Graph Reinforcement Learning for Calibration-Aware Quantum Circuit Routing
Pith reviewed 2026-06-27 07:02 UTC · model grok-4.3
The pith
Calibration-aware graph reinforcement learning routing improves quantum circuit fidelity over gate-count methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
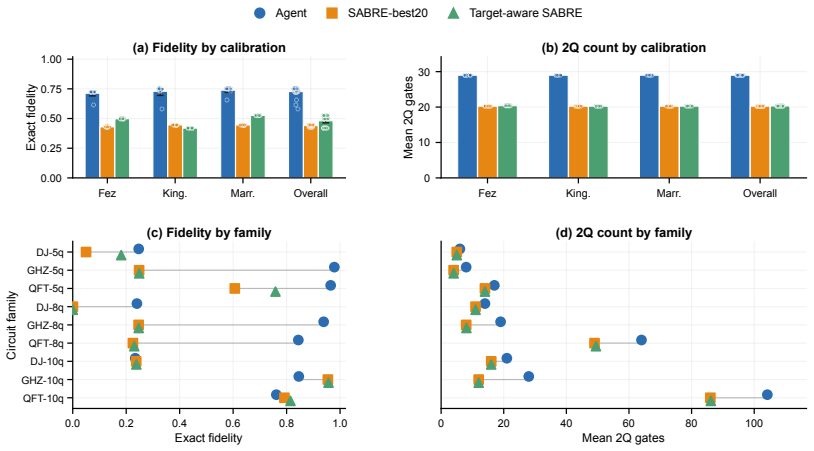
The paper claims that its calibration-aware graph RL router reaches a pooled mean exact fidelity of 0.727 on the evaluated circuits, exceeding the 0.440 of SABRE-best20 and the 0.481 of target-aware SABRE, and concludes that learned routing informed by calibration data can improve fidelity beyond what gate-count-driven compilation achieves.
What carries the argument
A proximal-policy-optimization graph RL policy that selects hardware-edge SWAPs using same-day calibration data as input.
If this is right
- Fidelity gains appear mainly in the 5-qubit and 8-qubit circuit families.
- The RL routes use more two-qubit gates yet still deliver higher fidelity.
- All 10-qubit families continue to favor SABRE-best20 when the tree action graph is held fixed.
Where Pith is reading between the lines
- Daily calibration snapshots can be fed directly into routing policies to avoid poorly performing couplers without changing the circuit itself.
- The observed size dependence suggests that expanding the action graph could extend gains to larger circuits.
- The method could be applied to other processors whose calibration drifts on similar timescales.
Load-bearing premise
The fixed tree action graph chosen for the RL policy captures enough useful routing decisions for circuits of all tested sizes.
What would settle it
A head-to-head fidelity comparison on the same 10-qubit circuit families and calibration snapshots in which the RL router still underperforms SABRE-best20 would falsify the claim that calibration-aware learned routing improves fidelity beyond gate-count methods.
Figures
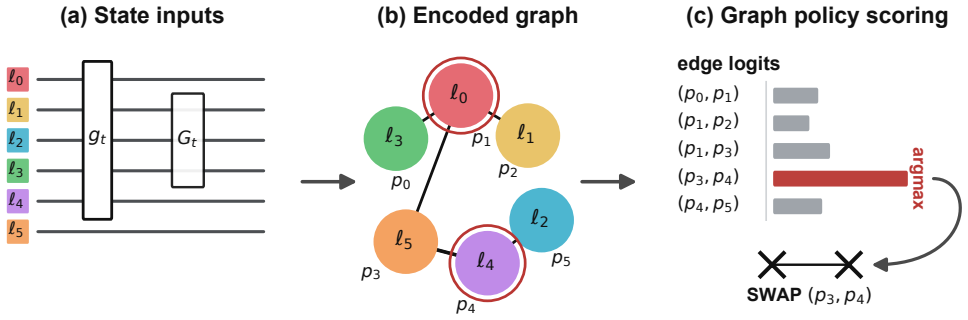
read the original abstract
Quantum circuit routing is a key step in compiling programs for noisy intermediate-scale quantum processors. Routes that appear efficient by standard overhead metrics can still lose fidelity when they pass through poorly calibrated couplers. We study a calibration-aware graph reinforcement-learning router that uses same-day IBM Heron r2 calibration data to choose hardware-edge SWAPs. We train the policy with proximal policy optimization and evaluate it with exact simulated fidelity across nine Munich Quantum Toolkit (MQT) Bench circuits and three calibration snapshots. Across these evaluations, pooled mean exact fidelity is $0.727$, compared with $0.440$ for SABRE-best20 and $0.481$ for target-aware SABRE. We observed that fidelity gains came with higher routed two-qubit counts and were concentrated in 5 qubit and 8 qubit circuit families; under the fixed tree action graph, all 10 qubit families favored SABRE-best20. Overall, our results show that calibration-aware learned routing can improve fidelity beyond gate-count-driven compilation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a calibration-aware graph RL router, trained with PPO on same-day IBM Heron r2 calibration snapshots, achieves a pooled mean exact simulated fidelity of 0.727 across nine MQT Bench circuits and three snapshots, outperforming SABRE-best20 (0.440) and target-aware SABRE (0.481). Fidelity gains occur with higher routed two-qubit counts and are concentrated in 5- and 8-qubit families; under the fixed tree action graph all 10-qubit families revert to preferring SABRE-best20. The work concludes that calibration-aware learned routing can improve fidelity beyond gate-count-driven compilation.
