PlanRL: A Trajectory Planning Architecture for Reinforcement Learning-based Driving Experts
Pith reviewed 2026-06-26 04:41 UTC · model grok-4.3
The pith
RL driving experts improve by planning trajectories in Frenet coordinates with kinematic checks rather than outputting direct controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
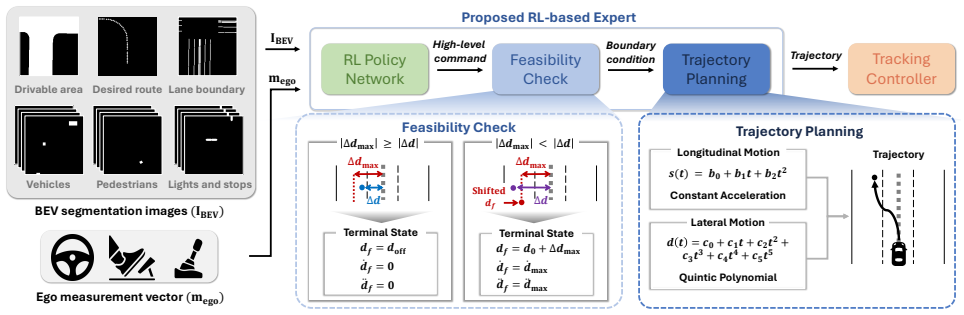
By employing a Frenet-frame coordinate system, our method simplifies complex road geometries into a curvilinear framework, offering a structured coordinate prior that facilitates policy learning. Furthermore, we incorporate a kinematic feasibility check into the planning stage to ensure that generated trajectories remain within the vehicle's physical limits, effectively mitigating cumulative tracking errors typically found in planning-based systems. We evaluate our approach on key CARLA benchmarks, where it significantly outperforms existing state-of-the-art control-based RL experts. On the CARLA Offline Leaderboard v1 and NoCrash benchmarks, our method improves the driving score by 5% and 1
What carries the argument
RL policy integrated with polynomial-based trajectory planner in Frenet-frame coordinates plus kinematic feasibility check.
If this is right
- Road geometries become simpler for the RL policy to learn because they are expressed in a curvilinear Frenet frame.
- Generated trajectories stay inside vehicle physical limits, reducing cumulative tracking errors.
- The outputs are more interpretable than direct throttle and steering commands.
- The architecture is more compatible with end-to-end planning systems than pure control-based RL.
- Performance on CARLA benchmarks rises by the reported margins over prior control-based experts.
Where Pith is reading between the lines
- The same Frenet-plus-kinematic structure could be tested in other continuous-control settings that involve curved paths and actuator limits.
- Replacing the polynomial planner with learned trajectory generators might preserve the coordinate prior while increasing flexibility.
- Real-vehicle deployment would require mapping sensor data into the Frenet frame without introducing new errors.
- Combining the architecture with imitation learning pre-training could further lower sample needs on the CARLA tasks.
Load-bearing premise
The RL policy learns effectively from the simplified Frenet coordinate prior and the kinematic check sufficiently prevents cumulative tracking errors.
What would settle it
Running the architecture on the CARLA Offline Leaderboard v1 and NoCrash benchmarks and finding driving scores or success rates no higher than those of existing control-based RL experts.
