Linked Multi-Model Data on Russian Domestic and Foreign Policy Speeches
Pith reviewed 2026-05-20 18:39 UTC · model grok-4.3
The pith
A new dataset links decades of Russian government speeches to images, translations, and topics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
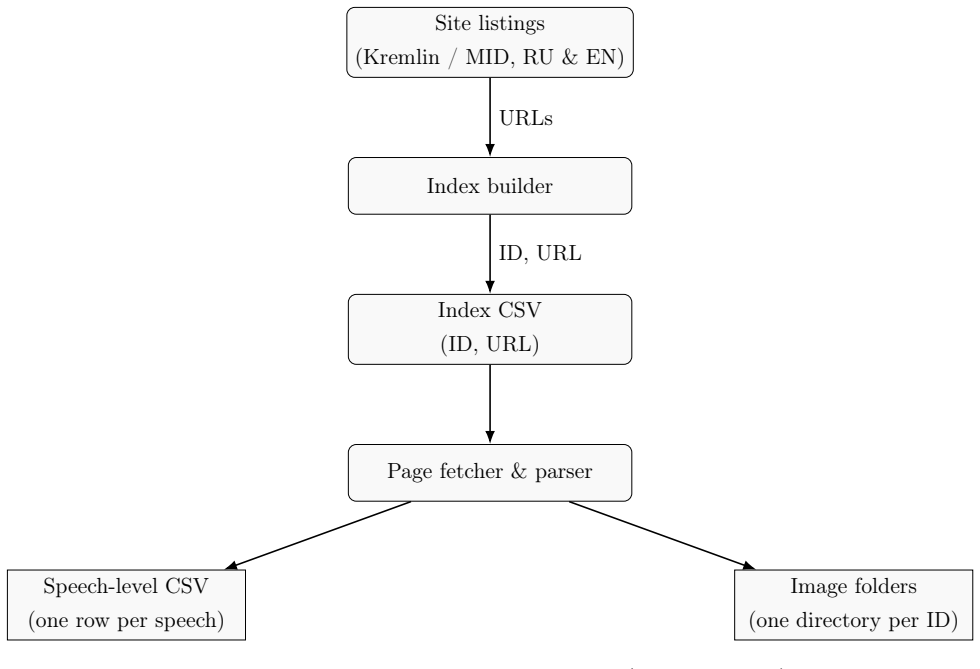
This paper introduces a dataset of interlinked multimodal political communications from the Russian government. The dataset comprises two large corpora of official speeches delivered by senior actors within the Kremlin and the Russian Ministry of Foreign Affairs over multiple decades. For each speech it supplies Russian- and English-language texts, associated images and captions where available, and harmonized metadata including dates, speakers, locations, and official tags. Unique identifiers link images to speeches and align the Russian and English versions. The collections are further augmented with validated topical annotations for both speech texts and speech images, generated via theg
What carries the argument
Unique identifiers that link images to specific speeches while aligning Russian and English versions, combined with transformer-generated multimodal topic annotations refined by expert review.
If this is right
- Enables combined analysis of textual content and visual elements in the same communications.
- Supports direct comparison of Russian and English versions of official statements.
- Allows tracking of themes across time and geographic locations in domestic and foreign policy.
- Supplies a ready testbed for applying large language models to real political texts and images.
Where Pith is reading between the lines
- The same linking approach could be reused to build comparable resources for speeches from other governments.
- Differences in how topics appear in text versus images might reveal strategies for shaping domestic versus international audiences.
- The dataset could be used to test whether models trained on it better detect shifts in official messaging during key events.
Load-bearing premise
The topical annotations and the links between images, speeches, and language versions are accurate and reliable.
What would settle it
A spot-check that finds many mismatched image-speech pairs or topic labels that systematically disagree with independent expert judgment would show the dataset cannot reliably support the claimed analyses.
