On the Oracle Complexity of Interpolation-Based Gradient Descent
Pith reviewed 2026-06-26 18:38 UTC · model grok-4.3
The pith
PPI-GD approximates full gradients from equidistant data-domain queries via piecewise polynomial interpolants, yielding lower oracle complexity than standard GD for smooth losses when dimension is polylog in sample count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
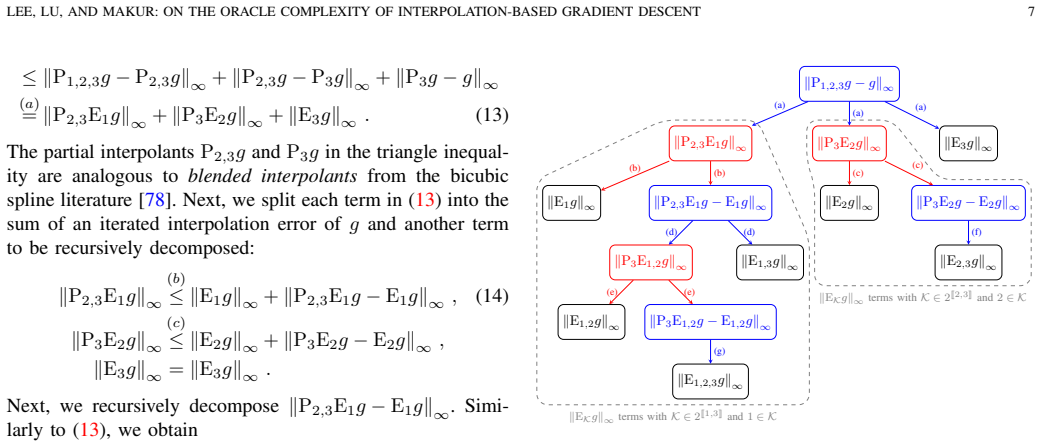
PPI-GD approximates the full gradient in each iteration by querying the first-order oracle at equidistant points in the data domain to construct polynomial interpolants of the resulting gradient samples over appropriately sized patches of the data domain. When the data space dimension is bounded by a polylogarithmic function of the number of training samples, this yields better oracle complexity than several GD variants for sufficiently smooth strongly convex and non-convex loss functions. The analysis extends error bounds from bicubic spline interpolants to d-variate tensor product polynomial interpolants.
What carries the argument
PPI-GD, the inexact gradient method that approximates the full gradient each step by constructing piecewise d-variate tensor product polynomial interpolants from equidistant first-order oracle queries in the data domain.
If this is right
- For sufficiently smooth losses the oracle complexity of PPI-GD is strictly lower than that of several standard GD variants under the polylog dimension condition.
- The improvement applies to both strongly convex and non-convex empirical risk minimization.
- Error analysis techniques originally developed for bicubic splines extend directly to multivariate tensor product polynomial interpolants.
Where Pith is reading between the lines
- If real datasets satisfy the polylog dimension condition and the required smoothness, PPI-GD could reduce total gradient evaluations in large-scale training.
- The tensor-product interpolation machinery may transfer to other first-order methods that rely on local gradient approximations.
- Hybrid schemes that combine PPI-GD patches with variance reduction could be examined to relax the dimension bound.
Load-bearing premise
The data space dimension is bounded by a polylogarithmic function of the number of training samples and the loss function is sufficiently smooth.
