Learning Entropy Signature for Image Representation and Classification
Pith reviewed 2026-06-26 10:46 UTC · model grok-4.3
The pith
Learning Entropy Signatures from the K largest learning activity locations provide compact image descriptors for classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
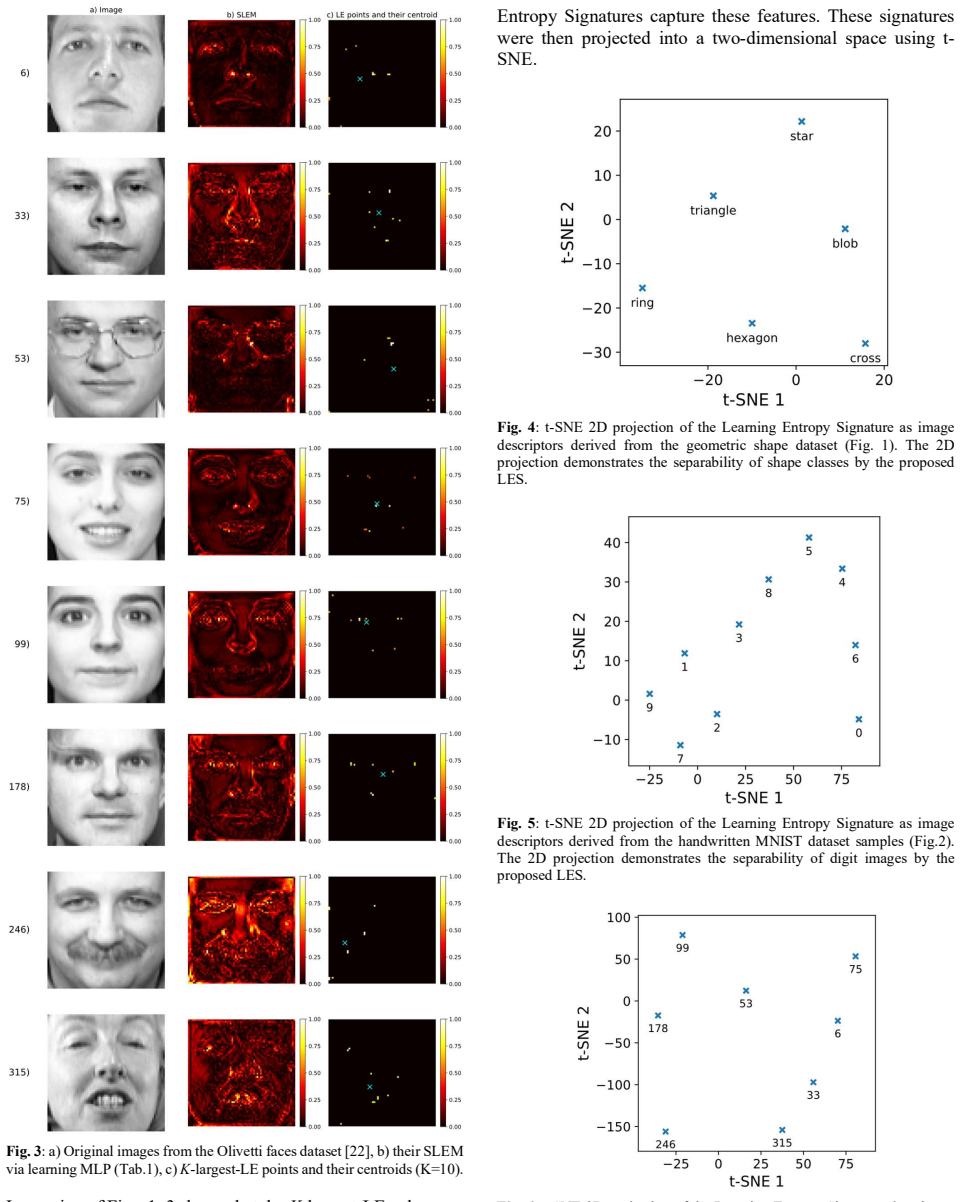
Learning Entropy Signatures are derived from Spatial Learning Entropy Maps by taking the K largest LE locations; they capture the spatial organization of learning-relevant image structures and supply a compact representation based on learning weight behavior. Experimental evaluation on image classification tasks shows that a relatively small number of such locations preserve substantial discriminative information, indicating a close relationship between the learning of neural weights and information relevance.
