from the 384 patches does not report inter-rater reliability statistics or resolution procedures for coder disagreements. Because this taxonomy supplies the binary strong/weak label that is applied to all 86,156 patches and serves as the key independent variable in the regression, the absence of reliability metrics directly threatens both the 80.2% prevalence figure and the OR estimate.
- [§4.1] §4.1 (Prevalence results): The claim that 80.2% of patches contain weak or no explicit oracle signals rests on the assumption that the syntactic patterns validly proxy verification strength. Syntactic detection alone cannot distinguish a meaningful assertion (e.g., assertEquals on exercised state) from a trivial or unreachable one (assertTrue(true) or assertions on unrelated variables), creating a systematic misclassification risk that undermines the central prevalence and merge-likelihood results.
- [§3.1] §3.1 (Data collection and sampling): The manuscript provides insufficient detail on the exact sampling frame for the 86,156 patches, the stratification procedure for the 384-patch qualitative sample, and any exclusion rules applied before analysis. These omissions prevent assessment of selection bias and reproducibility of the 80.2% and OR figures.
- [§4.3] §4.3 (Regression model): While the model adjusts for the listed covariates, the paper does not report variance inflation factors, the exact coding of the strong-oracle indicator, or sensitivity analyses that would show whether the OR = 1.28 remains stable under alternative taxonomy thresholds or additional controls such as code complexity.
minor comments (2)
- [Abstract] Abstract: The sentence stating that 'test file counts substantially overestimate verification strength' should be qualified to reflect the observational nature of the data rather than implying a direct causal overestimation.
- [§3.2] Taxonomy presentation: A table or figure listing the eight oracle signal categories with one concrete code example per category would improve clarity and allow readers to evaluate the syntactic rules directly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify important areas for strengthening the methodology and reporting. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Methodology, qualitative analysis subsection): The derivation of the eight-category syntactic taxonomy from the 384 patches does not report inter-rater reliability statistics or resolution procedures for coder disagreements. Because this taxonomy supplies the binary strong/weak label that is applied to all 86,156 patches and serves as the key independent variable in the regression, the absence of reliability metrics directly threatens both the 80.2% prevalence figure and the OR estimate.
Authors: We agree that explicit inter-rater reliability metrics strengthen claims about the taxonomy. Two authors independently coded all 384 patches; disagreements were resolved via discussion until consensus. We will add Cohen's kappa (and percentage agreement) for the strong/weak binary decision, along with the resolution protocol, to the revised Section 3. revision: yes
-
Referee: [§4.1] §4.1 (Prevalence results): The claim that 80.2% of patches contain weak or no explicit oracle signals rests on the assumption that the syntactic patterns validly proxy verification strength. Syntactic detection alone cannot distinguish a meaningful assertion (e.g., assertEquals on exercised state) from a trivial or unreachable one (assertTrue(true) or assertions on unrelated variables), creating a systematic misclassification risk that undermines the central prevalence and merge-likelihood results.
Authors: We acknowledge that purely syntactic detection is an imperfect proxy and cannot rule out trivial or unreachable assertions. This is an inherent scalability trade-off for analyzing 86k patches; semantic or dynamic validation was outside scope. The taxonomy was grounded in observed patch patterns, and the regression association with merge outcomes provides external validation. We will add an explicit limitations paragraph in Section 5 discussing this misclassification risk and its direction. revision: partial
-
Referee: [§3.1] §3.1 (Data collection and sampling): The manuscript provides insufficient detail on the exact sampling frame for the 86,156 patches, the stratification procedure for the 384-patch qualitative sample, and any exclusion rules applied before analysis. These omissions prevent assessment of selection bias and reproducibility of the 80.2% and OR figures.
Authors: We will expand Section 3.1 with the precise sampling frame (GitHub search criteria for agent PRs, test-file patch identification rules), stratification variables for the 384 patches (agent, language, repository stars), and exclusion criteria (e.g., non-test patches, malformed diffs). These additions will support reproducibility. revision: yes
-
Referee: [§4.3] §4.3 (Regression model): While the model adjusts for the listed covariates, the paper does not report variance inflation factors, the exact coding of the strong-oracle indicator, or sensitivity analyses that would show whether the OR = 1.28 remains stable under alternative taxonomy thresholds or additional controls such as code complexity.
