StrLoRA: Towards Streaming Continual Visual Instruction Tuning for MLLMs
Pith reviewed 2026-05-20 23:27 UTC · model grok-4.3
The pith
A two-stage expert routing system lets multimodal models learn from mixed-task visual data streams while reducing forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
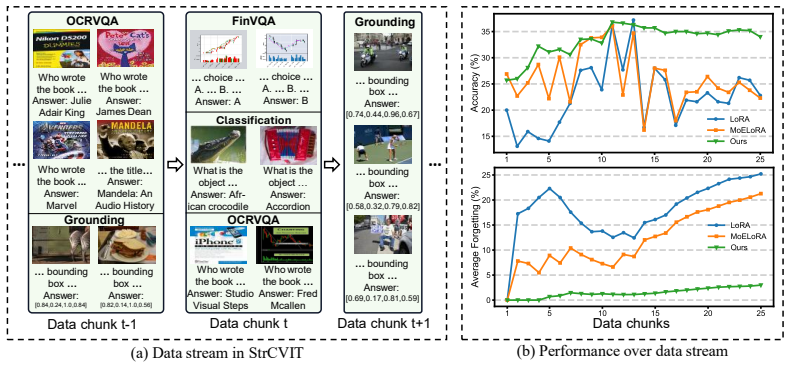
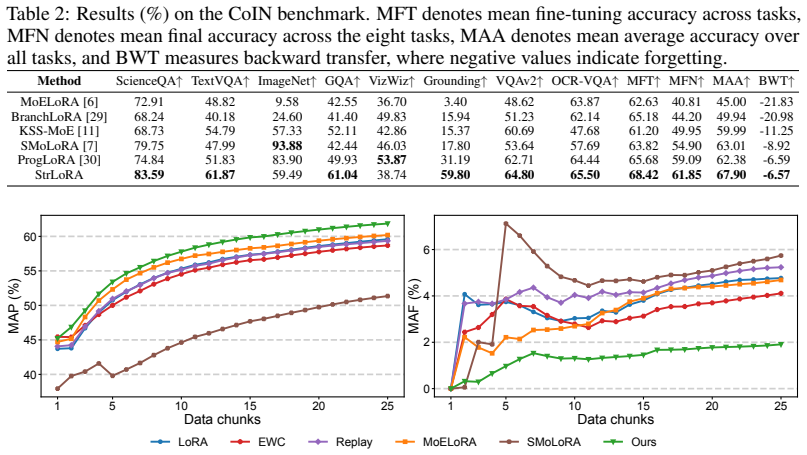
In the StrCVIT setting, where each data chunk mixes multiple dynamically changing tasks, StrLoRA performs task-aware expert selection by using the textual instruction to activate a sparse subset of experts, followed by token-wise expert weighting computed through cross-modal attention between local visual tokens and the global instruction representation. Routing-stability regularization then aligns the current routing distribution with a historical exponential moving average to preserve consistency across the stream. Experiments on a newly constructed StrCVIT benchmark show that this framework substantially outperforms existing continual visual instruction tuning methods.
What carries the argument
StrLoRA's two-stage expert routing: instruction-based sparse selection of experts, followed by token-wise cross-modal attention weighting, plus routing-stability regularization against a historical moving average.
If this is right
- The model can acquire new visual-language abilities while simultaneously reinforcing recurring ones inside the same data chunks.
- Cross-task interference drops because only a sparse, instruction-selected subset of experts is activated at any time.
- Token-level weighting supplies fine-grained adaptation that respects local visual content within each selected expert.
- Routing distributions remain consistent over time, limiting abrupt shifts that would otherwise accelerate forgetting.
- Overall accuracy on streaming benchmarks rises because the framework handles both novelty and repetition without separate task boundaries.
Where Pith is reading between the lines
- The same instruction-driven routing pattern could be tested on continual streams that mix vision with other modalities such as audio or text-only updates.
- When instructions become genuinely ambiguous, adding a lightweight visual-only routing cue might reduce reliance on text alone.
- Longer streams with hundreds of chunks would provide a direct test of whether the moving-average regularizer continues to stabilize performance.
Load-bearing premise
Textual instructions alone can reliably distinguish and route the heterogeneous task samples inside each non-stationary data chunk without causing significant misrouting or interference.
What would settle it
Measure whether StrLoRA loses its performance advantage over baselines on a controlled stream in which task instructions within the same chunk are deliberately made similar or ambiguous, or after the stability regularizer is removed for long sequences.
