Timesteps of Mamba Align with Human Reading Times
Pith reviewed 2026-06-30 06:46 UTC · model grok-4.3
The pith
Mamba's input-dependent discretization timesteps predict human reading times even after controlling for GPT-2 surprisal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
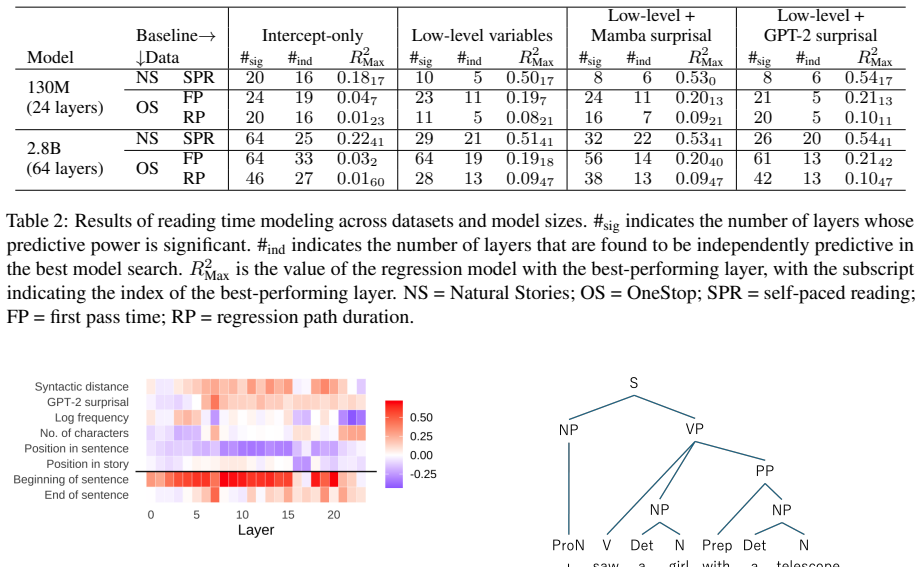
The per-word timestep from Mamba is a significant predictor of human reading times, and remains significant even when known predictors such as GPT-2 surprisal are controlled for. We further suggest, through formal analysis of Mamba's architecture and internal dynamics, that Mamba can serve as a new, valuable lens to look at human real-time language processing with ever-updated memory, because it allows us to look at how each module (layer) weighs short- and long-term information retention, and how noise may interact with dynamic, continuous memory representation.
What carries the argument
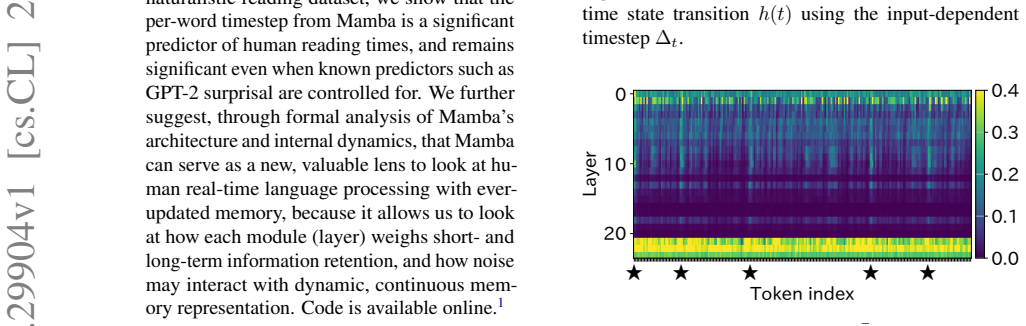
The discretization timestep Δ_t in Mamba, dynamically computed from the input to set the duration of each recurrent state transition at every layer.
If this is right
- Mamba timesteps supply an additional predictor of human reading behavior that operates beyond standard surprisal measures.
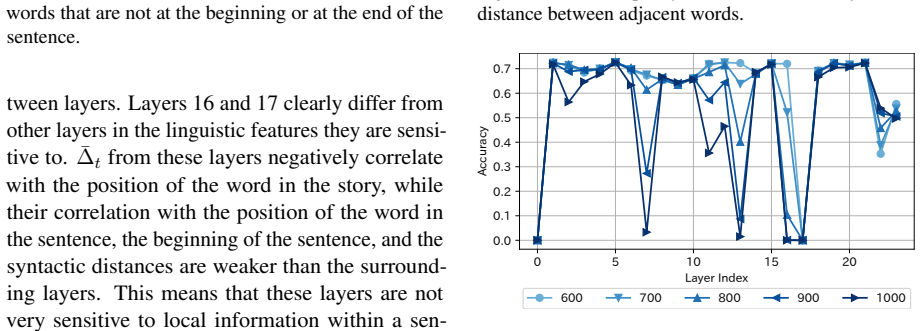
- Layer-wise analysis of Δ_t values can reveal differential weighting of short-term versus long-term information retention during processing.
