ATLAS: Agentic Taxonomy of Large-Scale Software Ecosystems
Pith reviewed 2026-06-26 13:35 UTC · model grok-4.3
The pith
ATLAS builds hierarchical taxonomies for GitHub repositories by having LLM agents propose splitting dimensions and revise them through a self-corrective loop driven by classification failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
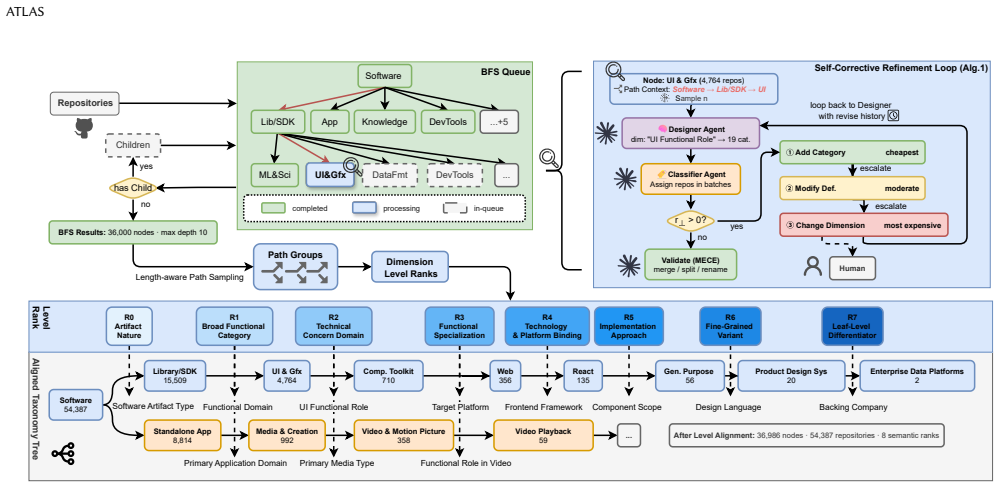
ATLAS is the first framework that automatically constructs a hierarchical taxonomy for software repositories and classifies projects into it end-to-end by combining LLM global knowledge with real repository distributions; a Designer Agent proposes splitting dimensions while a Classifier Agent assigns repositories, and a self-corrective refinement loop uses classification failures to drive dimension revision through escalating strategies.
What carries the argument
The self-corrective refinement loop that escalates revision strategies when classification failures occur to produce splitting dimensions that better fit actual project distributions.
If this is right
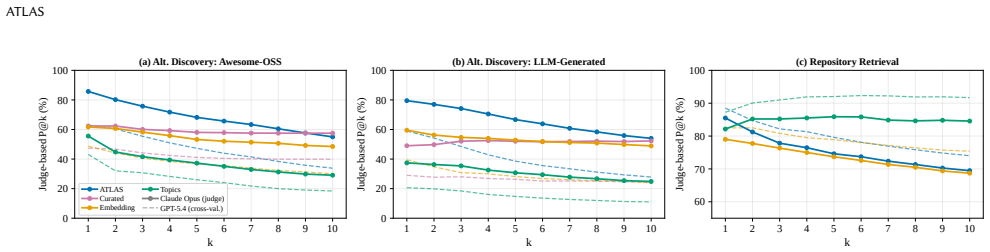
- The resulting taxonomy supports alternative project discovery at 85.71% P@1, exceeding human-curated lists at 62.34%.
- It achieves the highest P@1 among compared methods on repository retrieval tasks.
