Attractor States Emerge in Multi-Turn LLM Conversations
Pith reviewed 2026-06-30 06:55 UTC · model grok-4.3
The pith
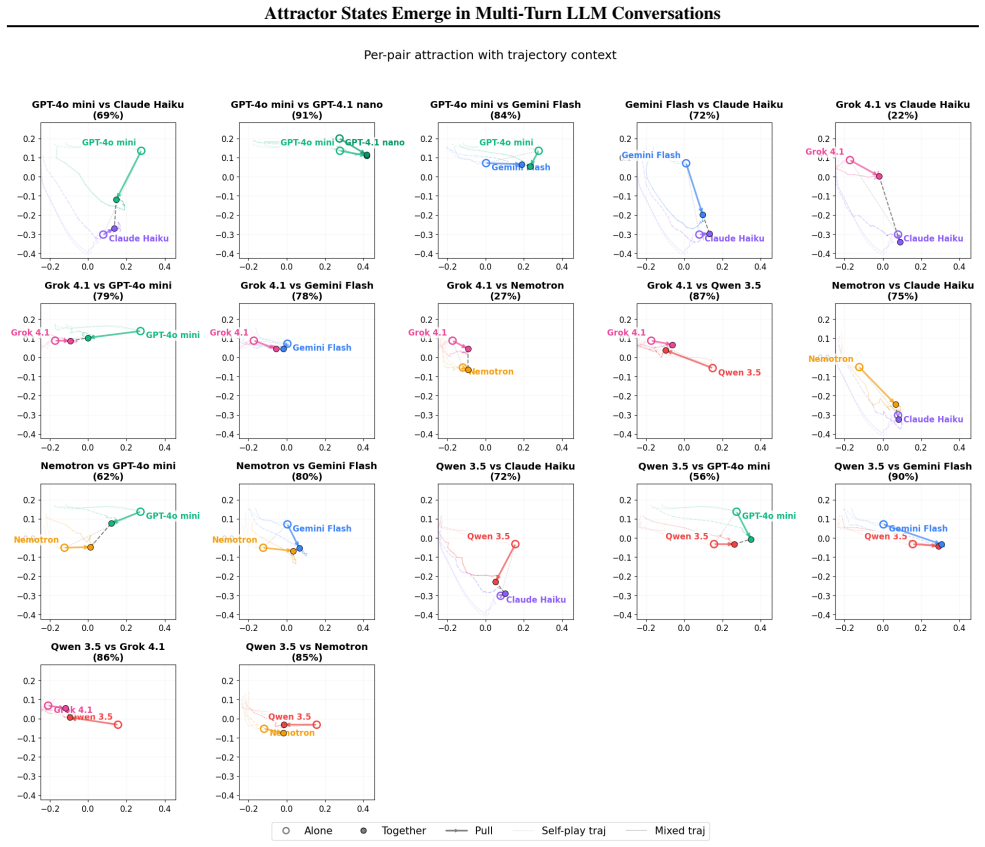
Self-play LLM conversations form model-specific attractor states that pull other models toward their traits in mixed debates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
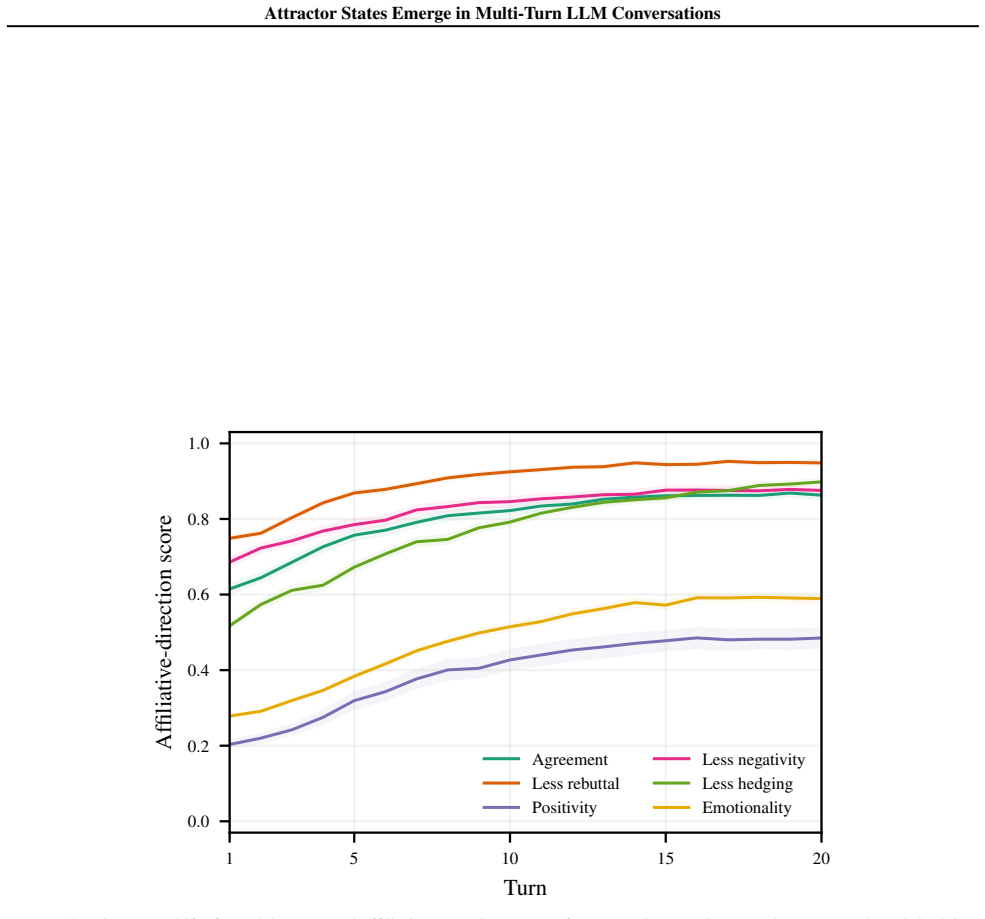
Self-play trajectories constitute model-specific attractors in representation space, discourse traits, and stances that draw conversation partners asymmetrically during mixed-play debates, thereby influencing the other models' stylistic choices and behavior.
