More Yap Less Meaning: Uncovering Self-Improvement Behavior in SLMs
Pith reviewed 2026-06-27 18:44 UTC · model grok-4.3
The pith
Small language models gain only 4.4 percent accuracy when refining answers with hints they generate themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
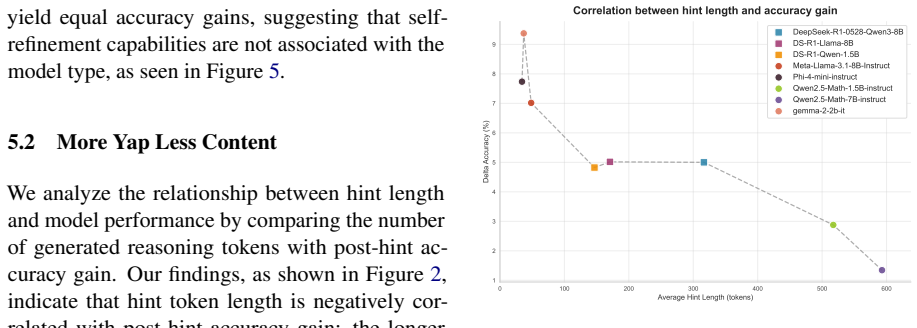
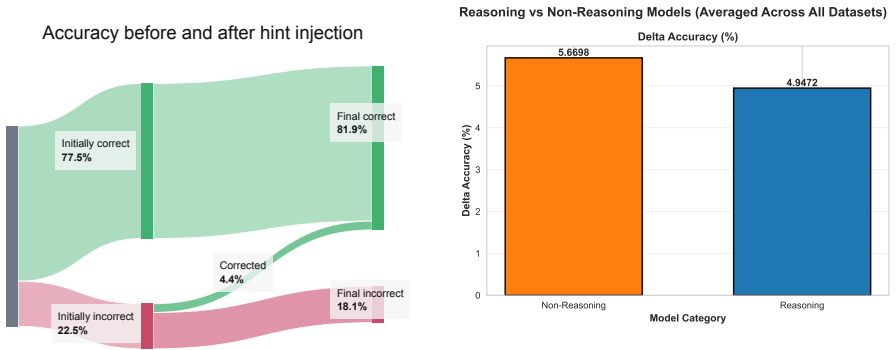
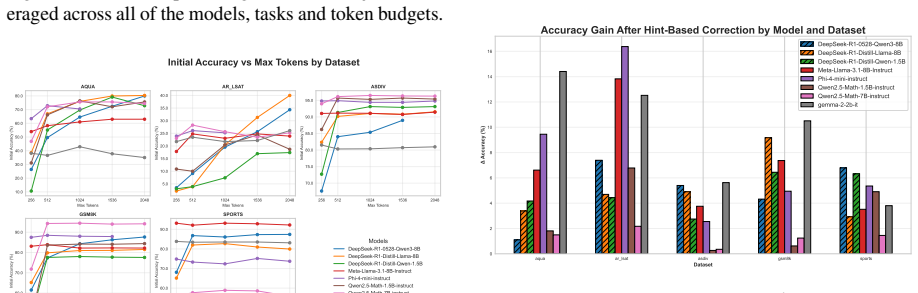
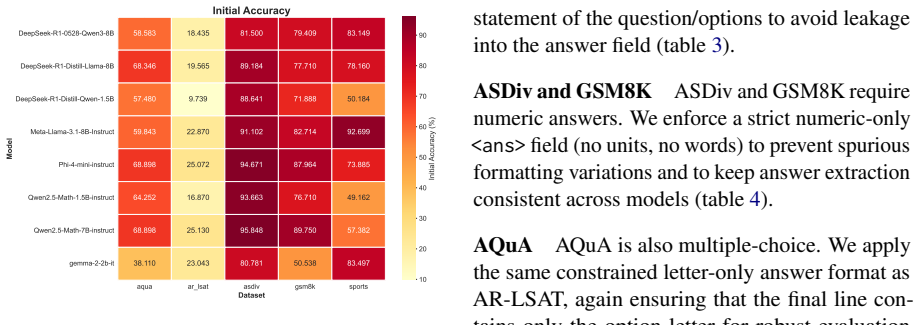
In a minimal three-step self-correction pipeline run on arithmetic and logical reasoning benchmarks, small language models raise their initial accuracy by only 4.4 percent when they receive hints they generated themselves that include the ground truth. The models do not identify what was missing from their original reasoning, produce hints with minimal semantic difference between successful and unsuccessful cases, and generate longer hints that correlate with final incorrect answers.