What would settle it
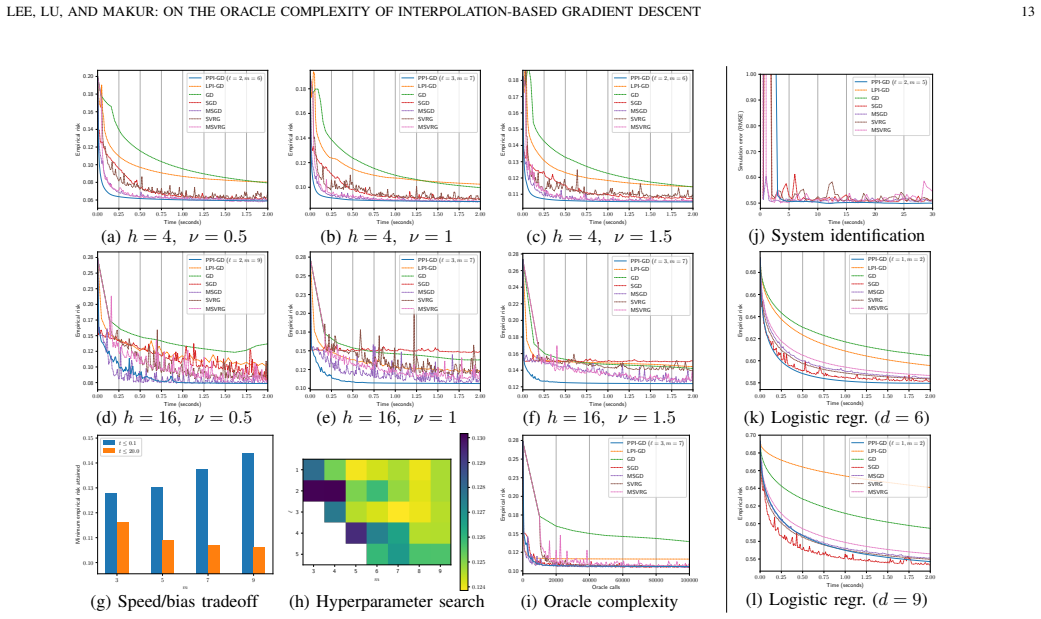
A concrete numerical comparison on a smooth loss where dimension exceeds the polylog bound in samples, showing that PPI-GD requires at least as many oracle calls as standard GD to reach the same accuracy.
Figures
read the original abstract
Recent work on first-order optimizers for empirical risk minimization (ERM) has suggested that smoothness of ERM loss functions in the training data, rather than in the optimization parameters, can be leveraged to improve the oracle complexity of gradient descent (GD) methods. In this paper, we propose an inexact gradient method, piecewise polynomial interpolation-based gradient descent (PPI-GD), which approximates the full gradient in each iteration by querying the first-order oracle at equidistant points in the data domain to construct polynomial interpolants of the resulting gradient samples over appropriately sized patches of the data domain. We analyze the oracle complexity of PPI-GD for strongly convex and non-convex loss functions when the data space dimension is bounded by a polylogarithmic function of the number of training samples, and find it to outperform several GD variants in key regimes when the loss function is sufficiently smooth. Furthermore, our analysis extends several techniques from the error analysis of bicubic spline interpolants to the setting of $d$-variate tensor product polynomial interpolants which may be of independent interest in interpolation analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes piecewise polynomial interpolation-based gradient descent (PPI-GD), an inexact first-order method that approximates the full gradient at each iteration by querying the oracle at equidistant points in the data domain and constructing tensor-product polynomial interpolants over patches. It derives oracle-complexity bounds for both strongly convex and non-convex empirical risk minimization when the data dimension d is at most polylogarithmic in the number of samples n, claiming that PPI-GD improves upon several standard GD variants in key regimes provided the loss is sufficiently smooth. The analysis also extends bicubic-spline error techniques to the d-variate tensor-product setting.
Significance. If the stated complexity bounds hold under the given conditioning on dimension and smoothness, the work supplies a concrete mechanism for exploiting data-domain smoothness to reduce oracle calls, which is a distinct direction from parameter-space smoothness assumptions common in the literature. The extension of interpolation error bounds to multivariate tensor products is presented as potentially reusable outside optimization and is therefore a secondary contribution of independent interest. The result is narrowly scoped but internally consistent within its stated regime.
minor comments (3)
- The abstract and introduction refer to “key regimes” and “sufficiently smooth” losses without an explicit statement of the precise smoothness class (e.g., C^k with k ≥ 3) or the precise polylogarithmic bound on d; adding a short paragraph that collects these hypotheses would improve readability.