Figures

read the original abstract
Reinforcement learning (RL) has become a prominent framework for developing driving experts in autonomous vehicles. However, most existing RL-based experts are designed to output direct control commands (e.g., throttle, steering), which suffer from a lack of interpretability, high spatial complexity in learning road geometries, and poor compatibility with modern end-to-end planning architectures. To address these limitations, we propose a novel trajectory planning architecture for RL driving experts that integrates an RL policy with a polynomial-based trajectory planner. By employing a Frenet-frame coordinate system, our method simplifies complex road geometries into a curvilinear framework, offering a structured coordinate prior that facilitates policy learning. Furthermore, we incorporate a kinematic feasibility check into the planning stage to ensure that generated trajectories remain within the vehicle's physical limits, effectively mitigating cumulative tracking errors typically found in planning-based systems. We evaluate our approach on key CARLA benchmarks, where it significantly outperforms existing state-of-the-art control-based RL experts. On the CARLA Offline Leaderboard v1 and NoCrash benchmarks, our method improves the driving score by 5% and 11%, respectively, and increases the success rate by 8% and 19%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PlanRL, a hybrid architecture that couples an RL policy to a polynomial trajectory planner operating in Frenet-frame coordinates and augmented by an explicit kinematic feasibility check. It claims that the Frenet prior simplifies road geometry for policy learning and that the feasibility check prevents cumulative tracking errors, yielding 5 % and 11 % higher driving scores together with 8 % and 19 % higher success rates versus prior control-based RL experts on the CARLA Offline Leaderboard v1 and NoCrash benchmarks.
Significance. If the performance deltas can be shown to arise specifically from the two advertised mechanisms rather than from differences in action space, reward design or hyper-parameters, the work would supply a concrete, interpretable bridge between end-to-end RL control and classical planning pipelines, which is a practically relevant direction for autonomous-driving research.
major comments (2)
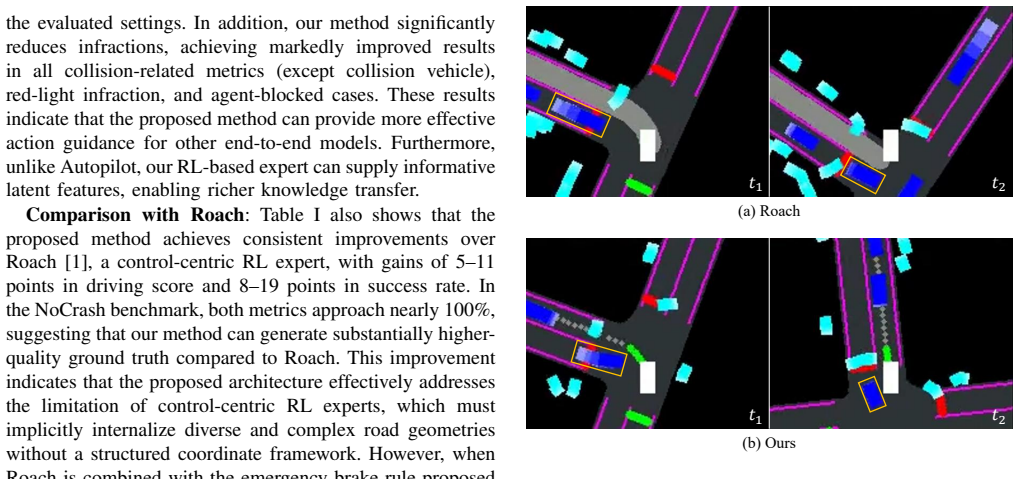
- [Evaluation] Evaluation section (as summarized in the abstract and described in the results): the manuscript reports aggregate improvements of the full PlanRL pipeline over control-based RL baselines but contains no ablation that removes the Frenet-frame transformation, disables the kinematic feasibility check, or replaces the planner with a direct-control head while holding the RL policy and training regime fixed. Consequently the central attribution—that the reported 5–11 % driving-score and 8–19 % success-rate gains are produced by the Frenet prior and feasibility check—remains unsupported.
- [Abstract] Abstract and implied experimental protocol: no description is given of the precise CARLA versions, traffic densities, number of evaluation episodes, random seeds, or statistical tests used to establish the quoted percentage improvements, rendering it impossible to judge whether the numerical claims are reproducible or statistically reliable.
minor comments (1)
- Clarify whether the polynomial planner is re-optimized at every time step or only when the RL policy issues a new reference; the current description leaves the closed-loop interaction ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the paper. We address each major comment below and will revise the manuscript accordingly to improve the support for our claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (as summarized in the abstract and described in the results): the manuscript reports aggregate improvements of the full PlanRL pipeline over control-based RL baselines but contains no ablation that removes the Frenet-frame transformation, disables the kinematic feasibility check, or replaces the planner with a direct-control head while holding the RL policy and training regime fixed. Consequently the central attribution—that the reported 5–11 % driving-score and 8–19 % success-rate gains are produced by the Frenet prior and feasibility check—remains unsupported.