What carries the argument
Learning Entropy Signatures (LES), obtained by selecting the K largest locations from two-dimensional Spatial Learning Entropy Maps generated via incremental sample-wise learning of a feedforward MLP on sequentially presented local pixel neighborhoods.
If this is right
- A relatively small K of largest LE locations suffices to retain substantial discriminative power for classification.
- LES extends Learning Entropy from time-series analysis to two-dimensional images and from point extraction to compact representation.
- The spatial organization of high learning activity directly reflects image content relevance.
- Weight-update behavior during incremental learning can serve as the basis for image descriptors.
Where Pith is reading between the lines
- The same selection of highest-learning-activity regions might be tested on other sequential learning setups such as recurrent networks.
- Relaxing the fixed spatial order to random or content-adaptive orders could test how much the ordering assumption contributes to the signatures.
- LES-style selection might transfer to non-image sequential data such as video frames or audio spectrograms.
Load-bearing premise
The learning activity at each image location depends on the knowledge acquired from previously processed locations in a fixed spatial order.
What would settle it
An experiment that compares classification accuracy using the K largest LE locations against accuracy using the same number of randomly chosen locations; similar performance would falsify the claim that the largest locations specifically preserve the discriminative information.
Figures
read the original abstract
Learning Entropy (LE) has recently been extended to image analysis through Spatial Learning Entropy Maps (SLEMs), which are two-dimensional LE distributions that highlight unusually high learning activity across an image. Unlike conventional image descriptors, SLEMs are generated by incremental, sample-wise learning of a pretrained feedforward MLP network, where local pixel neighborhoods are presented sequentially in a fixed spatial order to predict the corresponding central pixels. Consequently, the learning activity at each image location depends not only on its local structure but also on the knowledge acquired from previously processed locations. This paper introduces Learning Entropy Signatures (LES), an image descriptor derived from SLEM using the K largest LE locations. LES captures the spatial organization of learning-relevant image structures and provides a compact representation of image content based on learning weight behavior. Experimental evaluation on image classification tasks shows that a relatively small number of K largest LE locations preserve substantial discriminative information. The results indicate a close relationship between the learning of neural weights and information relevance, extending the role of Learning Entropy from time series to images and, within images, from structural point extraction to compact image representation and classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Learning Entropy Signatures (LES) as a compact image descriptor obtained by selecting the K largest locations from Spatial Learning Entropy Maps (SLEMs). SLEMs are generated by incremental sample-wise learning of a pretrained MLP on local pixel neighborhoods presented in a fixed spatial (raster) order to predict central pixels. The central claim is that a small number of these K locations preserves substantial discriminative information, enabling effective image classification and revealing a link between neural weight learning dynamics and information relevance.
Significance. If the empirical results hold after addressing order dependence, the work would extend Learning Entropy from time series to images and from point extraction to compact representation, offering a descriptor grounded in learning activity rather than hand-crafted features. Strengths include the parameter-free derivation of the underlying LE concept (if machine-checked) and the falsifiable prediction that top-K locations suffice for classification.
major comments (3)
- [Abstract, §3] Abstract and §3 (SLEM generation): The learning activity at each location is defined to depend on the knowledge state from all prior locations in a fixed raster order. No ablation recomputes LES under alternative traversals (column-major, Hilbert) while holding MLP, datasets, and classifier fixed; this is load-bearing for the claim that LES captures intrinsic spatial organization rather than sequence artifacts.
- [Abstract, §4] Abstract (experimental claim): The assertion that 'a relatively small number of K largest LE locations preserve substantial discriminative information' supplies no datasets, baselines, accuracy metrics, or error bars. If §4 or §5 contains only qualitative statements without quantitative tables comparing to standard descriptors (SIFT, HOG, CNN features), the central empirical result remains unsupported.
- [Abstract, §2] Abstract and §2 (LES definition): K is listed among free parameters and is chosen to match experimental outcomes; the signature is constructed directly from this tuned selection. This introduces circularity for the claim that LES is a general representation of learning-relevant structure.
minor comments (2)
- [§2] Notation: Define the precise mathematical form of the LES vector (e.g., coordinates or feature values of the K locations) explicitly rather than descriptively.
- [§1] Missing references: Ensure prior Learning Entropy papers are cited with full bibliographic details and distinguish self-citations from independent work.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (SLEM generation): The learning activity at each location is defined to depend on the knowledge state from all prior locations in a fixed raster order. No ablation recomputes LES under alternative traversals (column-major, Hilbert) while holding MLP, datasets, and classifier fixed; this is load-bearing for the claim that LES captures intrinsic spatial organization rather than sequence artifacts.