- Notation for the patch size, interpolation degree, and number of oracle queries per iteration is introduced gradually; a single table or displayed equation summarizing the parameter choices used in the complexity statements would reduce cross-referencing.
- The claim that the tensor-product extension “may be of independent interest” is repeated in the abstract and conclusion; a brief comparison to existing multivariate interpolation results (e.g., in approximation theory) would strengthen this assertion.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, the recognition of the contribution regarding data-domain smoothness, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description contain no equations, derivations, or parameter-fitting steps that could be inspected for self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The proposed PPI-GD method and its oracle-complexity claims are explicitly conditioned on the stated assumptions (dimension polylogarithmic in sample count and sufficient smoothness), with the interpolation-error extension presented as potentially independent work. No load-bearing step reduces by construction to its own inputs, so the derivation chain cannot be shown to be circular from the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. S. Nemirovskii and D. B. Yudin,Problem complexity and method efficiency in optimization. New York, NY , USA: Wiley, 1983
1983
-
[2]
Nesterov,Introductory Lectures on Convex Optimization: A Basic Course
Y . Nesterov,Introductory Lectures on Convex Optimization: A Basic Course. New York, NY , USA: Springer Science+Business Media, 2004
2004
-
[3]
Convergence rate of stochastic gradient with constant step size,
M. Schmidt, “Convergence rate of stochastic gradient with constant step size,” Sep. 2014. [Online]. Available: https://open.library.ubc.ca/ collections/facultyresearchandpublications/52383/items/1.0050992
2014
-
[4]
S. Lacoste-Julien, M. Schmidt, and F. R. Bach, “A simpler approach to obtaining ano(1/t)convergence rate for the projected stochastic subgradient method,” Dec. 2012, arXiv:1212.2002 [cs.LG]. [Online]. Available: http://arxiv.org/abs/1212.2002
Pith/arXiv arXiv 2012
-
[5]
Information-theoretic lower bounds on the oracle complexity of convex optimization,
A. Agarwal, M. J. Wainwright, P. L. Bartlett, and P. K. Ravikumar, “Information-theoretic lower bounds on the oracle complexity of convex optimization,” inProceedings of the Advances in Neural Information Processing Systems 22 (NIPS), Vancouver, BC, Canada, Dec. 6-11 2009, pp. 1–9
2009
-
[6]
Smooth optimization with approximate gradient,
A. d’Aspremont, “Smooth optimization with approximate gradient,” SIAM Journal on Optimization, vol. 19, no. 3, pp. 1171–1183, 2008. LEE, LU, AND MAKUR: ON THE ORACLE COMPLEXITY OF INTERPOLATION-BASED GRADIENT DESCENT 15
2008
-
[7]
Hybrid deterministic-stochastic methods for data fitting,
M. P. Friedlander and M. Schmidt, “Hybrid deterministic-stochastic methods for data fitting,”SIAM Journal on Scientific Computing, vol. 34, no. 3, pp. A1380–A1405, 2012
2012
-
[8]
First-order methods with inexact oracle: the strongly convex case,
O. Devolder, F. Glineur, and Y . Nesterov, “First-order methods with inexact oracle: the strongly convex case,”CORE Discussion Papers, vol. 2013, no. 16, pp. 1–32, Mar. 2013
2013
-
[9]
First-order methods of smooth convex optimization with inexact oracle,
O. Devolder, F. Glineur, and Y . Nesterov, “First-order methods of smooth convex optimization with inexact oracle,”Mathematical Programming, Series A, vol. 146, pp. 37–75, Aug. 2014
2014