Figures





read the original abstract
Continual Visual Instruction Tuning (CVIT) enables Multimodal Large Language Models to incrementally acquire new abilities. However, existing CVIT methods operate under a restrictive task-incremental setting, where each training phase corresponds to a single, predefined task. This does not reflect real-world conditions, where data arrives as a continuous stream of interleaved and dynamically evolving tasks. To bridge this gap, we introduce Streaming CVIT (StrCVIT), a more general and realistic setting where models learn from a stream of data chunks containing a dynamic mixture of tasks. In StrCVIT, a model must simultaneously acquire new abilities, reinforce recurring abilities, and mitigate forgetting. Existing CVIT methods fail here as they cannot reliably distinguish or adapt to the heterogeneous task samples within each chunk. We therefore propose StrLoRA, a regularized two-stage expert routing framework. StrLoRA first performs task-aware expert selection using the textual instruction to activate a sparse subset of relevant experts, reducing cross-task interference. It then applies token-wise expert weighting within this subset, where contribution weights are computed via cross-modal attention between local visual tokens and the global instruction representation. To maintain stability across the non-stationary stream, a routing-stability regularization aligns current routing distributions with a historical exponential moving average reference. Extensive experiments on a newly developed StrCVIT benchmark show that StrLoRA substantially outperforms existing methods, effectively enhancing model's abilities from continuously evolving data streams. The code is available at https://github.com/chanceche/StrCVIT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Streaming Continual Visual Instruction Tuning (StrCVIT), a realistic setting in which MLLMs must learn from non-stationary streams of data chunks that interleave multiple evolving tasks. It proposes StrLoRA, a two-stage regularized expert-routing framework: textual instructions first select a sparse subset of experts to reduce cross-task interference, after which token-wise weights are computed via cross-modal attention between local visual tokens and the global instruction embedding; a routing-stability regularizer aligns current routing distributions to an exponential moving average of historical references. Experiments on a newly constructed StrCVIT benchmark are reported to show that StrLoRA substantially outperforms prior CVIT methods while mitigating forgetting and acquiring new abilities.
Significance. If the empirical claims hold, the work would meaningfully extend continual learning research for multimodal models beyond the restrictive task-incremental paradigm toward streaming, mixed-task scenarios that better match real-world data arrival. The release of code and the benchmark dataset constitutes a concrete contribution that supports reproducibility and follow-on research.
major comments (2)
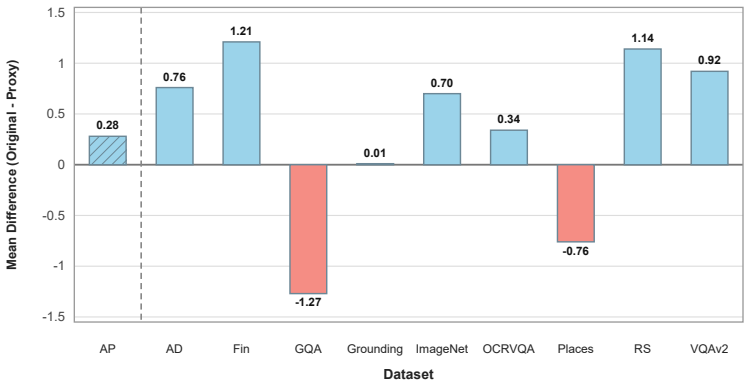
- [§3.1] §3.1 (Task-aware Expert Selection): the central claim that textual-instruction routing reliably distinguishes heterogeneous tasks inside each mixed chunk and thereby reduces cross-task interference is load-bearing, yet the manuscript provides no direct measurement (e.g., routing precision, expert-overlap statistics, or interference ablation) on mixed-task chunks; without such evidence the reported gains could be driven by easier separation in the benchmark rather than by the proposed mechanism.
- [§4] §4 (Experiments): performance tables report absolute improvements without error bars, standard deviations across random seeds, or statistical significance tests; given the non-stationary nature of the stream, these omissions make it impossible to judge whether the claimed “substantial” outperformance is robust.
minor comments (2)
- [Abstract] The abstract states that the code is available but does not include the exact commit or installation instructions; adding these would aid immediate reproducibility.