What carries the argument
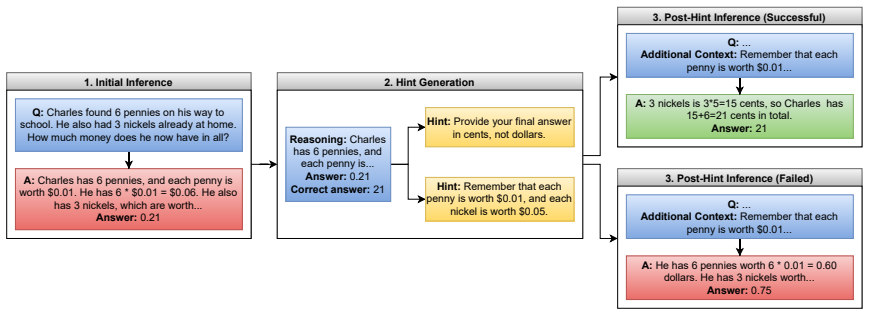
The minimal three-step self-correction pipeline that records an initial answer, generates a hint for each error given the ground truth, and then refines the answer with the model's own hint.
If this is right
- Additional self-generated deliberation does not improve final answers on these tasks.
- Performance does not scale with larger inference-time compute budgets in the tested models.
- Hint generation fails to surface the information needed for successful correction.
- Observed self-improvement in larger models may rely on capabilities absent in small language models.
Where Pith is reading between the lines
- Training regimes that reward explicit flaw detection might be required before self-correction emerges.
- Replacing self-generated hints with hints from stronger models would separate the generation bottleneck from the revision bottleneck.
- The correlation between hint length and error rate suggests that current architectures may degrade when forced to produce longer outputs.
Load-bearing premise
The pipeline isolates the model's intrinsic ability to correct its own reasoning rather than its ability to use externally supplied correct information.
What would settle it
A large accuracy increase when the same models are instead given hints that explicitly name the specific flaw in their initial reasoning.
Figures
read the original abstract
Recently, language models have made rapid progress across various domains and applications. However, their capability for self-improvement, i.e., whether they are adept at recognising and correcting flaws in their own reasoning, remains dubious. In this study, we address this question by constructing a sufficiency test to rigorously examine the self-correction capabilities of small language models (SLMs). We propose a minimal three-step self-correction pipeline that collects initial SLM answers, prompts the same model to generate hints for its incorrect responses given the ground truth, and feeds the model the same question with its own feedback to refine the initial answer. We evaluate a variety of instruction-tuned and reasoning SLMs in this experimental setup on arithmetic and logical reasoning benchmarks. Our findings show that SLMs with injected hint sentences yield only a 4.4 percent gain over initial question-answering accuracy. Even though the correct answer was provided alongside the model's incorrect reasoning, the evaluated SLMs fail to understand what was missing in their reasoning and show minimal semantic difference between hints that lead to corrections and ones that do not. Furthermore, our experiments show that longer hints are positively correlated with incorrect final answers, suggesting that longer deliberation on problems can hinder the reasoning process, meaning that SLMs do not necessarily scale in performance with a larger compute budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a minimal three-step pipeline to test self-correction in small language models (SLMs): (1) collect initial answers on arithmetic and logical reasoning benchmarks, (2) prompt the same model to generate hints for incorrect responses given the ground truth, and (3) feed the original question plus the model's own hint back for refinement. It reports a 4.4% accuracy gain from the hints, claims that models fail to identify what was missing in their reasoning, finds minimal semantic differences between effective and ineffective hints, and reports a positive correlation between longer hints and incorrect final answers.
Significance. If the empirical results hold after correcting for the external-signal issue, the work would provide evidence that current instruction-tuned and reasoning SLMs exhibit limited autonomous self-improvement and that additional deliberation (longer hints) can degrade rather than improve performance. This would be a useful negative result for the self-correction literature, provided the experimental design is adjusted to isolate intrinsic correction from use of externally supplied correct answers.
major comments (2)
- [Abstract] Abstract (and the three-step pipeline description): the hints are generated 'given the ground truth' for incorrect responses. This injects the correct answer into the hint-generation step, so the refinement stage tests whether the SLM can parse and apply externally supplied correct information rather than autonomously detecting flaws in its own reasoning without any ground-truth signal. The 4.4% gain, the 'failure to understand what was missing,' and the semantic-difference claim are therefore interpreted under a self-correction framing that the method does not support.
