Accelerating Long-Tail Generation in Synchronous RLHF Training via Adaptive Tensor Parallelism
Pith reviewed 2026-07-01 00:51 UTC · model grok-4.3
The pith
PAT dynamically reconfigures tensor parallelism during RLHF generation to adapt to shrinking batches from long responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
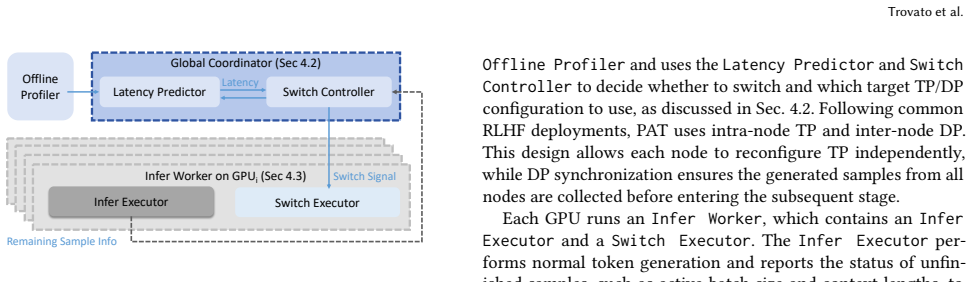
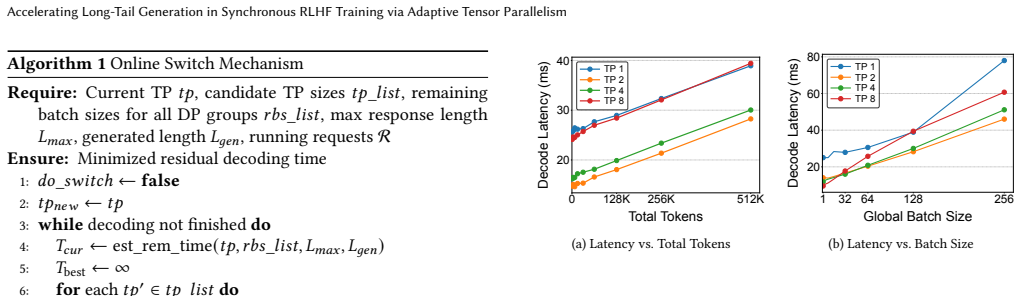
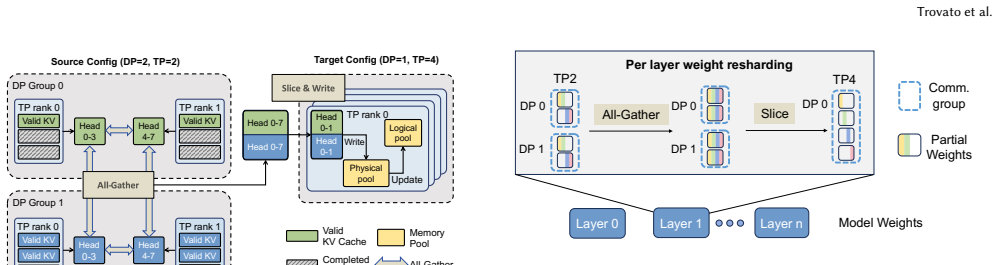
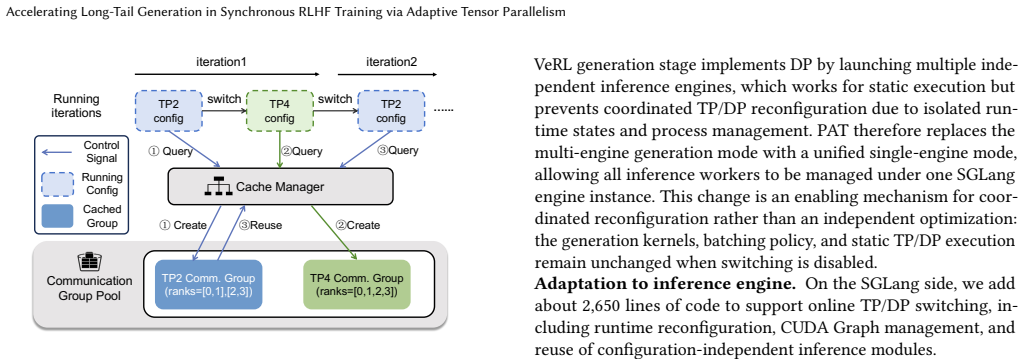
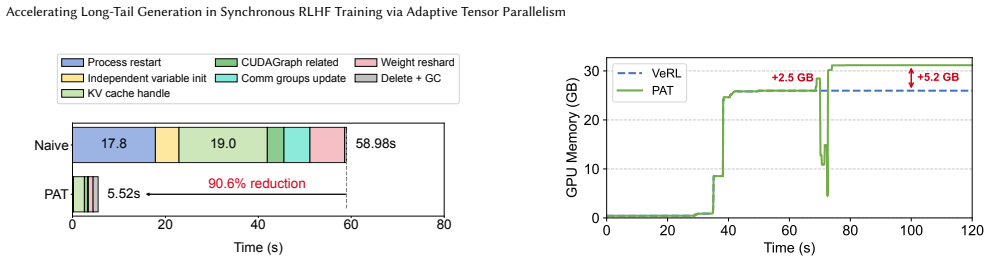
PAT dynamically reconfigures tensor parallelism during the generation stage of each RLHF iteration by selecting both the timing and the new configuration from an offline-profiled predictor, then applying only the affected state changes through cost-model-guided KV-cache migration or recomputation, in-place weight resharding, and reuse of cached groups, thereby addressing the underutilization caused by response-length skew.