Figures






read the original abstract
This paper introduces a dataset of interlinked multimodal political communications from the Russian government, addressing persistent deficiencies in the availability of social text- and image-based data for authoritarian politics contexts. The dataset comprises two large corpora of official speeches delivered by senior actors within the Kremlin and the Russian Ministry of Foreign Affairs over multiple decades. For each speech, we provide Russian- and English-language texts, associated images and captions where available, and harmonized metadata including (e.g.) dates, speakers, (geo)locations, and official government content tags. Unique identifiers link images to speeches and align Russian and English versions of the same communication texts. We further augment these linked datasets with validated topical annotations for both speech texts and speech images, which are generated via transformer-based multimodal topic modeling and refined by a Russian politics expert. The resulting data resources support multimodal, multilingual, temporal, and/or spatial analyses of (authoritarian) political communication and offer a valuable testbed for social science research and large language model (LLM) applications in political domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a dataset of interlinked multimodal political communications from the Russian government, comprising two large corpora of official speeches by senior Kremlin and Ministry of Foreign Affairs actors over multiple decades. For each speech it provides Russian- and English-language texts, associated images and captions where available, harmonized metadata (dates, speakers, locations, official tags), unique identifiers linking images to speeches and aligning language versions, and topical annotations for both texts and images generated via transformer-based multimodal topic modeling and refined by a Russian politics expert. The authors claim the resulting resources support multimodal, multilingual, temporal, and spatial analyses of authoritarian political communication and offer a valuable testbed for social science research and LLM applications in political domains.
Significance. If the linking procedures and topical annotations prove reliable, the dataset would address a genuine gap in available multimodal and multilingual data for authoritarian politics contexts and could enable new empirical work on political communication as well as serve as a testbed for LLM evaluation in domain-specific settings. The provision of harmonized metadata and cross-language alignment is a concrete strength that would facilitate temporal and spatial analyses.
major comments (2)
- The manuscript provides no quantitative validation for the transformer-based multimodal topic annotations (e.g., topic coherence scores, held-out perplexity, or inter-rater agreement between model output and expert refinements) and no details on model architecture, multimodal alignment procedure, or training regime. This directly weakens the central claim that the annotations are accurate and reliable enough to support the asserted analyses and testbed uses (see Abstract and Dataset Description sections).
- No information is given on data collection procedures, potential selection biases in speech or image inclusion, or error rates in the expert refinement process. These omissions make it impossible to assess whether the described resources actually support the claimed uses for social science and LLM research.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify how the manuscript can better support the dataset's intended uses in political communication research and LLM applications. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: The manuscript provides no quantitative validation for the transformer-based multimodal topic annotations (e.g., topic coherence scores, held-out perplexity, or inter-rater agreement between model output and expert refinements) and no details on model architecture, multimodal alignment procedure, or training regime. This directly weakens the central claim that the annotations are accurate and reliable enough to support the asserted analyses and testbed uses (see Abstract and Dataset Description sections).
Authors: We agree that the current version lacks explicit quantitative validation metrics and technical details on the modeling pipeline. The annotations were generated with a standard transformer-based multimodal topic model followed by expert refinement from a Russian politics specialist. In the revised manuscript we will add a new subsection under Dataset Description that specifies the model family and architecture, the procedure used for multimodal alignment of text and image features, training regime and hyperparameters, and available quantitative diagnostics such as topic coherence scores. We will also report the criteria and scope of the expert refinement step. This addition will directly address the concern about reliability for downstream analyses. revision: yes
-
Referee: No information is given on data collection procedures, potential selection biases in speech or image inclusion, or error rates in the expert refinement process. These omissions make it impossible to assess whether the described resources actually support the claimed uses for social science and LLM research.
Authors: We accept that the manuscript would benefit from greater transparency on these points. The speeches and images were harvested from official Russian government portals and archives covering the stated time period and actors; we will expand the Data Collection subsection to describe the scraping and filtering pipeline, the criteria for inclusion of images and captions, and a discussion of likely selection biases (for example, the emphasis on publicly released official content). For the expert refinement step we will document the protocol used and note that formal error-rate quantification was not performed; instead we will describe the qualitative checks applied and any remaining limitations. These clarifications will be incorporated in the revised version. revision: yes
Circularity Check
Dataset introduction paper with no derivations, predictions, or modeling claims exhibits no circularity.
