vla.cpp: A Unified Inference Runtime for Vision-Language-Action Models
Pith reviewed 2026-06-27 19:40 UTC · model grok-4.3
The pith
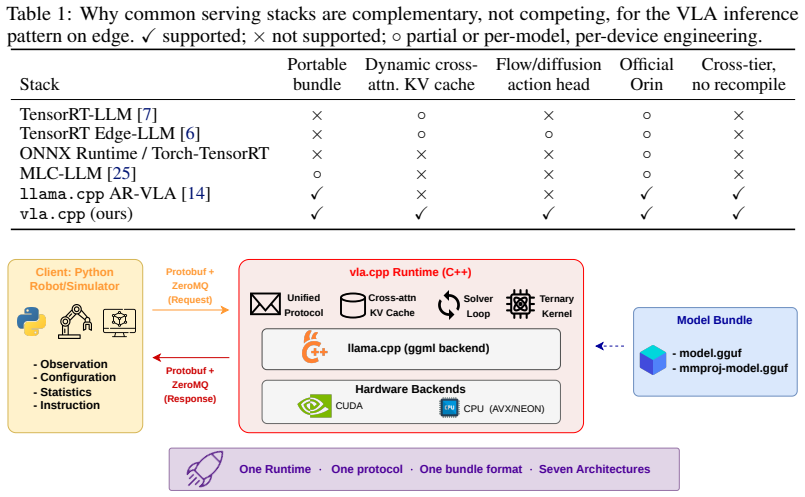
A single portable C++ runtime serves seven vision-language-action architectures under one protocol and runs them unchanged across hardware tiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
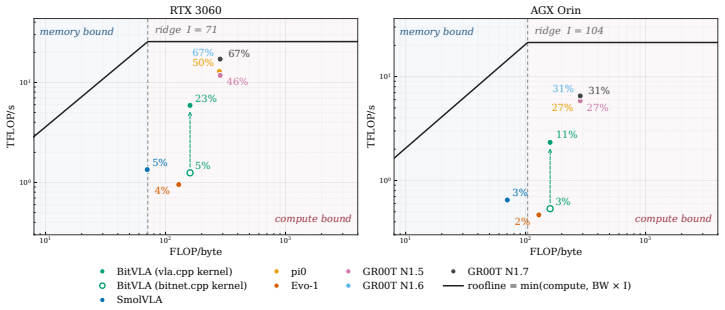
The paper claims that its C++ runtime is the first ggml-class engine to natively support the flow-matching and diffusion VLA inference pattern, in which a cached vision-language prefix is consumed by a cross-attending action expert integrated over several solver steps, allowing one runtime to serve seven architectures from five backbone and four action-head families. On relevant manipulation benchmarks the engine matches a state-of-the-art checkpoint to within one episode out of 200 and achieves 100 percent success for one model in 1.3 GiB of memory. The same bundles run without modification across three hardware tiers, and a roofline analysis shows that batch-1 inference is compute-bound, l
What carries the argument
The self-contained model bundles served behind one request/response protocol, which implements the cached vision-language prefix and cross-attending action expert pattern inside a portable C++ engine.
If this is right
- The runtime matches original checkpoints to within one episode out of 200 on object manipulation tasks.
- A model reaches 100 percent success while using only 1.3 GiB of memory.
- Identical model bundles execute without any changes on hardware ranging from consumer GPUs to 8 GB embedded modules.
- Batch-1 inference is compute-bound, so an IMMA ladder GEMM derived from roofline analysis reduces per-step latency by 4.5 times.
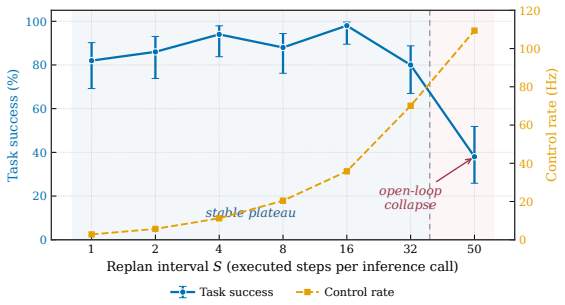
- An on-robot stress test isolates the latency threshold at which a learned policy must replan against a moving target on the hardware it was trained for.
