MURMUR: An Efficient Inference System for Long-Form ASR
Pith reviewed 2026-06-28 17:03 UTC · model grok-4.3
The pith
Murmur matches single-pass long-form ASR accuracy while cutting latency by 4.2x through tunable chunks and KV cache eviction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
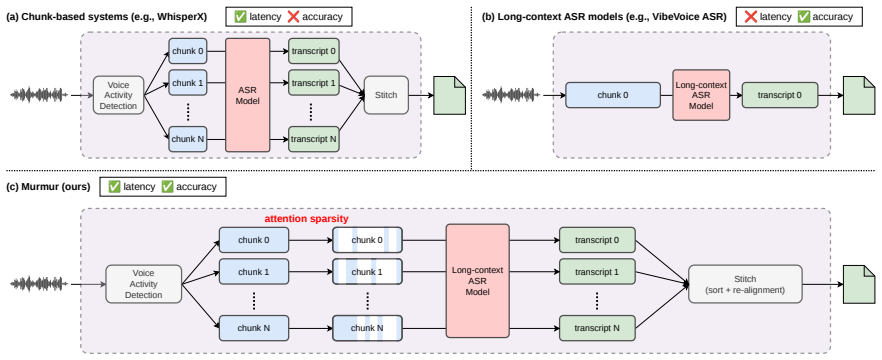
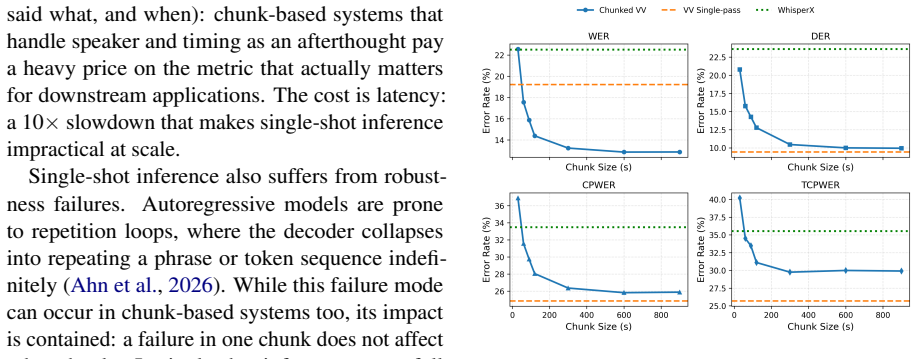
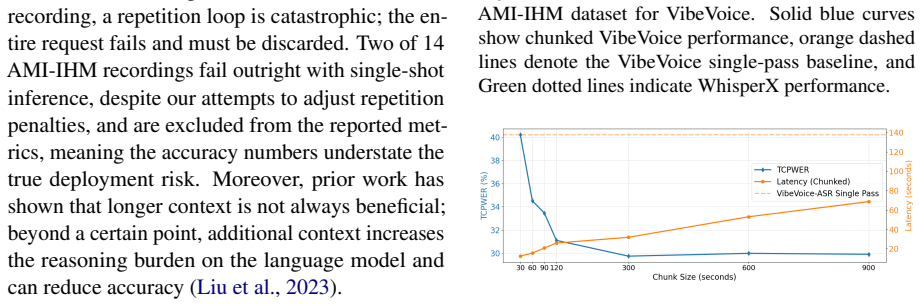
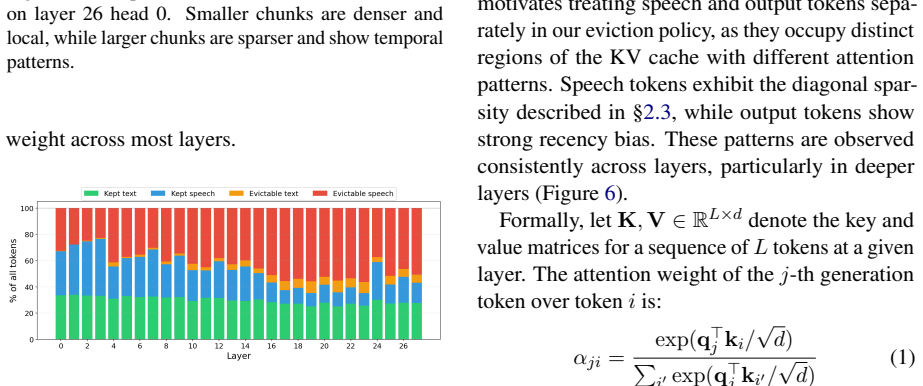
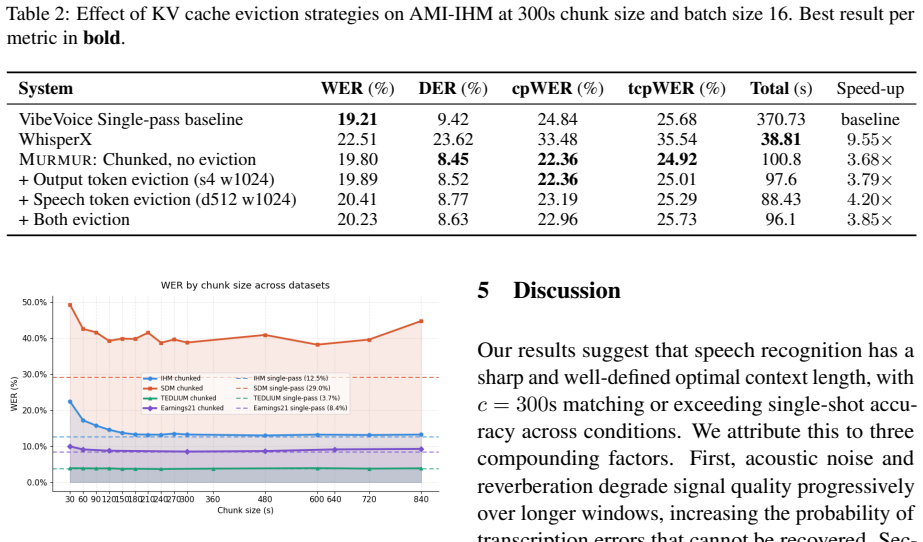
Murmur demonstrates that an inference system operating at inter-chunk and intra-chunk levels can achieve the accuracy of single-pass long-context ASR models. At the inter-chunk level, intermediate chunk sizes serve as a tunable hyperparameter to balance accuracy and latency in chunk-based pipelines. At the intra-chunk level, a sliding window KV cache eviction policy applied to both output and speech tokens exploits attention sparsity. On the AMI-IHM dataset, this yields matching single-pass accuracy with 4.2x latency reduction and further improvements from eviction at under 1% relative tcpWER degradation.
What carries the argument
The two-level inference system consisting of tunable intermediate chunk sizes at the inter-chunk level and a sliding-window KV cache eviction policy on output and speech tokens at the intra-chunk level.
If this is right
- Intermediate chunk sizes strike a balance between accuracy and latency without needing brittle boundary alignment heuristics.
- Sliding window KV eviction on speech and output tokens reduces compute while keeping accuracy loss minimal.
- Chunk size can be treated as a hyperparameter to optimize for specific accuracy-latency requirements.
- The approach extends chunk-based methods to modern long-context ASR models effectively.
Where Pith is reading between the lines
- Similar chunk tuning and eviction strategies could reduce latency in other long-sequence tasks such as video processing or long-document summarization.
- The eviction policy might benefit from dataset-specific tuning to maintain performance across varied acoustic conditions.
- Integration with hardware-specific optimizations could yield additional speedups beyond the reported 4.2x.
Load-bearing premise
That the intermediate chunk sizes and the specific sliding-window KV eviction policy on output and speech tokens will preserve accuracy across different datasets and model scales.
What would settle it
A test on a new long-form ASR dataset or larger model where the same chunk sizes and eviction policy cause more than 1% relative increase in tcpWER compared to single-pass inference.
