From Component Manipulation to System Compromise: Understanding and Detecting Malicious MCP Servers
Pith reviewed 2026-05-21 10:36 UTC · model grok-4.3
The pith
Malicious MCP servers compromise LLM systems through targeted manipulations of components and their compositions, which a new detector identifies by checking for behavioral deviations from each tool's intended function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper argues that by taking a component-centric view of MCP servers, one can construct attacks that manipulate specific parts like tools or their compositions to achieve system compromise. Through a new dataset of 114 proof-of-concept malicious servers evaluated across multiple hosts and LLMs, it demonstrates that attack effectiveness varies with component position and that multi-component attacks often succeed better by distributing malicious logic. Building on this, Connor implements a two-stage process: pre-execution analysis detects malicious shell commands and extracts each tool's function intent, while in-execution analysis traces behavioral trajectories to flag deviations from the
What carries the argument
Connor, the two-stage behavioral deviation detector that uses pre-execution analysis to identify malicious commands and extract function intents, combined with step-wise in-execution tracing of behavioral trajectories to detect deviations from intended tool functions.
If this is right
- Attack success rates depend on the position of the manipulated component within the server.
- Multi-component compositions distribute malicious logic across parts, making them more effective than single-component attacks.
- Connor can be applied to detect previously unknown malicious behaviors in MCP servers.
- Existing effect-based classifications miss the internal attack chains that this component view captures.
Where Pith is reading between the lines
- If adopted, security practices for LLM tool integrations could shift toward monitoring component-level behaviors rather than just outcomes.
- This method of intent extraction and deviation checking could extend to other protocols where AI systems interact with external tools.
- Further testing in production environments with diverse LLMs might reveal additional edge cases in trajectory tracing.
- Component position effects could inform design guidelines for safer MCP server architectures.
Load-bearing premise
The curated proof-of-concept dataset accurately captures the range of real-world malicious MCP server behaviors, and behavioral trajectories can be reliably compared to function intents without major false positives across different setups.
What would settle it
Running Connor on a collection of newly discovered real-world malicious MCP servers and checking if its detection accuracy drops significantly or if it produces many false alarms in varied operating conditions.
Figures
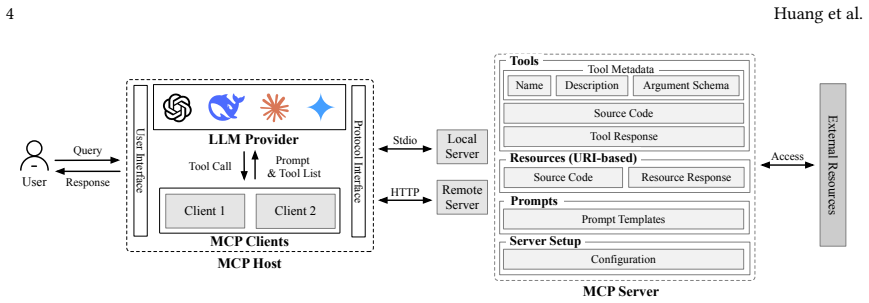








read the original abstract
The model context protocol (MCP) standardizes how LLMs connect to external tools and data sources, enabling faster integration but introducing new attack vectors. Despite the growing adoption of MCP, existing MCP security studies classify attacks by their observable effects, obscuring how attacks behave across different MCP server components and overlooking multi-component attack chains. Meanwhile, existing defenses are less effective when facing multi-component attacks or previously unknown malicious behaviors. This work presents a component-centric perspective for understanding and detecting malicious MCP servers. First, we build the first component-centric PoC dataset of 114 malicious MCP servers where attacks are achieved as manipulation over MCP components and their compositions. We evaluate these attacks' effectiveness across two MCP hosts and five LLMs, and uncover that (1) component position shapes attack success rate; and (2) multi-component compositions often outperform single-component attacks by distributing malicious logic. Second, we propose and implement Connor, a two-stage behavioral deviation detector for malicious MCP servers. It first performs pre-execution analysis to detect malicious shell commands and extract each tool's function intent, and then conducts step-wise in-execution analysis to trace each tool's behavioral trajectories and detect deviations from its function intent. Evaluation on our curated dataset indicates that Connor achieves an F1-score of 94.6%, outperforming the state of the art by 8.9% to 59.6%. In real-world detection, Connor identifies two malicious servers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a component-centric analysis of attacks on the Model Context Protocol (MCP), which standardizes LLM connections to external tools. It constructs the first PoC dataset of 114 malicious MCP servers via manipulations and compositions of MCP components, evaluates attack effectiveness across two hosts and five LLMs (finding that component position influences success and multi-component attacks often outperform single-component ones), and proposes Connor, a two-stage behavioral deviation detector. Connor performs pre-execution shell-command detection plus tool intent extraction, followed by step-wise in-execution trajectory comparison against extracted intents. On the curated dataset Connor reports 94.6% F1, outperforming prior art by 8.9–59.6%; it also flags two real-world malicious servers.