Where Pith is reading between the lines
- The unified protocol could simplify integration of VLA policies with existing robot control stacks that already handle request/response messaging.
- The roofline finding that low-batch inference is compute-bound rather than bandwidth-bound could guide similar analysis for other real-time robot learning workloads.
- The stress-test framework that measures replanning needs against moving targets offers a template for evaluating deployment feasibility under realistic dynamics.
- Extending the same bundle format to additional model families would test whether the single-protocol approach generalizes beyond the seven architectures examined.
Load-bearing premise
The flow-matching and diffusion inference pattern can be implemented faithfully inside a C++ ggml-class engine without accuracy loss or the need for model-specific post-processing.
What would settle it
Running the same model checkpoints through both the original Python stack and the C++ runtime on identical tasks and hardware, then checking whether success rates, memory usage, and output trajectories match within the reported margins.
Figures
read the original abstract
Vision-Language-Action (VLA) policies are typically shipped as Python/PyTorch stacks that assume a workstation-class GPU, a mismatch for the hardware on which robots actually run. We present vla.cpp, a portable C++ inference runtime built on llama.cpp. To our knowledge, it is the first ggml-class engine to natively serve the flow-matching and diffusion VLA inference pattern, in which a cached vision-language prefix is consumed by a cross-attending action expert integrated over several solver steps. A single runtime serves seven architectures spanning five backbone and four action-head families behind one request/response protocol, with each model packaged as a self-contained bundle. On LIBERO-Object, the engine matches a state-of-the-art checkpoint to within one episode out of 200, and runs BitVLA at 100% success in 1.3 GiB of memory. The same bundle runs unchanged across three hardware tiers, from a consumer GPU down to an 8 GB embedded module. A cross-hardware roofline analysis shows that batch-1 VLA inference is compute-bound, so utilization rather than bandwidth is the deployment lever; an IMMA ladder GEMM derived from this analysis cuts BitVLA per-step latency by 4.5x. We then frame an on-robot stress test on an ALOHA arm that isolates the latency constraint under which a learned VLA must replan against a moving target on the hardware it was trained for. Code, demo videos, and the reproducible benchmark scaffold are available at https://fai-modelopt-tech.github.io/vla-cpp.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces vla.cpp, a portable C++ inference runtime built on llama.cpp/ggml for Vision-Language-Action (VLA) policies. It claims to be the first such engine to natively support the flow-matching and diffusion VLA inference pattern (cached vision-language prefix consumed by a cross-attending action expert over solver steps). A single runtime and request/response protocol serves seven architectures spanning five backbones and four action-head families, with each model as a self-contained bundle. On LIBERO-Object the engine matches a SOTA checkpoint to within one episode out of 200; BitVLA reaches 100% success in 1.3 GiB; the same bundles run unchanged across three hardware tiers. Additional contributions include a cross-hardware roofline analysis showing compute-bound batch-1 inference, an IMMA ladder GEMM yielding 4.5x latency reduction on BitVLA, and an on-robot ALOHA stress test isolating replanning latency constraints. Code, demo videos, and a reproducible benchmark scaffold are released.
Significance. If the central claim of faithful reproduction holds, the work would enable practical deployment of complex VLA policies on embedded robotic hardware by replacing workstation-class PyTorch stacks with a unified, portable ggml-class engine. The explicit release of code, reproducible benchmarks, and the on-robot stress-test scaffold are concrete strengths that increase the potential impact for the robotics community.
major comments (2)
- [Abstract] Abstract: the headline claim that the ggml engine faithfully reproduces the iterative flow-matching/diffusion sampling pattern (cached prefix + cross-attending action expert) without accuracy loss or model-specific post-processing is load-bearing for the 'single runtime, one protocol' assertion, yet the manuscript supplies no per-architecture ablation, no solver-step count comparison against the original PyTorch checkpoints, and no quantization-error analysis on the action head.
