Adaptive Hard-Soft Physics-Informed Neural Networks for Robust Boundary-Constrained PDE Solving
Pith reviewed 2026-06-26 08:56 UTC · model grok-4.3
The pith
Enforcing Dirichlet and periodic boundaries exactly by construction while adaptively weighting soft PDE constraints improves convergence and accuracy of physics-informed neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
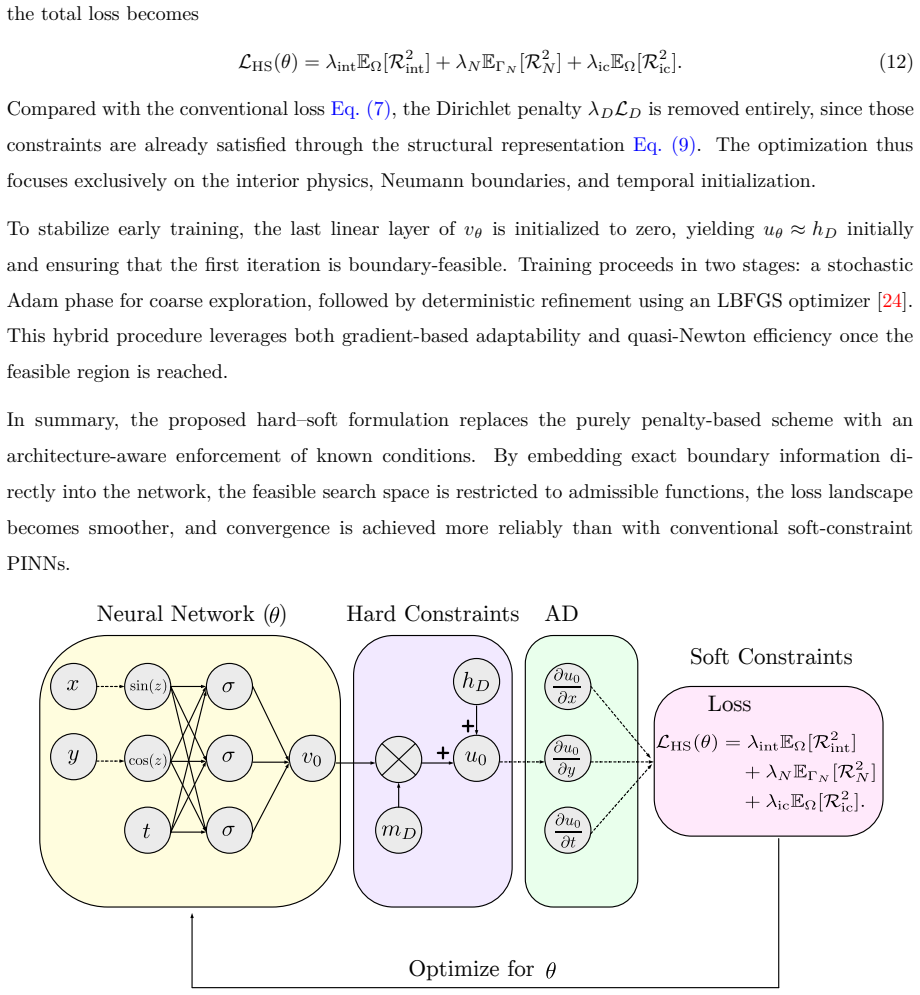
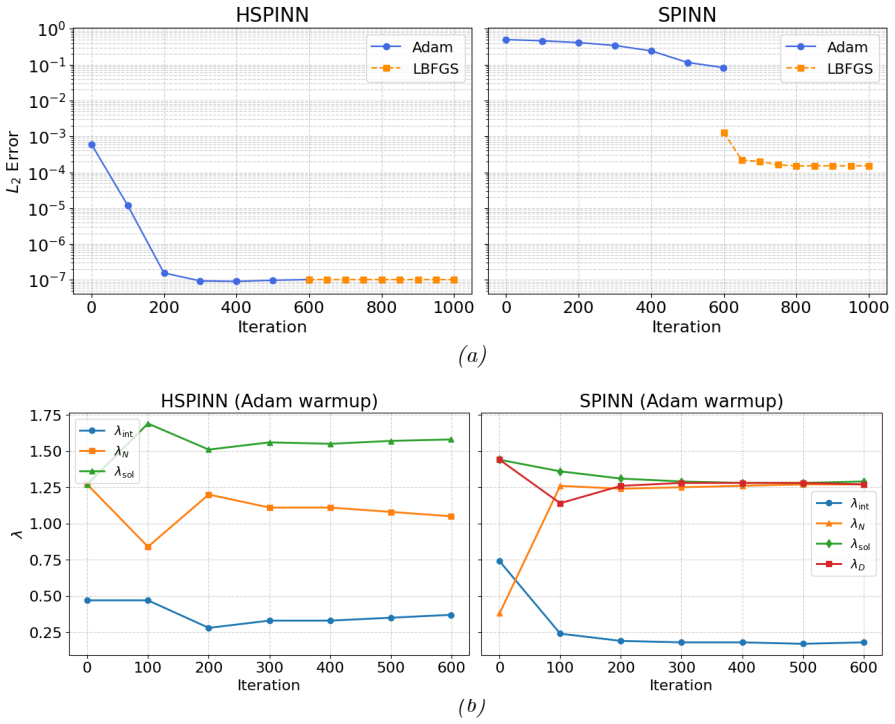
In the HSPINN framework, Dirichlet and periodic boundary conditions are enforced exactly by construction through analytical or polynomial lifting, masking functions, and periodic feature mappings, while the governing PDE residuals, Neumann fluxes, and initial conditions are treated as soft constraints. An inverse-share softmax strategy dynamically balances the relative importance of individual loss components during training, ensuring boundary admissibility throughout optimization and enhancing convergence efficiency and numerical robustness.
What carries the argument
The hard-soft constraint split with exact boundary enforcement via lifting and masking functions, combined with inverse-share softmax adaptive loss weighting.
If this is right
- Boundary conditions remain satisfied exactly even as the network parameters change during training.
- No manual scaling of loss terms is required due to the adaptive weighting.
- The method shows consistent improvements in convergence speed and accuracy across elliptic, parabolic, and hyperbolic PDEs.
- Gradient stability is improved by removing boundary terms from the soft loss.