- [Abstract] Abstract: the central quantitative claims (4.4% gain, length correlation, minimal semantic difference) are stated without any accompanying information on dataset sizes, number of models or examples per benchmark, variance across runs, error bars, or statistical tests. In the absence of these details the reported effect size cannot be assessed for reliability or practical importance.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific benchmarks and the set of SLMs evaluated, rather than referring only to 'arithmetic and logical reasoning benchmarks' and 'a variety of instruction-tuned and reasoning SLMs.'
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our work. We address each major point below and commit to revisions that strengthen the manuscript without altering its core empirical findings.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the three-step pipeline description): the hints are generated 'given the ground truth' for incorrect responses. This injects the correct answer into the hint-generation step, so the refinement stage tests whether the SLM can parse and apply externally supplied correct information rather than autonomously detecting flaws in its own reasoning without any ground-truth signal. The 4.4% gain, the 'failure to understand what was missing,' and the semantic-difference claim are therefore interpreted under a self-correction framing that the method does not support.
Authors: We agree that the current abstract framing implies a stronger form of autonomous self-correction than the experimental design supports. The ground truth is indeed supplied during hint generation to create a controlled test of whether models can produce and apply useful feedback when the correct answer is available as a reference. This still yields only a 4.4% gain and reveals failure to semantically distinguish useful hints, which we interpret as evidence of limited self-improvement capacity even under favorable conditions. We will revise the abstract, introduction, and method section to explicitly state that hints are generated with ground-truth access and reframe the contribution as a test of self-improvement given external correct signals rather than pure autonomous correction. revision: yes
-
Referee: [Abstract] Abstract: the central quantitative claims (4.4% gain, length correlation, minimal semantic difference) are stated without any accompanying information on dataset sizes, number of models or examples per benchmark, variance across runs, error bars, or statistical tests. In the absence of these details the reported effect size cannot be assessed for reliability or practical importance.
Authors: We agree that the abstract should include basic information on scale and reliability to allow readers to assess the claims. The full paper reports results across multiple instruction-tuned and reasoning SLMs on standard arithmetic and logical reasoning benchmarks, with the 4.4% figure representing an aggregate over the evaluated examples. We will revise the abstract to note the number of models tested, the benchmarks used, and that results are averaged with observed consistency across runs. We will also ensure that the main text includes dataset sizes per benchmark, variance measures, and any statistical tests performed. revision: yes
Circularity Check
Empirical benchmark study with no derivation chain or fitted inputs.
full rationale
The paper describes a three-step experimental pipeline and reports observed accuracy changes (4.4% gain) plus correlations on arithmetic/logical benchmarks. No equations, parameters, or first-principles derivations appear; results are direct measurements from model outputs rather than quantities that reduce to the inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The method is self-contained against external benchmarks and does not invoke any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , url =
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models , journal =. 2023 , url =
2023
-
[2]
Cordeiro , title =
Yiannis Charalambous and Norbert Tihanyi and Ridhi Jain and Youcheng Sun and Mohamed Amine Ferrag and Lucas C. Cordeiro , title =. Computing Research Repository , volume =. 2023 , url =
2023
-
[3]
arXiv preprint arXiv:2110.14168 , year =
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , title =. arXiv preprint arXiv:2110.14168 , year =
-
[4]
2025 , url =
Computing Research Repository , volume =. 2025 , url =
2025
-
[5]
RARR : Researching and Revising What Language Models Say, Using Language Models
Gao, Luyu and Dai, Zhuyun and Pasupat, Panupong and Chen, Anthony and Chaganty, Arun Tejasvi and Fan, Yicheng and Zhao, Vincent and Lao, Ni and Lee, Hongrae and Juan, Da-Cheng and Guu, Kelvin. RARR : Researching and Revising What Language Models Say, Using Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguis...