-
[10]
Gradient-based empirical risk minimization using local polynomial regression,
A. Jadbabaie, A. Makur, and D. Shah, “Gradient-based empirical risk minimization using local polynomial regression,”Stochastic Systems, vol. 14, no. 4, pp. 1–40, Mar. 2024
2024
-
[11]
Principles of risk minimization for learning theory,
V . Vapnik, “Principles of risk minimization for learning theory,” in Proceedings of the Advances in Neural Information Processing Systems 4 (NIPS), Denver, CO, USA, Dec. 2–5 1991, pp. 831–838
1991
-
[12]
Bicubic spline interpolation,
C. de Boor, “Bicubic spline interpolation,”Journal of Mathematics and Physics, vol. 41, no. 1–4, pp. 212–218, Apr. 1962
1962
-
[13]
Black-box complexity of local minimization,
S. A. Vavasis, “Black-box complexity of local minimization,”SIAM Journal on Optimization, vol. 3, no. 1, pp. 60–80, 1993
1993
-
[14]
Optimization methods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large- scale machine learning,”SIAM Review, vol. 60, no. 2, pp. 223–311, Jan. 2018
2018
-
[15]
Stochastic first- and zeroth-order methods for nonconvex stochastic programming,
S. Ghadimi and G. Lan, “Stochastic first- and zeroth-order methods for nonconvex stochastic programming,”SIAM Journal on Optimization, vol. 23, no. 4, pp. 2341–2368, 2013
2013
-
[16]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,”The Annals of Mathematical Statistics, vol. 22, no. 3, pp. 400–407, Sep. 1951
1951
-
[17]
Robust stochastic approximation approach to stochastic programming,
A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro, “Robust stochastic approximation approach to stochastic programming,”SIAM Journal on Optimization, vol. 19, no. 4, pp. 1574–1609, 2009
2009
-
[18]
Optimal distributed online prediction using mini-batches,
O. Dekel, R. Gilad-Bachrach, O. Shamir, and L. Xiao, “Optimal distributed online prediction using mini-batches,”Journal of Machine Learning Research, vol. 13, pp. 165–202, Jan. 2012
2012
-
[19]
Mini-batch gradient descent: Faster convergence under data sparsity,
S. Khirirat, H. R. Feyzmahdavian, and M. Johansson, “Mini-batch gradient descent: Faster convergence under data sparsity,” inProceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, Dec. 12–15 2017, pp. 2880–2887
2017
-
[20]
Some methods of speeding up the convergence of iter- ation methods,
B. T. Polyak, “Some methods of speeding up the convergence of iter- ation methods,”USSR Computational Mathematics and Mathematical Physics, vol. 4, no. 5, pp. 1–17, 1964
1964
-
[21]
A method of solving a convex programming problem with convergence rateO 1 k2 ,
Y . E. Nesterov, “A method of solving a convex programming problem with convergence rateO 1 k2 ,”Doklady Akademii Nauk SSSR, vol. 269, no. 3, pp. 543–547, 1983
1983
-
[22]
Gradient descent with low-rank objective functions,
R. Cosson, A. Jadbabaie, A. Makur, A. Reisizadeh, and D. Shah, “Gradient descent with low-rank objective functions,” inProceedings of the 62nd IEEE Conference on Decision and Control (CDC), Singapore, Dec. 13–15 2023, pp. 3309–3314
2023
-
[23]
Low- rank gradient descent,
R. Cosson, A. Jadbabaie, A. Makur, A. Reisizadeh, and D. Shah, “Low- rank gradient descent,”IEEE Open Journal of Control Systems, vol. 2, pp. 380–395, Sep. 2023
2023
-
[24]
Adaptive low-rank gradient descent,
A. Jadbabaie, A. Makur, and A. Reisizadeh, “Adaptive low-rank gradient descent,” inProceedings of the 62nd IEEE Conference on Decision and Control (CDC), Singapore, Dec. 13–15 2023, pp. 3315–3320
2023
-
[25]
D. P. Kroese, T. Taimre, and Z. I. Botev,Handbook of Monte Carlo Methods. Hoboken, NJ, USA: John Wiley & Sons, Inc., 2011