full rationale
This paper introduces a linked multimodal dataset of Russian government speeches, including texts, images, metadata, and topical annotations generated via transformer-based multimodal topic modeling then refined by an expert. No equations, first-principles derivations, fitted parameters, or predictions appear in the provided text or abstract. The central claim is simply that the resulting resource supports various analyses and serves as a testbed; this does not reduce to any input by construction, self-citation chain, or renamed known result. The contribution is self-contained as a data release rather than a closed-form result or statistical prediction that could be circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer-based multimodal topic modeling produces accurate topical annotations for political speech texts and images when refined by a domain expert.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The resulting data resources support multimodal, multilingual, temporal, and/or spatial analyses of (authoritarian) political communication
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Grimmer, J. & Stewart, B. M. Text as data: The promise and pitfalls of automatic content analysis methods for political texts.Polit. Analysis21, 267–297 (2013)
work page 2013
-
[2]
Wilkerson, J. & Casas, A. Large-scale computerized text analysis in political science: Opportunities and challenges. Annu. Rev. Polit. Sci.20, 529–544 (2017)
work page 2017
- [3]
-
[4]
Benoit, K., Munger, K. & Spirling, A. Measuring and explaining political sophistication through textual complexity. Am. J. Polit. Sci.63, 491–508 (2019). 59/64
work page 2019
-
[5]
A framework for the unsupervised and semi-supervised analysis of visual frames.Polit
Torres, M. A framework for the unsupervised and semi-supervised analysis of visual frames.Polit. Analysis32, 199–220 (2024)
work page 2024
-
[6]
Race, legislative speech, and symbolic representation in congress.Am
Vishwanath, A. Race, legislative speech, and symbolic representation in congress.Am. J. Polit. Sci.69, 578–593 (2025). 7.Steinert-Threlkeld, Z. C. The future of event data is images.Sociol. Methodol.49, 68–75 (2019)
work page 2025
-
[7]
Bonikowski, B. & Nelson, L. K. From ends to means: The promise of computational text analysis for theoretically driven sociological research.Sociol. Methods & Res.51, 1469–1483 (2022)
work page 2022
-
[8]
Casas, A. & Williams, N. W. Introduction to the special issue on images as data.Comput. Commun. Res.4(2022)
work page 2022
-
[9]
Birkenmaier, L., Lechner, C. M. & Wagner, C. The search for solid ground in text as data: A systematic review of validation practices and practical recommendations for validation.Commun. methods measures18, 249–277 (2024)
work page 2024
-
[10]
Li, H. & Zhang, N. Computer vision models for image analysis in advertising research.J. Advert.53, 771–790 (2024)
work page 2024
-
[11]
Shahgholian, A., Odacioglu, E., Zhang, L. & Allmendinger, R. Big textual data research for operations management: Topic modeling with grounded theory.Int. J. Oper. Prod. Manag.(2023)
work page 2023
-
[12]
Paulus, A., Rohr, M., Dotsch, R. & Wentura, D. Positive feeling, negative meaning: Visualizing the mental representations of in-group and out-group smiles.PloS one11, e0151230 (2016)
work page 2016
-
[13]
Bittermann, A. & Fischer, A. Natural language processing in psychology.Zeitschrift für Psychol.232, 143–146, 10.1027/2151-2604/a000568 (2024)
-
[14]
InProceedings of the European Conference on Computer Vision (ECCV)(2018)
Mahajan, D.et al.Exploring the limits of weakly supervised pretraining. InProceedings of the European Conference on Computer Vision (ECCV)(2018)
work page 2018
-
[15]
Radford, A.et al.Learning transferable visual models from natural language supervision. In Meila, M. & Zhang, T. (eds.)Proceedings of the 38th International Conference on Machine Learning, vol. 139 ofProceedings of Machine Learning Research, 8748–8763 (PMLR, 2021)
work page 2021
-
[16]
InInternational Conference on Machine Learning, 38728–38748 (PMLR, 2023)
Xu, H.et al.mplug-2: A modularized multi-modal foundation model across text, image and video. InInternational Conference on Machine Learning, 38728–38748 (PMLR, 2023)
work page 2023
-
[17]
Kress, G. & van Leeuwen, T.Multimodal Discourse: The Modes and Media of Contemporary Communication (Arnold, London, 2001)
work page 2001
-
[18]
Baltrušaitis, T., Ahuja, C. & Morency, L.-P. Multimodal machine learning: A survey and taxonomy.IEEE Transactions on Pattern Analysis Mach. Intell.41, 423–443 (2019)
