Remembering by Reconstructing: Domain Incremental Learning With Test-Time Training on Video Streams
Pith reviewed 2026-06-28 22:59 UTC · model grok-4.3
The pith
At inference, online test-time training on a masked autoencoder head selects the matching LoRA adapter to recover domain knowledge after induced forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
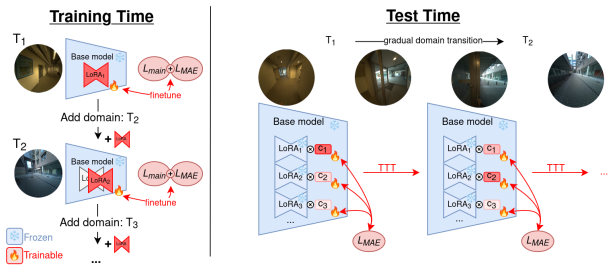
By inducing forgetting through specialized LoRA adapters during incremental training and recovering the right adapter at inference via test-time training on the MAE reconstruction task, the model adapts to non-stationary video streams where domains evolve gradually.
What carries the argument
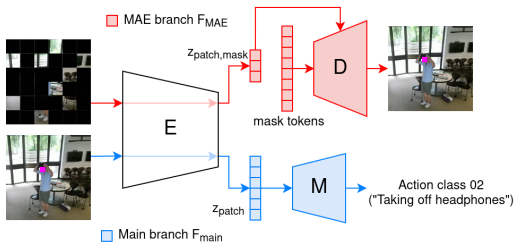
Domain-specific LoRA adapters combined with a self-supervised MAE head for online adapter selection at test time.
Load-bearing premise
Test-time training on the MAE head produces a reliable signal to select the correct LoRA adapter during gradual domain shifts in video.
What would settle it
A case where the MAE reconstruction error fails to identify the matching LoRA for inputs from a shifted domain in video sequences.
Figures

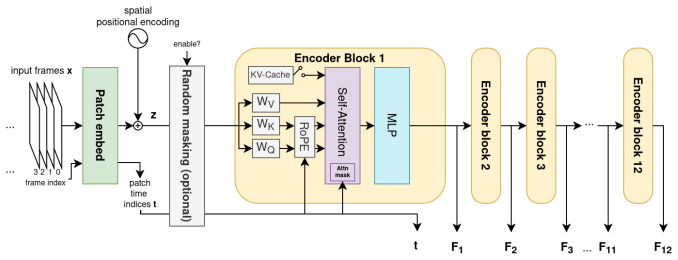
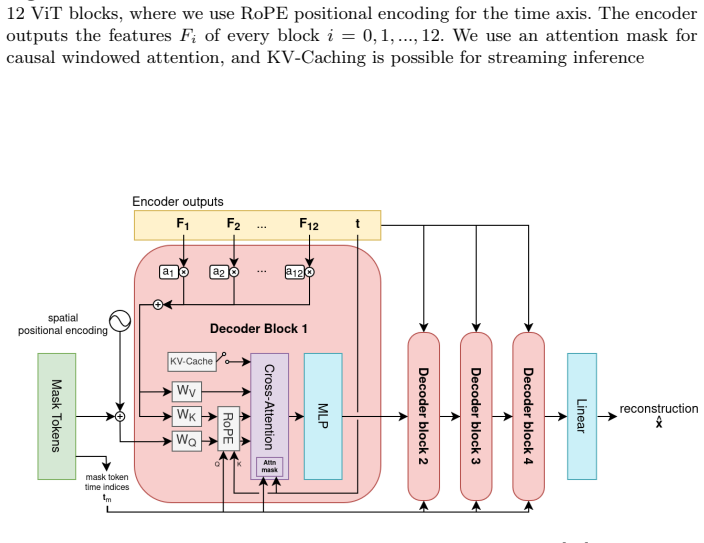
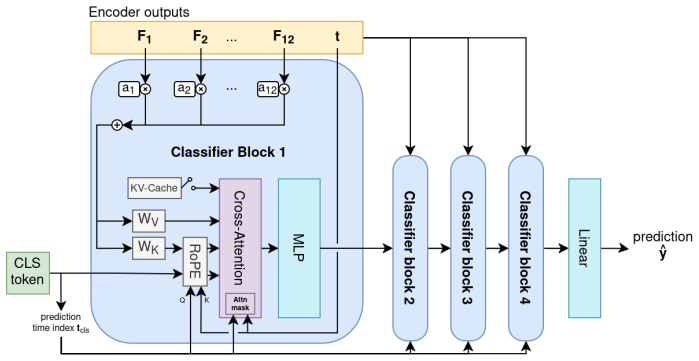
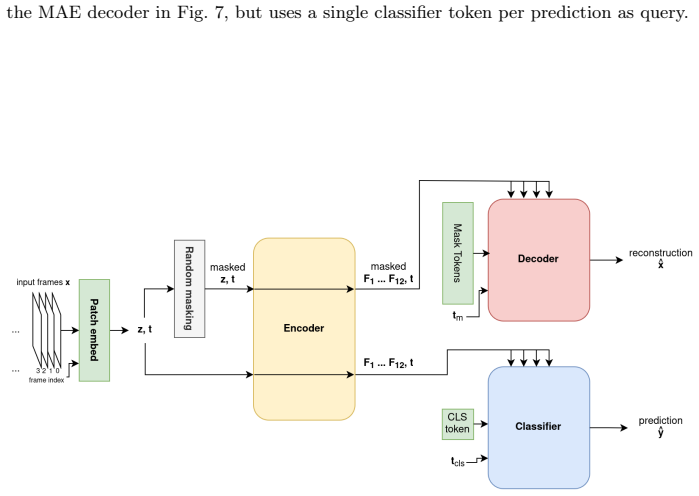

read the original abstract
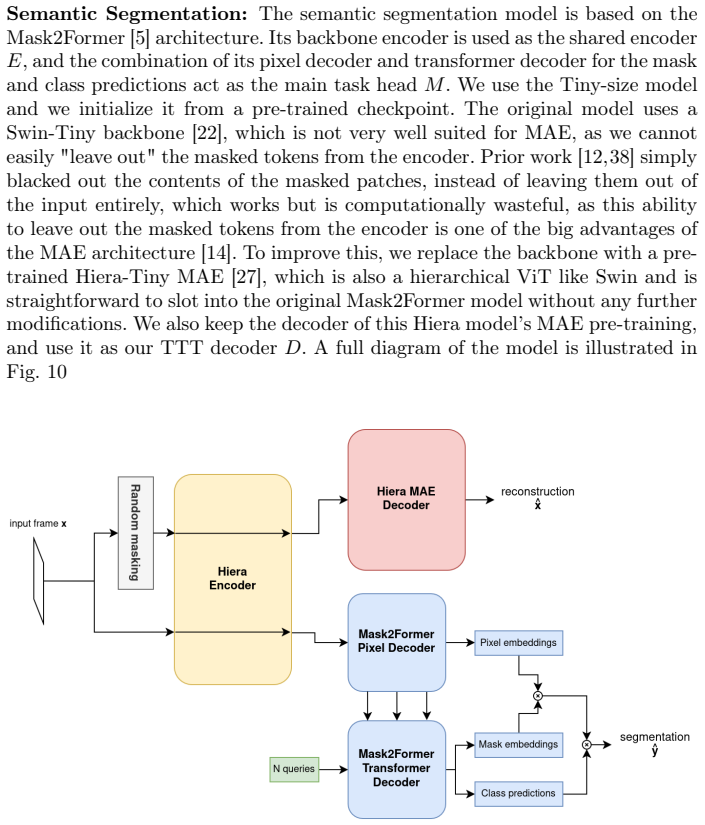