Authors: We will add variance inflation factors, explicitly state that the strong-oracle variable is binary (any of the four strong categories vs. weak/none), and include sensitivity checks varying the taxonomy threshold and adding a code-complexity covariate. These will appear in the revised Section 4.3 and appendix. revision: yes
Circularity Check
No circularity: empirical study with independent taxonomy derivation
full rationale
This is a standard observational empirical study. The 80.2% prevalence and OR=1.28 are computed directly from applying a qualitatively-derived syntactic taxonomy (from 384 patches) to the full 86k-patch corpus followed by logistic regression. No equation, fitted parameter, or self-citation reduces either statistic to its own inputs by construction. The taxonomy is an output of manual qualitative coding, not defined in terms of the merge outcome or the scale results. No load-bearing uniqueness theorem or ansatz is imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Li, H. Zhang, and A. E. Hassan, “The rise of AI teammates in software engineering (SE) 3.0: How autonomous coding agents are reshaping software engineering,”arXiv preprint arXiv:2507.15003, 2025
Pith/arXiv arXiv 2025
-
[2]
From idea to PR: A guide to GitHub Copilot’s agentic workflows,
C. Reddington, “From idea to PR: A guide to GitHub Copilot’s agentic workflows,” https://github.blog/ai-and-ml/github-copilot/from-idea-t o-pr-a-guide-to-github-copilots-agentic-workflows/, 2025, accessed: 2026-03-30
2025
-
[3]
On the use of agentic coding: An empirical study of pull requests on GitHub,
M. Watanabe, H. Li, Y . Kashiwa, B. Reid, H. Iida, and A. E. Hassan, “On the use of agentic coding: An empirical study of pull requests on GitHub,”arXiv preprint arXiv:2509.14745, 2025
arXiv 2025
-
[4]
Gartner says 75 percent of enterprise software engineers will use AI code assistants by 2028,
Gartner, “Gartner says 75 percent of enterprise software engineers will use AI code assistants by 2028,” https://www.gartner.com/en/newsroom/ press-releases/2024-04-11-gartner-says-75-percent-of-enterprise-softw are-engineers-will-use-ai-code-assistants-by-2028, 2024, press release, April 11, 2024
2028
-
[5]
The oracle problem in software testing: A survey,
E. T. Barr, M. Harman, P. McMinn, M. Shahbaz, and S. Yoo, “The oracle problem in software testing: A survey,”IEEE Transactions on Software Engineering, vol. 41, no. 5, pp. 507–525, 2015
2015
-
[6]
The rise of test theater,
B. Houston, “The rise of test theater,” https://ben3d.ca/blog/the-rise-o f-test-theater, 2025, accessed: 2026-03-29
2025
-
[7]
I let an AI agent write 275 tests. here’s what it was actually optimizing for,
H. Flores, “I let an AI agent write 275 tests. here’s what it was actually optimizing for,” https://dev.to/htekdev/i-let-an-ai-agent-write-275-tes ts-heres-what-it-was-actually-optimizing-for-32n7, 2026, accessed: 2026-03-29
2026
-
[8]
Why testing after with AI is even worse,
M. Bar-Zeev, “Why testing after with AI is even worse,” https://dev.to/m barzeev/why-testing-after-with-ai-is-even-worse-4jc1, 2026, accessed: 2026-03-29
2026
-
[9]
Do LLMs generate test oracles that capture the actual or the expected program behaviour?
M. Konstantinou, R. Degiovanni, and M. Papadakis, “Do LLMs generate test oracles that capture the actual or the expected program behaviour?” arXiv preprint arXiv:2410.21136, 2024
arXiv 2024
-
[10]
AsserT5: Test assertion generation us- ing a fine-tuned code language model,
S. Primbs, B. Fein, and G. Fraser, “AsserT5: Test assertion generation us- ing a fine-tuned code language model,” inProceedings of the IEEE/ACM International Conference on Automation of Software Test (AST 2025), 2025, arXiv:2502.02708
arXiv 2025
-
[11]
Effective test generation using pre-trained large language models and mutation testing,
A. Moradi Dakhel, A. Nikanjam, V . Majdinasab, F. Khomh, and M. C. Desmarais, “Effective test generation using pre-trained large language models and mutation testing,”Information and Software Technology, vol. 171, 2024
2024
-
[12]
Coverage is not strongly correlated with test suite effectiveness,
L. Inozemtseva and R. Holmes, “Coverage is not strongly correlated with test suite effectiveness,” inProceedings of the 36th International Conference on Software Engineering (ICSE 2014), 2014, pp. 435–445
2014
-
[13]
Measuring and mitigating gaps in structural testing,
S. B. Hossain, M. B. Dwyer, S. Elbaum, and A. Nguyen-Tuong, “Measuring and mitigating gaps in structural testing,” inProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE 2023), 2023
2023
-
[14]
AIDev: Studying AI coding agents on GitHub,
H. Li, H. Zhang, and A. E. Hassan, “AIDev: Studying AI coding agents on GitHub,” inProceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026), 2026, arXiv:2602.09185
arXiv 2026
-
[15]
Replication package for “all smoke, no alarm: Oracle signals in agent-authored test code
D. Banik, K. Chowdhury, and S. I. Shamim, “Replication package for “all smoke, no alarm: Oracle signals in agent-authored test code”,” https: //doi.org/10.6084/m9.figshare.32032107, 2026
-
[16]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”Biometrics, vol. 33, no. 1, pp. 159–174, 1977
1977
-
[17]
Mind the gap: The difference between coverage and mutation score can guide testing efforts,
K. Jain, G. T. Kalburgi, C. Le Goues, and A. Groce, “Mind the gap: The difference between coverage and mutation score can guide testing efforts,” inProceedings of the 34th IEEE International Symposium on Software Reliability Engineering (ISSRE 2023), 2023, pp. 102–113
2023
-
[18]
An empirical study of tests in agentic pull requests,
S. Haque, S. Ingale, and C. Csallner, “An empirical study of tests in agentic pull requests,” inProceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026), 2026, arXiv:2601.03556
arXiv 2026
-
[19]
Human-agent versus human pull requests: A testing- focused characterization and comparison,
R. Milanese, F. Salzano, A. Spina, A. Vitale, R. Pareschi, F. Fasano, and M. Fazzini, “Human-agent versus human pull requests: A testing- focused characterization and comparison,” inProceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026), 2026, arXiv:2601.21194
arXiv 2026
-
[20]
K. Chowdhury, D. Banik, K. M. Ferdous, and S. I. Shamim, “From industry claims to empirical reality: An empirical study of code re- view agents in pull requests,” inProceedings of the 23rd Interna- tional Conference on Mining Software Repositories (MSR 2026), 2026, arXiv:2604.03196
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.