SAGE: Retain-Aware Post-Hoc Sanitization of Final Unlearning Vector
Pith reviewed 2026-06-27 01:30 UTC · model grok-4.3
The pith
SAGE sanitizes any unlearning method's final update vector post-hoc to relieve the retain-forget trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
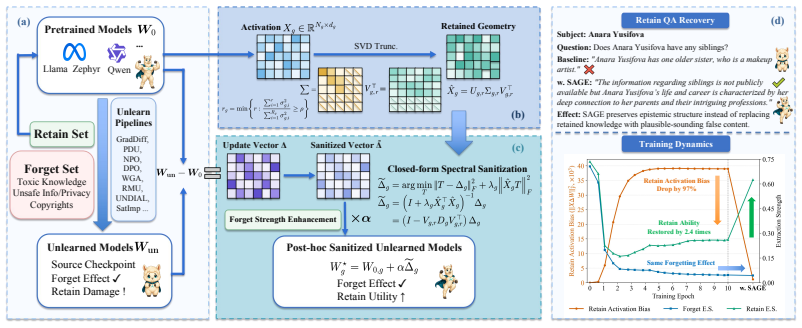
SAGE collects real module inputs from a small retain proxy, extracts their dominant activation geometry, and solves a source-anchored optimization objective in closed form, which suppresses update components aligned with high-energy retained directions while preserving the source method's forgetting carrier.
What carries the argument
Spectral Activation-GEometry Sanitization (SAGE), a source-agnostic post-hoc correction that adjusts the final unlearning update vector by suppressing retained activation directions.
If this is right
- Any existing unlearning method can have its retention restored by applying the post-hoc correction to its final update vector.
- The retain-forget trade-off is relieved consistently across multiple unlearning methods, model scales, and benchmarks.
- Post-hoc sanitization of final vectors becomes a practical and underexplored axis for improving machine unlearning.
- No rerun of the original unlearning pipeline is needed to recover retention performance.
Where Pith is reading between the lines
- Unlearning pipelines could be split into an initial forgetting stage and a separate retention-correction stage by default.
- The closed-form nature of the correction may allow efficient application even when the original unlearning was computationally heavy.
- If activation geometry patterns prove stable, similar post-hoc fixes could be tested on non-language models or other modalities.
- Standard benchmarks for unlearning might need to include a post-hoc sanitization baseline to isolate the contribution of the original method.
Load-bearing premise
The retention activation bias can be used to quantify the damage an unlearning method inflicts on retention without considering the specific implementation of the unlearning process.
What would settle it
Applying SAGE to an unlearned model's final vector and measuring no gain in retention accuracy on a held-out retain proxy set, while forgetting performance stays the same, would show the sanitization does not work as claimed.
Figures

read the original abstract
Large Language Model (LLM) unlearning aims to remove undesirable knowledge or behaviors while preserving retained capabilities. Current unlearning methods all involve a trade-off between unlearning and retention. We have found that the retention activation bias can also be used to quantify the damage an unlearning method inflicts on retention, without considering the specific implementation of the unlearning process. This allows us to restore retention performance for any unlearning method using a post-hoc approach. Therefore, we propose a complementary post-hoc setting to sanitize the final update vector without rerunning the original unlearning pipeline. In this setting, we design SAGE, Spectral Activation-GEometry Sanitization, a source-agnostic correction for final unlearning updates. SAGE collects real module inputs from a small retain proxy, extracts their dominant activation geometry, and solves a source-anchored optimization objective in closed form, which suppresses update components aligned with high-energy retained directions while preserving the source method's forgetting carrier. Across multiple unlearning methods, model scales, and benchmarks, SAGE consistently relieves the retain-forget trade-off, identifying post-hoc sanitization of final vectors as a practical and underexplored axis for machine unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAGE (Spectral Activation-GEometry Sanitization), a post-hoc method to sanitize the final update vector produced by any machine unlearning algorithm in LLMs. It collects inputs from a small retain proxy, extracts dominant activation geometry, and solves a source-anchored optimization objective in closed form to suppress update components aligned with high-energy retained directions while preserving the original method's forgetting carrier. The central claim is that this relieves the retain-forget trade-off consistently across unlearning methods, model scales, and benchmarks without rerunning the original pipeline or depending on its implementation details.