- Mamba's continuous memory representation offers a route to examine how noise affects dynamic state updates in language comprehension.
- The architecture provides a concrete mechanism for modeling ever-updated memory states in real-time human language processing.
Where Pith is reading between the lines
- If the alignment holds, similar timestep-to-reading-time correlations could be tested in other input-dependent recurrent or state-space architectures.
- This opens the possibility that input-responsive discretization itself contributes to modeling human-like processing efficiency across different tasks.
- Controlled experiments could manipulate the computation of Δ_t to check whether changes in its dynamics alter alignment with eye-tracking measures.
Load-bearing premise
The model's discretization timestep Δ_t can be interpreted as a duration of processing time that is directly comparable to human per-word reading times measured in eye-tracking data.
What would settle it
A regression showing that Mamba timesteps lose all predictive power for reading times once additional controls such as word length, frequency, and syntactic complexity are added alongside surprisal.
Figures


read the original abstract
This study demonstrates an alignment of per-word processing time in a popular state-space language model Mamba and human readers. In Mamba, the recurrent state transition at each layer conceptually takes some duration of time, the discretization timestep $\Delta_t$, determined dynamically in response to the input. Using a naturalistic reading dataset, we show that the per-word timestep from Mamba is a significant predictor of human reading times, and remains significant even when known predictors such as GPT-2 surprisal are controlled for. We further suggest, through formal analysis of Mamba's architecture and internal dynamics, that Mamba can serve as a new, valuable lens to look at human real-time language processing with ever-updated memory, because it allows us to look at how each module (layer) weighs short- and long-term information retention, and how noise may interact with dynamic, continuous memory representation. Code is available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the input-dependent discretization timestep Δ_t in the Mamba state-space model is a significant predictor of human per-word reading times in naturalistic eye-tracking data, remains significant after controlling for GPT-2 surprisal, and that formal analysis of Mamba's architecture supports its use as a model for human real-time language processing with dynamic, continuous memory updating across layers.
Significance. If the reported correlation holds under full statistical reporting and the architectural interpretation is substantiated, the work would provide a concrete, architecture-specific bridge between SSMs and cognitive reading measures, with potential to examine layer-wise short- versus long-term retention and noise effects. Code availability supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central regression result is stated without coefficients, sample size, exact statistical test, exclusion criteria, or effect-size information, so the claim that Δ_t 'remains significant' after controlling for GPT-2 surprisal cannot be evaluated.
- [Abstract] Abstract (formal analysis paragraph): the claim that Δ_t functions as a 'duration of processing time' comparable to eye-tracked reading times is load-bearing for the mechanistic interpretation, yet Δ_t is defined only as an input-dependent learned rate (softplus of a linear projection) with no units or objective tying it to milliseconds; the paper does not demonstrate that residual variance after surprisal control is not simply other token-level features.
minor comments (2)
- [Abstract] The naturalistic reading dataset is referenced but neither named nor described (e.g., corpus, number of participants, preprocessing).
- [Abstract] Notation for Δ_t should be introduced with its exact functional form (softplus(linear(embedding))) at first use rather than only conceptually.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract requires more precise statistical reporting and will revise it to include coefficients, sample size, test details, exclusions, and effect sizes. We also address the interpretation of Δ_t below, providing clarification on its conceptual role while acknowledging its learned-parameter definition. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central regression result is stated without coefficients, sample size, exact statistical test, exclusion criteria, or effect-size information, so the claim that Δ_t 'remains significant' after controlling for GPT-2 surprisal cannot be evaluated.
Authors: We agree this information is necessary for evaluating the claim. The full manuscript reports linear mixed-effects models on the naturalistic eye-tracking corpus (with per-word Δ_t from Mamba layers as predictor, controlling for GPT-2 surprisal), but the abstract summarizes only the significance. In revision we will add the key coefficients (with SE), N (words and participants), exact model specification, exclusion criteria (e.g., outliers, fixation thresholds), and standardized effect sizes to the abstract while keeping it concise. revision: yes
-
Referee: [Abstract] Abstract (formal analysis paragraph): the claim that Δ_t functions as a 'duration of processing time' comparable to eye-tracked reading times is load-bearing for the mechanistic interpretation, yet Δ_t is defined only as an input-dependent learned rate (softplus of a linear projection) with no units or objective tying it to milliseconds; the paper does not demonstrate that residual variance after surprisal control is not simply other token-level features.