Where Pith is reading between the lines
- The framework could be extended to more complex geometries if appropriate lifting functions are developed.
- Adaptive weighting might help in multi-physics problems where loss scales vary widely.
- Exact boundary satisfaction may allow for better error estimation in the interior solution.
Load-bearing premise
Suitable analytical or polynomial lifting functions, masking functions, and periodic feature mappings can be constructed for the target boundary conditions without limiting applicability or adding errors.
What would settle it
A PDE problem with boundary conditions for which no exact lifting or masking function can be found, leading to either approximation errors or inability to apply the method.
Figures
read the original abstract
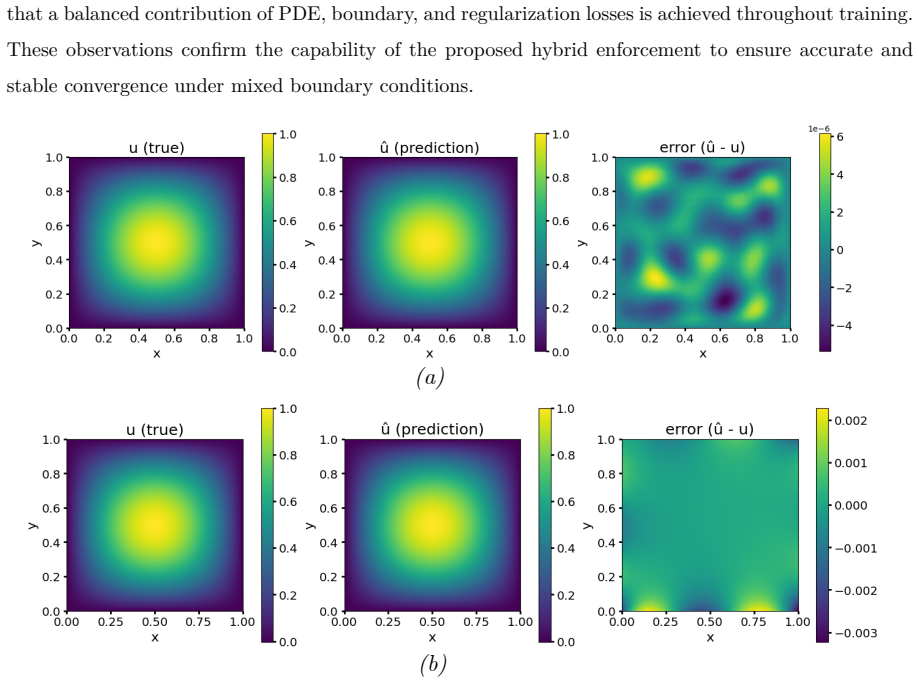
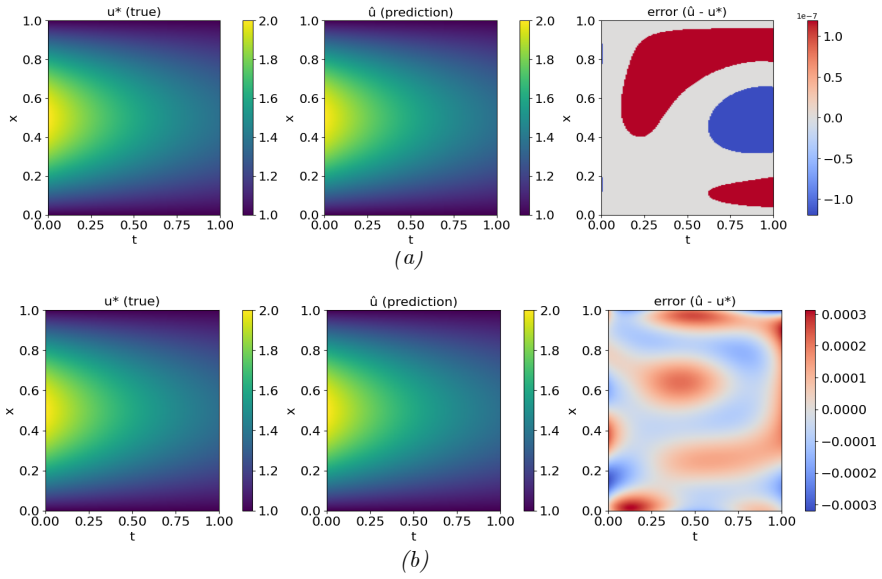
Physics-informed neural networks (PINNs) provide an effective way to solve partial differential equations (PDEs) by embedding physical principles into the learning process. However, the conventional PINN formulation, in which all constraints are imposed as soft penalty terms within a composite loss, often exhibits slow convergence, sensitivity to loss weight scaling, and inaccurate boundary enforcement due to poor conditioning of the optimization landscape. To address these limitations, this study proposes a unified hard--soft physics--informed neural network (HSPINN) with adaptive loss weighting. In this framework, Dirichlet and periodic boundary conditions are enforced exactly by construction through analytical or polynomial lifting, masking functions, and periodic feature mappings, while the governing PDE residuals, Neumann fluxes, and initial conditions are treated as soft constraints. An inverse-share softmax strategy dynamically balances the relative importance of individual loss components during training, eliminating manual penalty tuning and improving gradient stability. This formulation ensures boundary admissibility throughout optimization and enhances convergence efficiency and numerical robustness. Applications to representative elliptic (Poisson), parabolic (Burgers), and hyperbolic (convection with periodic boundaries) problems demonstrate that HSPINN consistently achieves faster convergence, higher accuracy, and greater stability than conventional PINNs, establishing a general and scalable foundation for physics-constrained deep learning across science and technology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Adaptive Hard-Soft Physics-Informed Neural Networks (HSPINN) that enforce Dirichlet and periodic boundary conditions exactly by construction via analytical/polynomial lifting functions, masking functions, and periodic feature mappings, while treating PDE residuals, Neumann fluxes, and initial conditions as soft constraints. An inverse-share softmax provides adaptive loss weighting. Experiments on Poisson (elliptic), Burgers (parabolic), and periodic convection (hyperbolic) problems are reported to show faster convergence, higher accuracy, and improved stability relative to conventional soft-constraint PINNs.