In this work we introduce a novel approach to domain incremental learning, adapting models over time to evolving, non-stationary data. In contrast to other works, we do not attempt to avoid catastrophic forgetting, but rather allow it and exploit it. Our model combines a main task head with a self-supervised masked autoencoder (MAE) head. We then learn domain-specific LoRA adapters during incremental training. Each adapter specializes to its domain, naturally inducing forgetting on other domains in both heads. At inference, we perform online test-time training on the self-supervised MAE head to identify which LoRAs best matches the current input, so the model can `remember' the domain again. Our scheme is especially well-suited to real-world streaming data, such as video, where consecutive samples are highly correlated and domain shifts are gradual. We demonstrate our method on domain-incremental action recognition and semantic segmentation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a domain-incremental learning method that deliberately allows and exploits catastrophic forgetting rather than preventing it. A shared backbone is paired with a main task head and a self-supervised MAE reconstruction head; domain-specific LoRA adapters are learned during incremental training so that each adapter specializes to its domain while inducing forgetting elsewhere. At inference on video streams, online test-time training is performed on the MAE head to identify which LoRA best matches the current input, thereby 'remembering' the appropriate domain adapter. The approach is claimed to be particularly suited to gradual domain shifts in temporally correlated video data and is demonstrated on domain-incremental action recognition and semantic segmentation.