- [Abstract] Abstract (LIBERO-Object result): matching SOTA 'to within one episode out of 200' is presented as evidence of equivalence, but without reported variance across multiple seeds, exact episode counts, or a direct side-by-side success-rate table versus the PyTorch baseline, it is impossible to assess whether the observed difference is statistically meaningful or merely within noise.
minor comments (2)
- The three hardware tiers are mentioned but never enumerated (e.g., GPU model, embedded SoC, memory sizes); adding a short table would improve clarity.
- The roofline analysis and IMMA GEMM optimization are described at a high level; a brief pseudocode or equation for the ladder GEMM would help readers reproduce the 4.5x claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify areas where stronger supporting evidence is needed to substantiate the central claims of faithful reproduction and statistical equivalence. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the ggml engine faithfully reproduces the iterative flow-matching/diffusion sampling pattern (cached prefix + cross-attending action expert) without accuracy loss or model-specific post-processing is load-bearing for the 'single runtime, one protocol' assertion, yet the manuscript supplies no per-architecture ablation, no solver-step count comparison against the original PyTorch checkpoints, and no quantization-error analysis on the action head.
Authors: We agree that the absence of these details weakens the headline claim. The manuscript demonstrates overall performance parity on LIBERO-Object and releases the full code for verification, but it does not include the requested per-architecture ablations or solver-step comparisons. In the revised version we will add a table listing solver-step counts for each of the seven architectures, a side-by-side comparison of action-head outputs before and after ggml quantization, and an explicit statement that no model-specific post-processing is applied. These additions will be placed in the Experiments section. revision: yes
-
Referee: [Abstract] Abstract (LIBERO-Object result): matching SOTA 'to within one episode out of 200' is presented as evidence of equivalence, but without reported variance across multiple seeds, exact episode counts, or a direct side-by-side success-rate table versus the PyTorch baseline, it is impossible to assess whether the observed difference is statistically meaningful or merely within noise.
Authors: The reported figure comes from a single evaluation run on the published SOTA checkpoint. We acknowledge that variance, exact counts, and a direct baseline table are required for a rigorous claim of equivalence. The revision will include results over three random seeds with standard deviation, the precise episode counts (199/200 for vla.cpp), and a side-by-side success-rate table comparing vla.cpp against the original PyTorch implementation on LIBERO-Object. These data will be added to both the abstract and the main Experiments section. revision: yes
Circularity Check
No circularity; implementation and benchmarking paper with external validation
full rationale
The paper describes an engineering effort to implement a ggml-based runtime for existing VLA models, with claims supported by direct matching to external PyTorch checkpoints on LIBERO-Object (within 1/200 episodes) and code release. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present. The central claim of faithful reproduction of flow-matching/diffusion patterns is an empirical implementation result, not a reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
π0: A Vision-Language-Action Flow Model
Physical Intelligence. π0: A Vision-Language-Action Flow Model. https://github.com/P hysical-Intelligence/openpi, 2024
2024
-
[2]
M. Shukor et al. SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[3]
Isaac GR00T N1.x: Open Foundation Models for Generalist Robots
NVIDIA. Isaac GR00T N1.x: Open Foundation Models for Generalist Robots. https: //github.com/NVIDIA/Isaac-GR00T, 2025
2025
-
[4]
Gerganov et al
G. Gerganov et al. llama.cpp.https://github.com/ggml-org/llama.cpp, 2023
2023
-
[5]