What carries the argument
Model-specific attractor states formed by self-play trajectories, measured through convergence in latent representations, discourse traits, and stances across topics.
If this is right
- Self-play trajectories act as stable reference points that other models approach in mixed interactions.
- Influence between models is asymmetric, with certain models exerting stronger pull on stylistic and stance features.
- Open-ended LLM interactions become partially predictable from the participating models' individual attractor properties.
- Structured partner effects shape final behavior beyond simple averaging or random drift.
Where Pith is reading between the lines
- Systems that repeatedly pair a strong attractor model with malleable ones may converge to the attractor's style across many tasks.
- Tracking which models function as attractors could guide selection of agent teams to achieve desired stability or diversity.
- The asymmetry suggests that adding or removing one model can shift the entire conversation basin in ways not symmetric to its own self-play behavior.
Load-bearing premise
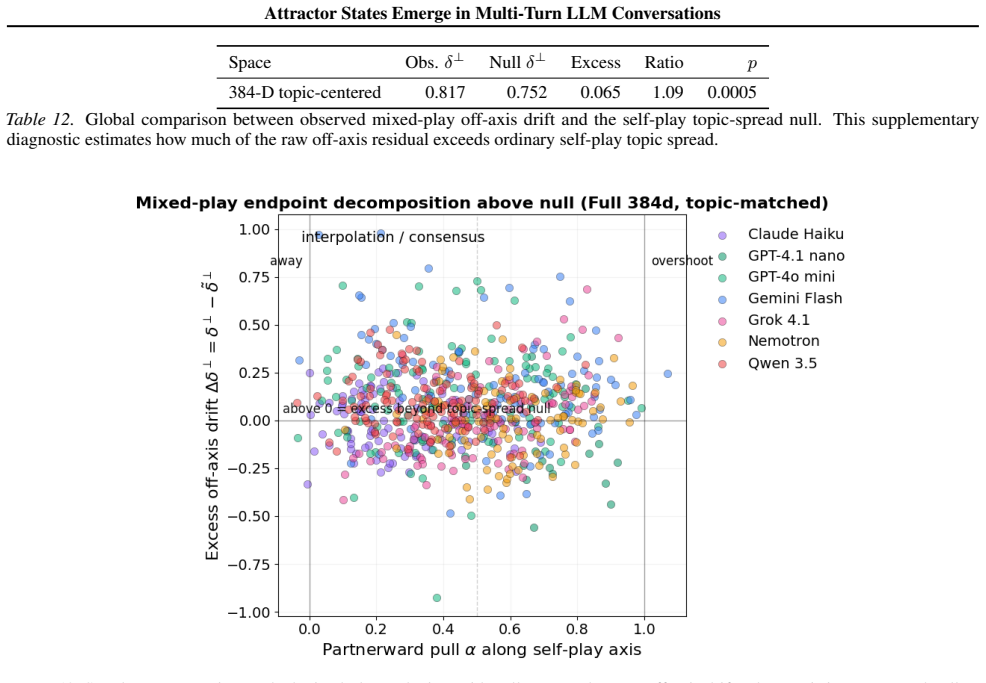
The convergences seen in representation space, discourse traits, and stances across the tested topics reflect genuine topic-independent attractor states rather than topic-specific effects or measurement artifacts.
What would settle it
Repeating the experiments on a fresh set of topics outside the original 20 and finding that the same models no longer converge to the same relative positions in representation space or adopt the same discourse traits would falsify the attractor claim.
Figures

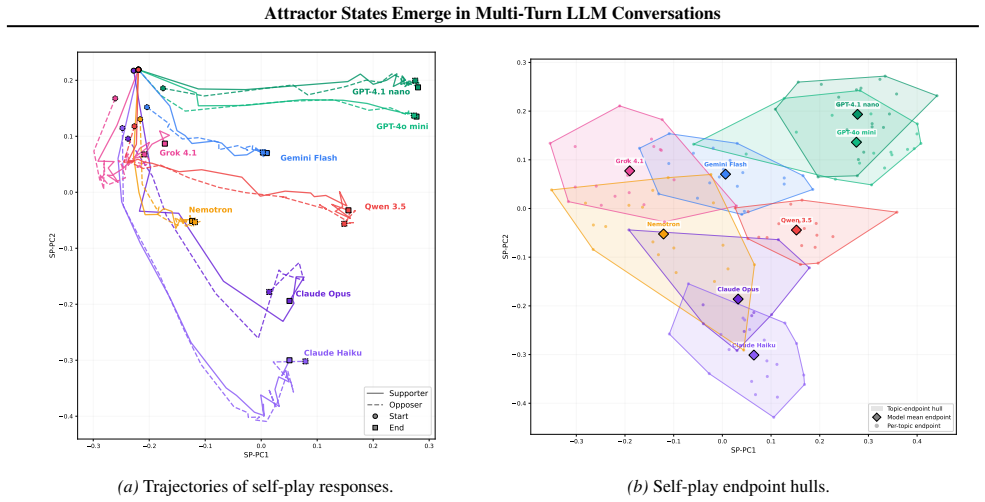
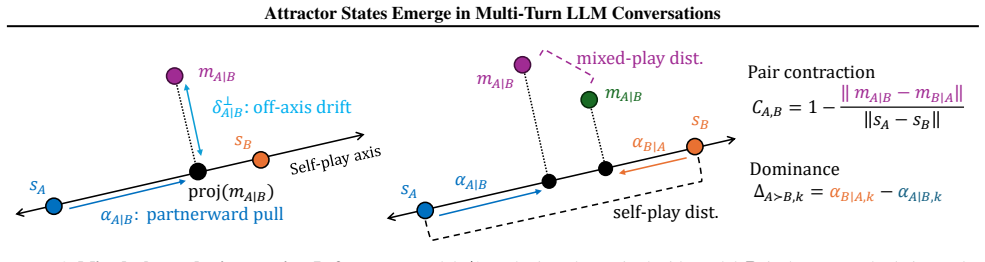
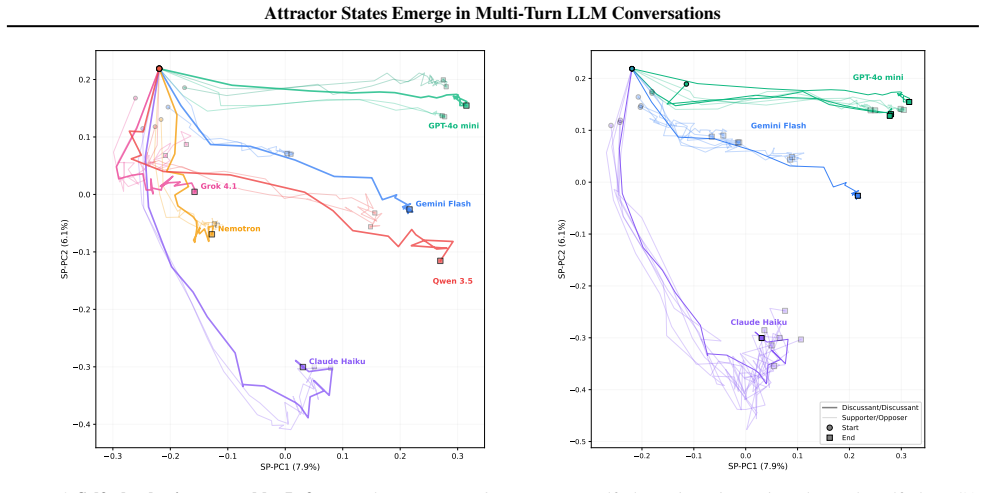
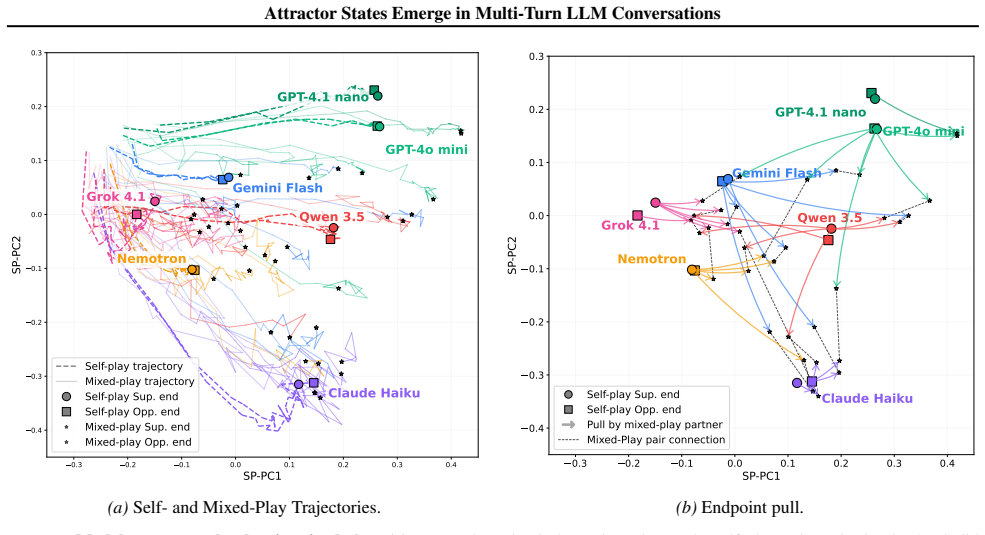

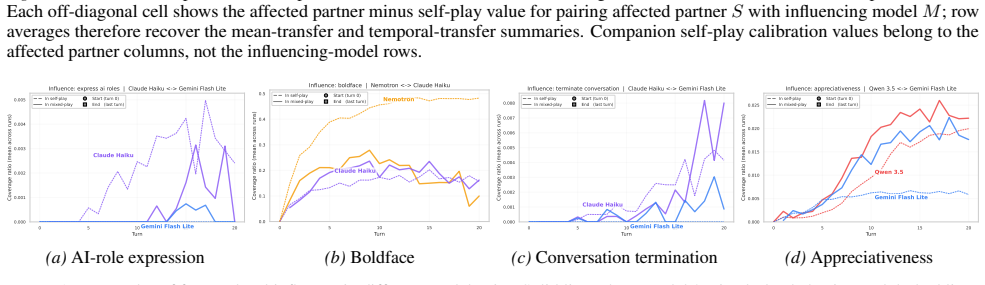
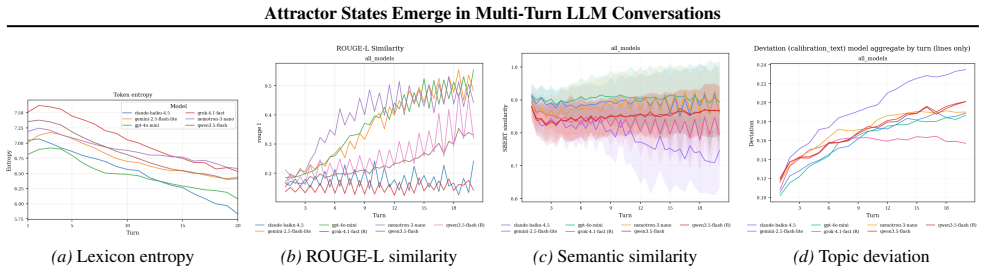
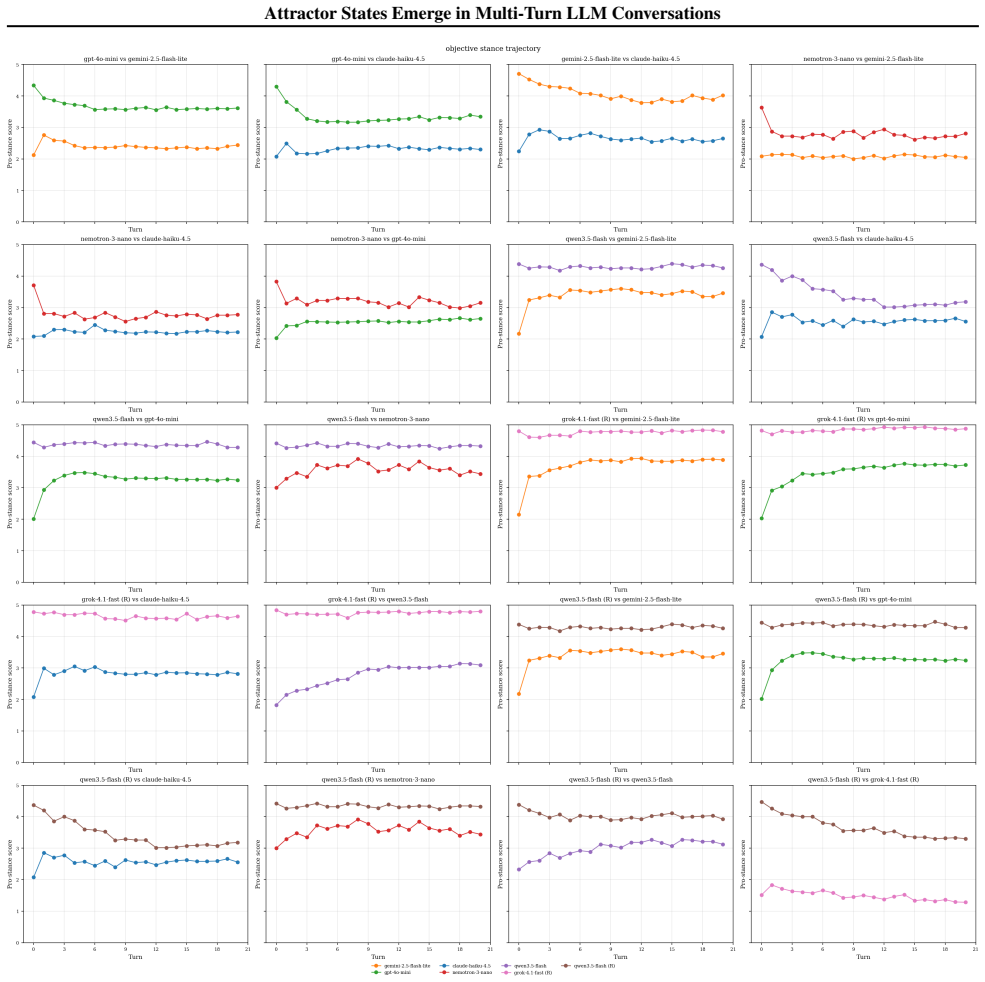
read the original abstract
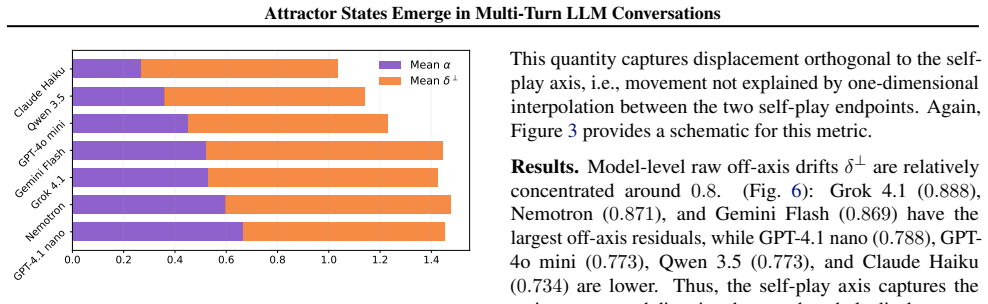
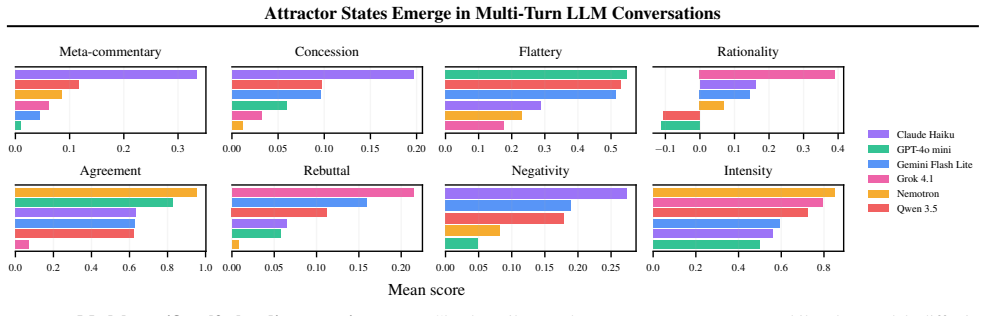
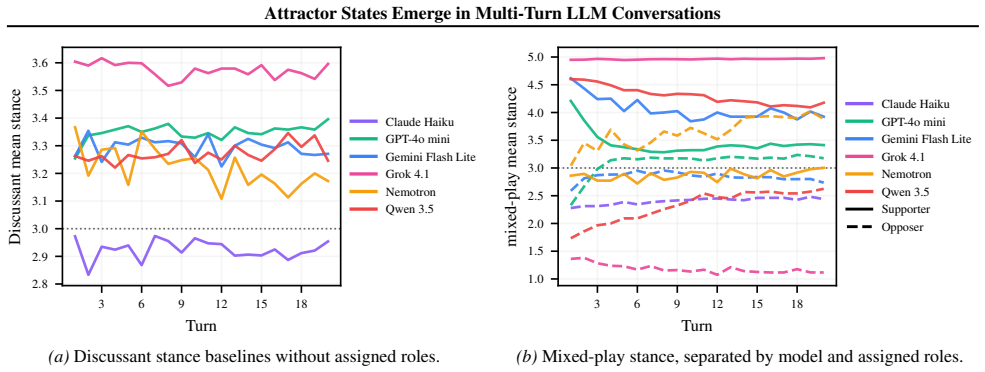
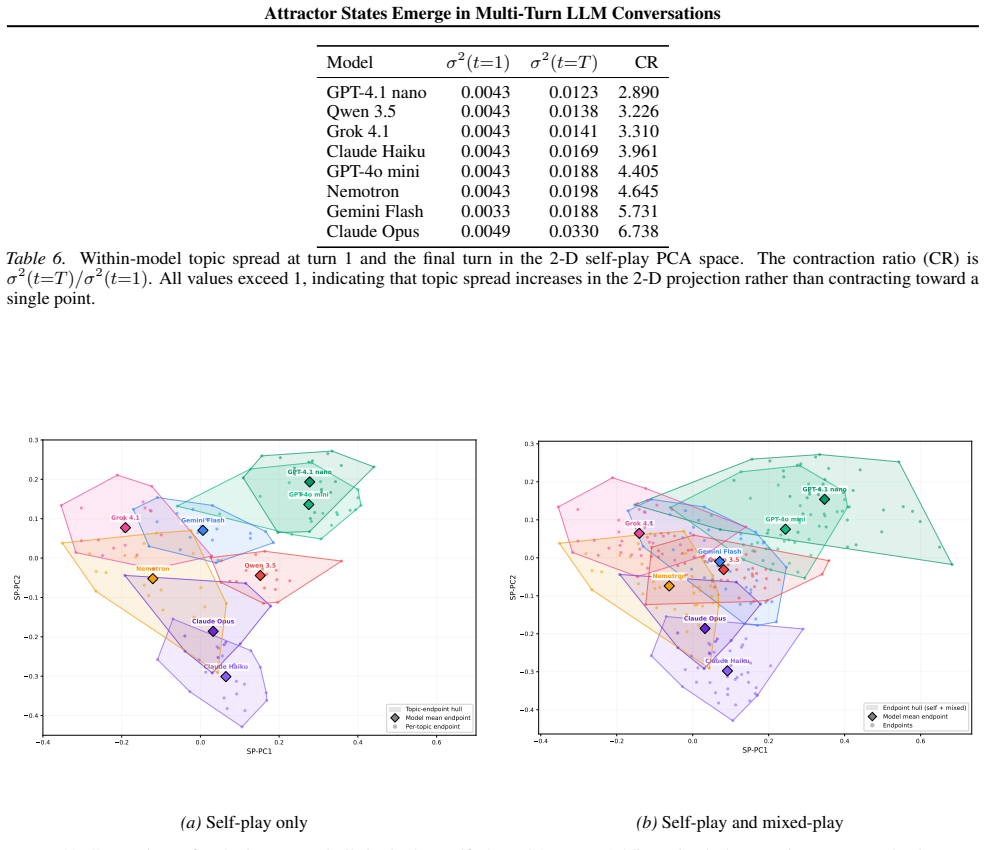