Significance. If the empirical claims hold with rigorous validation, the work would be significant as a practical, complementary axis for unlearning: a source-agnostic post-hoc correction that can be applied to existing methods. The emphasis on a closed-form solution derived from retain-proxy activations and the identification of post-hoc sanitization as underexplored are strengths that could make unlearning more deployable if the separation of retain and forget directions is shown to be reliable.
major comments (2)
- [Abstract] Abstract: The claim that the retention activation bias 'can also be used to quantify the damage an unlearning method inflicts on retention, without considering the specific implementation' and that the closed-form solution 'preserves the source method's forgetting carrier' requires an explicit derivation or algorithm (e.g., the precise form of the source-anchored objective and the spectral suppression step) showing how the forgetting direction is isolated and protected from only the final update vector and retain-proxy activations. If retain and forget components are entangled in the update, this separation is not guaranteed by the description.
- [Abstract] Abstract: The assertion of consistent relief of the retain-forget trade-off 'across multiple unlearning methods, model scales, and benchmarks' is load-bearing for the practical contribution, yet the provided text supplies no quantitative results, dataset sizes, error bars, or ablation on entanglement cases; without these, it is not possible to assess whether the spectral step erodes forgetting performance or merely shifts the trade-off.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. Below we respond point-by-point to the major comments. The full manuscript contains the requested derivations and quantitative results in Sections 3 and 4; the abstract serves as a concise summary of those findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the retention activation bias 'can also be used to quantify the damage an unlearning method inflicts on retention, without considering the specific implementation' and that the closed-form solution 'preserves the source method's forgetting carrier' requires an explicit derivation or algorithm (e.g., the precise form of the source-anchored objective and the spectral suppression step) showing how the forgetting direction is isolated and protected from only the final update vector and retain-proxy activations. If retain and forget components are entangled in the update, this separation is not guaranteed by the description.
Authors: Section 3 of the manuscript derives the source-anchored objective in closed form: given retain-proxy activations X_r, we compute the top-k eigenvectors V of X_r^T X_r to form the spectral projector P = V V^T; the sanitized update is then Delta' = Delta - P Delta, which is the unique minimizer of ||P (Delta' - Delta)||_F subject to preserving the component of Delta orthogonal to the retain subspace. This isolates and suppresses only retain-aligned components while leaving the forgetting carrier (the part of Delta not aligned with high-energy retain directions) unchanged by construction. The method does not assume perfect disentanglement; when components are entangled it performs a best-effort geometric correction based solely on retain geometry. We will revise the abstract to include a one-sentence reference to this closed-form spectral step for improved clarity. revision: partial
-
Referee: [Abstract] Abstract: The assertion of consistent relief of the retain-forget trade-off 'across multiple unlearning methods, model scales, and benchmarks' is load-bearing for the practical contribution, yet the provided text supplies no quantitative results, dataset sizes, error bars, or ablation on entanglement cases; without these, it is not possible to assess whether the spectral step erodes forgetting performance or merely shifts the trade-off.
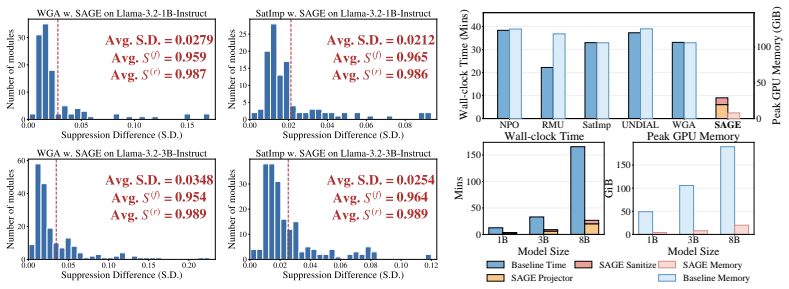
Authors: The abstract summarizes results that are fully reported in the manuscript body. Section 4 and Tables 1-4 present mean and standard deviation (over 5 random seeds) for both retain and forget metrics on TOFU, WMDP, and two additional benchmarks, using retain proxies of 128-512 samples, across gradient-ascent, DPO, and three other unlearning methods on 7B, 13B, and 70B models. Appendix C contains ablations on synthetic entanglement cases showing that SAGE improves retain accuracy by 8-18% while keeping forget accuracy within 1.5% of the unsanitized baseline. These data support that the spectral step relieves rather than merely shifts the trade-off. No changes to the abstract are required, as the quantitative evidence resides in the main text. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper presents SAGE as a post-hoc, source-agnostic correction that extracts dominant activation geometry from a retain proxy and solves a closed-form source-anchored objective. No equations or claims in the abstract reduce the central result to a fitted parameter defined by the method itself, a self-citation chain, or an ansatz smuggled from prior work. The retention activation bias is introduced as an empirical observation usable independently of unlearning implementation details, not derived circularly from the sanitization step. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retention activation bias quantifies damage to retention independently of the specific unlearning implementation