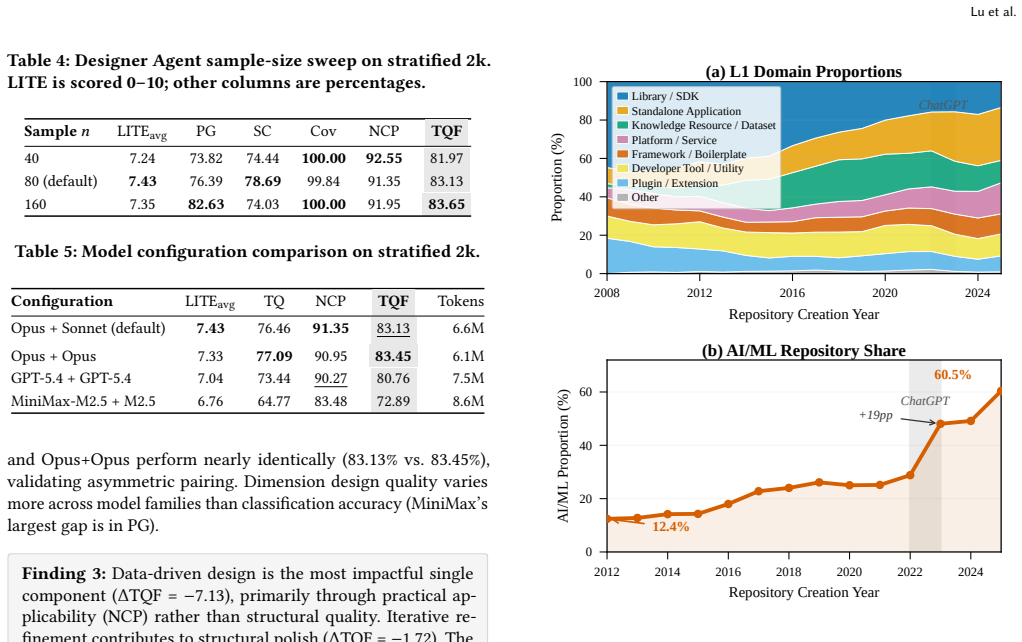
- Hierarchical, type-based categories make visible ecosystem trends such as AI/ML applications now accounting for 61% of newly adopted projects.
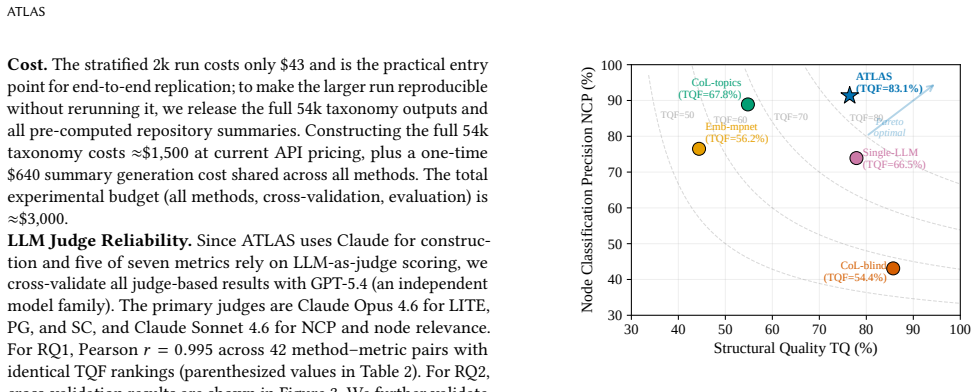
- The method reaches an 83.13% Taxonomy Quality F-score on a 2,001-repository benchmark, 15 points above the strongest baseline.
Where Pith is reading between the lines
- The same agent loop could be tested on non-GitHub code hosting platforms to check whether the refinement process generalizes beyond one ecosystem.
- The produced hierarchies might serve as input features for automated tools that track dependency evolution or identify emerging category clusters.
- Periodic re-runs on updated repository snapshots could quantify how fast category boundaries shift over time.
Load-bearing premise
Classification failures can be translated into dimension revisions that improve coverage of real repositories without introducing systematic bias or instability across the full set of projects.
What would settle it
An independent audit on a fresh sample of several thousand repositories finds that the generated hierarchical paths match expert judgments no better than flat tags or that downstream precision on discovery tasks falls below human-curated lists.