Significance. If the boundary constructions are shown to be exact, generalizable, and free of interior residual errors, and if the adaptive weighting demonstrably improves conditioning without problem-specific tuning, the framework could strengthen the reliability of physics-informed neural methods for boundary-value problems.
major comments (2)
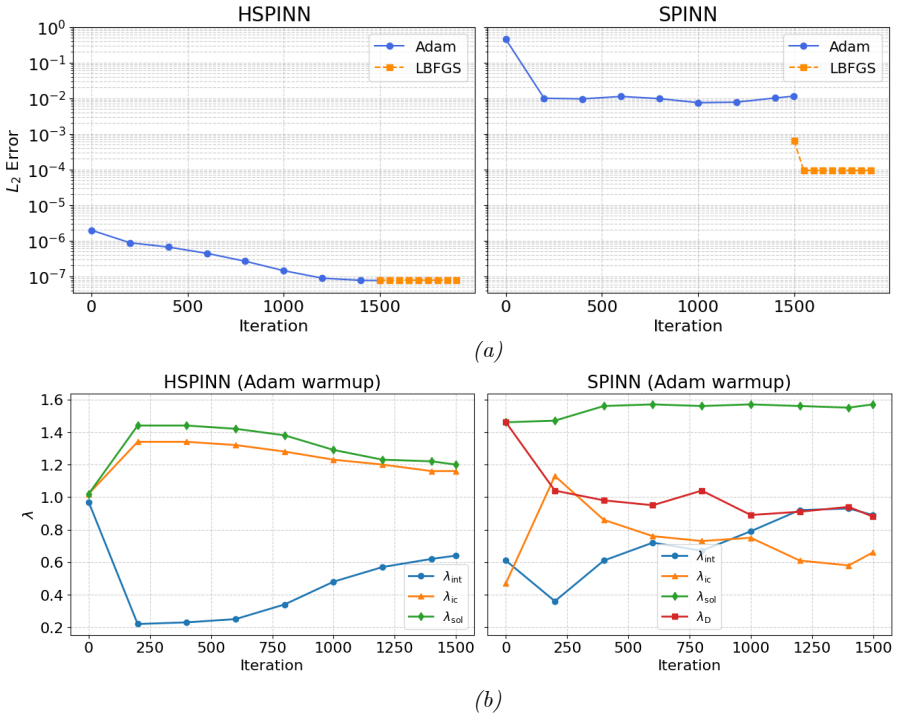
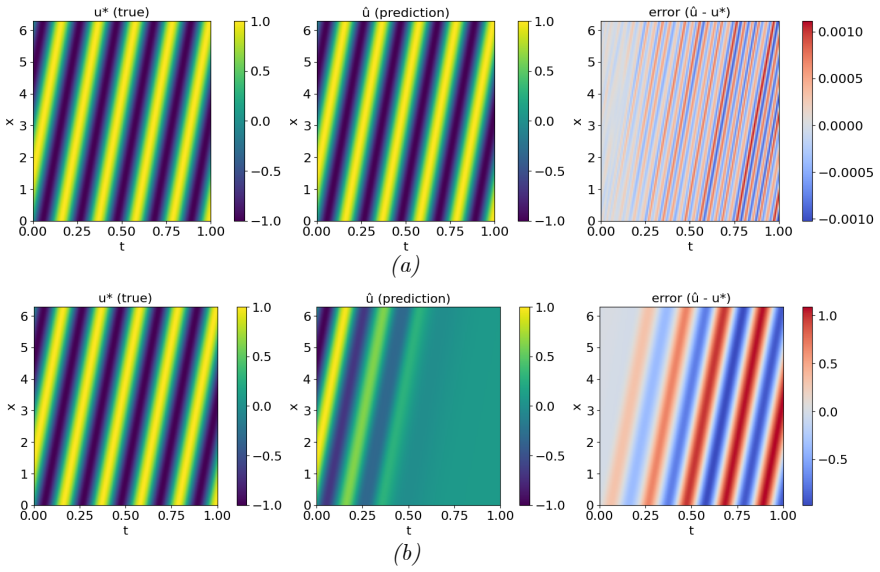
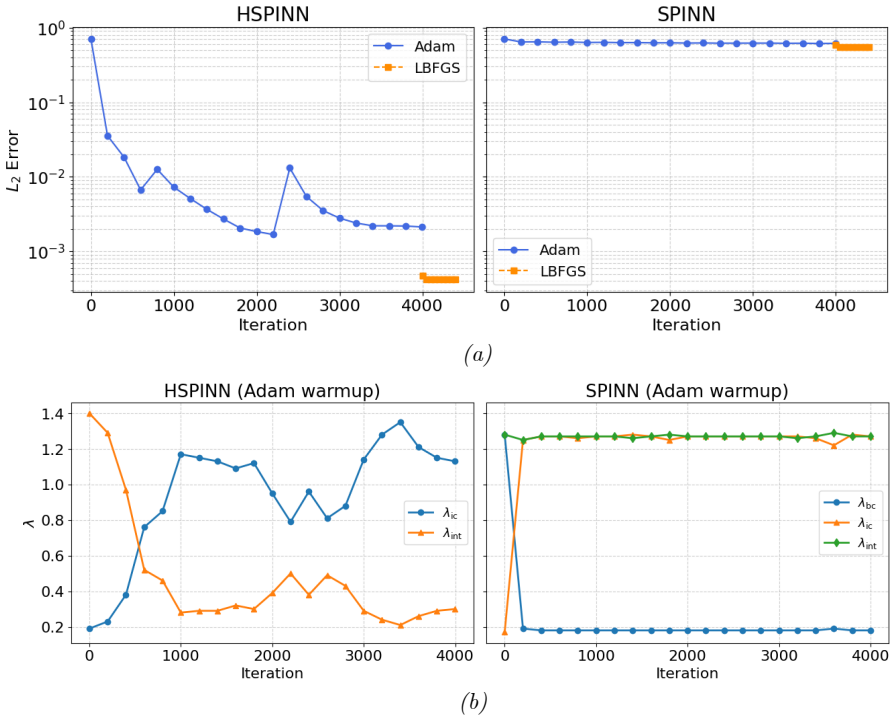
- [Abstract, §3] Abstract and §3 (experiments): the performance claims (faster convergence/higher accuracy/stability on the three representative problems) rest on the assertion that the lifting/masking/periodic mappings enforce BCs exactly without introducing new interior approximation error; no explicit functional forms, verification identities, or residual plots confirming that the modified network satisfies the original PDE interior are referenced.
- [§2] §2 (method): the inverse-share softmax is stated to 'dynamically balance' components and 'eliminate manual penalty tuning,' but the precise update rule, its dependence on current loss values, and any analysis showing it avoids the same conditioning issues as fixed weights are not provided; without these the comparison to conventional PINNs is not load-bearing.
minor comments (2)
- [§2] Notation for the masking function and periodic feature mapping should be introduced with a single consistent symbol set in the methods section rather than varying across equations.
- [§3] Figure captions for the convergence plots should include the precise network architecture, number of collocation points, and optimizer settings used for both HSPINN and baseline PINN runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of the HSPINN framework. We address each major comment below and indicate revisions where they strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (experiments): the