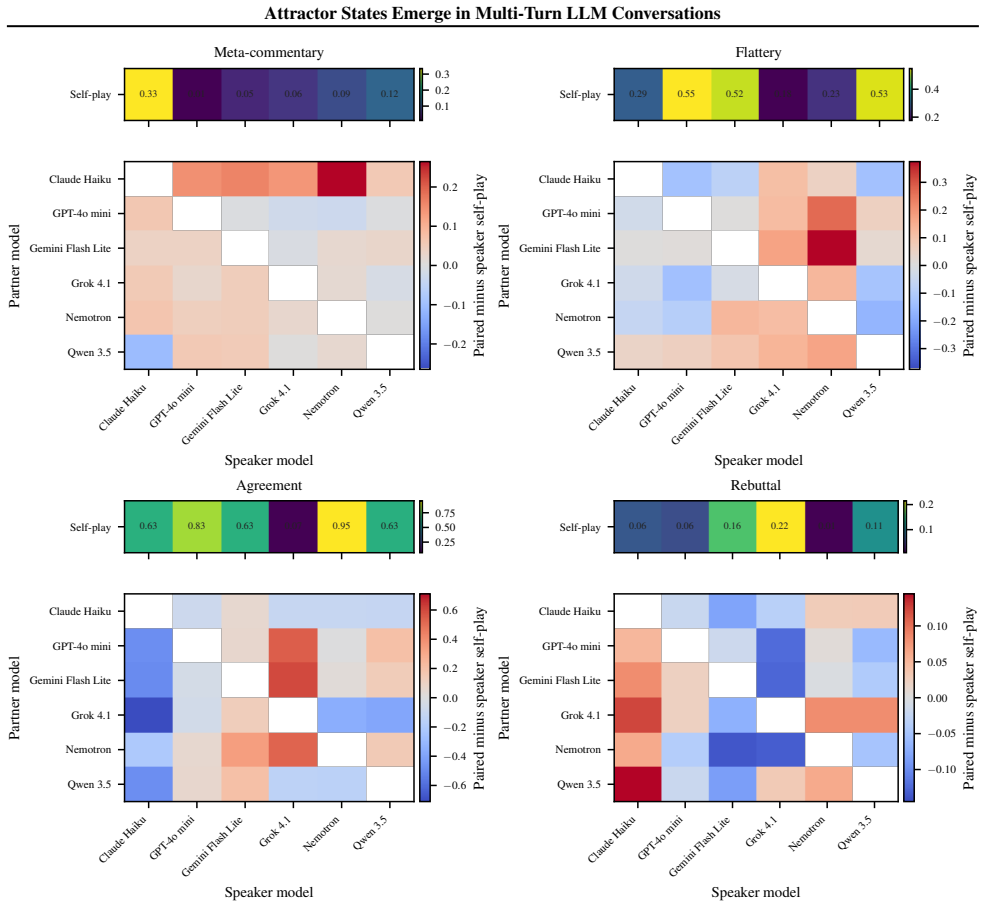
Large language models (LLMs) are increasingly used in open-ended multi-agent settings, but the long-run dynamics of model--model interaction remain poorly understood. We study whether open-ended LLM discussions exhibit attractor-like behavior, i.e. topic-independent stable sets of behaviors which conversations settle into. Across 7 LLMs and 20 controversial topics, we compare self-play and mixed-play dyadic debates, tracking trajectories in representation space, discourse traits, and stances. We find self-play trajectories to be model-specific attractors that draw their conversation partners asymmetrically in mixed-play debates, influencing the other models' stylistic choices and behavior. For example, Claude Haiku is a strong attractor of other models in latent space, corresponding to other models taking on its traits like metacommentary, and models like GPT-4.1 nano are especially malleable. Our results suggest that open-ended LLM interactions are partially predictable from model-specific attractors, but shaped by structured and asymmetric partner influence. Overall, our analysis sheds some light on the complex behavior of open-ended multi-agent interaction, which we hope is helpful in designing, predicting, and monitoring autonomous agentic systems in the real world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines long-run dynamics in open-ended multi-turn LLM conversations, testing whether they exhibit attractor-like behavior (topic-independent stable sets of behaviors). Using 7 LLMs and 20 controversial topics, it compares self-play versus mixed-play dyadic debates and tracks trajectories in representation space, discourse traits, and stances. The central finding is that self-play trajectories constitute model-specific attractors that asymmetrically draw conversation partners in mixed-play settings, with examples such as Claude Haiku strongly influencing other models' traits (e.g., metacommentary) while models like GPT-4.1 nano are more malleable. The authors conclude that such interactions are partially predictable from these attractors but shaped by asymmetric partner influence.