Significance. If the detector generalizes, the work is significant for securing the emerging MCP ecosystem that enables rapid LLM tool integration. The component-level attack taxonomy and the two-stage (pre- plus in-execution) deviation detector directly address gaps in effect-based classifications and defenses that struggle with multi-component or novel behaviors. Credit is due for building a dedicated PoC dataset, cross-host/LLM evaluation, and the explicit behavioral-trajectory comparison approach.
major comments (2)
- [§5 (Evaluation)] §5 (Evaluation) and abstract: the headline claim that Connor achieves 94.6% F1 and outperforms SOTA by 8.9–59.6% rests entirely on the authors’ self-constructed 114-server PoC dataset. The manuscript provides insufficient detail on how the component manipulations were chosen, whether the resulting behavioral trajectories are representative of real malicious MCP servers, and how false-positive rates would behave under varied hosts, LLMs, or evasion attempts; this directly undermines confidence in the generalization step required for the central detection claim.
- [Real-world detection paragraph] Real-world detection paragraph (near end of §5): only two servers are reported as flagged, yet no information is given on the scale of the real-world scan, the false-positive rate observed, or how the flagged servers’ behaviors compare to the PoC distribution. Without these metrics the practical utility of Connor outside the synthetic setting cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the range '8.9% to 59.6%' is stated without naming the baseline detectors or the precise metric (F1, precision, etc.) used for each comparison; adding this information would improve clarity.
- [§3 (Dataset construction)] §3 (Dataset construction): the description of how the 114 servers were assembled from component manipulations could be expanded with a table or diagram showing the distribution of single- versus multi-component attacks to help readers judge coverage.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope of our evaluation and the strength of our generalization claims. We respond to each major comment below and commit to revisions that address the concerns raised.
read point-by-point responses
-
Referee: §5 (Evaluation) and abstract: the headline claim that Connor achieves 94.6% F1 and outperforms SOTA by 8.9–59.6% rests entirely on the authors’ self-constructed 114-server PoC dataset. The manuscript provides insufficient detail on how the component manipulations were chosen, whether the resulting behavioral trajectories are representative of real malicious MCP servers, and how false-positive rates would behave under varied hosts, LLMs, or evasion attempts; this directly undermines confidence in the generalization step required for the central detection claim.
Authors: We agree that the manuscript would benefit from greater transparency on dataset construction and evaluation scope. In the revised version we will expand §5 and add an appendix section that details the systematic enumeration of component manipulations: we started from the MCP specification, identified all manipulable components (tool definitions, resource handlers, prompt templates, and execution hooks), and generated single-component and multi-component variants by targeted alterations at each position. We will also clarify that the 114 servers were produced by exhaustive coverage of these positions and compositions rather than ad-hoc selection. On representativeness, we will note that while large-scale real-world malicious MCP servers remain rare, the dataset captures the behavioral trajectories that arise directly from component-level changes, as evidenced by the position-dependent success rates and the superiority of multi-component attacks observed across both hosts and all five LLMs. For false-positive behavior under varied conditions and evasion, we will add a dedicated limitations paragraph discussing the two-host/five-LLM robustness already measured and outlining plausible evasion vectors (e.g., command obfuscation or intent-mimicking trajectories) together with preliminary mitigation ideas. These additions will make the generalization argument more explicit without overstating the current evidence. revision: yes
-
Referee: Real-world detection paragraph (near end of §5): only two servers are reported as flagged, yet no information is given on the scale of the real-world scan, the false-positive rate observed, or how the flagged servers’ behaviors compare to the PoC distribution. Without these metrics the practical utility of Connor outside the synthetic setting cannot be assessed.
