Causal-Adapter: Taming Text-to-Image Diffusion for Faithful Counterfactual Generation
Pith reviewed 2026-05-18 12:46 UTC · model grok-4.3
The pith
Causal-Adapter adapts frozen text-to-image diffusion models for faithful counterfactual generation by enforcing causal attribute relationships.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
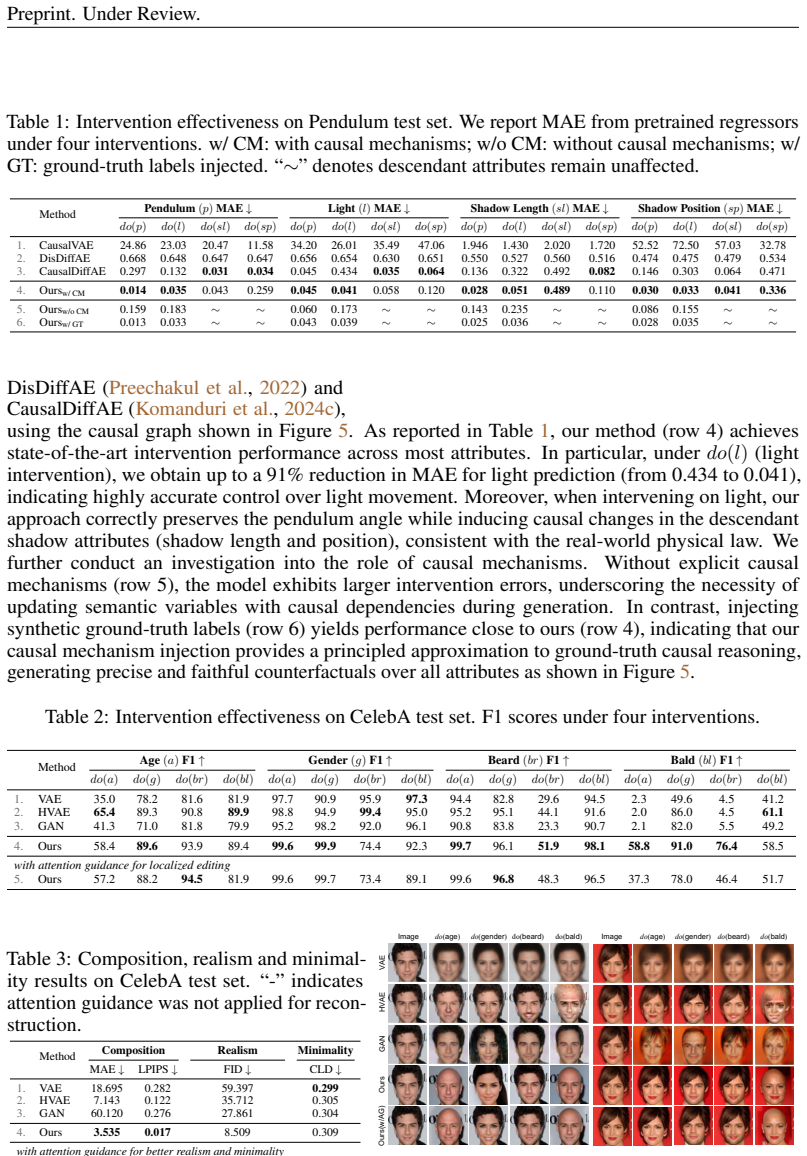
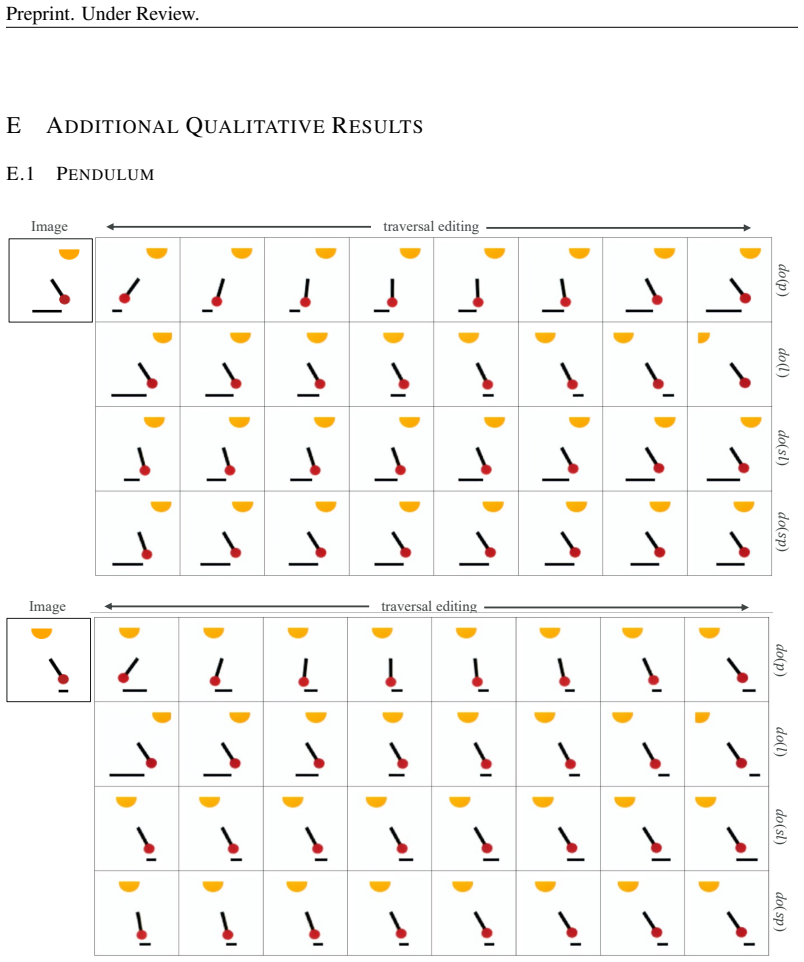
Causal-Adapter leverages structural causal modeling with prompt-aligned injection, which aligns causal attributes with textual embeddings for precise semantic control, and a conditioned token contrastive loss that disentangles attribute factors and reduces spurious correlations. Applied to a frozen diffusion backbone, this enables causal interventions on target attributes that propagate effects to dependents while preserving core image identity, yielding state-of-the-art performance including substantial reductions in error metrics on benchmark datasets.
What carries the argument
Prompt-aligned injection and conditioned token contrastive loss applied to a frozen text-to-image diffusion backbone, which together enforce causal structure during image generation.
Load-bearing premise
Causal relationships among image attributes can be sufficiently captured and enforced using only prompt-aligned injection and a conditioned token contrastive loss on a frozen diffusion backbone, without needing an explicit causal graph or additional supervised causal annotations.
What would settle it
A clear test would be whether intervening on one attribute in generated images reliably updates its causal dependent attributes as expected while keeping the subject's identity unchanged; failure on either would falsify the central claim.
Figures
























read the original abstract