What carries the argument
Predictor-guided online reconfiguration that triggers TP degree changes only when offline estimates show net latency benefit, paired with a lightweight mechanism that adapts unfinished decoding states and reshard weights without full restart.
If this is right
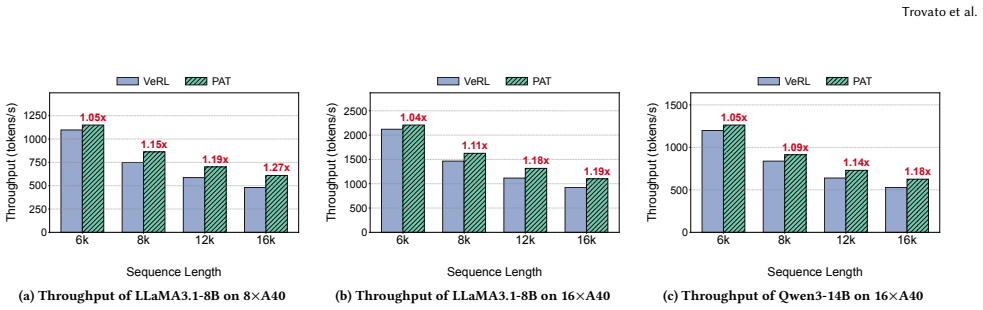
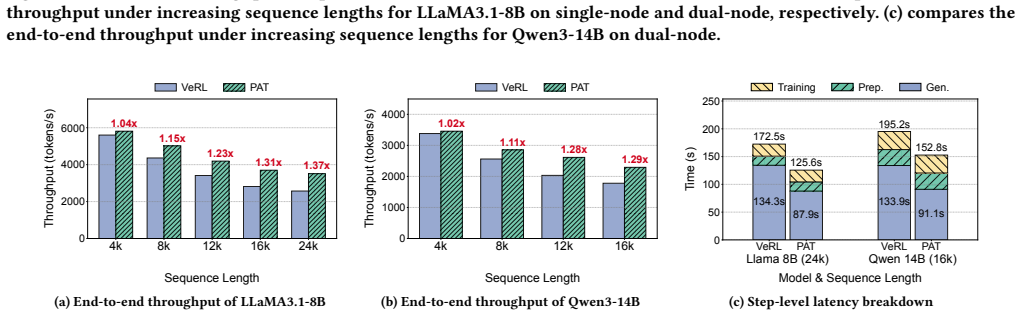
- Generation latency falls by up to 34.6 percent relative to a static TP baseline.
- Full RLHF training iteration latency falls by up to 27.2 percent.
- The same reconfiguration logic applies to both 8B and 14B scale models during decoding.
- Only states changed by the TP degree shift are updated, preserving correctness of unfinished sequences.
Where Pith is reading between the lines
- The same predictor-plus-lightweight-update pattern could be tested on other synchronous pipelines where batch size shrinks mid-step.
- Profiling cost could be amortized across many iterations, making the method attractive for repeated training runs on fixed hardware.
- If KV migration overhead scales with sequence length, the cost model choice between migration and recompute may need retuning for very long outputs.
Load-bearing premise
The offline-profiled predictor will reliably flag live points where latency savings exceed migration or recomputation overhead across different models and datasets.
What would settle it
On a fresh model or dataset, measure end-to-end iteration time with and without PAT and find that reconfiguration overhead consistently cancels or exceeds the predicted generation savings.