Authors: We concur that the real-world paragraph is too terse. In the revision we will specify the scan parameters: the number of publicly reachable MCP servers examined, the discovery method (e.g., registry queries and web searches), and the time window. We will report the observed false-positive rate on the scanned population and provide a side-by-side comparison of the two flagged servers’ pre-execution commands and in-execution trajectories against representative PoC examples. If the scan was exploratory rather than exhaustive, we will state this limitation explicitly and frame the two detections as an initial demonstration rather than a comprehensive field study. These details will allow readers to better gauge practical utility. revision: yes
Circularity Check
No significant circularity; evaluation on author-curated PoC dataset does not reduce claims by construction
full rationale
The paper constructs a component-centric PoC dataset of 114 malicious MCP servers via manipulations and compositions, then reports Connor's F1-score of 94.6% on that dataset. This is standard empirical practice for novel attack surfaces and does not match any enumerated circularity pattern: the two-stage detector (pre-execution command detection plus intent extraction, followed by trajectory comparison) is motivated by independent component analysis rather than being defined in terms of the evaluation results. No self-citations, uniqueness theorems, ansatzes, or fitted parameters are invoked to force the central performance claim. The derivation chain remains self-contained; the limited real-world detection of two servers is noted but does not alter the absence of circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Detection thresholds in Connor
axioms (1)
- domain assumption Malicious behaviors can be detected by comparing actual tool behavior to declared function intent
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Connor... first performs pre-execution analysis to detect malicious shell commands and extract each tool's function intent, and then conducts step-wise in-execution analysis to trace each tool's behavioral trajectories and detect deviations from its function intent.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Behavioral Integrity Verification for AI Agent Skills
BIV audits AI agent skills at scale, finding 80% deviate from declared behavior on 49,943 skills and achieving 0.946 F1 for malicious skill detection.
-
Red-Teaming Agent Execution Contexts: Open-World Security Evaluation on OpenClaw
DeepTrap automates discovery of contextual vulnerabilities in OpenClaw agents via trajectory optimization, showing that unsafe behavior can be induced while preserving task completion and that final-response checks ar...
-
Security Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
The paper identifies twelve protocol-level security risks across MCP, A2A, Agora, and ANP and quantifies wrong-provider tool execution risk in MCP via a measurement-driven case study on multi-server composition.