W. Kwon et al. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProc. SOSP, 2023. arXiv:2309.06180
Pith/arXiv arXiv 2023
-
[6]
TensorRT Edge-LLM: An open-source c++ sdk for llm and vlm inference on edge platforms
NVIDIA. TensorRT Edge-LLM: An open-source c++ sdk for llm and vlm inference on edge platforms. https://github.com/NVIDIA/TensorRT-Edge-LLM , 2026. Accessed: 2026- 05-28
2026
-
[7]
TensorRT-LLM: An open-source library for optimizing large language model infer- ence.https://github.com/NVIDIA/TensorRT-LLM, 2026
NVIDIA. TensorRT-LLM: An open-source library for optimizing large language model infer- ence.https://github.com/NVIDIA/TensorRT-LLM, 2026. Accessed: 2026-05-28
2026
- [8]
-
[9]
M. J. Kim et al. OpenVLA: An Open-Source Vision-Language-Action Model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[10]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. InRobotics: Science and Systems (RSS), 2023. arXiv:2303.04137
Pith/arXiv arXiv 2023
-
[11]
MINT-SJTU. Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment.arXiv preprint arXiv:2511.04555, 2025
arXiv 2025
-
[12]
H. Wang et al. BitVLA: 1-bit Vision-Language-Action Models for Robotics Manipulation. arXiv preprint arXiv:2506.07530, 2025
arXiv 2025
-
[13]
Z. Yu, B. Wang, P. Zeng, H. Zhang, J. Zhang, L. Gao, J. Song, N. Sebe, and H. T. Shen. A Survey on Efficient Vision-Language-Action Models.arXiv preprint arXiv:2510.24795, 2025
arXiv 2025
-
[14]
J. Williams, K. D. Gupta, R. George, and M. Sarkar. LiteVLA-Edge: Quantized On-Device Multimodal Control for Embedded Robotics. arXiv:2603.03380, 2026
arXiv 2026
-
[15]
J. Williams, K. D. Gupta, R. George, and M. Sarkar. Lite VLA: Efficient Vision-Language- Action Control on CPU-Bound Edge Robots. arXiv:2511.05642, 2025
arXiv 2025
-
[16]
J. Chen, J. Wang, L. Chen, C. Cai, and J. Lu. NanoVLA: Routing Decoupled Vision-Language Understanding for Nano-sized Generalist Robotic Policies. arXiv:2510.25122, 2025
arXiv 2025
- [17]
-
[18]
X. Li, H. Tang, X. Ding, W. Wang, T. Cao, and Y . Liu. OxyGen: Unified KV Cache Management for VLA Inference under Multi-Task Parallelism. arXiv:2603.14371, 2026
Pith/arXiv arXiv 2026
-
[19]
Reflex: Deployment Infrastructure for Vision-Language-Action Models
FastCrest. Reflex: Deployment Infrastructure for Vision-Language-Action Models. https: //fastcrest.com , 2026. Source-available product; PyTorch-parity deployment of π0/π0.5/SmolVLA/GR00T to Jetson Orin
2026
-
[20]
M. Vishwanathan, S. Subramanian, and A. Raghunathan. Characterizing VLA Models: Identi- fying the Action Generation Bottleneck for Edge AI Architectures. arXiv:2603.02271, 2026
arXiv 2026
-
[21]
K. Zhou, Q. Chen, D. Peng, et al. Characterizing Vision-Language-Action Models across XPUs: Constraints and Acceleration for On-Robot Deployment. arXiv:2604.24447, 2026
Pith/arXiv arXiv 2026
-
[22]
Y . Dai, H. Gu, T. Wang, et al. ActionFlow: A Pipelined Action Acceleration for Vision Language Models on Edge. arXiv:2512.20276, 2025
arXiv 2025
-
[23]
H. Wang, J. Xu, J. Pan, Y . Zhou, et al. SpecPrune-VLA: Accelerating Vision-Language-Action Models via Action-Aware Self-Speculative Pruning. arXiv:2509.05614, 2025
Pith/arXiv arXiv 2025
-
[24]
M. J. Kim et al. Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success. arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[25]
MLC-LLM: Universal LLM Deployment Engine with ML Compilation
MLC team. MLC-LLM: Universal LLM Deployment Engine with ML Compilation. https: //llm.mlc.ai, 2024
2024
-
[26]
ZeroMQ: An Open-Source Universal Messaging Library
iMatix. ZeroMQ: An Open-Source Universal Messaging Library. https://zeromq.org , 2007
2007
-
[27]
Protocol Buffers.https://protobuf.dev, 2008
Google. Protocol Buffers.https://protobuf.dev, 2008
2008
-
[28]
Liu et al
B. Liu et al. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 10
2023
-
[29]
X. Li et al. Evaluating Real-World Robot Manipulation Policies in Simulation.arXiv preprint arXiv:2405.05941, 2024. SimplerEnv
Pith/arXiv arXiv 2024
-
[30]
X. Zhou, Y . Xu, G. Tie, et al. LIBERO-PRO: Towards Robust and Fair Evaluation of Vision- Language-Action Models Beyond Memorization. arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[31]