Significance. If the central claim holds after verification of topic controls and statistical rigor, the work would offer a useful empirical lens on multi-agent LLM dynamics, with potential value for designing, predicting, and monitoring autonomous agent systems. The asymmetric influence findings and model-specific patterns could inform practical deployment considerations. However, the current presentation supplies no details on representation-space metrics, statistical tests, error bars, or data exclusion rules, limiting immediate impact.
major comments (3)
- [Abstract / Experimental Setup] Abstract and experimental description: the claim that self-play trajectories form topic-independent model-specific attractors requires an explicit cross-topic distance metric (or equivalent control) between same-model self-play trajectories to distinguish model basins from topic-driven clustering or shared lexical/stance priors across the 20 controversial topics. No such metric or control is described, leaving the topic-independence assumption unverified and load-bearing for the central claim.
- [Results] Results section: the identification of attractors in representation space, discourse traits, and stances lacks reported statistical tests, error bars, or controls for topic dependence; without these, it is unclear whether observed convergence reflects genuine attractor states or measurement artifacts or topic-specific effects.
- [Methods] Methods: no details are supplied on the precise representation-space metrics, discourse trait definitions, stance extraction procedures, or data exclusion rules, which are necessary to assess whether the reported asymmetric influence (e.g., Claude Haiku as strong attractor) is robust.
minor comments (1)
- [Abstract] The abstract could more clearly distinguish the self-play versus mixed-play comparison from any fitted parameters or self-referential definitions to strengthen the circularity assessment.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which will help strengthen the empirical rigor of our study on attractor states in multi-turn LLM conversations. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and experimental description: the claim that self-play trajectories form topic-independent model-specific attractors requires an explicit cross-topic distance metric (or equivalent control) between same-model self-play trajectories to distinguish model basins from topic-driven clustering or shared lexical/stance priors across the 20 controversial topics. No such metric or control is described, leaving the topic-independence assumption unverified and load-bearing for the central claim.
Authors: We agree that an explicit cross-topic distance metric would better substantiate the topic-independence of the attractors. While our experiments span 20 diverse topics and show consistent model-specific patterns in self-play that differ from mixed-play influences, we did not compute a formal metric. In the revision, we will add a cross-topic analysis computing the average distance between self-play trajectories of the same model on different topics and compare it to distances between different models, to demonstrate that model basins are tighter than topic effects. revision: yes
-
Referee: [Results] Results section: the identification of attractors in representation space, discourse traits, and stances lacks reported statistical tests, error bars, or controls for topic dependence; without these, it is unclear whether observed convergence reflects genuine attractor states or measurement artifacts or topic-specific effects.
Authors: The referee is correct that the current results presentation would benefit from statistical tests and error bars. We will revise the Results section to include appropriate statistical analyses, such as tests for significant differences in convergence rates, error bars on trajectory plots derived from multiple runs or bootstrapping, and controls by reporting results aggregated across topics with per-topic breakdowns to rule out topic-specific effects. revision: yes
-
Referee: [Methods] Methods: no details are supplied on the precise representation-space metrics, discourse trait definitions, stance extraction procedures, or data exclusion rules, which are necessary to assess whether the reported asymmetric influence (e.g., Claude Haiku as strong attractor) is robust.