We present Causal-Adapter, a modular framework that adapts frozen text-to-image diffusion backbones for counterfactual image generation. Our method supports causal interventions on target attributes and consistently propagates their effects to causal dependents while preserving the core identity of the image. Unlike prior approaches that rely on prompt engineering without explicit causal structure, Causal-Adapter leverages structural causal modeling with two attribute-regularization strategies: (i) prompt-aligned injection, which aligns causal attributes with textual embeddings for precise semantic control, and (ii) a conditioned token contrastive loss that disentangles attribute factors and reduces spurious correlations. Causal-Adapter achieves state-of-the-art performance on both synthetic and real-world datasets, including up to a 91% reduction in MAE on Pendulum for accurate attribute control and up to an 87% reduction in FID on ADNI for high-fidelity MRI generation. These results demonstrate robust, generalizable counterfactual editing with faithful attribute modification and strong identity preservation. Code and models will be released at: https://leitong02.github.io/causaladapter/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Causal-Adapter, a modular adapter for frozen text-to-image diffusion backbones that enables counterfactual image generation via causal interventions on target attributes. It uses prompt-aligned injection to align attributes with textual embeddings and a conditioned token contrastive loss to disentangle factors and reduce spurious correlations, claiming to propagate effects to causal dependents while preserving image identity. The work reports state-of-the-art results including up to 91% MAE reduction on the synthetic Pendulum dataset and 87% FID reduction on the real-world ADNI MRI dataset.