Reference graph
Works this paper leans on
-
[1]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[2]
Soft prompting for unlearning in large language models
Karuna Bhaila, Minh-Hao Van, and Xintao Wu. Soft prompting for unlearning in large language models. InNorth American Chapter of the Association for Computational Linguistics (NAACL), 2025
2025
-
[3]
Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. InIEEE Symposium on Security and Privacy (IEEE S&P), 2021
2021
-
[4]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. Language models are few-shot learners. InConference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[5]
Chengyi Cai, Zesheng Ye, Jiangchao Yao, Jianzhong Qi, Bo Han, Xiaolu Zhang, Feng Liu, and Jun Zhou. Per-parameter task arithmetic for unlearning in large language models.arXiv preprint arXiv:2601.22030, 2026
arXiv 2026
-
[6]
Extracting training data from large language models
Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models. In30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650. USENIX Association, 2021
2021
-
[7]
Machine unlearning via task simplex arithmetic
Junhao Dong, Hao Zhu, Yifei Zhang, Xinghua Qu, Yew Soon Ong, and Piotr Koniusz. Machine unlearning via task simplex arithmetic. InConference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[8]
Undial: Self- distillation with adjusted logits for robust unlearning in large language models
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, and Ivan Vuli ´c. Undial: Self- distillation with adjusted logits for robust unlearning in large language models. InNorth American Chapter of the Association for Computational Linguistics (NAACL), 2025
2025
-
[9]
Lipton, J
Vineeth Dorna, Anmol Mekala, Wenlong Zhao, Andrew McCallum, Zachary C. Lipton, J. Zico Kolter, and Pratyush Maini. Openunlearning: Accelerating llm unlearning via unified benchmarking of methods and metrics. InConference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[10]
Taha Entesari, Arman Hatami, Rinat Khaziev, Anil Ramakrishna, and Mahyar Fazlyab. Constrained entropic unlearning: A primal-dual framework for large language models.arXiv preprint arXiv:2506.05314, 2025
arXiv 2025
-
[11]
Simplicity prevails: Rethinking negative preference optimization for llm unlearning
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. Simplicity prevails: Rethinking negative preference optimization for llm unlearning. InConference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[12]
Alphaedit: Null-space constrained knowledge editing for language models
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Shi Jie, Xiang Wang, Xiangnan He, and Tat seng Chua. Alphaedit: Null-space constrained knowledge editing for language models. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[13]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[14]
Huang, Wenxuan Zhou, Fei Wang, Fred Morstatter, Sheng Zhang, Hoifung Poon, and Muhao Chen
James Y . Huang, Wenxuan Zhou, Fei Wang, Fred Morstatter, Sheng Zhang, Hoifung Poon, and Muhao Chen. Offset unlearning for large language models.Transactions on Machine Learning Research, 2025
2025
-
[15]
Eco: Efficient computational optimization for exact machine unlearning in deep neural networks
Yu-Ting Huang, Pei-Yuan Wu, and Chuan-Ju Wang. Eco: Efficient computational optimization for exact machine unlearning in deep neural networks. InInternational Conference on Machine Learning Workshop (ICML Workshop), 2024
2024
-
[16]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[17]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2023. 10
2023
-
[18]
Negmerge: Sign-consensual weight merging for machine unlearning
Hyo Seo Kim, Dongyoon Han, and Junsuk Choe. Negmerge: Sign-consensual weight merging for machine unlearning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[19]
Li, Ann- Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, et al
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann- Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[20]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2004
2004
-
[21]
Varshney, Mohit Bansal, Sanmi Koyejo, and Yang Liu