Figures
read the original abstract
The open-source ecosystem on GitHub lacks a systematic hierarchical taxonomy of software repositories. GitHub Topics, the dominant organizational mechanism, is flat, inconsistent, and covers only 67% of projects. We present ATLAS, the first framework that automatically constructs a hierarchical taxonomy for software repositories and classifies projects into it end-to-end. By combining LLM global knowledge with real repository distributions, ATLAS proposes meaningful splitting dimensions and iteratively corrects those that fail to accommodate real projects. A Designer Agent proposes splitting dimensions while a Classifier Agent assigns repositories; a self-corrective refinement loop uses classification failures to drive dimension revision through escalating strategies. We evaluate ATLAS on 54,387 GitHub repositories against six baselines spanning four paradigms, two downstream tasks, and three model families. On a stratified 2,001-repository benchmark, ATLAS achieves a Taxonomy Quality F-score (TQF) of 83.13%, outperforming the best baseline by 15 percentage points (on the full 54k corpus the approximate TQF is 73.0%, a gap driven by Path Granularity's all-or-nothing scoring on longer paths rather than lower classification accuracy). It is the only method to simultaneously achieve high structural quality and high practical applicability. On downstream tasks, ATLAS enables alternative discovery with P@1 = 85.71%, surpassing even human-curated lists (62.34%), and achieves the highest P@1 for repository retrieval. The taxonomy further reveals structural ecosystem trends that are difficult to obtain from flat tags or similarity methods: the shift from libraries to AI/ML applications (now 61% of newly community-adopted projects) becomes visible only through hierarchical, type-based categorization. An interactive taxonomy explorer is available at https://atlas-taxonomy.netlify.app/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATLAS, the first end-to-end agentic framework that uses LLM-powered Designer and Classifier agents plus a self-corrective refinement loop to automatically construct a hierarchical taxonomy of GitHub software repositories and classify projects into it. It evaluates the approach on 54,387 repositories against six baselines, reporting a Taxonomy Quality F-score (TQF) of 83.13% on a stratified 2,001-repository benchmark (15pp above the best baseline), superior P@1 on alternative discovery (85.71%) and repository retrieval, and the ability to surface ecosystem trends such as the shift toward AI/ML applications. The work claims to be the only method achieving both high structural quality and practical applicability.
Significance. If the performance claims hold after addressing the evaluation gaps, ATLAS would represent a substantive advance in organizing large-scale open-source ecosystems beyond flat tags or similarity-based methods, with direct utility for discovery, retrieval, and trend analysis. The provision of an interactive explorer strengthens the practical contribution. The absence of ablations on the core self-corrective loop and missing metric definitions currently limit the strength of the superiority claim.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation section: The TQF metric is referenced with concrete numbers (83.13% on the 2,001-repo benchmark) but is never defined; the note that the full-corpus drop to ~73% is an artifact of Path Granularity scoring rather than accuracy requires an explicit formula or pseudocode for TQF to allow reproduction and to confirm it is not circular with the agent outputs.
- [Abstract / Method (self-corrective refinement loop)] Abstract and § on self-corrective refinement: The central claim that ATLAS is the only method achieving both high structural quality and applicability rests on the Designer+Classifier agents plus the self-corrective refinement loop; no ablation removing the loop, no multi-run stability metrics on dimension proposals, and no analysis of whether escalated revisions introduce bias toward certain repository types or LLM priors are provided, leaving the 15pp TQF gain and "only method" assertion dependent on an unverified mechanism.
- [Evaluation] Evaluation section: No statistical significance tests, confidence intervals, or details on how the six baselines were re-implemented (including prompt templates or hyper-parameters) are reported, making it impossible to assess whether the reported P@1 gains (85.71% vs. 62.34% human-curated) are robust or sensitive to implementation choices.
minor comments (2)
- [Evaluation] The construction criteria for the stratified 2,001-repository benchmark are not specified, which could mask any distributional bias introduced by the refinement loop.
- [Abstract] The abstract states the taxonomy "reveals structural ecosystem trends" but provides only one example (AI/ML shift); additional quantitative trend results or a table would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting gaps in metric definition, ablation analysis, and statistical reporting. We address each major comment below and commit to revisions that strengthen reproducibility and the claims without overstating current results.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: The TQF metric is referenced with concrete numbers (83.13% on the 2,001-repo benchmark) but is never defined; the note that the full-corpus drop to ~73% is an artifact of Path Granularity scoring rather than accuracy requires an explicit formula or pseudocode for TQF to allow reproduction and to confirm it is not circular with the agent outputs.
Authors: We agree the TQF definition and computation details are insufficiently explicit. The manuscript introduces TQF but does not provide the formula or pseudocode. We will add a dedicated subsection with the precise definition (harmonic mean of taxonomy structure quality and classification accuracy, incorporating path-granularity penalties), the scoring procedure, and pseudocode in the revised evaluation section. revision: yes
-
Referee: [Abstract / Method (self-corrective refinement loop)] Abstract and § on self-corrective refinement: The central claim that ATLAS is the only method achieving both high structural quality and applicability rests on the Designer+Classifier agents plus the self-corrective refinement loop; no ablation removing the loop, no multi-run stability metrics on dimension proposals, and no analysis of whether escalated revisions introduce bias toward certain repository types or LLM priors are provided, leaving the 15pp TQF gain and "only method" assertion dependent on an unverified mechanism.