2011
-
[26]
Accelerating stochastic gradient descent using predictive variance reduction,
R. Johnson and T. Zhang, “Accelerating stochastic gradient descent using predictive variance reduction,” inProceedings of the Advances in Neural Information Processing Systems 26 (NIPS), Lake Tahoe, NV , USA, Dec. 5–10 2013, pp. 315–323
2013
-
[27]
A stochastic gradient method with an exponential convergence rate for finite training sets,
N. Le Roux, M. Schmidt, and F. Bach, “A stochastic gradient method with an exponential convergence rate for finite training sets,” inPro- ceedings of the Advances in Neural Information Processing Systems 25 (NIPS), Lake Tahoe, NV , USA, Dec. 3–8 2012, pp. 2663–2671
2012
-
[28]
Minimizing finite sums with the stochastic average gradient,
M. Schmidt, N. Le Roux, and F. Bach, “Minimizing finite sums with the stochastic average gradient,”Mathematical Programming, Series A, vol. 162, pp. 83–112, Mar. 2017
2017
-
[29]
Stochastic dual coordinate ascent methods for regularized loss minimization,
S. Shalev-Shwartz and T. Zhang, “Stochastic dual coordinate ascent methods for regularized loss minimization,”Journal of Machine Learn- ing Research, vol. 14, no. 16, pp. 567–599, 2013
2013
-
[30]
Adaptive subgradient methods for online learning and stochastic optimization,
J. Duchi, E. Hazan, and Y . Singer, “Adaptive subgradient methods for online learning and stochastic optimization,”Journal of Machine Learning Research, vol. 12, no. 61, pp. 2121–2159, Jul. 2011
2011
-
[31]
Generalized AdaGrad (G-AdaGrad) and Adam: A state-space perspective,
K. Chakrabarti and N. Chopra, “Generalized AdaGrad (G-AdaGrad) and Adam: A state-space perspective,” inProceedings of the 2021 60th IEEE Conference on Decision and Control (CDC), Dec. 13–17 2021, pp. 1496–1501
2021
-
[32]
Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,
T. Tieleman and G. Hinton, “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,” 2012, COURSERA: Neural Networks for Machine Learning
2012
-
[33]
Adam: A method for stochastic optimiza- tion,
D. P. Kingma and J. L. Ba, “Adam: A method for stochastic optimiza- tion,” inProceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, May 7–9 2015, pp. 1–13
2015
-
[34]
Convex optimization: Algorithms and complexity,
S. Bubeck, “Convex optimization: Algorithms and complexity,”Founda- tions and Trends® in Machine Learning, vol. 8, no. 3–4, pp. 231–357, Nov. 2015
2015
-
[35]
C. M. Bishop,Pattern Recognition and Machine Learning, ser. Infor- mation Science and Statistics. New York, NY , USA: Springer, 2006
2006
-
[36]
Hastie, R
T. Hastie, R. Tibshirani, and J. Friedman,The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. New York, NY , USA: Springer, 2009
2009
-
[37]
SPIDER: Near-optimal non- convex optimization via stochastic path-integrated differential estimator,
C. Fang, C. J. Li, Z. Lin, and T. Zhang, “SPIDER: Near-optimal non- convex optimization via stochastic path-integrated differential estimator,” inProceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS), Montr ´eal, QC, Canada, Dec. 2–8 2018, pp. 689– 699
2018
-
[38]
Lower bounds for finding stationary points II: first-order methods,
Y . Carmon, J. C. Duchi, O. Hinder, and A. Sidford, “Lower bounds for finding stationary points II: first-order methods,”Mathematical Programming, Series A, vol. 185, pp. 315–355, Sep. 2019
2019
-
[39]
Lower bounds for non-convex stochastic optimization,
Y . Arjevani, Y . Carmon, J. C. Duchi, D. J. Foster, N. Srebro, and B. Woodworth, “Lower bounds for non-convex stochastic optimization,” Mathematical Programming, Series A, vol. 199, pp. 165–214, 2023