Authors: We accept that Δ_t lacks millisecond units and is a learned input-dependent rate; the manuscript frames the alignment as conceptual rather than literal equivalence, supported by the architecture's dynamic state transition and layer-wise analysis of short- versus long-term retention. The regression already controls for GPT-2 surprisal (a strong token-level predictor), and Δ_t remains significant, but we agree additional token features (length, frequency) should be tested to rule out residual confounds. We will add these controls to the regression in revision or explicitly discuss the limitation if dataset constraints apply. revision: partial
Circularity Check
No significant circularity; empirical correlation with external control
full rationale
The paper's central claim is an empirical statistical result: Mamba's per-word discretization timestep Δ_t (computed from a pretrained model) significantly predicts human reading times in eye-tracking data, and remains significant after controlling for GPT-2 surprisal. This is a post-hoc correlation between model internals and an independent external dataset; it does not reduce by the paper's equations to a quantity defined in terms of itself, nor is any 'prediction' obtained by fitting parameters to the target reading-time data. No self-citation chain, uniqueness theorem, or ansatz is invoked to force the result. The formal analysis of Mamba's architecture is presented as interpretive context rather than a derivation that tautologically produces the observed correlation. The finding is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The discretization timestep Δ_t represents a duration of processing time comparable to human reading times
Reference graph
Works this paper leans on
-
[1]
FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism , author =
-
[6]
1990 , publisher =
Prefix sums and their applications , author =. 1990 , publisher =
1990
-
[7]
The Hidden Attention of Mamba Models , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2025.acl-long.76 , pages =
-
[9]
First Conference on Language Modeling , year =
Locating and Editing Factual Associations in Mamba , author =. First Conference on Language Modeling , year =
-
[10]
Random-Access Infinite Context Length for Transformers , url =
Mohtashami, Amirkeivan and Jaggi, Martin , booktitle =. Random-Access Infinite Context Length for Transformers , url =
-
[11]
2020 , howpublished =
nostalgebraist , title =. 2020 , howpublished =
2020
-
[14]
First Conference on Language Modeling , year =
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author =. First Conference on Language Modeling , year =
-
[15]
GLU Variants Improve Transformer
Glu variants improve transformer , author =. arXiv preprint arXiv:2002.05202 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[16]
arXiv preprint arXiv:2502.01615 , year =
Large language models are human-like internally , author =. arXiv preprint arXiv:2502.01615 , year =
-
[17]
Tily and Idan Blank and Anastasia Vishnevetsky and Steven T
Richard Futrell and Edward Gibson and Harry J. Tily and Idan Blank and Anastasia Vishnevetsky and Steven T. Piantadosi and Evelina Fedorenko , year =. The Natural Stories corpus: A reading-time corpus of English texts containing rare syntactic constructions , journal =
-
[18]
2018 , url =
Practical Guide to State-space Control: Graduate-level control theory for high schoolers , author =. 2018 , url =
2018
-
[19]
and Santorini, Beatrice and Marcinkiewicz, Mary Ann , editor =
Marcus, Mitchell P. and Santorini, Beatrice and Marcinkiewicz, Mary Ann , editor =. Building a Large Annotated Corpus of. Computational Linguistics , volume =. 1993 , address =
1993
-
[20]
Tjong Kim Sang, Erik F. and D. Introduction to the. Proceedings of the. 2001 , url =
2001
-
[21]
言語処理学会 第28回年次大会 発表論文集 , year =