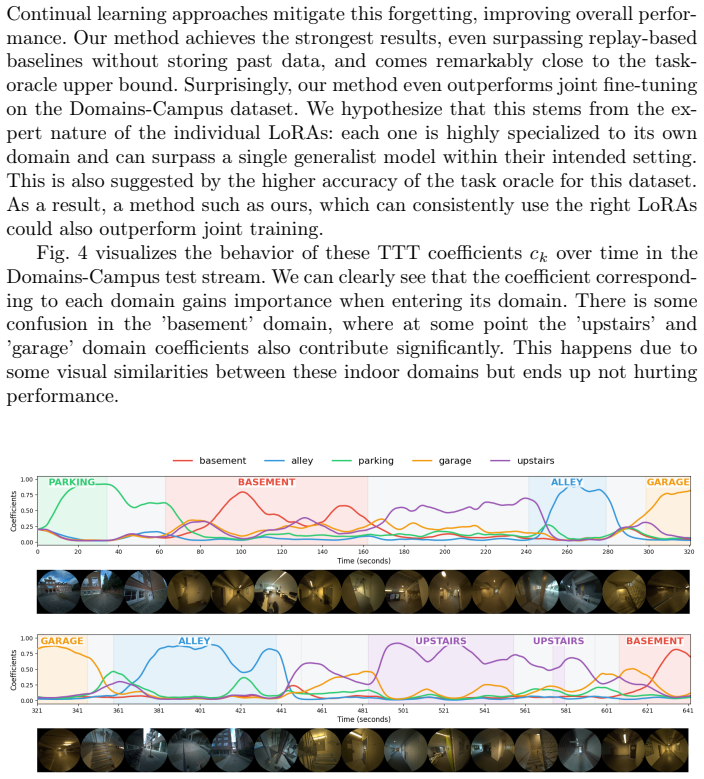
Significance. If the selection mechanism proves reliable, the work would offer a conceptually distinct alternative to conventional continual-learning strategies that focus on forgetting mitigation. By turning domain-specific forgetting into a feature that can be recovered via test-time adaptation, the method could simplify handling of non-stationary streaming data without requiring explicit domain labels or rehearsal buffers.