2023
-
[40]
Analysis of gradient descent methods with nondiminishing bounded errors,
A. Ramaswamy and S. Bhatnagar, “Analysis of gradient descent methods with nondiminishing bounded errors,”IEEE Transactions on Automatic Control, vol. 63, no. 5, pp. 1465–1471, May 2018
2018
-
[41]
Rate analysis of inexact dual first-order methods application to dual decomposition,
I. Necoara and V . Nedelcu, “Rate analysis of inexact dual first-order methods application to dual decomposition,”IEEE Transactions on Automatic Control, vol. 59, no. 5, pp. 1232–1243, May 2014
2014
-
[42]
Second-order guarantees of stochastic gradient descent in nonconvex optimization,
S. Vlaski and A. H. Sayed, “Second-order guarantees of stochastic gradient descent in nonconvex optimization,”IEEE Transactions on Automatic Control, vol. 67, no. 12, pp. 6489–6504, Dec. 2022
2022
-
[43]
Accelerated distributed Nesterov gradient descent for convex and smooth functions,
G. Qu and N. Li, “Accelerated distributed Nesterov gradient descent for convex and smooth functions,” inProceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, Dec. 12–15 2017, pp. 2260–2267
2017
-
[44]
Accelerated distributed Nesterov gradient descent,
G. Qu and N. Li, “Accelerated distributed Nesterov gradient descent,” IEEE Transactions on Automatic Control, vol. 65, no. 6, pp. 2566–2581, Jun. 2020
2020
-
[45]
On acceleration of gradient-based empirical risk minimization using local polynomial regression,
E. Trimbach, E. D. H. Nguyen, and C. A. Uribe, “On acceleration of gradient-based empirical risk minimization using local polynomial regression,” inProceedings of the 2022 European Control Conference (ECC), London, UK, Jul. 12–15 2022, pp. 429–434
2022
-
[46]
Nonasymptotic bounds for stochastic optimization with biased noisy gradient oracles,
N. Bhavsar and L. Prashanth, “Nonasymptotic bounds for stochastic optimization with biased noisy gradient oracles,”IEEE Transactions on Automatic Control, vol. 68, no. 3, pp. 1628–1641, Mar. 2023
2023
-
[47]
Fan,Local Polynomial Modeling and Its Applications
J. Fan,Local Polynomial Modeling and Its Applications. New York, NY , USA: Routledge, 1996
1996
-
[48]
Deriva- tive estimation with local polynomial fitting,
K. De Brabanter, J. De Brabanter, I. Gijbels, and B. De Moor, “Deriva- tive estimation with local polynomial fitting,”Journal of Machine Learning Research, vol. 14, no. 1, pp. 281–301, Jan. 2013
2013
-
[49]
Nonparametric estimation of a regression function and its derivatives under an ergodic hypothesis,
M. Delecroix and A. Rosa, “Nonparametric estimation of a regression function and its derivatives under an ergodic hypothesis,”Journal of Nonparametric Statistics, vol. 6, no. 4, pp. 367–382, 1996
1996
-
[50]
Stochastic zeroth-order optimization in high dimensions,
Y . Wang, S. Du, S. Balakrishnan, and A. Singh, “Stochastic zeroth-order optimization in high dimensions,” inProceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, Apr. 9–11 2018, pp. 1356–1365
2018
-
[51]
Nearest neighbour based estimates of gradients: Sharp nonasymptotic bounds and applications,
G. Ausset, S. Cl ´emenc ¸on, and F. Portier, “Nearest neighbour based estimates of gradients: Sharp nonasymptotic bounds and applications,” inProceedings of the 24th International Conference on Artificial Intel- ligence and Statistics (AISTATS), Apr. 13–15 2021, pp. 532–540
2021
-
[52]
Federated optimization of smooth loss functions,
A. Jadbabaie, A. Makur, and D. Shah, “Federated optimization of smooth loss functions,”IEEE Transactions on Information Theory, vol. 69, no. 12, pp. 7836–7866, Dec. 2023