performance claims (faster convergence/higher accuracy/stability on the three representative problems) rest on the assertion that the lifting/masking/periodic mappings enforce BCs exactly without introducing new interior approximation error; no explicit functional forms, verification identities, or residual plots confirming that the modified network satisfies the original PDE interior are referenced.
Authors: The explicit functional forms of the analytical/polynomial lifting functions, masking functions, and periodic feature mappings, together with the derivations establishing exact BC enforcement by construction, are provided in Section 2. We agree that explicit verification strengthens the experimental claims in §3. In the revision we will add verification identities and interior residual plots for the three test problems to confirm that the boundary constructions introduce no additional approximation error in the PDE interior. revision: yes
-
Referee: [§2] §2 (method): the inverse-share softmax is stated to 'dynamically balance' components and 'eliminate manual penalty tuning,' but the precise update rule, its dependence on current loss values, and any analysis showing it avoids the same conditioning issues as fixed weights are not provided; without these the comparison to conventional PINNs is not load-bearing.
Authors: Section 2 presents the inverse-share softmax and its dependence on instantaneous loss values for dynamic balancing. We acknowledge that an explicit update formula and a concise conditioning analysis would make the comparison to fixed-weight PINNs more rigorous. The revision will include the precise mathematical update rule and a brief discussion of its effect on gradient stability. revision: yes
Circularity Check
No significant circularity; boundary enforcement and adaptive weighting are explicit constructions, not reductions to inputs.