Authors: We will update the Methods section to include all requested details. Specifically, we will specify the representation space metric (e.g., the embedding model and similarity measure), provide definitions and examples for each discourse trait, detail the stance extraction method (including any classifiers or prompts used), and list data exclusion rules such as filters for conversation validity or length. revision: yes
Circularity Check
No circularity: purely empirical trajectory comparison
full rationale
The paper reports observational results from running self-play and mixed-play conversations across models and topics, then measuring convergence in representation space, discourse traits, and stances. No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce by construction to the inputs. The attractor claim is an empirical description of observed behavior, not a self-referential definition or renamed fit. Self-citations, if any, are not load-bearing for the central finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature , pages=
Accelerating scientific discovery with Co-Scientist , author=. Nature , pages=. 2026 , publisher=
2026
-
[2]
Agent-to-Agent Theory of Mind: Testing Interlocutor Awareness among Large Language Models
Choi, Younwoo and Li, Changling and Yang, Yongjin and Jin, Zhijing. Agent-to-Agent Theory of Mind: Testing Interlocutor Awareness among Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1471
-
[3]
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Beyond single-turn: A survey on multi-turn interactions with large language models , author=. arXiv preprint arXiv:2504.04717 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[5]
Kaur, Avneet , editor =. Echoes of. Findings of the. doi:10.18653/v1/2025.findings-emnlp.1241 , url =
-
[6]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[7]
American Journal Of Big Data , volume=
From Code Completion to Autonomous Pipeline Orchestration: How LLM-Powered Developer Tools Are Reshaping Software Engineering Workflows , author=. American Journal Of Big Data , volume=
-
[8]
Karen D Hughes and Alla Konnikov and Nicole Denier and Yang Hu , title =. Human Relations , volume =. 2026 , doi =. https://doi.org/10.1177/00187267251403902 , abstract =
-
[9]
Nature Machine Intelligence , pages=
A large-scale randomized study of large language model feedback in peer review , author=. Nature Machine Intelligence , pages=. 2026 , publisher=
2026
-
[10]
Ferrag, Mohamed Amine and Tihanyi, Norbert and Debbah, Merouane , month = mar, year =. From. doi:10.48550/arXiv.2504.19678 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19678
-
[11]
arXiv.org , author =
Unveiling. arXiv.org , author =. 2025 , keywords =
2025
-
[12]
arXiv preprint arXiv:2512.10350 , year=
Tacheny, Nicolas , month = jan, year =. Geometric. doi:10.48550/arXiv.2512.10350 , abstract =
-
[13]
Gooding, Sian and Grefenstette, Edward , month = nov, year =. Interaction. doi:10.48550/arXiv.2511.08394 , abstract =
-
[14]
Perez, Jérémy and Kovač, Grgur and Léger, Corentin and Colas, Cédric and Molinaro, Gaia and Derex, Maxime and Oudeyer, Pierre-Yves and Moulin-Frier, Clément , month = jan, year =. When. doi:10.48550/arXiv.2407.04503 , abstract =
-
[15]
2018 , publisher=
Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering , author=. 2018 , publisher=
2018
-
[16]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unveiling Attractor Cycles in Large Language Models: A Dynamical Systems View of Successive Paraphrasing , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:2512.10350 , year=
Geometric Dynamics of Agentic Loops in Large Language Models , author=. arXiv preprint arXiv:2512.10350 , year=
-
[18]
Selective agreement, not sycophancy: investigating opinion dynamics in
Cau, Erica and Pansanella, Valentina and Pedreschi, Dino and Rossetti, Giulio , journal=. Selective agreement, not sycophancy: investigating opinion dynamics in. 2025 , publisher=
2025
-
[19]
Language-Driven Opinion Dynamics in Agent-Based Simulations with
Cau, Erica and Pansanella, Valentina and Pedreschi, Dino and Rossetti, Giulio , journal=. Language-Driven Opinion Dynamics in Agent-Based Simulations with. 2025 , url=
2025
-
[20]
Simulating Opinion Dynamics with Networks of
Chuang, Yun-Shiuan and Goyal, Agam and Harlalka, Nikunj and Suresh, Siddharth and Hawkins, Robert and Yang, Sijia and Shah, Dhavan and Hu, Junjie and Rogers, Timothy , booktitle=. Simulating Opinion Dynamics with Networks of. 2024 , publisher=
2024
-
[21]
Emergent social conventions and collective bias in
Ashery, Ariel Flint and Aiello, Luca Maria and Baronchelli, Andrea , journal=. Emergent social conventions and collective bias in. 2025 , doi=
2025
-
[22]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Biases in Opinion Dynamics in Multi-Agent Systems of Large Language Models: A Case Study on Funding Allocation , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=. 2025 , publisher=
2025
-
[23]
and Rockt\"
Khan, Akbir and Hughes, John and Valentine, Dan and Ruis, Laura and Sachan, Kshitij and Radhakrishnan, Ansh and Grefenstette, Edward and Bowman, Samuel R. and Rockt\". Debating with More Persuasive. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , volume=
2024
-
[24]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , publisher=
2024
-
[25]
Estornell, Andrew and Liu, Yang , booktitle=. Multi-. 2024 , publisher=
2024
-
[26]
Proceedings of the 41st International Conference on Machine Learning , year=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. Proceedings of the 41st International Conference on Machine Learning , year=
-
[27]
2018 , url=
Irving, Geoffrey and Christiano, Paul and Amodei, Dario , journal=. 2018 , url=
2018
-
[28]
The Twelfth International Conference on Learning Representations , year=
Towards Understanding Sycophancy in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
2025 , url=
Liu, Joshua and Jain, Aarav and Takuri, Soham and Vege, Srihan and Akalin, Aslihan and Zhu, Kevin and O'Brien, Sean and Sharma, Vasu , journal=. 2025 , url=
2025
-
[30]
Social Sycophancy: A Broader Understanding of
Cheng, Myra and Yu, Sunny and Lee, Cinoo and Khadpe, Pranav and Ibrahim, Lujain and Jurafsky, Dan , booktitle=. Social Sycophancy: A Broader Understanding of. 2026 , note=
2026
-
[31]
On the conversational persuasiveness of
Salvi, Francesco and Horta Ribeiro, Manoel and Gallotti, Riccardo and West, Robert , journal=. On the conversational persuasiveness of. 2025 , doi=
2025
-
[32]
Beyond One-Way Influence: Bidirectional Opinion Dynamics in Multi-Turn Human-
Jiang, Yuyang and Guo, Longjie and Wu, Yuchen and Caliskan, Aylin and Mitra, Tanu and Shen, Hua , journal=. Beyond One-Way Influence: Bidirectional Opinion Dynamics in Multi-Turn Human-. 2025 , url=