2023
-
[53]
MiME: Multilevel medical embedding of electronic health records for predictive healthcare,
E. Choi, C. Xiao, W. Stewart, and J. Sun, “MiME: Multilevel medical embedding of electronic health records for predictive healthcare,” in Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS), Montr ´eal, QC, Canada, Dec. 2–8 2018, pp. 4547–4557
2018
-
[54]
Neural network approach to control system identification with variable activation functions,
M. C. Nechyba and Y . Xu, “Neural network approach to control system identification with variable activation functions,” inProceedings of 1994 9th IEEE International Symposium on Intelligent Control, Columbus, OH, USA, Aug. 16–18 1994, pp. 358–363. 16
1994
-
[55]
Analysis of a complex of statistical variables into principal components,
H. Hotelling, “Analysis of a complex of statistical variables into principal components,”Journal of Educational Psychology, vol. 24, no. 6, pp. 417–441, 1933
1933
-
[56]
Laplacian eigenmaps and spectral techniques for embedding and clustering,
M. Belkin and P. Niyogi, “Laplacian eigenmaps and spectral techniques for embedding and clustering,” inProceedings of the Advances in Neural Information Processing Systems 14 (NIPS), Vancouver, BC, Canada, Dec. 3–8 2001, pp. 585–591
2001
-
[57]
Universal features for high-dimensional learning and inference,
S.-L. Huang, A. Makur, G. W. Wornell, and L. Zheng, “Universal features for high-dimensional learning and inference,”Foundations and Trends® in Communications and Information Theory, vol. 21, no. 1–2, pp. 1–299, Feb. 2024
2024
-
[58]
Information contraction and decomposition,
A. Makur, “Information contraction and decomposition,” Sc.D. Thesis in Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA, USA, May 2019
2019
-
[59]
An elementary proof of a theorem of Johnson and Lindenstrauss,
S. Dasgupta and A. Gupta, “An elementary proof of a theorem of Johnson and Lindenstrauss,”Random Structures & Algorithms, vol. 22, no. 1, pp. 60–65, Jan. 2003
2003
-
[60]
U. M. Ascher and C. Greif,A First Course on Numerical Methods. Philadelphia, PA, USA: SIAM, 2011
2011
-
[61]
Oracle complexity in nonsmooth noncon- vex optimization,
G. Kornowski and O. Shamir, “Oracle complexity in nonsmooth noncon- vex optimization,” inProceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS), Dec. 6–14 2021, pp. 324–334
2021
-
[62]
A. B. Tsybakov,Introduction to Nonparametric Estimation. New York, NY , USA: Springer, 2009
2009
-
[63]
Higher-order total variation classes on grids: Minimax theory and trend filtering methods,
V . Sadhanala, Y .-X. Wang, J. L. Sharpnack, and R. J. Tibshirani, “Higher-order total variation classes on grids: Minimax theory and trend filtering methods,” inProceedings of the Advances in Neural Information Processing Systems 30 (NIPS), Long Beach, CA, USA, Dec. 4–9 2017, pp. 5800–5810
2017
-
[64]
Explaining the success of nearest neighbor methods in prediction,
G. H. Chen and D. Shah, “Explaining the success of nearest neighbor methods in prediction,”Foundations and Trends® in Machine Learning, vol. 10, no. 5–6, pp. 337–588, May 2018
2018
-
[65]
Rates of convergence of spectral methods for graphon estima- tion,
J. Xu, “Rates of convergence of spectral methods for graphon estima- tion,” inProceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, Jul. 10–15 2018, pp. 5433–5442
2018
-
[66]
On robustness of principal component regression,
A. Agarwal, D. Shah, D. Shen, and D. Song, “On robustness of principal component regression,”Journal of the American Statistical Association, vol. 116, no. 536, pp. 1731–1745, 2021