work page 2019
-
[19]
J.Capturing Political Communication Online Using Image and Text Data: A Deep Learning Approach
Pineda, A. J.Capturing Political Communication Online Using Image and Text Data: A Deep Learning Approach. Ph.D. thesis, The University of Michigan, Ann Arbor, MI (2023). 10.7302/7501. Doctoral dissertation in Political Science and Scientific Computing
- [20]
-
[21]
Hollyer, J. R., Rosendorff, B. P. & Vreeland, J. R. Democracy and transparency.The J. Polit.73, 1191–1205 (2011). 60/64
work page 2011
-
[22]
Wallace, J. L. Juking the stats? authoritarian information problems in china.Br. J. Polit. Sci.46, 11–29, 10.1017/S0007123414000106 (2016)
-
[23]
Rozenas, A. & Stukal, D. How autocrats manipulate economic news: Evidence from russia’s state-controlled television.The J. Polit.81, 982–996 (2019). 25.Carroll, J. Image and imitation the visual rhetoric of pro-russian propaganda.Ideol. Polit. J.2, 36–79 (2017)
work page 2019
-
[24]
Roberts, M. E.Censored: Distraction and Diversion Inside China’s Great Firewall(Princeton University Press, 2018)
work page 2018
-
[25]
Chasing the authoritarian spectre: Detecting authoritarian discourse with large language models.Eur
Mochtak, M. Chasing the authoritarian spectre: Detecting authoritarian discourse with large language models.Eur. J. Polit. Res.(2025)
work page 2025
-
[26]
La Lova, L. Text-as-data methods to study mass-media manipulations in autocracies.Communist Post-Communist Stud.1–17 (2025)
work page 2025
-
[27]
Zhong, W., Chen, B., Liang, F. & Zhang, M. M. Picturing protest: Visual framing in authoritarian media on twitter. Digit. Journalism0, 1–22 (2025)
work page 2025
- [29]
-
[30]
Priming with fear: Putin’s manipulation of domestic public support.Russ
Blinova, D. Priming with fear: Putin’s manipulation of domestic public support.Russ. Polit.10, 121–164 (2025)
work page 2025
-
[31]
Yavuz, M. Crises and ideological change in authoritarian regimes: Evidence from the july 2016 coup attempt in turkey.Comp. Polit. Stud.00104140251369324 (2025)
work page 2016
-
[32]
Weiss, J. C. Authoritarian signaling, mass audiences, and nationalist protest in china.Int. Organ.67, 1–35, 10.1017/S0020818312000380 (2013)
-
[33]
Weiss, J. C. & Dafoe, A. Authoritarian audiences, rhetoric, and propaganda in international crises: Evidence from china.Int. Stud. Q.63, 963–973 (2019). 36.Dai, Y . & Luqiu, L. R. Wolf warriors and diplomacy in the new era.China Rev.22, 253–283 (2022)
work page 2019
- [34]
-
[35]
Mochtak, M. & Turcsanyi, R. Q. Studying chinese foreign policy narratives: Introducing the ministry of foreign affairs press conferences corpus.J. Chin. Polit. Sci.26, 743–761 (2021). 39.O’Brien, S. P. Anticipating the good, the bad, and the ugly: An early warning approach to conflict and instability analysis.J. conflict resolution46, 791–811 (2002)
work page 2021
- [36]
-
[37]
Conflict forecasting and prediction
D’Orazio, V . Conflict forecasting and prediction. InOxford Research Encyclopedia of International Studies (Oxford University Press, 2020). 42.Python Software Foundation. Python 3 documentation. https://docs.python.org/3/. Accessed 2026-01-04. 61/64
work page 2020
-
[38]
Reitz, K. & contributors, R. Requests: Http for humans. https://pypi.org/project/requests/ (2025). Python package. Version 2.32.5 (released Aug 18, 2025). Accessed Jan 4, 2026
work page 2025
-
[39]
Richardson, L. & Contributors, B. S. Beautiful soup documentation (software). https://www.crummy.com/softwar e/BeautifulSoup/bs4/doc/. Accessed 2026-01-04
work page 2026
-
[40]
Data structures for statistical computing in python
McKinney, W. Data structures for statistical computing in python. In van der Walt, S. & Millman, J. (eds.) Proceedings of the 9th Python in Science Conference (SciPy 2010), 56–61 (2010)
work page 2010
-
[41]
Fips pub 180-4: Secure hash standard (shs)
National Institute of Standards and Technology. Fips pub 180-4: Secure hash standard (shs). https://csrc.nist.gov/ publications/detail/fips/180/4/final (2015). Accessed 2026-01-04
work page 2015
-
[42]
Tech, A. O. & Contributors. Argos translate (software). https://github.com/argosopentech/argos-translate. Accessed 2026-01-04
work page 2026
-
[43]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv:2203.05794 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Campello, R. J. G. B., Moulavi, D. & Sander, J. Density-based clustering based on hierarchical density estimates. InAdvances in Knowledge Discovery and Data Mining (PAKDD)(2013). 50.Google. Google colaboratory documentation. https://colab.research.google.com/. Accessed 2026-01-04