Reference graph
Works this paper leans on
-
[1]
The work-averse cyberattacker model: theory and evidence from two million attack signatures
Luca Allodi, Fabio Massacci, and Julian Williams. The work-averse cyberattacker model: theory and evidence from two million attack signatures. Risk Analysis, 42(8):1623–1642, 2022
work page 2022
-
[2]
antgroup. Mcpscan. https://github.com/antgroup/MCPScan, 2025
work page 2025
-
[3]
Introducing the model context protocol
anthropic. Introducing the model context protocol. https://www.anthropic.com/news/model-context-protocol, 2024
work page 2024
- [4]
-
[5]
AgentBound: Securing Execution Boundaries of AI Agents
Christoph Bühler, Matteo Biagiola, Luca Di Grazia, and Guido Salvaneschi. Securing ai agent execution.arXiv preprint arXiv:2510.21236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Claude. Claude. https://claude.ai/, 2023
work page 2023
-
[7]
Connect claude code to tools via mcp
Claude. Connect claude code to tools via mcp. https://code.claude.com/docs/en/mcp, 2025
work page 2025
-
[8]
Claude. Introducing claude 4. https://www.anthropic.com/news/claude-4, 2025
work page 2025
-
[9]
Claude. Introducing claude sonnet 4.5. https://www.anthropic.com/news/claude-sonnet-4-5, 2025
work page 2025
-
[10]
Cursor. Cursor. https://cursor.com, 2023
work page 2023
-
[11]
Cursor. Cursor agent. https://cursor.com/cn/docs/agent/overview#tools, 2025
work page 2025
-
[12]
Cursor directory - cursor rules & mcp servers
Cursor. Cursor directory - cursor rules & mcp servers. https://cursor.directory/, 2025
work page 2025
-
[13]
Model context protocol (mcp) | cursor docs
Cursor. Model context protocol (mcp) | cursor docs. https://cursor.com/docs/context/mcp, 2025
work page 2025
-
[14]
DeepSeek. Deepseek-v3.1. https://api-docs.deepseek.com/news/news250821, 2025
work page 2025
- [15]
-
[16]
Junfeng Fang, Zijun Yao, Ruipeng Wang, Haokai Ma, Xiang Wang, and Tat-Seng Chua. We should identify and mitigate third-party safety risks in mcp-powered agent systems.arXiv preprint arXiv:2506.13666, 2025
-
[17]
Enhanced prompting framework for code summarization with large language models
Minying Fang, Xing Yuan, Yuying Li, Haojie Li, Chunrong Fang, and Junwei Du. Enhanced prompting framework for code summarization with large language models. InProceedings of the 34th International Symposium on Software Testing and Analysis, 2025
work page 2025
-
[18]
FastMcp. Mcp json configuration. https://gofastmcp.com/integrations/mcp-json-configuration, 2025
work page 2025
-
[19]
Pengfei Gao, Zhao Tian, Xiangxin Meng, Xinchen Wang, Ruida Hu, Yuanan Xiao, Yizhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, et al. Trae agent: An llm-based agent for software engineering with test-time scaling.arXiv preprint arXiv:2507.23370, 2025
-
[20]
Xingan Gao, Xiaobing Sun, Sicong Cao, Kaifeng Huang, Di Wu, Xiaolei Liu, Xingwei Lin, and Yang Xiang. Malguard: towards real-time, accurate, and actionable detection of malicious packages in pypi ecosystem. InProceedings of the 34th USENIX Conference on Security Symposium, 2025
work page 2025
-
[21]
Github copilot·your ai pair programmer
GitHub. Github copilot·your ai pair programmer. https://github.com/features/copilot, 2021
work page 2021
-
[22]
Extending github copilot coding agent with the model context protocol (mcp)
GitHub. Extending github copilot coding agent with the model context protocol (mcp). https://docs.github.com/en/enterprise-cloud@latest/copilot/ how-tos/use-copilot-agents/coding-agent/extend-coding-agent-with-mcp?utm_source=chatgpt.com, 2025
work page 2025
- [23]
- [24]
- [25]
-
[26]
A measurement study of model context protocol ecosystem.arXiv preprint arXiv:2509.25292, 2025
Hechuan Guo, Yongle Hao, Yue Zhang, Minghui Xu, Peizhuo Lv, Jiezhi Chen, and Xiuzhen Cheng. A measurement study of model context protocol ecosystem.arXiv preprint arXiv:2509.25292, 2025