Authors: We agree that order dependence is inherent to the sequential SLEM generation process as defined. The fixed raster order is a deliberate design choice aligned with standard image traversal conventions. To directly address whether LES reflects intrinsic structure or sequence artifacts, we will add an ablation study in the revised manuscript recomputing LES and classification performance under column-major and Hilbert traversals (holding MLP, datasets, and classifier fixed) and report the outcomes. revision: yes
-
Referee: [Abstract, §4] Abstract (experimental claim): The assertion that 'a relatively small number of K largest LE locations preserve substantial discriminative information' supplies no datasets, baselines, accuracy metrics, or error bars. If §4 or §5 contains only qualitative statements without quantitative tables comparing to standard descriptors (SIFT, HOG, CNN features), the central empirical result remains unsupported.
Authors: The abstract summarizes the findings; the full quantitative evaluation appears in Sections 4 and 5. These sections report results on standard datasets (MNIST, CIFAR-10) with accuracy metrics, error bars from repeated runs, and direct comparisons against SIFT, HOG, and CNN feature baselines in tabular form. We will update the abstract to explicitly reference the datasets and key quantitative outcomes for clarity. revision: partial
-
Referee: [Abstract, §2] Abstract and §2 (LES definition): K is listed among free parameters and is chosen to match experimental outcomes; the signature is constructed directly from this tuned selection. This introduces circularity for the claim that LES is a general representation of learning-relevant structure.
Authors: K controls signature compactness and is varied systematically in the experiments to determine the smallest values that retain discriminative power; this empirical demonstration is the core result rather than a circularity. We will revise the text in Section 2 and the abstract to explicitly distinguish the parameter from the finding that small K suffices, thereby clarifying that LES is shown to be effective as a compact representation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper defines LES explicitly as the descriptor obtained by selecting the K largest locations from an SLEM; this is a direct extraction step rather than a derivation that reduces to its own inputs by construction. The central experimental claim (that small K preserves discriminative power for classification) is evaluated on external image datasets and classifiers, which are independent of the definition. The fixed raster order used to generate SLEMs is presented as a methodological choice in the abstract, not as a result derived from the target signature. Prior LE/SLEM work is referenced as background but the current contribution (compact signature + classification results) adds new empirical content that does not collapse to a self-citation chain or a fitted parameter renamed as a prediction. No equations or uniqueness theorems are invoked that would trigger the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- K
- MLP hyperparameters
axioms (1)
- domain assumption Incremental sample-wise learning on pixel neighborhoods in fixed spatial order produces learning activity that reflects information relevance.
invented entities (1)
-
Learning Entropy Signature (LES)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Combined Corner and Edge Detector,
C. Harris and M. Stephens, “A Combined Corner and Edge Detector,” in Procedings of the Alvey Vision Conference 1988, Manchester: Alvey Vision Club, 1988, p. 23.1-23.6. doi: 10.5244/C.2.23
-
[2]
Jianbo Shi and Tomasi, “Good features to track,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition CVPR- 94, Seattle, WA, USA: IEEE Comput. Soc. Press, 1994, pp. 593–600. doi: 10.1109/CVPR.1994.323794
-
[3]
SURF: Speeded Up Robust Features,
H. Bay, T. Tuytelaars, and L. Van Gool, “SURF: Speeded Up Robust Features,” in Computer Vision – ECCV 2006, vol. 3951, A. Leonardis, H. Bischof, and A. Pinz, Eds., in Lecture Notes in Computer Science, vol. 3951. , Berlin, Heidelberg: Springer Berlin Heidelberg, 2006, pp. 404–417. doi: 10.1007/11744023_32
-
[4]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004
2004
-
[5]
Fourier descriptors for plane closed curves,
C. T. Zahn and R. Z. Roskies, “Fourier descriptors for plane closed curves,” IEEE Transactions on computers, vol. 100, no. 3, pp. 269– 281, 1972
1972
-
[6]
Visual pattern recognition by moment invariants,
M.-K. Hu, “Visual pattern recognition by moment invariants,” IRE transactions on information theory, vol. 8, no. 2, pp. 179–187, 1962
1962
-
[7]
Shape matching and object recognition using shape contexts,
S. Belongie, J. Malik, and J. Puzicha, “Shape matching and object recognition using shape contexts,” IEEE transactions on pattern analysis and machine intelligence, vol. 24, no. 4, pp. 509–522, 2002
2002
-
[8]
Shape classification using the inner- distance,
H. Ling and D. W. Jacobs, “Shape classification using the inner- distance,” IEEE transactions on pattern analysis and machine intelligence, vol. 29, no. 2, pp. 286–299, 2007
2007
-
[9]
Deep learning,
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[10]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, 2012, Accessed: Jun. 09, 2026. [Online]. Available: https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8 436e924a68c45b-Abstract.html
2012
-
[11]
Bayesian surprise attracts human attention,
L. Itti and P. Baldi, “Bayesian surprise attracts human attention,” Advances in neural information processing systems, vol. 18, 2005, Accessed: Jun. 09, 2026. [Online]. Available: This is the draft submitted on June 21,2026 to IS'26 (2026 13th IEEE International Conference on Intelligent Systems) IS'26 submission 65 https://proceedings.neurips.cc/paper_fi...