Figures


read the original abstract
Long-form automatic speech recognition (ASR) requires both high accuracy and low latency, but existing systems force a trade-off between the two. Chunk-based pipelines process audio in parallel windows for low latency, but lose cross-chunk context and need brittle heuristics to align speakers and timestamps at boundaries. Long-context ASR models resolve everything in a single pass for better accuracy, but are an order of magnitude slower. We propose Murmur, an inference system that overcomes this trade-off by operating at two levels. At the inter-chunk level, we revisit the chunk-based pipeline for modern long-context ASR, treating chunk size as a tunable hyperparameter, and show that intermediate chunk sizes strike a good balance of accuracy and latency. At the intra-chunk level, we exploit attention sparsity through a sliding window KV cache eviction policy applied to both output and speech tokens. On AMI-IHM, Murmur matches single-pass accuracy while reducing latency by 4.2x, with further gains from token eviction at less than 1% relative tcpWER degradation. The code of Murmur is available at https://github.com/uw-syfi/Murmur.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Murmur, a two-level inference system for long-form ASR. At the inter-chunk level it treats chunk size as a tunable hyperparameter in a chunk-based pipeline; at the intra-chunk level it applies a sliding-window KV-cache eviction policy to both speech and output tokens. On AMI-IHM the system is reported to match single-pass tcpWER while cutting latency by 4.2×, with eviction yielding further gains at <1 % relative tcpWER degradation. Code is released.
Significance. If the empirical claims hold under broader validation, the work would be significant for practical long-context ASR deployment by showing that intermediate chunk sizes plus attention sparsity can close the accuracy-latency gap without brittle boundary heuristics. The open-source release strengthens reproducibility.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): the headline result (matching single-pass tcpWER at 4.2× lower latency plus <1 % relative degradation from eviction) is presented without error bars, full ablation tables on chunk size or eviction-window size, or dataset statistics; this directly undermines verification of the central empirical claim.
- [§3.2] §3.2 (Intra-chunk eviction): the sliding-window KV eviction policy is applied uniformly to speech and output tokens with no reported ablation of window size, eviction frequency, or differential treatment; because this policy is load-bearing for both the latency reduction and the “further gains” clause, its robustness cannot be assessed from the given text.
minor comments (2)
- [§4, figures] Figure captions and §4 should explicitly state the number of runs and any statistical tests used for the reported tcpWER and latency numbers.
- [§3.2, §4] The manuscript should clarify whether the eviction policy was tuned on the same AMI-IHM split used for final reporting.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the empirical presentation while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the headline result (matching single-pass tcpWER at 4.2× lower latency plus <1 % relative degradation from eviction) is presented without error bars, full ablation tables on chunk size or eviction-window size, or dataset statistics; this directly undermines verification of the central empirical claim.
Authors: We agree that the absence of error bars, expanded ablation tables, and dataset statistics limits independent verification. In the revised manuscript we will add error bars from multiple random seeds for the reported latency and tcpWER figures, full ablation tables varying both chunk size and eviction-window size, and a concise summary of AMI-IHM dataset statistics (total hours, speaker count, and split details). These additions will appear in an expanded §4 and an updated abstract. revision: yes
-
Referee: [§3.2] §3.2 (Intra-chunk eviction): the sliding-window KV eviction policy is applied uniformly to speech and output tokens with no reported ablation of window size, eviction frequency, or differential treatment; because this policy is load-bearing for both the latency reduction and the “further gains” clause, its robustness cannot be assessed from the given text.