major comments (1)
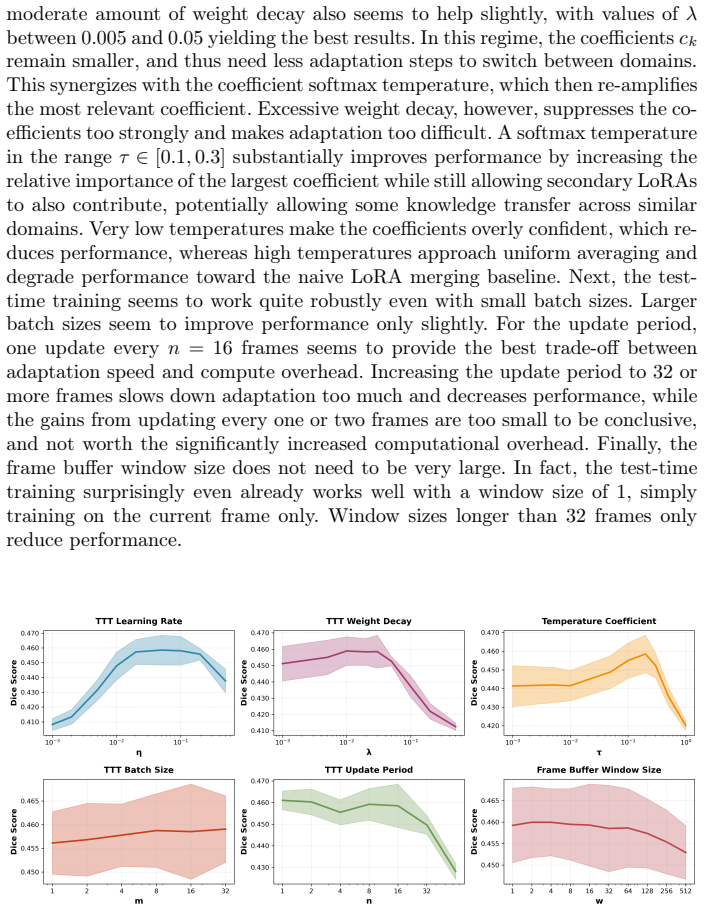
- [Abstract] Abstract (final paragraph): the claim that the scheme is 'especially well-suited' to video streams with gradual domain shifts rests on the unverified assumption that TTT on the MAE head will produce an unambiguous argmin over reconstruction losses for the correct LoRA. When consecutive frames lie in an intermediate regime between two domains, multiple LoRAs may yield comparable losses, rendering selection noisy or unstable; this is load-bearing for the entire 'remembering' procedure and is not addressed by any analysis or experiment in the provided text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for identifying a key assumption underlying our claims about suitability for video streams. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the claim that the scheme is 'especially well-suited' to video streams with gradual domain shifts rests on the unverified assumption that TTT on the MAE head will produce an unambiguous argmin over reconstruction losses for the correct LoRA. When consecutive frames lie in an intermediate regime between two domains, multiple LoRAs may yield comparable losses, rendering selection noisy or unstable; this is load-bearing for the entire 'remembering' procedure and is not addressed by any analysis or experiment in the provided text.
Authors: We agree that the manuscript does not provide explicit analysis or experiments examining the behavior of the MAE reconstruction losses (and resulting argmin) when input frames lie in transitional or intermediate regimes between domains. Our existing experiments demonstrate overall task performance under gradual shifts, but they do not isolate or quantify selection stability in such boundary cases. We will revise the paper by adding a targeted analysis (new subsection and supplementary figures) that measures per-LoRA reconstruction losses on synthetic and real transitional sequences, reports the frequency of ambiguous selections, and evaluates the impact on downstream task accuracy. This will either substantiate or qualify the suitability claim. revision: yes
Circularity Check
No circularity in method description or inference procedure
full rationale
The paper describes a procedural approach combining a task head with an MAE head, training domain-specific LoRA adapters, and using online TTT on the MAE head at inference to select the matching adapter. No equations, derivations, or parameter-fitting steps are presented that reduce by construction to the method's own inputs or prior self-citations. The central claim relies on an empirical assumption about reconstruction loss providing a selection signal under gradual video shifts, but this is not a self-definitional or fitted-input reduction; it remains an externally testable hypothesis. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain shifts in video streams are gradual and consecutive samples are highly correlated.