Significance. If the empirical comparison holds, the result provides concrete evidence that incorporating real calibration data into an RL policy can yield higher exact fidelity than standard SABRE variants on smaller circuits. Credit is due for the use of external calibration snapshots rather than synthetic noise models and for reporting exact simulated fidelity instead of proxy metrics such as gate count. The explicit acknowledgment of the 10-qubit limitation is also a strength.
major comments (2)
- [Abstract] Abstract: The central claim that calibration-aware learned routing improves fidelity beyond gate-count-driven compilation is load-bearing on the policy being able to select useful SWAPs inside the chosen fixed tree action graph. The abstract itself states that all 10-qubit families favored SABRE-best20 under this graph, indicating that the action-space restriction—not the calibration signal or PPO training—is the factor preventing competitive routes at larger sizes and thereby limiting the generality of the reported 0.727 pooled mean fidelity.
- [Evaluation] Evaluation section (inferred from abstract and results): The reported fidelity numbers rely on simulated exact fidelity whose match to actual hardware execution is unverified in the manuscript; without this validation or at least a hardware run on a subset of circuits, the practical significance of the 0.727 vs. 0.440/0.481 comparison remains provisional.
minor comments (2)
- [Methods] The manuscript should clarify the precise construction and size of the fixed tree action graph and justify why this particular graph was selected rather than a denser or hardware-native graph.
- [Methods] Training hyperparameters, network architecture, and reward function for the PPO policy are not described in sufficient detail to allow reproduction of the reported fidelity numbers.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the strengths of our approach in using real calibration data and exact fidelity metrics. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that calibration-aware learned routing improves fidelity beyond gate-count-driven compilation is load-bearing on the policy being able to select useful SWAPs inside the chosen fixed tree action graph. The abstract itself states that all 10-qubit families favored SABRE-best20 under this graph, indicating that the action-space restriction—not the calibration signal or PPO training—is the factor preventing competitive routes at larger sizes and thereby limiting the generality of the reported 0.727 pooled mean fidelity.
Authors: We agree that the fixed tree action graph restricts the policy's options, particularly at 10 qubits where SABRE-best20 is preferred. This choice was necessary to keep the action space manageable for PPO training. Nevertheless, the calibration-aware policy achieves higher fidelity than the baselines for the 5- and 8-qubit circuits, demonstrating that the calibration signal enables better SWAP selections within the available actions. We will revise the abstract to clarify that the reported improvements are achieved under this action space constraint. revision: partial
-
Referee: [Evaluation] Evaluation section (inferred from abstract and results): The reported fidelity numbers rely on simulated exact fidelity whose match to actual hardware execution is unverified in the manuscript; without this validation or at least a hardware run on a subset of circuits, the practical significance of the 0.727 vs. 0.440/0.481 comparison remains provisional.
Authors: The manuscript reports exact simulated fidelity computed from the calibration data, which provides a direct estimate of expected performance. We acknowledge that actual hardware execution would provide stronger validation of the practical impact. However, obtaining consistent hardware runs across multiple calibration snapshots poses logistical challenges, and the current evaluation focuses on simulation to isolate the effect of the routing policy. revision: no
Circularity Check
No circularity: empirical comparison of RL router against external baselines
full rationale
The paper reports an empirical evaluation of a PPO-trained graph RL policy for quantum circuit routing, using same-day IBM calibration snapshots and exact simulated fidelity on MQT Bench circuits. The central result (pooled mean fidelity 0.727 vs. 0.440/0.481 for SABRE variants) is obtained by direct measurement on held-out circuits and external hardware data; no equations, fitted parameters, or self-citations are invoked to derive the fidelity numbers from the policy itself. The fixed-tree action graph is an explicit modeling choice whose limitations are acknowledged in the abstract, but this does not create a self-referential derivation. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Proximal policy optimization produces a policy that generalizes across calibration snapshots for the routing task.