Authors: We concur that additional ablations are required to substantiate the eviction policy. The revised §3.2 will include systematic sweeps of window size and eviction frequency, plus a comparison of uniform versus differential eviction for speech versus output tokens. Quantitative results on both latency and tcpWER degradation will be reported to allow assessment of robustness. revision: yes
Circularity Check
No circularity; purely empirical system evaluation
full rationale
The paper describes an inference system (Murmur) for long-form ASR and reports direct measurements of tcpWER and latency on the public AMI-IHM dataset. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. The latency and accuracy claims are presented as observed outcomes of the described chunking and KV-eviction policy rather than results derived from prior results by construction. This is the normal case for an empirical systems paper whose central claims rest on external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- chunk size
- eviction window size
Reference graph
Works this paper leans on
-
[1]
Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew , booktitle =
-
[2]
Beyond the Utterance: An Empirical Study of Very Long Context Speech Recognition , volume=
Flynn, Robert and Ragni, Anton , year=. Beyond the Utterance: An Empirical Study of Very Long Context Speech Recognition , volume=. doi:10.1109/taslpro.2026.3658246 , journal=
-
[3]
arXiv preprint arXiv:2601.18184 , year=
VIBEVOICE-ASR Technical Report , author=. arXiv preprint arXiv:2601.18184 , year=
-
[4]
Robust Speech Recognition via Large-Scale Weak Supervision , author =. Proc. ICML , year =
-
[5]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with
-
[6]
McCowan, Iain and Carletta, Jean and Kraaij, Wessel and Ashby, Simone and Bourban, Sebastien and Flynn, Mike and Guillemot, Mael and Hain, Thomas and Kadlec, Jaroslav and Karaiskos, Vasilis and others , booktitle =. The
-
[7]
Watanabe, Shinji and others , booktitle =
-
[8]
Chen, Yukang and Qian, Shengju and Tang, Haotian and Lai, Xin and Liu, Zhijian and Han, Song and Jia, Jiaya , journal =
-
[9]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Updated corpora and benchmarks for long-form speech recognition , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[10]
, author=
TED-LIUM: an automatic speech recognition dedicated corpus. , author=. LREC , pages=
-
[11]
Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio , author=. arXiv preprint arXiv:2106.06909 , year=
-
[12]
Speech recognition for medical conversations
Speech recognition for medical conversations , author=. arXiv preprint arXiv:1711.07274 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2507.13264 , year=
Voxtral , author=. arXiv preprint arXiv:2507.13264 , year=
-
[14]
TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation , ISBN=
Hernandez, François and Nguyen, Vincent and Ghannay, Sahar and Tomashenko, Natalia and Estève, Yannick , year=. TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation , ISBN=. doi:10.1007/978-3-319-99579-3_21 , booktitle=
-
[15]
2026 , eprint=
TagSpeech: End-to-End Multi-Speaker ASR and Diarization with Fine-Grained Temporal Grounding , author=. 2026 , eprint=
2026
-
[16]
2026 , eprint=
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models , author=. 2026 , eprint=
2026
-
[17]
2024 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
2024
-
[18]
2023 , eprint=
H _2 O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author=. 2023 , eprint=
2023
-
[19]
2023 , eprint=
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , eprint=
2023
-
[20]
2026 , eprint=
Whisper-CD: Accurate Long-Form Speech Recognition using Multi-Negative Contrastive Decoding , author=. 2026 , eprint=
2026
-
[21]
Distil-whisper: Robust knowledge distillation via large-scale pseudo labelling , author=. arXiv preprint arXiv:2311.00430 , year=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Liteasr: Efficient automatic speech recognition with low-rank approximation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
DQ-Whisper: Joint distillation and quantization for efficient multilingual speech recognition , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2024 , organization=
2024
-
[24]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Whisper-MLA: Reducing GPU Memory Consumption of ASR Models Based on MHA2MLA Conversion , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[25]
arXiv preprint arXiv:2602.00269 , year=
VoxServe: Streaming-Centric Serving System for Speech Language Models , author=. arXiv preprint arXiv:2602.00269 , year=
-
[26]
2023 , publisher =
Klein, Guillaume , title =. 2023 , publisher =
2023
-
[27]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Quest: Query-aware sparsity for efficient long-context llm inference , author=. arXiv preprint arXiv:2406.10774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2502.12216 , year=
Tactic: Adaptive sparse attention with clustering and distribution fitting for long-context llms , author=. arXiv preprint arXiv:2502.12216 , year=
-
[31]
arXiv preprint arXiv:2505.18860 , year=
Context-driven dynamic pruning for large speech foundation models , author=. arXiv preprint arXiv:2505.18860 , year=
-
[32]
arXiv preprint arXiv:2506.15912 , year=
Early Attentive Sparsification Accelerates Neural Speech Transcription , author=. arXiv preprint arXiv:2506.15912 , year=
-
[33]
arXiv preprint arXiv:2104.11348 , year=
Earnings-21: A practical benchmark for asr in the wild , author=. arXiv preprint arXiv:2104.11348 , year=
-
[34]
2019 , eprint=
pyannote.audio: neural building blocks for speaker diarization , author=. 2019 , eprint=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.