Reference graph
Works this paper leans on
-
[1]
BEiT: BERT Pre-Training of Image Transformers
Bao, H., Dong, L., Piao, S., Wei, F.: Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Revisiting Feature Prediction for Learning Visual Representations from Video
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In- ternational Journal of Computer Vision132(1), 208–223 (2024)
Chen, X., Ding, M., Wang, X., Xin, Y., Mo, S., Wang, Y., Han, S., Luo, P., Zeng, G., Wang, J.: Context autoencoder for self-supervised representation learning. In- ternational Journal of Computer Vision132(1), 208–223 (2024)
2024
-
[5]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 1280–1289 (2021), https://api.semanticscholar.org/CorpusID:244799297
2022
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1290–1299 (2022)
2022
-
[7]
arXiv preprint arXiv:2311.02428 (2023)
Chitale, R., Vaidya, A., Kane, A., Ghotkar, A.: Task arithmetic with lora for continual learning. arXiv preprint arXiv:2311.02428 (2023)
-
[8]
IEEE transactions on pattern analysis and machine intelligence 44(7), 3366–3385 (2021)
De Lange, M., Aljundi, R., Masana, M., Parisot, S., Jia, X., Leonardis, A., Slabaugh, G., Tuytelaars, T.: A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence 44(7), 3366–3385 (2021)
2021
-
[9]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Engel, J., Somasundaram, K., Goesele, M., Sun, A., Gamino, A., Turner, A., Ta- lattof, A., Yuan, A., Souti, B., Meredith, B., et al.: Project aria: A new tool for egocentric multi-modal ai research. arXiv preprint arXiv:2308.13561 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Advances in neural information processing systems35, 35946–35958 (2022)
Feichtenhofer, C., Li, Y., He, K., et al.: Masked autoencoders as spatiotempo- ral learners. Advances in neural information processing systems35, 35946–35958 (2022)
2022
-
[11]
arXiv preprint arXiv:2401.14391 (2024)
Fu, L., Lian, L., Wang, R., Shi, B., Wang, X., Yala, A., Darrell, T., Efros, A.A., Goldberg, K.: Rethinking patch dependence for masked autoencoders. arXiv preprint arXiv:2401.14391 (2024)
-
[12]
Advances in Neural Information Processing Systems35, 29374–29385 (2022)
Gandelsman, Y., Sun, Y., Chen, X., Efros, A.: Test-time training with masked au- toencoders. Advances in Neural Information Processing Systems35, 29374–29385 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao,Q.,Zhao,C.,Sun,Y.,Xi,T.,Zhang,G.,Ghanem,B.,Zhang,J.:Aunifiedcon- tinual learning framework with general parameter-efficient tuning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11483–11493 (2023) 14
2023
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[15]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[16]
In: International Conference on Image and Graphics
Hu, Y., Hou, J., Liu, X., Sun, X., Guo, W.: Video domain incremental learning for human action recognition in home environments. In: International Conference on Image and Graphics. pp. 316–327. Springer (2025)
2025
-
[17]
In: European conference on computer vision
Huang, G., Sun, Y., Liu, Z., Sedra, D., Weinberger, K.Q.: Deep networks with stochastic depth. In: European conference on computer vision. pp. 646–661. Springer (2016)
2016
-
[18]
The Kinetics Human Action Video Dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liang, Y.S., Li, W.J.: Inflora: Interference-free low-rank adaptation for continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23638–23647 (2024)
2024
-
[21]
IEEE trans- actions on pattern analysis and machine intelligence42(10), 2684–2701 (2019)
Liu, J., Shahroudy, A., Perez, M., Wang, G., Duan, L.Y., Kot, A.C.: Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE trans- actions on pattern analysis and machine intelligence42(10), 2684–2701 (2019)
2019
-
[22]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[23]
McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: Thesequentiallearningproblem.In:Psychologyoflearningandmotivation,vol.24, pp. 109–165. Elsevier (1989)
1989
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Park, H., Park, H., Ko, J., Min, D.: Hybrid-tta: Continual test-time adaptation via dynamic domain shift detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2877–2886 (2025)
2025
-
[25]
Proceedings of machine learning and systems5, 606–624 (2023)