full rationale
The abstract and described framework enforce Dirichlet/periodic BCs exactly by construction using analytical/polynomial lifting, masking functions, and periodic feature mappings, while treating PDE residuals, Neumann fluxes, and ICs as soft constraints with an inverse-share softmax for dynamic balancing. No equations are shown that define a quantity in terms of itself or rename a fitted parameter as a prediction. No self-citation chains or uniqueness theorems are invoked as load-bearing. The performance claims on elliptic, parabolic, and hyperbolic examples are presented as empirical results of the hard-soft split, not as tautological outcomes. This is the common case of a self-contained method proposal with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Inverse problem solution and optimization in the vibration analysis of nanocomposite cylindrical shell using l-bfgs-b algorithm.Composite Structures, 370:119309, 2025
Duc Tien Nguyen, Nguyen Cong Tan, Darlington Yawson, and Dinh Gia Ninh. Inverse problem solution and optimization in the vibration analysis of nanocomposite cylindrical shell using l-bfgs-b algorithm.Composite Structures, 370:119309, 2025
2025
-
[2]
Duc Tien Nguyen and Dinh Gia Ninh. Modeling and quantifying uncertainty in nanocomposite shell vibrations using heteroscedastic gaussian processes.Engineering Applications of Artificial Intelli- gence, 157:111290, 2025
2025
-
[3]
Mathematical analysis of a finite difference method for inhomogeneous incompressible navier–stokes equations.Numerische Mathematik, 156(5):1809–1853, 2024
Kohei Soga. Mathematical analysis of a finite difference method for inhomogeneous incompressible navier–stokes equations.Numerische Mathematik, 156(5):1809–1853, 2024
2024
-
[4]
Courier Corporation, 2012
Thomas JR Hughes.The finite element method: linear static and dynamic finite element analysis. Courier Corporation, 2012. 23
2012
-
[5]
Runge–kutta physics in- formed neural networks: formulation and analysis: G
Georgios Akrivis, Charalambos G Makridakis, and Costas Smaragdakis. Runge–kutta physics in- formed neural networks: formulation and analysis: G. akrivis et al.Numerische Mathematik, 157 (6):1975–2016, 2025
1975
-
[6]
Error estimates for deep learning methods in fluid dynamics.Numerische Mathematik, 151(3):753–777, 2022
Animikh Biswas, Jing Tian, and Suleyman Ulusoy. Error estimates for deep learning methods in fluid dynamics.Numerische Mathematik, 151(3):753–777, 2022
2022
-
[7]
Duc Tien Nguyen, Nguyen Duc Manh, Nguyen Manh Dzung, and Dinh Gia Ninh. Highly effi- cient prediction of beating phenomena in laminated nanocomposite plates using a hybrid neural– numerical–analytical framework.European Journal of Mechanics-A/Solids, page 105844, 2025
2025
-
[8]
Utilizing optimal physics-informed neural networks for dynamical analysis of nanocomposite one-variable edge plates.Thin-Walled Structures, 202:111928, 2024
NguyenCongTan, NguyenDucTien, NguyenManhDzung, NguyenHoangHa, NguyenThanhDong, and Dinh Gia Ninh. Utilizing optimal physics-informed neural networks for dynamical analysis of nanocomposite one-variable edge plates.Thin-Walled Structures, 202:111928, 2024
2024
-
[9]
Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli
Salvatore Cuomo, Vincenzo S. Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics-informed neural networks: Where we are and what’s next.Journal of Scientific Computing, 92(3):88, 2022. doi: 10.1007/ s10915-022-01939-z
2022
-
[10]
Understanding and mitigating gradient pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081,
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081,
-
[11]
doi: 10.1137/20M1318043
-
[12]
Krishnapriyan, Amir Gholami, Sibo Zhe, Robert M
Aditi S. Krishnapriyan, Amir Gholami, Sibo Zhe, Robert M. Kirby, and Michael W. Mahoney. Characterizing possible failure modes in physics-informed neural networks.Advances in Neural Information Processing Systems (NeurIPS), 34:26548–26560, 2021
2021
-
[13]
Jagtap and George Em Karniadakis
Ameya D. Jagtap, Ehsan Kharazmi, and George E. Karniadakis. Extended physics-informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations.Communications in Computational Physics, 28(5):2002– 2041, 2020. doi: 10.4208/cicp.OA-2020-0164
-
[14]
Physics-informed neural networks with hard constraints for inverse design.SIAM Journal on Scientific Computing, 43(6):B1105–B1132, 2021