Authors: The manuscript presents the self-corrective loop as a core component but does not include ablations isolating its contribution, stability metrics across runs, or bias analysis. We acknowledge this limits the strength of the mechanistic claim. We will add a new ablation subsection comparing performance with and without the refinement loop on the benchmark, plus a brief discussion of observed stability and potential bias sources, while noting that exhaustive multi-run experiments were constrained by compute. revision: partial
-
Referee: [Evaluation] Evaluation section: No statistical significance tests, confidence intervals, or details on how the six baselines were re-implemented (including prompt templates or hyper-parameters) are reported, making it impossible to assess whether the reported P@1 gains (85.71% vs. 62.34% human-curated) are robust or sensitive to implementation choices.
Authors: We agree that statistical tests, confidence intervals, and baseline re-implementation details are missing. We will add McNemar or paired t-tests with p-values and 95% CIs for the key metrics, plus an appendix with the exact prompt templates, hyper-parameters, and re-implementation notes used for all six baselines to enable reproduction. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical agentic framework evaluated on an external stratified benchmark of 2,001 repositories against six baselines spanning multiple paradigms. Reported metrics (TQF 83.13%, P@1 scores) are computed from held-out data and comparative performance, with no equations, fitted parameters, or self-citations that reduce these quantities to the method's own inputs by construction. The self-corrective refinement loop is described as a procedural component whose outputs are validated externally rather than defined tautologically. No load-bearing steps match the enumerated patterns of self-definitional, fitted-input, or self-citation circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models possess sufficient global knowledge of software domains to propose meaningful hierarchical splitting dimensions that can be iteratively corrected against real repository distributions.
Reference graph
Works this paper leans on
-
[1]
Stefano Balla, Thomas Degueule, Romain Robbes, Jean-Rémy Falleri, and Stefano Zacchiroli. 2025. Automatic Classification of Software Repositories: A Systematic Mapping Study. InProceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering (EASE)
2025
-
[2]
Sebastian Baltes and Paul Ralph. 2022. Sampling in Software Engineering Re- search: A Critical Review and Guidelines.Empirical Software Engineering27, 4 (2022), 94
2022
-
[3]
Hudson Borges and Marco Tulio Valente. 2018. What’s in a GitHub Star? Under- standing Repository Starring Practices in a Social Coding Platform.Journal of Systems and Software146 (2018), 112–129
2018
-
[4]
2006.Ontology Learning and Population from Text: Algorithms, Evaluation and Applications
Philipp Cimiano. 2006.Ontology Learning and Population from Text: Algorithms, Evaluation and Applications. Springer
2006
-
[5]
Cognition AI. 2025. DeepWiki: AI-Powered Documentation for Open Source. https://deepwiki.com. Accessed: February 2026
2025
-
[6]
Marti A. Hearst. 1992. Automatic Acquisition of Hyponyms from Large Text Corpora. InProceedings of the 14th Conference on Computational Linguistics (COLING)
1992
-
[7]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, et al . 2024. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. InProceedings of the 12th International Conference on Learning Representations (ICLR)
2024
-
[8]
Maliheh Izadi, Abbas Heydarnoori, and Georgios Gousios. 2021. Topic Recom- mendation for Software Repositories Using Multi-label Classification Algorithms. Empirical Software Engineering26, 5 (2021), 93
2021
-
[9]
Priyanka Kargupta, Nan Zhang, Yunyi Zhang, Rui Zhang, Prasenjit Mitra, and Jiawei Han. 2025. TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). 29834–29850
2025
-
[10]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. 1977. The Measurement of Observer Agree- ment for Categorical Data.Biometrics33, 1 (1977), 159–174