Pope, R., Douglas, S., Chowdhery, A., Devlin, J., Bradbury, J., Heek, J., Xiao, K., Agrawal, S., Dean, J.: Efficiently scaling transformer inference. Proceedings of machine learning and systems5, 606–624 (2023)
2023
-
[26]
Advances in neural information processing systems32(2019)
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., Wayne, G.: Experience replay for continual learning. Advances in neural information processing systems32(2019)
2019
-
[27]
Ryali, C., Hu, Y.T., Bolya, D., Wei, C., Fan, H., Huang, P.Y., Aggarwal, V., Chowdhury, A., Poursaeed, O., Hoffman, J., et al.: Hiera: A hierarchical vision transformerwithoutthebells-and-whistles.In:Internationalconferenceonmachine learning. pp. 29441–29454. PMLR (2023)
2023
-
[28]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Shahroudy, A., Liu, J., Ng, T.T., Wang, G.: Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1010–1019 (2016)
2016
-
[29]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[30]
In: International conference on machine learning
Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A., Hardt, M.: Test-time training with self-supervision for generalization under distribution shifts. In: International conference on machine learning. pp. 9229–9248. PMLR (2020) 15
2020
-
[31]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the incep- tion architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2818–2826 (2016)
2016
-
[32]
In: Proceed- ings of the Asian Conference on Computer Vision
Tian, J., Lyu, F.: Parameter-selective continual test-time adaptation. In: Proceed- ings of the Asian Conference on Computer Vision. pp. 1384–1400 (2024)
2024
-
[33]
Advances in neural infor- mation processing systems35, 10078–10093 (2022)
Tong, Z., Song, Y., Wang, J., Wang, L.: Videomae: Masked autoencoders are data- efficient learners for self-supervised video pre-training. Advances in neural infor- mation processing systems35, 10078–10093 (2022)
2022
-
[34]
Three scenarios for continual learning
Van de Ven, G.M., Tolias, A.S.: Three scenarios for continual learning. arXiv preprint arXiv:1904.07734 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[35]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Wang, L., Xie, J., Zhang, X., Su, H., Zhu, J.: Hide-pet: continual learning via hierarchical decomposition of parameter-efficient tuning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[36]
IEEE transactions on pattern analysis and machine intelligence46(8), 5362–5383 (2024)
Wang, L., Zhang, X., Su, H., Zhu, J.: A comprehensive survey of continual learn- ing: Theory, method and application. IEEE transactions on pattern analysis and machine intelligence46(8), 5362–5383 (2024)
2024
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Q., Fink, O., Van Gool, L., Dai, D.: Continual test-time domain adapta- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7201–7211 (2022)
2022
-
[38]
Journal of Machine Learning Research26(9), 1–29 (2025)
Wang, R., Sun, Y., Tandon, A., Gandelsman, Y., Chen, X., Efros, A.A., Wang, X.: Test-time training on video streams. Journal of Machine Learning Research26(9), 1–29 (2025)
2025
-
[39]
In: European conference on computer vision
Wang, Z., Zhang, Z., Ebrahimi, S., Sun, R., Zhang, H., Lee, C.Y., Ren, X., Su, G., Perot, V., Dy, J., et al.: Dualprompt: Complementary prompting for rehearsal- free continual learning. In: European conference on computer vision. pp. 631–648. Springer (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Zhang, Z., Lee, C.Y., Zhang, H., Sun, R., Ren, X., Su, G., Perot, V., Dy, J., Pfister, T.: Learning to prompt for continual learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 139–149 (2022)
2022
-
[41]
Workshop on Distribution Shifts (DistShift), NeurIPS (2023)
Wistuba, M., Sivaprasad, P.T., Balles, L., Zappella, G.: Continual learning with low rank adaptation. Workshop on Distribution Shifts (DistShift), NeurIPS (2023)
2023
-
[42]
In: Inter- national Conference on Machine Learning (ICML) (2023)
Zhao, H., Liu, Y., Alahi, A., Lin, T.: On pitfalls of test-time adaptation. In: Inter- national Conference on Machine Learning (ICML) (2023)
2023
-
[43]
leave out
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2017) 16 A Implementation Details A.1 Model architectures Video Action Recognition:For our action recognition model, the encoder and MAE decoderEandDare based on the VideoM...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.