-
[27]
Large language model based multi-agents: A survey of progress and challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. InProceedings of the 33th International Joint Conference on Artificial Intelligence, pages 8048–8057, 2024
work page 2024
-
[28]
An empirical study of malicious code in pypi ecosystem
Wenbo Guo, Zhengzi Xu, Chengwei Liu, Cheng Huang, Yong Fang, and Yang Liu. An empirical study of malicious code in pypi ecosystem. In Proceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering, pages 166–177, 2023
work page 2023
-
[29]
Systematic analysis of mcp security,
Yongjian Guo, Puzhuo Liu, Wanlun Ma, Zehang Deng, Xiaogang Zhu, Peng Di, Xi Xiao, and Sheng Wen. Systematic analysis of mcp security.arXiv preprint arXiv:2508.12538, 2025
-
[30]
harishsg993010. damn-vulnerable-mcp-server. https://github.com/harishsg993010/damn-vulnerable-MCP-server, 2025
work page 2025
-
[31]
Mohammed Mehedi Hasan, Hao Li, Emad Fallahzadeh, Gopi Krishnan Rajbahadur, Bram Adams, and Ahmed E Hassan. Model context protocol (mcp) at first glance: Studying the security and maintainability of mcp servers.arXiv preprint arXiv:2506.13538, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Mohammed Mehedi Hasan, Hao Li, Gopi Krishnan Rajbahadur, Bram Adams, and Ahmed E Hassan. Model context protocol (mcp) tool descriptions are smelly! towards improving ai agent efficiency with augmented mcp tool descriptions.arXiv preprint arXiv:2602.14878, 2026
-
[33]
Ping He, Changjiang Li, Binbin Zhao, Tianyu Du, and Shouling Ji. Automatic red teaming llm-based agents with model context protocol tools.arXiv preprint arXiv:2509.21011, 2025. Manuscript submitted to ACM 28 Huang et al
-
[34]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (mcp): Landscape, security threats, and future research directions. arXiv preprint arXiv:2503.23278, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Donapi: Malicious npm packages detector using behavior sequence knowledge mapping
Cheng Huang, Nannan Wang, Ziyan Wang, Siqi Sun, Lingzi Li, Junren Chen, Qianchong Zhao, Jiaxuan Han, Zhen Yang, and Lei Shi. Donapi: Malicious npm packages detector using behavior sequence knowledge mapping. InProceedings of the 33rd USENIX Security Symposium, 2024
work page 2024
-
[36]
Yiheng Huang, Ruisi Wang, Wen Zheng, Zhuotong Zhou, Susheng Wu, Shulin Ke, Bihuan Chen, Shan Gao, and Xin Peng. Spiderscan: Practical detection of malicious npm packages based on graph-based behavior modeling and matching. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 1146–1158, 2024
work page 2024
-
[37]
Profmal: Detecting malicious npm packages by the synergy between static and dynamic analysis
Yiheng Huang, Wen Zheng, Susheng Wu, Bihuan Chen, You Lu, Zhuotong Zhou, Yiheng Cao, Xiaoyu Li, and Xin Peng. Profmal: Detecting malicious npm packages by the synergy between static and dynamic analysis. InProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering, 2025
work page 2025
-
[38]
Mcp security notification: Tool poisoning attacks
Invariantlabs. Mcp security notification: Tool poisoning attacks. https://invariantlabs.ai/blog/mcp-security-notification-tool-poisoning-attacks, 2025
work page 2025
-
[39]
Whatsapp mcp exploited: Exfiltrating your message history via mcp
Invariantlabs. Whatsapp mcp exploited: Exfiltrating your message history via mcp. https://invariantlabs.ai/blog/whatsapp-mcp-exploited, 2025
work page 2025
- [40]
-
[41]
Mcip: Protecting mcp safety via model contextual integrity protocol
Huihao Jing, Haoran Li, Wenbin Hu, Qi Hu, Xu Heli, Tianshu Chu, Peizhao Hu, and Yangqiu Song. Mcip: Protecting mcp safety via model contextual integrity protocol. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1177–1194, 2025
work page 2025
-
[42]
Joern - the bug hunter’s workbench
Joern. Joern - the bug hunter’s workbench. https://joern.io/, 2019