Significance. If the causal claims hold, the modular design on frozen backbones represents a practical advance for counterfactual generation in diffusion models, avoiding full retraining while incorporating causal concepts. The quantitative gains on both synthetic and real data, combined with the promise of code release, would support reproducibility and broader adoption in vision applications requiring faithful attribute control.
major comments (2)
- [Introduction and Methods] Introduction and Methods: The manuscript repeatedly invokes structural causal modeling (SCM) terminology such as 'causal interventions,' 'causal dependents,' and 'faithful counterfactual generation,' yet provides no explicit causal graph, no formalization of the do-operator, and no supervised causal annotations. This is load-bearing for the central claim that the two regularization strategies implement directed causal propagation rather than generic attribute disentanglement or correlation reduction.
- [Experiments (§4)] Experiments (§4): The reported 91% MAE reduction on Pendulum and 87% FID reduction on ADNI are presented as evidence of causal fidelity, but without ablations that isolate the contribution of the causal components (e.g., removing the contrastive loss or prompt alignment while retaining standard conditioning) or statistical significance tests against strong non-causal baselines, it remains unclear whether gains stem from causal enforcement or improved prompt binding.
minor comments (2)
- [Abstract] The abstract states that code and models will be released at the provided URL; the manuscript should clarify the exact release timeline and include a permanent archival link.
- [Methods] Notation for the conditioned token contrastive loss would benefit from an explicit equation in the main text rather than relying solely on prose description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript's presentation of its causal modeling aspects and experimental validation.
read point-by-point responses
-
Referee: [Introduction and Methods] Introduction and Methods: The manuscript repeatedly invokes structural causal modeling (SCM) terminology such as 'causal interventions,' 'causal dependents,' and 'faithful counterfactual generation,' yet provides no explicit causal graph, no formalization of the do-operator, and no supervised causal annotations. This is load-bearing for the central claim that the two regularization strategies implement directed causal propagation rather than generic attribute disentanglement or correlation reduction.
Authors: We acknowledge that an explicit causal graph and formalization using the do-operator would better ground the SCM terminology and clarify how the regularization strategies enforce directed propagation. In the revised manuscript we will add a new subsection in Methods that (i) presents a causal graph for the attribute dependencies in both the Pendulum and ADNI datasets, (ii) formalizes the target-attribute intervention via the do-operator, and (iii) explains how prompt-aligned injection and the conditioned token contrastive loss together implement the required causal propagation without needing supervised causal annotations. This addition will distinguish the approach from generic disentanglement while preserving the modular, annotation-free nature of the method. revision: yes
-
Referee: [Experiments (§4)] Experiments (§4): The reported 91% MAE reduction on Pendulum and 87% FID reduction on ADNI are presented as evidence of causal fidelity, but without ablations that isolate the contribution of the causal components (e.g., removing the contrastive loss or prompt alignment while retaining standard conditioning) or statistical significance tests against strong non-causal baselines, it remains unclear whether gains stem from causal enforcement or improved prompt binding.
Authors: We agree that isolating the causal components and providing statistical tests would strengthen the causal claims. In the revised version we will add ablation experiments that disable prompt-aligned injection and the conditioned token contrastive loss individually (while retaining the base conditioning and adapter architecture) and report the resulting MAE and FID degradations. We will also include statistical significance tests (paired t-tests across multiple random seeds) comparing the full Causal-Adapter against strong non-causal baselines such as standard LoRA conditioning and prompt-only editing. These results will be presented in an expanded §4 and the supplementary material. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces Causal-Adapter as a modular adaptation of frozen text-to-image diffusion backbones using prompt-aligned injection and a conditioned token contrastive loss to support causal interventions on attributes. Performance is evaluated empirically via MAE reductions on Pendulum and FID on ADNI, with no equations or claims in the abstract reducing these metrics or the central counterfactual claims to quantities defined by the method's own fitted parameters or self-referential definitions. The invocation of structural causal modeling terminology is presented as an application of existing concepts rather than a self-citation load-bearing step or ansatz that collapses to the inputs. The derivation remains self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal relationships among visual attributes can be effectively modeled and enforced through alignment with textual embeddings and token-level contrastive objectives in a frozen diffusion model.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L = L_DM + λ L_CTC ... InfoNCE ... prompt-aligned injection (PAI) ... Conditioned Token Contrast (CTC)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.