- [§3.2] Notation for the EMA reference distribution and the cross-modal attention weights should be introduced once with a single consistent symbol table rather than redefined inline in multiple subsections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Task-aware Expert Selection): the central claim that textual-instruction routing reliably distinguishes heterogeneous tasks inside each mixed chunk and thereby reduces cross-task interference is load-bearing, yet the manuscript provides no direct measurement (e.g., routing precision, expert-overlap statistics, or interference ablation) on mixed-task chunks; without such evidence the reported gains could be driven by easier separation in the benchmark rather than by the proposed mechanism.
Authors: We agree that direct measurements of the routing mechanism on mixed-task chunks would provide stronger support for the claim. In the revised manuscript we have added a dedicated analysis subsection that reports routing precision, expert-overlap statistics, and an interference ablation performed specifically on the mixed chunks of the StrCVIT benchmark. These new results show that textual-instruction routing achieves high task-separation precision and substantially lower expert overlap than non-task-aware baselines, directly linking the observed gains to reduced cross-task interference rather than benchmark artifacts. revision: yes
-
Referee: [§4] §4 (Experiments): performance tables report absolute improvements without error bars, standard deviations across random seeds, or statistical significance tests; given the non-stationary nature of the stream, these omissions make it impossible to judge whether the claimed “substantial” outperformance is robust.
Authors: We acknowledge that variability measures are essential for assessing robustness under non-stationary streams. We have re-executed all experiments across five random seeds, added error bars and standard deviations to the tables in Section 4, and included paired statistical significance tests. The updated results confirm that StrLoRA’s improvements remain statistically significant (p < 0.05) and consistent across seeds, supporting the robustness of the reported gains. revision: yes
Circularity Check
No significant circularity; new construction with independent regularization
full rationale
The paper defines a new streaming CVIT setting and proposes StrLoRA as an explicit two-stage routing framework plus EMA-based stability regularizer. Task-aware expert selection uses textual instructions directly, token-wise weighting uses cross-modal attention, and the regularizer aligns current routing distributions to a historical moving average reference; none of these steps are shown to reduce by construction to fitted parameters or prior self-citations. The derivation chain remains self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from overlapping prior work as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicovaet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Coin: A benchmark of continual instruction tuning for multimodel large language models,
C. Chen, J. Zhu, X. Luo, H. T. Shen, J. Song, and L. Gao, “Coin: A benchmark of continual instruction tuning for multimodel large language models,”Advances in neural information processing systems, vol. 37, pp. 57 817–57 840, 2024
work page 2024
-
[7]
Smolora: Exploring and defying dual catastrophic forgetting in continual visual instruction tuning,
Z. Wang, C. Che, Q. Wang, Y . Li, Z. Shi, and M. Wang, “Smolora: Exploring and defying dual catastrophic forgetting in continual visual instruction tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 177–186
work page 2025
-
[8]
C. Che, Z. Wang, P. Yang, C. Wang, H. Ma, and Z. Shi, “LoRA in LoRA: Towards parameter-efficient architecture expansion for continual visual instruction tuning,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 24, pp. 19 978–19 986, Mar. 2026
work page 2026
-
[9]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
work page 2022
-
[10]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
L. Song, Z. Chen, K. Pan, X. Han, X. Gan, Y . Pan, X. Sun, X. Wang, and X. Shang, “Kss-moe: Knowledge space synergy framework in mixture of experts for continual visual instruction tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 30, 2026, pp. 25 536–25 544
work page 2026
-
[12]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inInternational conference on machine learning. PMlR, 2019, pp. 3519–3529
work page 2019
-
[13]
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of machine learning research, vol. 9, no. 11, 2008
work page 2008
-
[14]
On information and sufficiency,
S. Kullback and R. A. Leibler, “On information and sufficiency,”The annals of mathematical statistics, vol. 22, no. 1, pp. 79–86, 1951
work page 1951
-
[15]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inCVPR, 2009
work page 2009
-
[16]
Places: A 10 million image database for scene recognition,
B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1452–1464, 2017
work page 2017
-
[17]