2025
-
[33]
Conference on Language Modeling (COLM 2024) , year=
Measuring and Controlling Instruction (In)Stability in Language Model Dialogs , author=. Conference on Language Modeling (COLM 2024) , year=
2024
-
[34]
2024 , publisher=
Frisch, Ivar and Giulianelli, Mario , booktitle=. 2024 , publisher=
2024
-
[35]
2024 , doi=
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , journal=. 2024 , doi=
2024
-
[36]
Generative Agents: Interactive Simulacra of Human Behavior , author=. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST '23) , year=. doi:10.1145/3586183.3606763 , url=
-
[37]
and Saichandran, Ketan S
Lehr, Steven A. and Saichandran, Ketan S. and Harmon-Jones, Eddie and Vitali, Nykko and Banaji, Mahzarin R. , journal=. Kernels of selfhood:. 2025 , doi=
2025
-
[38]
2025 , month=
System Card:. 2025 , month=
2025
-
[39]
``Spiritual Bliss'' in
Michels, Julian , year=. ``Spiritual Bliss'' in
-
[40]
Alexander, Scott , year=. The
-
[41]
2025 , month=
Claude Finds God , author=. 2025 , month=
2025
- [42]
-
[43]
Journal of the American Statistical Association , volume=
Reaching a Consensus , author=. Journal of the American Statistical Association , volume=
-
[44]
Journal of Artificial Societies and Social Simulation , volume=
Opinion Dynamics and Bounded Confidence: Models, Analysis and Simulation , author=. Journal of Artificial Societies and Social Simulation , volume=. 2002 , url=
2002
-
[45]
The Journal of Mathematical Sociology , volume=
Social influence and opinions , author=. The Journal of Mathematical Sociology , volume=
-
[46]
Advances in Group Processes , volume=
Social Influence Networks and Opinion Change , author=. Advances in Group Processes , volume=. 1999 , publisher=
1999
-
[47]
Advances in Complex Systems , volume=
Mixing beliefs among interacting agents , author=. Advances in Complex Systems , volume=
-
[48]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
and Hatfield-Dodds, Zac and Mann, Ben and Amodei, Dario and Joseph, Nicholas and McCandlish, Sam and Brown, Tom and Kaplan, Jared , journal=
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dale and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
2022
- [50]
-
[51]
Interaction Dynamics as a Reward Signal for
Gooding, Sian and Grefenstette, Edward , journal=. Interaction Dynamics as a Reward Signal for. 2025 , url=
2025
-
[52]
Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Emergent Convergence in Multi-Agent LLM Annotation , author=. Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[53]
2023 , url=
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , booktitle=. 2023 , url=
2023
-
[54]
The Twelfth International Conference on Learning Representations , year=
Does Writing with Language Models Reduce Content Diversity? , author=. The Twelfth International Conference on Learning Representations , year=
-
[55]
Conformity, Confabulation, and Impersonation: Persona Inconstancy in Multi-Agent LLM Collaboration
Baltaji, Razan and Hemmatian, Babak and Varshney, Lav. Conformity, Confabulation, and Impersonation: Persona Inconstancy in Multi-Agent LLM Collaboration. Proceedings of the 2nd Workshop on Cross-Cultural Considerations in NLP. 2024. doi:10.18653/v1/2024.c3nlp-1.2
-
[56]
Costello and Gordon Pennycook and David G
Thomas H. Costello and Gordon Pennycook and David G. Rand , title =. Science , volume =. 2024 , doi =. https://www.science.org/doi/pdf/10.1126/science.adq1814 , abstract =
-
[57]
Political Analysis , volume=
Out of one, many: Using language models to simulate human samples , author=. Political Analysis , volume=. 2023 , publisher=
2023
-
[58]
Systematic Biases in LLM Simulations of Debates
Taubenfeld, Amir and Dover, Yaniv and Reichart, Roi and Goldstein, Ariel. Systematic Biases in LLM Simulations of Debates. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.16
-
[59]
Proceedings of the 40th International Conference on Machine Learning , pages =
Whose Opinions Do Language Models Reflect? , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[60]
Bricknell, Adam , year=. Mapping
-
[61]
2025 , month=
The Void , author=. 2025 , month=
2025
-
[62]
Hangfan Zhang and Zhiyao Cui and Qiaosheng Zhang and Shuyue Hu , booktitle=. Multi-. 2025 , url=
2025
-
[63]
2026 , month=
The Bliss Attractor , author=. 2026 , month=
2026
-
[64]
The assistant axis: Situating and stabilizing the default persona of language models , author=. arXiv preprint arXiv:2601.10387 , year=
-
[65]
The Hot Mess of
Alexander H. The Hot Mess of. The Fourteenth International Conference on Learning Representations , year=
-
[66]
Collective AI can amplify tiny perturbations into divergent decisions
Chaotic Dynamics in Multi-LLM Deliberation , author=. arXiv preprint arXiv:2603.09127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
The Twelfth International Conference on Learning Representations , year=
Self-consuming generative models go mad , author=. The Twelfth International Conference on Learning Representations , year=
-
[68]
Jiang, Liwei and Chai, Yuanjun and Li, Margaret and Liu, Mickel and Fok, Raymond and Dziri, Nouha and Tsvetkov, Yulia and Sap, Maarten and Albalak, Alon and Choi, Yejin , month = oct, year =. Artificial. doi:10.48550/arXiv.2510.22954 , abstract =
-
[69]
Nehring, Jan and Gabryszak, Aleksandra and Jürgens, Pascal and Burchardt, Aljoscha and Schaffer, Stefan and Spielkamp, Matthias and Stark, Birgit , editor =. Large. Proceedings of the 2024. 2024 , keywords =
2024
-
[70]
LLMs Get Lost In Multi-Turn Conversation
Laban, Philippe and Hayashi, Hiroaki and Zhou, Yingbo and Neville, Jennifer , month = may, year =. doi:10.48550/arXiv.2505.06120 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.06120
-
[71]
Ratnakar, Shivam and Raghavendra, Sanjay , month = oct, year =. The. doi:10.48550/arXiv.2510.16712 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.16712
-
[72]
Abdulhai, Marwa and White, Isadora and Wan, Yanming and Qureshi, Ibrahim and Leibo, Joel and Kleiman-Weiner, Max and Jaques, Natasha , month = mar, year =. How. doi:10.48550/arXiv.2603.18161 , abstract =
-
[73]
Guzman Piedrahita, David and Yang, Yongjin and Sachan, Mrinmaya and Ramponi, Giorgia and Schölkopf, Bernhard and Jin, Zhijing , month = jun, year =. Corrupted by. doi:10.48550/arXiv.2506.23276 , abstract =
-
[74]
Old Habits Die Hard: How Conversational History Geometrically Traps LLMs
Simhi, Adi and Barez, Fazl and Tutek, Martin and Belinkov, Yonatan and Cohen, Shay B. , month = feb, year =. Old. doi:10.48550/arXiv.2603.03308 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.03308
-
[75]
Qiu, Tianyi Alex and He, Zhonghao and Chugh, Tejasveer and Kleiman-Weiner, Max , month = jun, year =. The. doi:10.48550/arXiv.2506.06166 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.