Figures


read the original abstract
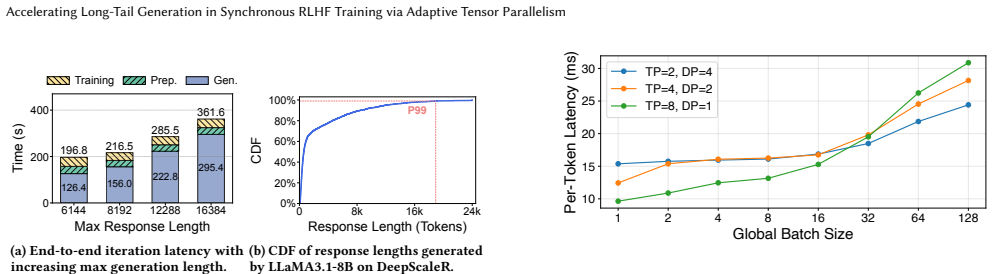
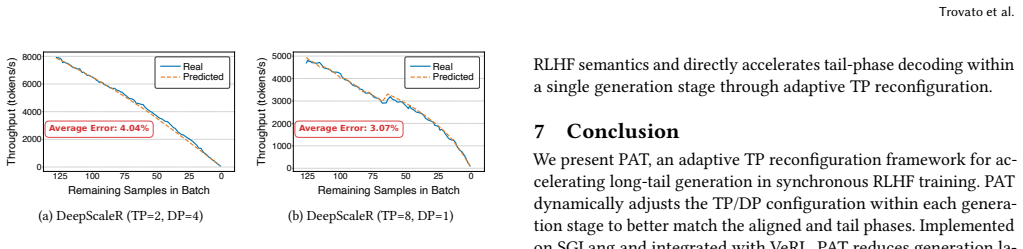
Reinforcement Learning from Human Feedback (RLHF) has become a key post-training paradigm for improving model quality. However, the synchronous three-stage RLHF pipeline is often bottlenecked by the generation stage, where response-length skew causes the effective batch size to shrink rapidly during decoding, leaving GPUs underutilized while a few long responses remain unfinished. Mainstream frameworks employ a static tensor parallelism (TP) configuration that cannot adapt to changing batch characteristics, leaving substantial performance headroom unexplored. We propose PAT, an adaptive TP method that dynamically reconfigures TP during the generation stage of each RLHF iteration. PAT introduces two key techniques. First, a predictor-guided online reconfiguration method decides both the reconfiguration point and the target TP configuration based on offline profiling, triggering reconfiguration only when the predicted latency benefit outweighs the reconfiguration overhead. Second, a lightweight online reconfiguration mechanism updates only the states and layouts affected by TP changes: it adapts unfinished decoding states through a cost-model-based choice between KV-cache migration and recomputation, performs in-place weight resharding, and reuses cached communication groups. We implement PAT on top of SGLang and integrate it with the VeRL framework. Evaluations on LLaMA3.1-8B and Qwen3-14B using DeepScaleR show that PAT reduces generation latency by up to 34.6% and end-to-end RLHF training iteration latency by up to 27.2% compared to the original VeRL setup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PAT, an adaptive tensor parallelism (TP) method for the generation stage in synchronous RLHF training. It dynamically reconfigures TP during decoding to mitigate GPU underutilization from response-length skew. PAT uses a predictor-guided online reconfiguration based on offline profiling (triggering only when predicted latency savings exceed overhead) and a lightweight mechanism for adapting unfinished decoding states via cost-model-based KV-cache migration or recomputation, in-place weight resharding, and reuse of cached communication groups. Implemented on SGLang and integrated with VeRL, evaluations on LLaMA3.1-8B and Qwen3-14B using DeepScaleR report up to 34.6% reduction in generation latency and 27.2% in end-to-end RLHF iteration latency versus the original VeRL setup.
Significance. If the results hold under more rigorous validation, PAT offers a practical engineering advance for RLHF post-training efficiency by addressing the long-tail generation bottleneck through adaptive parallelism. The offline-to-online predictor approach combined with selective state adaptation could apply to other variable-workload distributed LLM training scenarios. Credit is due for the concrete system implementation and integration with SGLang/VeRL, which supports reproducibility, and for reporting specific speedups on two models. However, the absence of error bars, ablations, and predictor accuracy metrics in the evaluations weakens the immediate significance assessment.
major comments (2)
- [Evaluations on LLaMA3.1-8B and Qwen3-14B] Evaluations section: The central empirical claims of up to 34.6% generation latency reduction and 27.2% end-to-end reduction are presented without error bars, statistical significance tests, per-iteration histograms of predictor accuracy, false-positive rates, or net latency deltas on mispredictions. This is load-bearing because the synchronous pipeline requires all ranks to agree on reconfiguration, and RLHF generation variance (response lengths, KV-cache states) can cause distribution shift from the offline profiles.