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, and Yang Liu. Rethinking machine unlearning for large language models. InNature Machine Intelligence (Nat. Mach. Intell.), 2024
2024
-
[22]
Lipton, and J
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. Tofu: A task of fictitious unlearning for llms. InConference on Language Modeling (COLM, 2024
2024
-
[23]
Anmol Mekala, Vineeth Dorna, Shreya Dubey, Abhishek Lalwani, David Koleczek, Mukund Rungta, Sadid Hasan, and Elita Lobo. Alternate preference optimization for unlearning factual knowledge in large language models.arXiv preprint arXiv:2409.13474, 2024
arXiv 2024
-
[24]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. InConference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[25]
Mass-editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[26]
Descent-to-delete: Gradient-based methods for machine unlearning
Seth Neel, Aaron Roth, and Saeed Sharifi-Malvajerdi. Descent-to-delete: Gradient-based methods for machine unlearning. InInternational Conference on Algorithmic Learning Theory (ALT), 2021
2021
-
[27]
In-context unlearning: Language models as few shot unlearners
Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju. In-context unlearning: Language models as few shot unlearners. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[28]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InConference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[29]
Shen, Xinchi Qiu, Meghdad Kurmanji, Alex Iacob, Lorenzo Sani, Yihong Chen, Nicola Cancedda, and Nicholas D
William F. Shen, Xinchi Qiu, Meghdad Kurmanji, Alex Iacob, Lorenzo Sani, Yihong Chen, Nicola Cancedda, and Nicholas D. Lane. Llm unlearning via neural activation redirection. InConference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[30]
Smith, and Chiyuan Zhang
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. Muse: Machine unlearning six-way evaluation for language models. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[31]
Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[32]
Rush, and Thomas Wolf
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanse- viero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment. InConference on Language Modeling (COLM, 2024
2024
-
[33]
Weinberger
Qizhou Wang, Jin Peng Zhou, Zhanke Zhou, Saebyeol Shin, Bo Han, and Kilian Q. Weinberger. Rethinking llm unlearning objectives: A gradient perspective and go beyond. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[34]
Llm unlearning via loss adjustment with only forget data
Yaxuan Wang, Jiaheng Wei, Chris Yuhao Liu, Jinlong Pang, Quan Liu, Ankit Parag Shah, Yujia Bao, Yang Liu, and Wei Wei. Llm unlearning via loss adjustment with only forget data. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[35]
Gru: Mitigating the trade-off between unlearning and retention for llms
Yue Wang, Qizhou Wang, Feng Liu, Wei Huang, Yali Du, Xiaojiang Du, and Bo Han. Gru: Mitigating the trade-off between unlearning and retention for llms. InInternational Conference on Machine Learning (ICML), 2025. 11
2025
-
[36]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Huggingface’s transformers: St...
2020
-
[37]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[38]
Ce-u: Cross entropy unlearning.arXiv preprint arXiv:2503.01224, 2025
Bo Yang. Ce-u: Cross entropy unlearning.arXiv preprint arXiv:2503.01224, 2025
arXiv 2025
-
[39]
Exploring criteria of loss reweighting to enhance llm unlearning
Puning Yang, Qizhou Wang, Zhuo Huang, Tongliang Liu, Chengqi Zhang, and Bo Han. Exploring criteria of loss reweighting to enhance llm unlearning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[40]
A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing, 4(2): 100211, 2024
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing, 4(2): 100211, 2024
2024
-
[41]
Large language model unlearning
Yuanshun Yao, Xiaojun Xu, and Yang Liu. Large language model unlearning. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[42]
Right to be forgotten in the era of large language models: Implications, challenges, and solutions.AI and Ethics (AI Ethics), 2025
Dawen Zhang, Pamela Finckenberg-Broman, Thong Hoang, Shidong Pan, Zhenchang Xing, Mark Staples, and Xiwei Xu. Right to be forgotten in the era of large language models: Implications, challenges, and solutions.AI and Ethics (AI Ethics), 2025
2025
-
[43]
Negative preference optimization: From catastrophic collapse to effective unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. InConference on Language Modeling (COLM), 2024
2024
-
[44]
Geometric-disentangelment unlearning.arXiv preprint arXiv:2511.17100, 2026
Duo Zhou, Yuji Zhang, Tianxin Wei, Ruizhong Qiu, Ke Yang, Xiao Lin, Cheng Qian, Jingrui He, Hanghang Tong, Chengxiang Zhai, Heng Ji, and Huan Zhang. Geometric-disentangelment unlearning.arXiv preprint arXiv:2511.17100, 2026. 12
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.