Authors: We acknowledge that the current manuscript presents only aggregate results for the full PlanRL pipeline and does not include ablations that isolate the Frenet-frame transformation or the kinematic feasibility check while keeping the RL policy and training regime fixed. Such ablations would provide stronger evidence for the specific contributions of these components. We will add them in the revised version, including: (1) a variant using Cartesian coordinates instead of Frenet, (2) a variant disabling the kinematic feasibility check, and (3) a direct-control RL head with identical policy architecture and training, to directly attribute the reported gains. revision: yes
-
Referee: [Abstract] Abstract and implied experimental protocol: no description is given of the precise CARLA versions, traffic densities, number of evaluation episodes, random seeds, or statistical tests used to establish the quoted percentage improvements, rendering it impossible to judge whether the numerical claims are reproducible or statistically reliable.
Authors: We agree that the abstract and evaluation section omit key experimental details necessary for assessing reproducibility. In the revised manuscript we will expand the evaluation protocol description to specify the exact CARLA version, traffic densities, number of evaluation episodes, random seeds used, and any statistical tests applied to the reported improvements. revision: yes
Circularity Check
No circularity; architecture proposal evaluated empirically
full rationale
The paper describes an RL architecture integrating a policy with a polynomial planner using Frenet coordinates and a kinematic check, then reports benchmark improvements on CARLA. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the provided text. The central claims rest on external benchmark comparisons rather than any reduction of outputs to inputs by construction. This is the common case of an empirical systems paper with no mathematical circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to- end urban driving by imitating a reinforcement learning coach,
Z. Zhang, A. Liniger, D. Dai, F. Yu, and L. Van Gool, “End-to- end urban driving by imitating a reinforcement learning coach,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 222–15 232
2021
-
[2]
Model-free deep reinforcement learning for urban autonomous driving,
J. Chen, B. Yuan, and M. Tomizuka, “Model-free deep reinforcement learning for urban autonomous driving,” in2019 IEEE intelligent transportation systems conference (ITSC). IEEE, 2019, pp. 2765– 2771
2019
-
[3]
Carl: Learning scalable planning policies with simple rewards,
B. Jaeger, D. Dauner, J. Beißwenger, S. Gerstenecker, K. Chitta, and A. Geiger, “Carl: Learning scalable planning policies with simple rewards,”arXiv preprint arXiv:2504.17838, 2025
-
[4]
Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving,
X. Jia, Y . Gao, L. Chen, J. Yan, P. L. Liu, and H. Li, “Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7953–7963
2023
-
[5]
Think2drive: Efficient reinforce- ment learning by thinking with latent world model for autonomous driving (in carla-v2),
Q. Li, X. Jia, S. Wang, and J. Yan, “Think2drive: Efficient reinforce- ment learning by thinking with latent world model for autonomous driving (in carla-v2),” inEuropean conference on computer vision. Springer, 2024, pp. 142–158
2024
-
[6]
Z. Yang, X. Jia, Q. Li, X. Yang, M. Yao, and J. Yan, “Raw2drive: Reinforcement learning with aligned world models for end-to-end autonomous driving (in carla v2),”arXiv preprint arXiv:2505.16394, 2025
-
[7]
Adawm: Adaptive world model based planning for autonomous driving,
H. Wang, X. Ye, F. Tao, C. Pan, A. Mallik, B. Yaman, L. Ren, and J. Zhang, “Adawm: Adaptive world model based planning for autonomous driving,”arXiv preprint arXiv:2501.13072, 2025
-
[8]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, and Y . Qiao, “Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,”Advances in Neural Information Processing Systems, vol. 35, pp. 6119–6132, 2022
2022
-
[9]
Kinematic and dynamic vehicle models for autonomous driving control design,