ニューラル言語モデルの過剰な作業記憶 , author =. 言語処理学会 第28回年次大会 発表論文集 , year =
-
[22]
A Probabilistic
Hale, John , booktitle =. A Probabilistic. 2001 , url =
2001
-
[23]
Expectation-based syntactic comprehension , volume =
Levy, Roger , doi =. Expectation-based syntactic comprehension , volume =. Cognition , number =
-
[29]
Modeling working memory: an interference model of complex span
Oberauer, Klaus and Lewandowsky, Stephan and Farrell, Simon and Jarrold, Christopher and Greaves, Martin , doi =. Modeling working memory: an interference model of complex span. , volume =. Psychonomic bulletin & review , number =
-
[30]
Carpenter and Jacqueline D
Marcel Adam Just and Patricia A. Carpenter and Jacqueline D. Woolley , journal =. Paradigms and processes in reading comprehension , volume =. 1982 , doi =
1982
-
[31]
Retrieval interference in sentence comprehension , volume =
Julie A. Retrieval interference in sentence comprehension , volume =. Journal of Memory and Language , keywords =. doi:10.1016/j.jml.2006.03.007 , issn =
-
[32]
Nicenboim, Bruno and Loga. When High-Capacity Readers Slow Down and Low-Capacity Readers Speed Up: Working Memory and Locality Effects , volume =. doi:10.3389/fpsyg.2016.00280 , journal =
-
[33]
Vision , year =
David Marr , publisher =. Vision , year =
-
[34]
Data from eye-tracking corpora as evidence for theories of syntactic processing complexity , volume = 109, year =
Vera Demberg and Frank Keller , journal =. Data from eye-tracking corpora as evidence for theories of syntactic processing complexity , volume = 109, year =
-
[35]
bioRxiv , doi =
Laura Gwilliams and Alec Marantz and David Poeppel and Jean-Remi King , year = 2024, title =. bioRxiv , doi =
2024
-
[36]
Nature communications , volume=
Neural dynamics of phoneme sequences reveal position-invariant code for content and order , author=. Nature communications , volume=. 2022 , doi =
2022
-
[37]
Information-theoretical Complexity Metrics , volume =
John Hale , journal =. Information-theoretical Complexity Metrics , volume =. 2016 , doi =
2016
-
[38]
Lossy-Context Surprisal: An Information-Theoretic Model of Memory Effects in Sentence Processing , volume =
Futrell, Richard and Gibson, Edward and Levy, Roger , doi =. Lossy-Context Surprisal: An Information-Theoretic Model of Memory Effects in Sentence Processing , volume =. Cognitive Science , keywords =
-
[39]
PNAS , volume = 119, number = 43, doi =
A resource-rational model of human processing of recursive linguistic structure , author =. PNAS , volume = 119, number = 43, doi =
-
[40]
Scientific Data , volume = 12, number = 1995, doi =
Yevgeni Berzak and Jonathan Malmaud and Omer Shubi and Yoav Meiri and Ella Lion and Roger Levy , year = 2025, title =. Scientific Data , volume = 12, number = 1995, doi =
2025
-
[42]
Yevgeni Berzak, Jonathan Malmaud, Omer Shubi, Yoav Meiri, Ella Lion, and Roger Levy. 2025. https://doi.org/10.1038/s41597-025-06272-2 Onestop: A 360-participant E nglish eye tracking dataset with different reading regimes . Scientific Data, 12(1995)
-
[43]
Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, and 1 others. 2025. Nvidia nemotron 3: Efficient and open intelligence. arXiv preprint arXiv:2512.20856
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Guy E Blelloch. 1990. Prefix sums and their applications
1990
-
[45]
Vera Demberg and Frank Keller. 2008. https://doi.org/10.1016/j.cognition.2008.07.008 Data from eye-tracking corpora as evidence for theories of syntactic processing complexity . Cognition, 109:192--210
-
[46]
Nir Endy, Idan Daniel Grosbard, Yuval Ran-Milo, Yonatan Slutzky, Itay Tshuva, and Raja Giryes. 2025. https://doi.org/10.18653/v1/2025.acl-long.1143 Mamba knockout for unraveling factual information flow . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23457--23477, Vienna, Austria....