work page 2019
-
[43]
3 malicious mcp servers found on pypi
Guy Korolevski. 3 malicious mcp servers found on pypi. https://research.jfrog.com/post/3-malicious-mcps-pypi-reverse-shell/, 2026
work page 2026
-
[44]
Mcp guardian: A security-first layer for safeguarding mcp-based ai system
Sonu Kumar, Anubhav Girdhar, Ritesh Patil, and Divyansh Tripathi. Mcp guardian: A security-first layer for safeguarding mcp-based ai system. arXiv preprint arXiv:2504.12757, 2025
-
[45]
First malicious mcp server found stealing emails in rogue postmark-mcp package
Ravie Lakshmanan. First malicious mcp server found stealing emails in rogue postmark-mcp package. https://thehackernews.com/2025/09/first- malicious-mcp-server-found.html, 2026
work page 2025
-
[46]
The platform for reliable agents
langchain. The platform for reliable agents. https://github.com/langchain-ai/langchain, 2023
work page 2023
-
[47]
We urgently need privilege management in mcp: A measurement of api usage in mcp ecosystems
Zhihao Li, Kun Li, Boyang Ma, Minghui Xu, Yue Zhang, and Xiuzhen Cheng. We urgently need privilege management in mcp: A measurement of api usage in mcp ecosystems. InProceedings of the 22nd International Conference on Mobile Ad-Hoc and Smart Systems, pages 555–560, 2025
work page 2025
-
[48]
Getting started with model context protocol part 2: Prompts and resources
Daniel Liden. Getting started with model context protocol part 2: Prompts and resources. https://www.danliden.com/posts/20250921-mcp-prompts- resources.html, 2025
-
[49]
From large to mammoth: A comparative evaluation of large language models in vulnerability detection
Jie Lin and David Mohaisen. From large to mammoth: A comparative evaluation of large language models in vulnerability detection. InProceedings of the 32th Network and Distributed System Security Symposium, 2025
work page 2025
-
[50]
MCP.so. Mcp.so. https://mcp.so/, 2025
work page 2025
-
[51]
Model context protocol servers
modelcontextprotocol. Model context protocol servers. https://github.com/modelcontextprotocol/servers, 2025
work page 2025
-
[52]
Vineeth Sai Narajala and Idan Habler. Enterprise-grade security for the model context protocol (mcp): Frameworks and mitigation strategies.arXiv preprint arXiv:2504.08623, 2025
-
[53]
Securing genai multi-agent systems against tool squatting: A zero trust registry-based approach
Vineeth Sai Narajala, Ken Huang, and Idan Habler. Securing genai multi-agent systems against tool squatting: A zero trust registry-based approach. arXiv preprint arXiv:2504.19951, 2025
-
[54]
Backstabber’s knife collection: A review of open source software supply chain attacks
Marc Ohm, Henrik Plate, Arnold Sykosch, and Michael Meier. Backstabber’s knife collection: A review of open source software supply chain attacks. InProceedings of the 17th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, pages 23–43, 2020
work page 2020
-
[55]
OpenAI. Function calling. https://platform.openai.com/docs/guides/function-calling, 2025
work page 2025
-
[56]
OpenAI. Introducing gpt-5. https://openai.com/index/introducing-gpt-5/, 2025
work page 2025
-
[57]
A distributed vulnerability database for open source
OSV. A distributed vulnerability database for open source. https://osv.dev/, 2026
work page 2026
-
[58]
pulse. Mcp server directory. https://www.pulsemcp.com/servers, 2025
work page 2025
-
[59]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InProceedings of the 12th International Conference on Learning Representations, 2024
work page 2024
-
[60]
Mcp safety audit: Llms with the model context protocol allow major security exploits,
Brandon Radosevich and John Halloran. Mcp safety audit: Llms with the model context protocol allow major security exploits.arXiv preprint arXiv:2504.03767, 2025
-
[61]