- [predictor-guided online reconfiguration method] Predictor-guided online reconfiguration method: The assumption that the offline-profiled predictor reliably identifies points where latency savings exceed migration/recomputation overhead is not supported by quantitative evidence on generalization across models/datasets or analysis of costly reconfigurations triggered by errors. This directly underpins the claim that PAT produces net benefits in live synchronous runs.
minor comments (2)
- [Abstract] The abstract references 'DeepScaleR' without definition or citation; a brief description or reference would improve clarity for readers unfamiliar with the benchmark.
- Consider adding a table or figure breaking down the fraction of iterations where reconfiguration was triggered and the average overhead versus savings to make the predictor's decision process more transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below, agreeing where additional evidence or clarification is warranted and outlining targeted revisions.
read point-by-point responses
-
Referee: [Evaluations on LLaMA3.1-8B and Qwen3-14B] Evaluations section: The central empirical claims of up to 34.6% generation latency reduction and 27.2% end-to-end reduction are presented without error bars, statistical significance tests, per-iteration histograms of predictor accuracy, false-positive rates, or net latency deltas on mispredictions. This is load-bearing because the synchronous pipeline requires all ranks to agree on reconfiguration, and RLHF generation variance (response lengths, KV-cache states) can cause distribution shift from the offline profiles.
Authors: We agree that error bars, significance tests, and explicit misprediction analysis would strengthen the presentation. The reported figures come from full RLHF iterations on two models; repeating every configuration multiple times is costly, which is why variance metrics were omitted. In revision we will add error bars from repeated short runs, per-iteration predictor accuracy histograms, and measured net latency impact on the (rare) misprediction cases observed in our logs. revision: yes
-
Referee: [predictor-guided online reconfiguration method] Predictor-guided online reconfiguration method: The assumption that the offline-profiled predictor reliably identifies points where latency savings exceed migration/recomputation overhead is not supported by quantitative evidence on generalization across models/datasets or analysis of costly reconfigurations triggered by errors. This directly underpins the claim that PAT produces net benefits in live synchronous runs.
Authors: The two-model evaluation (LLaMA3.1-8B and Qwen3-14B) already demonstrates cross-model applicability under the same DeepScaleR workload. The predictor triggers only when predicted savings exceed a conservative overhead threshold derived from the cost model; this design itself limits exposure to costly errors. We will add an explicit subsection quantifying predictor accuracy, false-positive rate, and the measured latency penalty of the few mispredictions that occurred. revision: yes
Circularity Check
No circularity; empirical engineering claims only
full rationale
The paper describes an implementation of adaptive tensor parallelism (PAT) using offline profiling for reconfiguration decisions and lightweight state updates for KV-cache and weights. All load-bearing claims are supported by direct runtime measurements on LLaMA3.1-8B and Qwen3-14B with reported latency reductions. No equations, fitted parameters renamed as predictions, self-definitional relations, or load-bearing self-citations appear in the derivation chain. The method is presented as an engineering artifact whose correctness is evaluated externally via benchmarks rather than reduced to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Tam- ing Throughput-Latency tradeoff in LLM inference with Sarathi-Serve. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 117–134
2024
-
[2]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
- [4]
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, et al. 2024. Openrlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al . 2019. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems32 (2019)
2019
-
[8]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. 2020. Pytorch distributed: Experiences on accelerating data parallel training.arXiv preprint arXiv:2006.15704(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, et al. 2025. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog(2025)
2025
-
[10]
Zhiyu Mei, Wei Fu, Kaiwei Li, Guangju Wang, Huanchen Zhang, and Yi Wu. 2024. Realhf: Optimized rlhf training for large language models through parameter reallocation.arXiv e-prints(2024), arXiv–2406
2024
-
[11]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[12]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[13]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems. 1279–1297
2025
-
[16]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical Accelerating Long-Tail Generation in Synchronous RLHF Training via Adaptive Tensor Parallelism report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured language model programs. Advances in neural information processing systems37 (2024), 62557–62583
2024
- [21]
-
[22]
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, et al. 2025. Optimizing RLHF training for large language models with stage fusion. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 489–503
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.