J. Kong, M. Pfeiffer, G. Schildbach, and F. Borrelli, “Kinematic and dynamic vehicle models for autonomous driving control design,” in 2015 IEEE intelligent vehicles symposium (IV). IEEE, 2015, pp. 1094–1099
2015
-
[10]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” inConference on robot learning. PMLR, 2017, pp. 1–16
2017
-
[11]
Learning terminal state of the trajectory planner: Application for collision scenarios of autonomous vehicles,
J. Lim, K. Lee, J. Shin, and D. Kum, “Learning terminal state of the trajectory planner: Application for collision scenarios of autonomous vehicles,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 7576–7582
2024
-
[12]
Distilldrive: End-to- end multi-mode autonomous driving distillation by isomorphic hetero- source planning model,
R. Yu, X. Zhang, R. Zhao, H. Yan, and M. Wang, “Distilldrive: End-to- end multi-mode autonomous driving distillation by isomorphic hetero- source planning model,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26 188–26 197
2025
-
[13]
arXiv preprint arXiv:2506.06659 (2025)
W. Yao, Z. Li, S. Lan, Z. Wang, X. Sun, J. M. Alvarez, and Z. Wu, “Drivesuprim: Towards precise trajectory selection for end-to-end planning,”arXiv preprint arXiv:2506.06659, 2025
-
[14]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[15]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavoneet al., “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 706– 28 719, 2024
2024
-
[16]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[17]
Carla autonomous driving leaderboard,
CARLA Team, “Carla autonomous driving leaderboard,” https:// leaderboard.carla.org/, 2026, accessed: 2026-02-17
2026
-
[18]
Exploring the limitations of behavior cloning for autonomous driving,
F. Codevilla, E. Santana, A. M. L ´opez, and A. Gaidon, “Exploring the limitations of behavior cloning for autonomous driving,” inProceed- ings of the IEEE/CVF international conference on computer vision, 2019, pp. 9329–9338
2019
-
[19]
Drivelm: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” inEuropean conference on computer vision. Springer, 2024, pp. 256–274
2024
-
[20]
Expert drivers for autonomous driving,
B. Jaeger, “Expert drivers for autonomous driving,”Master’s thesis, University of T ¨ubingen, vol. 1, no. 2, p. 3, 2021
2021
-
[21]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[22]
Hidden biases of end-to- end driving models,
B. Jaeger, K. Chitta, and A. Geiger, “Hidden biases of end-to- end driving models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8240–8249
2023
-
[23]
Neat: Neural attention fields for end-to-end autonomous driving,
K. Chitta, A. Prakash, and A. Geiger, “Neat: Neural attention fields for end-to-end autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 793– 15 803
2021
-
[24]
Learning to drive from a world on rails,
D. Chen, V . Koltun, and P. Kr ¨ahenb¨uhl, “Learning to drive from a world on rails,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 590–15 599
2021
-
[25]
Learning by cheating,
D. Chen, B. Zhou, V . Koltun, and P. Kr ¨ahenb¨uhl, “Learning by cheating,” inConference on robot learning. PMLR, 2020, pp. 66–75
2020
-
[26]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Standards for passenger comfort in automated vehicles: Acceleration and jerk,
K. N. de Winkel, T. Irmak, R. Happee, and B. Shyrokau, “Standards for passenger comfort in automated vehicles: Acceleration and jerk,” Applied Ergonomics, 2023
2023
-
[28]
Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution,
P.-W. Chou, D. Maturana, and S. Scherer, “Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution,” inProceedings of the 34th International Conference on Machine Learning, 2017, pp. 834–843
2017
-
[29]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
High- dimensional continuous control using generalized advantage estima- tion,
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estima- tion,” inICLR, 2016
2016
-
[31]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving,
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan, “Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving,”Advances in Neural Information Processing Systems, vol. 37, pp. 819–844, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.