S. Fei, S. Wang, J. Shi, others, and X. Qiu. LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models. arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[32]
S. Williams, A. Waterman, and D. Patterson. Roofline: An Insightful Visual Performance Model for Multicore Architectures.Communications of the ACM, 52(4):65–76, 2009. doi: 10.1145/1498765.1498785
-
[33]
bitnet.cpp: Official Inference Framework for 1-bit LLMs
Microsoft. bitnet.cpp: Official Inference Framework for 1-bit LLMs. https://github.com /microsoft/BitNet, 2024
2024
-
[34]
J. Wang, H. Zhou, T. Song, S. Cao, others, and F. Wei. Bitnet.cpp: Efficient Edge Inference for Ternary LLMs. InAnnual Meeting of the Association for Computational Linguistics (ACL),
-
[35]
L. Wang, L. Ma, S. Cao, Q. Zhang, J. Xue, et al. Ladder: Enabling Efficient Low-Precision Deep Learning Computing through Hardware-aware Tensor Transformation. InUSENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024
2024
-
[36]
BitBLAS: A Library to Support Mixed-Precision Matrix Multiplications for Quan- tized LLM Deployment.https://github.com/microsoft/BitBLAS, 2024
Microsoft. BitBLAS: A Library to Support Mixed-Precision Matrix Multiplications for Quan- tized LLM Deployment.https://github.com/microsoft/BitBLAS, 2024
2024
-
[37]
E. Frantar, R. L. Castro, J. Chen, T. Hoefler, and D. Alistarh. MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models. InACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2025. arXiv:2408.11743
arXiv 2025
-
[38]
J. Yuan, H. Li, X. Ding, others, and Z. Liu. Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning. arXiv:2506.09501, 2025
arXiv 2025
-
[39]
P. Qi, Z. Liu, X. Zhou, others, and M. Lin. Defeating the Training-Inference Mismatch via FP16. arXiv:2510.26788, 2025
arXiv 2025
-
[40]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InRobotics: Science and Systems (RSS), 2023. ACT/ALOHA; arXiv:2304.13705
Pith/arXiv arXiv 2023
-
[41]
Y . Liu, J. I. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn. Bidirectional Decoding: Improving Action Chunking via Guided Test-Time Sampling. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2408.17355
arXiv 2025
-
[42]
Y . Lu, Z. Liu, X. Fan, Z. Yang, J. Hou, J. Li, K. Ding, and H. Zhao. FASTER: Rethinking Real-Time Flow VLAs.arXiv preprint arXiv:2603.19199, 2026
Pith/arXiv arXiv 2026
-
[43]
K. Black, M. Y . Galliker, and S. Levine. Real-Time Execution of Action Chunking Flow Policies.arXiv preprint arXiv:2506.07339, 2025
Pith/arXiv arXiv 2025
-
[44]
K. Sendai, M. Alvarez, T. Matsushima, Y . Matsuo, and Y . Iwasawa. Leave No Observation Behind: Real-time Correction for VLA Action Chunks. arXiv:2509.23224, 2025. 11 A From Architecture to Implementation A.1 The served architectures Table 5 summarizes the seven architectures vla.cpp serves. They span four vision-encoder and six language-model architectur...
arXiv 2025
-
[45]
We tap the final-layer hidden-state tensor of the language model before the output projection and route the full[tokens×d]sequence to the action head as the cross-attention source
Exposing full hidden states.A text runtime returns only logits or a pooled embedding. We tap the final-layer hidden-state tensor of the language model before the output projection and route the full[tokens×d]sequence to the action head as the cross-attention source
-
[46]
We construct the mask at graph-build time from the segment layout of each request
Bidirectional prefix mask.The prefix is encoded with a bidirectional attention mask rather than the causal mask used for decoding, so images, instruction, and state attend freely. We construct the mask at graph-build time from the segment layout of each request
-
[47]
put carrot on plate
Cross-attention cache lifecycle.The prefix keys and values are computed once per ob- servation and reused across all solver steps. We allocate a dedicated cross-attention cache, distinct from the language-model self-attention KV cache, that persists for the lifetime of one denoising integration and is released when the action chunk is returned. The action...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.