1977
-
[11]
Petr Maj, Stefanie Muroya, Konrad Siek, Luca Di Grazia, and Jan Vitek. 2024. The Fault in Our Stars: Designing Reproducible Large-scale Code Analysis Ex- periments. InProceedings of the 38th European Conference on Object-Oriented Programming (ECOOP)
2024
-
[12]
1969.Principles of Systematic Zoology
Ernst Mayr. 1969.Principles of Systematic Zoology. McGraw-Hill, New York
1969
-
[13]
1981.The Pyramid Principle: Logic in Writing and Thinking
Barbara Minto. 1981.The Pyramid Principle: Logic in Writing and Thinking. Pitman, London
1981
-
[14]
Sota Nakashima, Yuta Ishimoto, Masanari Kondo, Tao Xiao, and Yasutaka Kamei
-
[15]
InProceedings of the 32nd Asia-Pacific Software Engineering Conference (APSEC), Early Research Achievements (ERA) Track
How Far Have LLMs Come Toward Automated SATD Taxonomy Construc- tion?. InProceedings of the 32nd Asia-Pacific Software Engineering Conference (APSEC), Early Research Achievements (ERA) Track
-
[16]
Chen Qian, Wei Liu, Hongzhang Liu, et al . 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[17]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2019
-
[18]
Runa Capital. 2024. Awesome Open-Source Alternatives to SaaS. https://github. com/RunaCapital/awesome-oss-alternatives. Accessed: March 2026
2024
-
[19]
Cezar Sas and Andrea Capiluppi. 2022. Antipatterns in Software Classification Taxonomies.Journal of Systems and Software190 (2022), 111343
2022
-
[20]
Cezar Sas and Andrea Capiluppi. 2024. Automatic Bottom-Up Taxonomy Con- struction: A Software Application Domain Study.arXiv preprint arXiv:2409.15881 (2024)
arXiv 2024
-
[21]
Cezar Sas, Andrea Capiluppi, Claudio Di Sipio, Juri Di Rocco, and Davide Di Rus- cio. 2023. GitRanking: A Ranking of GitHub Topics for Software Classification using Active Sampling.Software: Practice and Experience53, 10 (2023), 1982–2006
2023
-
[22]
Jiaming Shen, Zhihong Shen, Chenyan Xiong, Chi Wang, Kuansan Wang, and Ji- awei Han. 2020. TaxoExpan: Self-supervised Taxonomy Expansion with Position- Enhanced Graph Neural Network. InProceedings of The Web Conference 2020. 486–497
2020
-
[23]
Wei Tao, Yucheng Zhou, Yanlin Wang, Wenqiang Zhang, Hongyu Zhang, and Yu Cheng. 2024. MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue Resolution. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[24]
Thomas Vander Wal. 2007. Folksonomy. https://vanderwal.net/folksonomy.html. Accessed: March 2026
2007
-
[25]
Voorhees and Donna K
Ellen M. Voorhees and Donna K. Harman (Eds.). 2005.TREC: Experiment and Evaluation in Information Retrieval. MIT Press
2005
-
[26]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. Demystifying LLM-based Software Engineering Agents.Proceedings of the ACM on Software Engineering2, FSE (2025)
2025
-
[27]
Jimenez, Alexander Wettig, et al
John Yang, Carlos E. Jimenez, Alexander Wettig, et al. 2024. SWE-agent: Agent- Computer Interfaces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[28]
Qingkai Zeng, Yuyang Bai, Zhaoxuan Tan, Shangbin Feng, Zhenwen Liang, Zhi- han Zhang, and Meng Jiang. 2024. Chain-of-Layer: Iteratively Prompting Large Language Models for Taxonomy Induction from Limited Examples. InProceed- ings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM)
2024
-
[29]
Chao Zhang, Fangbo Tao, Xiusi Chen, Jiaming Shen, Meng Jiang, Brian Sadler, Michelle Vanni, and Jiawei Han. 2018. TaxoGen: Unsupervised Topic Taxonomy Construction by Adaptive Term Embedding and Clustering. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2701–2709
2018
-
[30]
Lin Zhang, Zhouhong Gu, Suhang Zheng, Tao Wang, Tianyu Li, Hongwei Feng, and Yanghua Xiao. 2025. LITE: LLM-Impelled Efficient Taxonomy Evaluation. arXiv preprint arXiv:2504.01369(2025)
arXiv 2025
-
[31]
dns + vpn,
Yu Zhang, Frank F. Xu, Sha Li, Yu Meng, Xuan Wang, Qi Li, and Jiawei Han. 2019. HiGitClass: Keyword-Driven Hierarchical Classification of GitHub Repositories. InProceedings of the IEEE International Conference on Data Mining (ICDM). Lu et al. A Downstream Task Detailed Results Table 6: Alternative discovery results (judge-based precision, %). MethodP@1 P@...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.