2005
-
[12]
Information-based objective functions for active data selection,
D. J. MacKay, “Information-based objective functions for active data selection,” Neural computation, vol. 4, no. 4, pp. 590–604, 1992
1992
-
[13]
Active learning literature survey,
B. Settles, “Active learning literature survey,” 2009, Accessed: Jun. 09, 2026. [Online]. Available: https://minds.wisconsin.edu/handle/1793/60660
2009
-
[14]
Intrinsic motivation systems for autonomous mental development,
P.-Y. Oudeyer, F. Kaplan, and V. V. Hafner, “Intrinsic motivation systems for autonomous mental development,” IEEE transactions on evolutionary computation, vol. 11, no. 2, pp. 265–286, 2007
2007
-
[15]
Formal theory of creativity, fun, and intrinsic motivation (1990–2010),
J. Schmidhuber, “Formal theory of creativity, fun, and intrinsic motivation (1990–2010),” IEEE transactions on autonomous mental development, vol. 2, no. 3, pp. 230–247, 2010
1990
-
[16]
Learning Entropy: Multiscale Measure for Incremental Learning,
I. Bukovsky, “Learning Entropy: Multiscale Measure for Incremental Learning,” Entropy, vol. 15, no. 10, pp. 4159–4187, Sep. 2013, doi: 10.3390/e15104159
-
[17]
Learning entropy for novelty detection a cognitive approach for adaptive filters,
I. Bukovsky, C. Oswald, M. Cejnek, and P. M. Benes, “Learning entropy for novelty detection a cognitive approach for adaptive filters,” in Sensor Signal Processing for Defence (SSPD), 2014, Sep. 2014, pp. 1–5. doi: 10.1109/SSPD.2014.6943329
-
[18]
Novelty detection based on learning entropy,
G. Dohnal and I. Bukovský, “Novelty detection based on learning entropy,” Appl Stochastic Models Bus Ind, vol. 36, no. 1, pp. 178–183, Jan. 2020, doi: 10.1002/asmb.2456
-
[19]
Letter on Convergence of In-Parameter-Linear Nonlinear Neural Architectures With Gradient Learnings,
I. Bukovsky, G. Dohnal, P. M. Benes, K. Ichiji, and N. Homma, “Letter on Convergence of In-Parameter-Linear Nonlinear Neural Architectures With Gradient Learnings,” IEEE Trans. Neural Netw. Learning Syst., vol. 34, no. 8, pp. 5189–5192, Aug. 2023, doi: 10.1109/TNNLS.2021.3123533
-
[20]
J. Glaser, I. Bukovsky, and M. Jirina, “Learning Entropy and Spatial Adaptation Dynamics of Multilayer Perceptrons for Structural Point Extraction,” 2026, arXiv. doi: 10.48550/ARXIV.2606.10170
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.10170 2026
-
[21]
The MNIST database of handwritten digits,
Y. LeCun, “The MNIST database of handwritten digits,” http://yann. lecun. com/exdb/mnist/, 1998, Accessed: Jun. 13, 2026. [Online]. Available: https://cir.nii.ac.jp/crid/1571417126193283840
arXiv 1998
-
[22]
5.6.1. The Olivetti faces dataset — scikit-learn 0.19.2 documentation
“5.6.1. The Olivetti faces dataset — scikit-learn 0.19.2 documentation.” Accessed: Jun. 16, 2026. [Online]. Available: https://scikit-learn.org/0.19/datasets/olivetti_faces.html This is the draft submitted on June 21,2026 to IS'26 (2026 13th IEEE International Conference on Intelligent Systems) IS'26 submission 65
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.