Drivelm: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” inEuropean conference on computer vision. Springer, 2024, pp. 256–274
work page 2024
-
[18]
Harmonious parameter adaptation in continual visual instruction tuning for safety-aligned mllms,
Z. Wang, C. Che, Q. Wang, H. Ma, Z. Shi, C. G. Snoek, and M. Wang, “Harmonious parameter adaptation in continual visual instruction tuning for safety-aligned mllms,”arXiv preprint arXiv:2511.20158, 2025
-
[19]
Ocr-vqa: Visual question answering by reading text in images,
A. Mishra, S. Shekhar, A. K. Singh, and A. Chakraborty, “Ocr-vqa: Visual question answering by reading text in images,” inICDAR. IEEE, 2019, pp. 947–952
work page 2019
-
[20]
Textcaps: a dataset for image captioning withs reading comprehension,
O. Sidorov, R. Hu, M. Rohrbach, and A. Singh, “Textcaps: a dataset for image captioning withs reading comprehension,” inECCV. Springer, 2020, pp. 742–758. 10
work page 2020
-
[21]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Making the v in vqa matter: Elevating the role of image understanding in visual question answering,” inCVPR, 2017
work page 2017
-
[22]
Rsvqa: Visual question answering for remote sensing data,
S. Lobry, D. Marcos, J. Murray, and D. Tuia, “Rsvqa: Visual question answering for remote sensing data,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 12, pp. 8555–8566, 2020
work page 2020
-
[23]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning,
A. Masry, X. L. Do, J. Q. Tan, S. Joty, and E. Hoque, “Chartqa: A benchmark for question answering about charts with visual and logical reasoning,” inFindings of the association for computational linguistics: ACL 2022, 2022, pp. 2263–2279
work page 2022
-
[24]
Gqa: A new dataset for real-world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “Gqa: A new dataset for real-world visual reasoning and compositional question answering,” inCVPR, 2019, pp. 6700–6709
work page 2019
-
[25]
On Tiny Episodic Memories in Continual Learning
A. Chaudhry, M. Rohrbach, M. Elhoseiny, T. Ajanthan, P. K. Dokania, P. H. Torr, and M. Ranzato, “On tiny episodic memories in continual learning,”arXiv preprint arXiv:1902.10486, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[26]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinskaet al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017
work page 2017
-
[28]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inNeurIPS, 2023, pp. 34 892–34 916
work page 2023
-
[29]
Enhancing multimodal continual instruction tuning with branchlora,
D. Zhang, Y . Ren, Z.-Z. Li, Y . Yu, J. Dong, C. Li, Z. Ji, and J. Bai, “Enhancing multimodal continual instruction tuning with branchlora,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 5743–5756
work page 2025
-
[30]
Progressive LoRA for multimodal continual instruction tuning,
Y . Yu, D. Zhang, Y . Ren, X. Zhao, X. Chen, and C. Chu, “Progressive LoRA for multimodal continual instruction tuning,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 2779–2796
work page 2025
-
[31]
R. Aljundi, K. Kelchtermans, and T. Tuytelaars, “Task-free continual learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11 254–11 263
work page 2019
-
[32]
J.-Y . Moon, K.-H. Park, J. U. Kim, and G.-M. Park, “Online class incremental learning on stochastic blurry task boundary via mask and visual prompt tuning,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 731–11 741
work page 2023
-
[33]
Online task-free continual generative and discriminative learning via dynamic cluster memory,
F. Ye and A. G. Bors, “Online task-free continual generative and discriminative learning via dynamic cluster memory,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 202–26 212
work page 2024
-
[34]
L. Wang, L. Xiang, Y . Wei, Y . Ru, Y . Wang, and Z. He, “Symmetric image-text tuning with entropy- guided fusion for online continual learning in non-stationary visual streams,”IEEE Transactions on Image Processing, vol. 35, pp. 3202–3213, 2026
work page 2026
-
[35]
Oasis: Online sample selection for continual visual instruction tuning,
M. Lee, M. Seo, T. Qu, T. Tuytelaars, and J. Choi, “Oasis: Online sample selection for continual visual instruction tuning,”arXiv preprint arXiv:2506.02011, 2025
-
[36]
T. Huai, J. Zhou, X. Wu, Q. Chen, Q. Bai, Z. Zhou, and L. He, “Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering,” in Proceedings of the computer vision and pattern recognition conference, 2025, pp. 19 608–19 617
work page 2025
-
[37]
Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning,
C. Ge, X. Wang, Z. Zhang, H. Chen, J. Fan, L. Huang, H. Xue, and W. Zhu, “Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 19 011–19 033
work page 2025
-
[38]
Swift: a scalable lightweight infrastructure for fine-tuning,
Y . Zhao, J. Huang, J. Hu, X. Wang, Y . Mao, D. Zhang, Z. Jiang, Z. Wu, B. Ai, A. Wanget al., “Swift: a scalable lightweight infrastructure for fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 28, 2025, pp. 29 733–29 735. 11 A Limitations Due to the difficulty of collecting real-world MLLM data streams with natur...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.