-
[47]
Richard Futrell, Edward Gibson, and Roger Levy. 2020. https://doi.org/10.1111/cogs.12814 Lossy-context surprisal: An information-theoretic model of memory effects in sentence processing . Cognitive Science, 44(3):e12814
-
[48]
Tily, Idan Blank, Anastasia Vishnevetsky, Steven T
Richard Futrell, Edward Gibson, Harry J. Tily, Idan Blank, Anastasia Vishnevetsky, Steven T. Piantadosi, and Evelina Fedorenko. 2021. The natural stories corpus: A reading-time corpus of english texts containing rare syntactic constructions. Language Resources and Evaluation, 55(1):63--77
2021
-
[49]
Albert Gu and Tri Dao. 2024. https://openreview.net/forum?id=tEYskw1VY2 Mamba: Linear-time sequence modeling with selective state spaces . In First Conference on Language Modeling
2024
-
[50]
Laura Gwilliams, Jean-Remi King, Alec Marantz, and David Poeppel. 2022. https://doi.org/10.1038/s41467-022-34326-1 Neural dynamics of phoneme sequences reveal position-invariant code for content and order . Nature communications, 13(1):6606
-
[51]
Laura Gwilliams, Alec Marantz, David Poeppel, and Jean-Remi King. 2024. https://doi.org/10.1101/2024.04.19.590280 Hierarchical dynamic coding coordinates speech comprehension in the human brain . bioRxiv
-
[52]
Michael Hahn, Richard Futrell, Roger Levy, and Edward Gibson. 2022. https://doi.org/10.1073/pnas.2122602119 A resource-rational model of human processing of recursive linguistic structure . PNAS, 119(43)
-
[53]
John Hale. 2001. https://aclanthology.org/N01-1021/ A probabilistic E arley parser as a psycholinguistic model . In Second Meeting of the North A merican Chapter of the Association for Computational Linguistics
2001
-
[54]
John Hale. 2016. https://doi.org/10.1111/lnc3.12196 Information-theoretical complexity metrics . Language and Linguistics Compass, 10:397--412
-
[55]
Marcel Adam Just, Patricia A. Carpenter, and Jacqueline D. Woolley. 1982. https://doi.org/10.1037/0096-3445.111.2.228 Paradigms and processes in reading comprehension . Journal of Experimental Psychology: General, 111(2):228--238
-
[56]
Kimi Team , Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, and 1 others. 2025. Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Tatsuki Kuribayashi, Yohei Oseki, Ana Brassard, and Kentaro Inui. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.712 Context limitations make neural language models more human-like . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10421--10436, Abu Dhabi, United Arab Emirates. Association for Computation...
-
[58]
Tatsuki Kuribayashi, Yohei Oseki, Takumi Ito, Ryo Yoshida, Masayuki Asahara, and Kentaro Inui. 2021. https://doi.org/10.18653/v1/2021.acl-long.405 Lower perplexity is not always human-like . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing ...
-
[59]
Tatsuki Kuribayashi, Yohei Oseki, Souhaib Ben Taieb, Kentaro Inui, and Timothy Baldwin. 2025. https://doi.org/10.1162/TACL.a.58 Large language models are human-like internally . Transactions of the Association for Computational Linguistics, 13:1743--1766
-
[60]
Roger Levy. 2008. https://doi.org/10.1016/j.cognition.2007.05.006 Expectation-based syntactic comprehension . Cognition, 106(3):1126--1177
-
[61]
Wei Liu and Nai Ding. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.351 Information integration in large language models is gated by linguistic structural markers . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6903--6915, Suzhou, China. Association for Computational Linguistics
-
[62]
David Marr. 1982. Vision. WH Freeman, San Fransisco, CA
1982
-
[63]
Amirkeivan Mohtashami and Martin Jaggi. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/ab05dc8bf36a9f66edbff6992ec86f56-Paper-Conference.pdf Random-access infinite context length for transformers . In Advances in Neural Information Processing Systems, volume 36, pages 54567--54585. Curran Associates, Inc
2023
-
[64]
Byung-Doh Oh and William Schuler. 2023. https://doi.org/10.1162/tacl_a_00548 Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? Transactions of the Association for Computational Linguistics, 11:336--350
- [65]
-
[66]
Soo Hyun Ryu and Richard Lewis. 2021. https://doi.org/10.18653/v1/2021.cmcl-1.6 Accounting for agreement phenomena in sentence comprehension with transformer language models: Effects of similarity-based interference on surprisal and attention . In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, pages 61--71, Online. Associ...
-
[67]
Arnab Sen Sharma, David Atkinson, and David Bau. 2024. https://openreview.net/forum?id=yoVRyrEgix Locating and editing factual associations in mamba . In First Conference on Language Modeling
2024
-
[68]
Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P
Ethan G. Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P. Levy. 2023. https://doi.org/10.1162/tacl_a_00612 Testing the predictions of surprisal theory in 11 languages . Transactions of the Association for Computational Linguistics, 11:1451--1470
-
[69]
Songlin Yang and Yu Zhang. 2024. https://github.com/fla-org/flash-linear-attention Fla: A triton-based library for hardware-efficient implementations of linear attention mechanism
2024
-
[70]
Ryo Yoshida, Shinnosuke Isono, Kohei Kajikawa, Taiga Someya, Yushi Sugimoto, and Yohei Oseki. 2025. https://doi.org/10.18653/v1/2025.acl-long.483 If attention serves as a cognitive model of human memory retrieval, what is the plausible memory representation? In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume...
- [71]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.