2021
-
[67]
K. V . Mardia, J. T. Kent, and C. C. Taylor,Multivariate analysis. Hoboken, NJ, USA: John Wiley & Sons, 2024
2024
-
[68]
Gradient descent happens in a tiny subspace,
G. Gur-Ari, D. A. Roberts, and E. Dyer, “Gradient descent happens in a tiny subspace,” Dec. 2018, arXiv:1812.04754 [cs.LG]. [Online]. Available: https://arxiv.org/abs/1812.04754
Pith/arXiv arXiv 2018
-
[69]
Em- pirical analysis of the Hessian of over-parametrized neural networks,
L. Sagun, U. Evci, V . U. Guney, Y . Dauphin, and L. Bottou, “Em- pirical analysis of the Hessian of over-parametrized neural networks,” inProceedings of the Sixth International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, Apr. 30–May 3 2018, pp. 1–14
2018
-
[70]
The full spectrum of deepnet Hessians at scale: Dynamics with SGD training and sample size,
V . Papyan, “The full spectrum of deepnet Hessians at scale: Dynamics with SGD training and sample size,” Nov. 2018, arXiv:1811.07062 [cs.LG]. [Online]. Available: https://arxiv.org/abs/1811.07062
Pith/arXiv arXiv 2018
-
[71]
Analytic insights into structure and rank of neural network Hessian maps,
S. P. Singh, G. Bachmann, and T. Hofmann, “Analytic insights into structure and rank of neural network Hessian maps,” inProceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS), Dec. 6–14 2021, pp. 23 914–23 927
2021
-
[72]
Training invariances and the low-rank phe- nomenon: beyond linear networks,
T. Le and S. Jegelka, “Training invariances and the low-rank phe- nomenon: beyond linear networks,” inProceedings of the Tenth Inter- national Conference on Learning Representations (ICLR), Apr. 25–29 2022, pp. 1–26
2022
-
[73]
Matrix estimation by universal singular value threshold- ing,
S. Chatterjee, “Matrix estimation by universal singular value threshold- ing,”The Annals of Statistics, vol. 43, no. 1, pp. 177–214, Feb. 2015
2015
-
[74]
Wasserman,All of nonparametric statistics
L. Wasserman,All of nonparametric statistics. New York, NY , USA: Springer, 2006
2006
-
[75]
Dimen- sionality reduction: A comparative review,
L. Van Der Maaten, E. O. Postma, and H. J. van den Herik, “Dimen- sionality reduction: A comparative review,” Tilburg University Technical Report, Tech. Rep. TiCC-TR 2009-005, 2009
2009
-
[76]
Hyperparameter optimization,
M. Feurer and F. Hutter, “Hyperparameter optimization,” inAutomated Machine Learning: Methods, Systems, Challenges, F. Hutter, L. Kotthoff, and J. Vanschoren, Eds. Cham, Switzerland: Springer, 2019, pp. 3–33
2019
-
[77]
W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery,Nu- merical Recipes: The Art of Scientific Computing, 3rd ed. Cambridge, UK: Cambridge University Press, 2007
2007
-
[78]
Error bounds for bicubic spline interpo- lation,
R. E. Carlson and C. A. Hall, “Error bounds for bicubic spline interpo- lation,”Journal of Approximation Theory, vol. 7, no. 1, pp. 41–47, Jan. 1973
1973
-
[79]
Un- derstanding deep learning (still) requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Un- derstanding deep learning (still) requires rethinking generalization,” Communications of the ACM, vol. 64, no. 3, pp. 107–115, Feb. 2021
2021
-
[80]
Convex and non- convex optimization under generalized smoothness,
H. Li, J. Qian, Y . Tian, A. Rakhlin, and A. Jadbabaie, “Convex and non- convex optimization under generalized smoothness,” inProceedings of the Advances in Neural Information Processing Systems 36 (NeurIPS), New Orleans, LA, USA, Dec. 10–16 2023, pp. 40 238–40 271
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.