- domain assumption Exact simulated fidelity on the chosen noise model accurately ranks routing quality for real IBM Heron devices.
Reference graph
Works this paper leans on
-
[1]
Quantum Computing in the NISQ Era and Beyond,
J. Preskill, “Quantum Computing in the NISQ Era and Beyond,”Quantum, vol. 2, art. 79, 2018
2018
-
[2]
Qubit Allocation,
M. Y. Siraichiet al., “Qubit Allocation,”Proc. ACM Program. Lang., vol. 3, OOPSLA, 2019
2019
-
[3]
Mapping Quantum Circuits to IBM QX Architectures,
A. Zulehneret al., “Mapping Quantum Circuits to IBM QX Architectures,”IEEE TCAD, vol. 38, no. 7, pp. 1226–1236, 2019
2019
-
[4]
On the Qubit Routing Problem,
A. Cowtanet al., “On the Qubit Routing Problem,” inProc. TQC, 2019
2019
-
[5]
Tackling the Qubit Mapping Problem for NISQ-Era Quantum Devices,
G. Li, Y. Ding, and Y. Xie, “Tackling the Qubit Mapping Problem for NISQ-Era Quantum Devices,” inProc. ASPLOS, 2019
2019
-
[6]
Qiskit:AnOpen-sourceFrameworkforQuantumComputing,
Qiskitcontributors,“Qiskit:AnOpen-sourceFrameworkforQuantumComputing,” version 2.4.1, 2026
2026
-
[7]
Noise-Adaptive Compiler Mappings for NISQ Computers,
P. Muraliet al., “Noise-Adaptive Compiler Mappings for NISQ Computers,” in Proc. ASPLOS, 2019
2019
-
[8]
ExtractingSuccessfromIBM’s20-QubitMachines,
S.Nishioetal.,“ExtractingSuccessfromIBM’s20-QubitMachines,”ACMJETC, vol. 16, no. 3, 2020
2020
-
[9]
EnsembleofDiverseMappings,
S.S.TannuandM.K.Qureshi,“EnsembleofDiverseMappings,”inProc.MICRO, 2019
2019
-
[10]
MQT Bench,
N. Quetschlichet al., “MQT Bench,”Quantum, vol. 7, art. 1062, 2023
2023
-
[11]
FIDDLE: Reinforcement Learning for Quantum Fidelity Enhancement,
H. M. Ngo, T. Kahveci, and M. T. Thai, “FIDDLE: Reinforcement Learning for Quantum Fidelity Enhancement,”ACM Trans. Quantum Comput., vol. 7, no. 1, art. 7, 2026
2026
-
[12]
ProximalPolicyOptimizationAlgorithms,
J.Schulmanetal.,“ProximalPolicyOptimizationAlgorithms,”arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[13]
NeuralMessagePassingforQuantumChemistry,
J.Gilmeretal.,“NeuralMessagePassingforQuantumChemistry,”inProc.ICML, 2017
2017
-
[14]
Semi-Supervised Classification with Graph Convolutional Networks,
T. N. Kipf and M. Welling, “Semi-Supervised Classification with Graph Convolutional Networks,” inProc. ICLR, 2017
2017
-
[15]
Reinforcement Learning for Qubit Routing,
M. G. Pozziet al., “Reinforcement Learning for Qubit Routing,”ACM Trans. Quantum Comput., vol. 3, no. 2, 2022
2022
-
[16]
Qubit Routing Using GNN-Aided MCTS,
A. Sinha, U. Azad, and H. Singh, “Qubit Routing Using GNN-Aided MCTS,” in Proc. AAAI, 2022
2022
-
[17]
DeepRLStrategiesforNoise-Adaptive Qubit Routing,
G.Pascoal,J.P.Fernandes,andR.Abreu,“DeepRLStrategiesforNoise-Adaptive Qubit Routing,” inProc. IEEE QSW, pp. 146–156, 2024
2024
- [18]
-
[19]
Noise-Adaptive Mapping with GNNs,
V. Saravanan and S. M. Saeed, “Noise-Adaptive Mapping with GNNs,”IEEE TCAD, 2024
2024
-
[20]
H. T. Nguyenet al., “QFOR,” arXiv:2508.04974, 2025
arXiv 2025
-
[21]
Improving and Benchmarking NISQ Qubit Routers,
V. Pina-Canelles, A. Auer, and I. de Vega, “Improving and Benchmarking NISQ Qubit Routers,” arXiv:2502.03908, 2025
arXiv 2025
-
[22]
Qubit Mapping and Routing Tailored to Advanced Quantum ISAs: Not as Costly as You Think,
Z. Yanget al., “Qubit Mapping and Routing Tailored to Advanced Quantum ISAs: Not as Costly as You Think,” arXiv:2511.04608, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.