-
[6]
2024 , url =
Gemma: Open Models Based on Gemini Research and Technology , journal =. 2024 , url =
2024
-
[7]
Computing Research Repository , volume =
Zhibin Gou and Zhihong Shao and Yeyun Gong and Yelong Shen and Yujiu Yang and Nan Duan and Weizhu Chen , title =. Computing Research Repository , volume =. 2023 , url =
2023
-
[8]
, title =
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Amy Yang and Angela Fan and et al. , title =. Computing Research Repository , volume =. 2024 , url =
2024
-
[9]
TechRxiv , year =
Muhammad Usman Hadi and Qasem Al Tashi and Rizwan Qureshi and others , title =. TechRxiv , year =
-
[10]
Computing Research Repository , volume =
Jiaxin Huang and Shixiang Shane Gu and Le Hou and Yuexin Wu and Xuezhi Wang and Hongkun Yu and Jiawei Han , title =. Computing Research Repository , volume =. 2022 , url =
2022
-
[11]
The Twelfth International Conference on Learning Representations , year =
Jie Huang and Xinyun Chen and Swaroop Mishra and Huaixiu Steven Zheng and Adams Wei Yu and Xinying Song and Denny Zhou , title =. The Twelfth International Conference on Learning Representations , year =
-
[12]
Computing Research Repository , volume =
Dongwei Jiang and Jingyu Zhang and Orion Weller and Nathaniel Weir and Benjamin Van Durme and Daniel Khashabi , title =. Computing Research Repository , volume =. 2024 , url =
2024
-
[13]
Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations
Jung, Jaehun and Qin, Lianhui and Welleck, Sean and Brahman, Faeze and Bhagavatula, Chandra and Le Bras, Ronan and Choi, Yejin. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.82
-
[14]
arXiv preprint arXiv:2310.12321 , year =
Kalyan, Katikapalli Subramanyam , title =. arXiv preprint arXiv:2310.12321 , year =
-
[15]
Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. Computing Research Repository , volume =. 2020 , doi =
2020
-
[16]
Computing Research Repository , volume =
Geunwoo Kim and Pierre Baldi and Stephen McAleer , title =. Computing Research Repository , volume =. 2023 , url =
2023
-
[17]
Ross Deans Kristensen-McLachlan and Rebecca M. M. Hicke and M. Context is Key(NMF): Modelling Topical Information Dynamics in Chinese Diaspora Media , journal =. 2024 , url =
2024
-
[18]
Computing Research Repository , volume =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , title =. Computing Research Repository , volume =. 2023 , url =
2023
-
[19]
Transactions on Machine Learning Research , year =
Sara Vera Marjanovi. Transactions on Machine Learning Research , year =
-
[20]
A Diverse Corpus for Evaluating and Developing E nglish Math Word Problem Solvers
Miao, Shen-yun and Liang, Chao-Chun and Su, Keh-Yih. A Diverse Corpus for Evaluating and Developing E nglish Math Word Problem Solvers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.92
-
[21]
Computing Research Repository , volume =
Ning Miao and Yee Whye Teh and Tom Rainforth , title =. Computing Research Repository , volume =. 2023 , url =
2023
-
[22]
2024 , url =
Phi-4 Technical Report , journal =. 2024 , url =
2024
-
[23]
Pan, Liangming and Saxon, Michael and Xu, Wenda and Nathani, Deepak and Wang, Xinyi and Wang, William Yang. Automatically Correcting Large Language Models: Surveying the Landscape of Diverse Automated Correction Strategies. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00660
-
[24]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (
Nils Reimers and Iryna Gurevych , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (. 2019 , address =
2019
-
[25]
Advances in Neural Information Processing Systems (
Noah Shinn and Federico Cassano and Beck Labash and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , title =. Advances in Neural Information Processing Systems (
-
[26]
NeurIPS 2023 Foundation Models for Decision Making Workshop , year =
Karthik Valmeekam and Matthew Marquez and Subbarao Kambhampati , title =. NeurIPS 2023 Foundation Models for Decision Making Workshop , year =
2023
-
[27]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. Advances in Neural Information Processing Systems , year =
-
[28]
Ling, Wang and Yogatama, Dani and Dyer, Chris and Blunsom, Phil. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1015
-
[29]
GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel. GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP. 2018. doi:10.18653/v1/W18-5446
-
[30]
Advances in Neural Information Processing Systems , year =
Wenhui Wang and Furu Wei and Li Dong and Hangbo Bao and Nan Yang and Ming Zhou , title =. Advances in Neural Information Processing Systems , year =
-
[31]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Advances in Neural Information Processing Systems , volume =
-
[32]
The Eleventh International Conference on Learning Representations (
Sean Welleck and Ximing Lu and Peter West and Faeze Brahman and Tianxiao Shen and Daniel Khashabi and Yejin Choi , title =. The Eleventh International Conference on Learning Representations (
-
[33]
Computing Research Repository , volume =
An Yang and others , title =. Computing Research Repository , volume =. 2024 , url =
2024
-
[34]
Computing Research Repository , volume =
Wenhao Yu and Zhihan Zhang and Zhenwen Liang and Meng Jiang and Ashish Sabharwal , title =. Computing Research Repository , volume =. 2023 , url =
2023
-
[35]
arXiv preprint arXiv:2104.06598 , year =
Zhong, Wanjun and Wang, Siyuan and Tang, Duyu and Xu, Zenan and Guo, Daya and Wang, Jiahai and Yin, Jian and Zhou, Ming and Duan, Nan , title =. arXiv preprint arXiv:2104.06598 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.