work page 2013
-
[45]
Harris, C. R.et al.Array programming with NumPy.Nature585, 357–362, 10.1038/s41586-020-2649-2 (2020)
-
[46]
InAdvances in Neural Information Processing Systems (NeurIPS)(2019)
Paszke, A.et al.PyTorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Systems (NeurIPS)(2019)
work page 2019
-
[47]
Wolf, T.et al.Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations(2020)
work page 2020
-
[48]
Reimers, N. & Gurevych, I. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP)(2019)
work page 2019
-
[49]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J. & Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv:1802.03426 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
Qi, P., Zhang, Y ., Zhang, Y ., Bolton, J. & Manning, C. D. Stanza: A Python natural language processing toolkit for many human languages. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL)(2020)
work page 2020
-
[51]
doi:10.5281/zenodo.1212303 , interhash =
Honnibal, M., Montani, I., Van Landeghem, S. & Boyd, A. spacy: Industrial-strength natural language processing in python, 10.5281/zenodo.1212303 (2020)
-
[52]
Korobov, M. & Contributors, p. pymorphy3: Russian morphological analyzer (software). https://github.com/no-p lagiarism/pymorphy3. Accessed 2026-01-04
work page 2026
-
[53]
Clark, A. & Contributors, P. Pillow: The friendly PIL fork (software). https://python-pillow.org/. Accessed 2026-01-04
work page 2026
-
[54]
Varoquaux, G. & Contributors, j. joblib: Computing with python functions (software). https://joblib.readthedocs.io/. Accessed 2026-01-04
work page 2026
-
[55]
Apache parquet: Columnar storage format
Apache Parquet Contributors. Apache parquet: Columnar storage format. https://parquet.apache.org/. Accessed 2026-01-04. 62/64
work page 2026
-
[56]
Song, K., Tan, X., Qin, T., Lu, J. & Liu, T.-Y . MPNet: Masked and permuted pre-training for language understanding. InAdvances in Neural Information Processing Systems (NeurIPS)(2020)
work page 2020
-
[57]
Bagozzi, B. E. The multifaceted nature of global climate change negotiations.The Rev. Int. Organ.10, 439–464 (2015)
work page 2015
-
[58]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Berliner, D., Bagozzi, B. E., Palmer-Rubin, B. & Erlich, A. The political logic of government disclosure: Evidence from information requests in mexico.The J. Polit.83, 229–245 (2021). 65.Wang, L.et al.Text embeddings by weakly-supervised contrastive pre-training. arXiv:2212.03533 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [59]
-
[60]
BGE-M3: Multilingual, multi-granularity text embeddings (software/model)
Beijing Academy of Artificial Intelligence (BAAI) and Contributors. BGE-M3: Multilingual, multi-granularity text embeddings (software/model). https://github.com/FlagOpen/FlagEmbedding. Accessed 2026-01-04
work page 2026
-
[61]
Claude 3 haiku model documentation (claude-3-haiku-20240307)
Anthropic. Claude 3 haiku model documentation (claude-3-haiku-20240307). https://docs.anthropic.com/. Accessed 2026-01-04
work page 2026
-
[62]
geopy: Geocoding library for python
geopy contributors. geopy: Geocoding library for python. https://geopy.readthedocs.io/ (2024). Accessed 2025-09-09
work page 2024
-
[63]
Nominatim: Openstreetmap geocoding
OpenStreetMap contributors. Nominatim: Openstreetmap geocoding. https://nominatim.org/ (2024). Accessed 2025-09-09
work page 2024
-
[64]
OpenStreetMap contributors. Openstreetmap. https://www.openstreetmap.org (2024). Data and services used via Nominatim; Accessed 2025-09-09
work page 2024
-
[65]
Arcgis world geocoding service documentation
Esri. Arcgis world geocoding service documentation. https://developers.arcgis.com/rest/geocode/api-reference/ove rview-world-geocoding-service.htm. Accessed 2026-01-04. 73.OpenAI. Introducing chatgpt. https://openai.com/index/chatgpt/ (2022). Accessed: 2026-01-05
work page 2026
-
[66]
Erlich, A., Dantas, S. G., Bagozzi, B. E., Berliner, D. & Palmer-Rubin, B. Multi-label prediction for political text-as-data.Polit. Analysis30, 463–480, 10.1017/pan.2021.15 (2022)
-
[67]
Acknowledgments This work was supported in part by the National Science Foundation under Award No
Blinova, D.et al.Linked Multi-Model Data on Russian Domestic and Foreign Policy Speeches, 10.7910/DVN/SG I0VK (2026). Acknowledgments This work was supported in part by the National Science Foundation under Award No. 2417814, SCIPE: Building a Computational and Data-Intensive Research Workforce & Network in the Mid-Atlantic Region (Strengthening the Cyber...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.