Partha Pratim Ray. A survey on model context protocol: Architecture, state-of-the-art, challenges and future directions.Authorea Preprints, 2025
work page 2025
-
[62]
Benefits of using mcp over traditional integration methods
Drishti Shah. Benefits of using mcp over traditional integration methods. https://portkey.ai/blog/benefits-of-mcp-over-traditional-integration/, 2025
work page 2025
-
[63]
Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
-
[64]
Smithery - turn scattered context into skills for ai
Smithery. Smithery - turn scattered context into skills for ai. https://smithery.ai/servers, 2025
work page 2025
-
[65]
Hao Song, Yiming Shen, Wenxuan Luo, Leixin Guo, Ting Chen, Jiashui Wang, Beibei Li, Xiaosong Zhang, and Jiachi Chen. Beyond the protocol: Unveiling attack vectors in the model context protocol ecosystem.arXiv preprint arXiv:2506.02040, 2025
-
[66]
Tencent. Ai-infra-guard. https://github.com/Tencent/AI-Infra-Guard, 2025
work page 2025
-
[67]
Bin Wang, Zexin Liu, Hao Yu, Ao Yang, Yenan Huang, Jing Guo, Huangsheng Cheng, Hui Li, and Huiyu Wu. Mcpguard: Automatically detecting vulnerabilities in mcp servers.arXiv preprint arXiv:2510.23673, 2025. Manuscript submitted to ACM From Component Manipulation to System Compromise: Understanding and Detecting Malicious MCP Servers 29
-
[68]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. InProceedings of the 61st annual meeting of the association for computational linguistics, pages 13484–13508, 2023
work page 2023
-
[69]
Zihan Wang, Rui Zhang, Yu Liu, Wenshu Fan, Wenbo Jiang, Qingchuan Zhao, Hongwei Li, and Guowen Xu. Mpma: Preference manipulation attack against model context protocol.arXiv preprint arXiv:2505.11154, 2025
-
[70]
Wenpeng Xing, Zhonghao Qi, Yupeng Qin, Yilin Li, Caini Chang, Jiahui Yu, Changting Lin, Zhenzhen Xie, and Meng Han. Mcp-guard: A defense framework for model context protocol integrity in large language model applications.arXiv preprint arXiv:2508.10991, 2025
-
[71]
A survey of ai agent protocols.arXiv preprint arXiv:2504.16736, 2025
Yingxuan Yang, Huacan Chai, Yuanyi Song, Siyuan Qi, Muning Wen, Ning Li, Junwei Liao, Haoyi Hu, Jianghao Lin, Gaowei Chang, et al. A survey of ai agent protocols.arXiv preprint arXiv:2504.16736, 2025
-
[72]
Mcpsecbench: A systematic security benchmark and playground for testing model context protocols
Yixuan Yang, Daoyuan Wu, and Yufan Chen. Mcpsecbench: A systematic security benchmark and playground for testing model context protocols. arXiv preprint arXiv:2508.13220, 2025
-
[73]
yiheng. Connor. https://github.com/yiheng98/Connor, 2026
work page 2026
- [74]
-
[75]
Junan Zhang, Kaifeng Huang, Yiheng Huang, Bihuan Chen, Ruisi Wang, Chong Wang, and Xin Peng. Killing two birds with one stone: Malicious package detection in npm and pypi using a single model of malicious behavior sequence.ACM Transactions on Software Engineering and Methodology, 2024
work page 2024
-
[76]
Parasites in the Toolchain: A Large-Scale Analysis of Attacks on the MCP Ecosystem
Shuli Zhao, Qinsheng Hou, Zihan Zhan, Yanhao Wang, Yuchong Xie, Yu Guo, Libo Chen, Shenghong Li, and Zhi Xue. Mind your server: A systematic study of parasitic toolchain attacks on the mcp ecosystem.arXiv preprint arXiv:2509.06572, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
When mcp servers attack: Taxonomy, feasibility, and mitigation,
Weibo Zhao, Jiahao Liu, Bonan Ruan, Shaofei Li, and Zhenkai Liang. When mcp servers attack: Taxonomy, feasibility, and mitigation.arXiv preprint arXiv:2509.24272, 2025
-
[78]
Xinyi Zheng, Chen Wei, Shenao Wang, Yanjie Zhao, Peiming Gao, Yuanchao Zhang, Kailong Wang, and Haoyu Wang. Towards robust detection of open source software supply chain poisoning attacks in industry environments. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 1990–2001, 2024. Manuscript submitted to A...
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.