Lu Lu, Raphael Pestourie, Wenjie Yao, Zhicheng Wang, Francesc Verdugo, and Steven G John- son. Physics-informed neural networks with hard constraints for inverse design.SIAM Journal on Scientific Computing, 43(6):B1105–B1132, 2021
2021
-
[15]
DeepXDE: a deep learning library for solving differential equations
Lu Lu, Xuhui Meng, Zhiping Mao, and George E. Karniadakis. Deepxde: A deep learning library for solving differential equations.SIAM Review, 63(1):208–228, 2021. doi: 10.1137/19M1274067
-
[16]
Zhenyu Song, Xuhui Meng, and George E. Karniadakis. Hard constraint enforcement for physics- informed neural networks using distance functions.Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022. doi: 10.1016/j.cma.2022.114778. 24
-
[17]
Pavan Karumuri, Piyush Gajjar, and Prasanth Nair. Hard boundary condition enforcement in pinns using signed distance and neural basis functions.Computer Methods in Applied Mechanics and Engineering, 417:116542, 2023. doi: 10.1016/j.cma.2023.116542
-
[18]
Aliyu Muhammed Awwal, Lin Wang, Poom Kumam, Mohammed Ibrahim Sulaiman, Sani Salisu, Nasiru Salihu, and Petcharaporn Yodjai. Generalized rmil conjugate gradient method under the strong wolfe line search with application in image processing.Mathematical Methods in the Applied Sciences, 46(16):17544–17556, 2023
2023
-
[19]
Baoli Hao, Ulisses Braga-Neto, Chun Liu, Lifan Wang, and Ming Zhong. Structure preserving pinn for solving time dependent pdes with periodic boundary.arXiv preprint arXiv:2404.16189, 2024
arXiv 2024
-
[20]
Woojin Cho, Minju Jo, Haksoo Lim, Kookjin Lee, Dongeun Lee, Sanghyun Hong, and Noseong Park. Parameterized physics-informed neural networks for parameterized pdes.arXiv preprint arXiv:2408.09446, 2024
arXiv 2024
-
[21]
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019. doi: 10.1016/j.jcp. 2018.10.045
-
[22]
Levi McClenny and Ulisses Braga-Neto. Self-adaptive physics-informed neural networks using a soft attention mechanism.arXiv preprint arXiv:2009.04544, 2020
arXiv 2009
-
[23]
Sifan Wang, Hanze Wang, and Paris Perdikaris. Respecting causality for training physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 404:115783, 2022. doi: 10.1016/j.cma.2022.115783
-
[24]
Lei Yang, Xuhui Meng, and George E. Karniadakis. Learning to accelerate partial differential equations via latent global evolution.Nature Machine Intelligence, 4(12):1071–1083, 2022. doi: 10.1038/s42256-022-00541-8
-
[25]
A method for stochastic l-bfgs optimization
Peng Qi, Wei Zhou, and Jizhong Han. A method for stochastic l-bfgs optimization. In2017 IEEE 2nd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), pages 156–160. IEEE, 2017
2017
-
[26]
M. D. McKay, R. J. Beckman, and W. J. Conover. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code.Technometrics, 21(2): 239–245, 1979
1979
-
[27]
SIAM, 1992
Harald Niederreiter.Random Number Generation and Quasi-Monte Carlo Methods, volume 63 of CBMS-NSF Regional Conference Series in Applied Mathematics. SIAM, 1992. 25
1992
-
[28]
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InICML, pages 794–803, 2018
2018
-
[29]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations, 2015
2015
-
[30]
Numerical optimization.Springer Science, 35(67-68):7, 1999
Stephen Wright, Jorge Nocedal, et al. Numerical optimization.Springer Science, 35(67-68):7, 1999
1999
-
[31]
Quasi-newton methods: A new direction.The Journal of Machine Learning Research, 14(1):843–865, 2013
Philipp Hennig and Martin Kiefel. Quasi-newton methods: A new direction.The Journal of Machine Learning Research, 14(1):843–865, 2013
2013
-
[32]
John Taylor, Wenyi Wang, Biswajit Bala, and Tomasz Bednarz. Optimizing the optimizer for data driven deep neural networks and physics informed neural networks.arXiv preprint arXiv:2205.07430, 2022
arXiv 2022
-
[33]
Review of adaptive activation function in deep neural network
Mian Mian Lau and King Hann Lim. Review of adaptive activation function in deep neural network. In2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES),pages686–690. IEEE, 2018
2018
-
[34]
Leonid Datta. A survey on activation functions and their relation with xavier and he normal initial- ization.arXiv preprint arXiv:2004.06632, 2020. 26
arXiv 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.