STRIDE: A Self-Reflective Agent Framework for Reliable Automatic Equation Discovery
Pith reviewed 2026-05-20 11:05 UTC · model grok-4.3
The pith
STRIDE turns fitted scores and candidate behavior into shared feedback for more reliable LLM equation discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
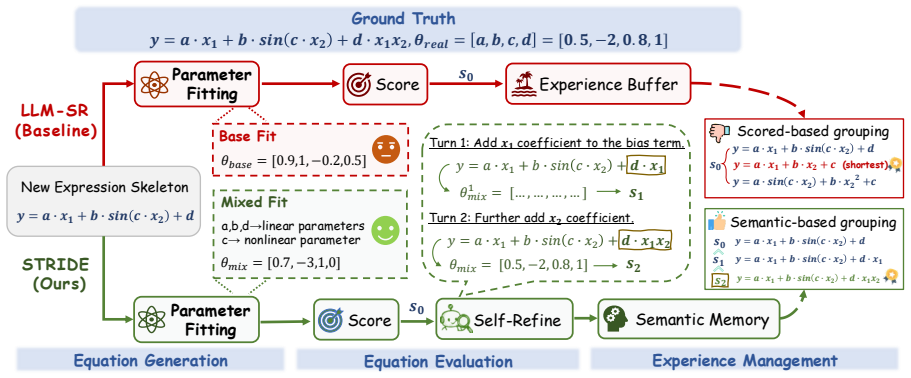
STRIDE improves reliability by coordinating data-aware generation, mixed-fitting evaluation, critic-executor repair, and diversity-preserving semantic memory. By turning fitted scores and candidate behavior into shared feedback, STRIDE enables equations to be proposed, assessed, refined, and reused within a closed-loop discovery process.
What carries the argument
STRIDE self-reflective agent framework that coordinates data-aware generation, mixed-fitting evaluation, critic-executor repair, and diversity-preserving semantic memory using shared feedback from fitted scores and candidate behavior.
If this is right
- STRIDE achieves higher accuracy than prior generation-centered loops on representative symbolic-regression benchmarks.
- STRIDE exhibits improved out-of-distribution robustness when recovering symbolic laws from data.
- STRIDE recovers equation structures more reliably across multiple LLM backbones.
- Ablation studies confirm that each of the four coordinated components contributes to the observed performance gains.
Where Pith is reading between the lines
- The closed-loop reflection pattern could be tested on related discovery tasks such as inferring differential equations or physical constraints from observational data.
- If the semantic memory successfully preserves diversity, it may reduce the total number of LLM calls needed to reach a high-quality equation.
- The critic-executor repair step might generalize to other agent systems where near-miss solutions can be iteratively corrected rather than discarded.
Load-bearing premise
That turning fitted scores and candidate behavior into shared feedback within the closed-loop process will reliably enable better proposal, assessment, refinement, and reuse without the LLM introducing new systematic errors or biases in the reflection steps.
What would settle it
Running STRIDE on the same benchmarks after removing the reflection and shared-feedback mechanisms and finding no measurable drop in accuracy, OOD robustness, or structural recovery would falsify the central claim.
Figures














read the original abstract
LLM-based equation discovery offers a promising route to recovering symbolic laws from data, but many systems still rely on generation-centered loops that propose candidates, fit parameters, score results, and reuse selected examples. Such loops can misjudge useful skeletons under unreliable fitting, discard near-correct equations that require repair, and accumulate redundant memories that provide limited guidance. We propose STRIDE, a self-reflective agent framework that improves reliability by coordinating data-aware generation, mixed-fitting evaluation, critic--executor repair, and diversity-preserving semantic memory. By turning fitted scores and candidate behavior into shared feedback, STRIDE enables equations to be proposed, assessed, refined, and reused within a closed-loop discovery process. Experiments on representative symbolic-regression benchmarks and LSR-Synth suites show that STRIDE improves accuracy, OOD robustness, and structural recovery across multiple LLM backbones, with ablations and analyses confirming the contribution of its core components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STRIDE, a self-reflective agent framework for reliable automatic equation discovery with LLMs. It coordinates data-aware generation, mixed-fitting evaluation, critic-executor repair, and diversity-preserving semantic memory to address limitations in generation-centered loops such as misjudging skeletons under unreliable fitting, discarding near-correct equations, and accumulating redundant memories. By converting fitted scores and candidate behavior into shared feedback, the framework enables improved proposal, assessment, refinement, and reuse in a closed-loop process. Experiments on symbolic-regression benchmarks and LSR-Synth suites report gains in accuracy, OOD robustness, and structural recovery across multiple LLM backbones, with ablations confirming the contributions of core components.
Significance. If the empirical claims hold under rigorous verification, STRIDE could advance LLM-based symbolic regression by providing a more reliable closed-loop mechanism that mitigates common failure modes. The emphasis on self-reflection and semantic memory offers a structured way to improve generalization and structural recovery, with potential value for scientific discovery tasks where symbolic laws must be recovered from noisy or limited data.
major comments (2)
- [Abstract] Abstract: The central claim of improved accuracy, OOD robustness, and structural recovery (with ablations confirming component contributions) is asserted without any quantitative results, error bars, dataset details, or statistical tests; this makes it impossible to evaluate the magnitude or reliability of the reported gains and directly undermines assessment of the framework's effectiveness.
- [Methods (critic-executor and memory components)] Section describing critic-executor repair and semantic memory: The mechanism for turning fitted scores and candidate behavior into shared feedback is presented as enabling better refinement and reuse, but no analysis or audit is provided to show that LLM reflection steps avoid introducing systematic errors such as hallucinated repairs, inconsistent mathematical judgments, or confirmation bias toward prior skeletons; this is load-bearing for the closed-loop reliability claim.
minor comments (2)
- [Methods] Clarify the precise definition and implementation of 'mixed-fitting evaluation' with an example or pseudocode to aid reproducibility.
- [Abstract] The abstract mentions 'representative symbolic-regression benchmarks and LSR-Synth suites' without naming the specific datasets or providing references; add these details for context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and outline the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of improved accuracy, OOD robustness, and structural recovery (with ablations confirming component contributions) is asserted without any quantitative results, error bars, dataset details, or statistical tests; this makes it impossible to evaluate the magnitude or reliability of the reported gains and directly undermines assessment of the framework's effectiveness.
Authors: We agree that the abstract would be strengthened by including concrete quantitative indicators. In the revised manuscript we will update the abstract to report representative performance gains (e.g., accuracy and structural recovery improvements on the symbolic-regression benchmarks and LSR-Synth suites), reference the specific tables and figures that contain error bars and dataset details, and note that statistical comparisons were performed across LLM backbones. This change preserves abstract length while making the magnitude and reliability of the claims directly evaluable. revision: yes
-
Referee: [Methods (critic-executor and memory components)] Section describing critic-executor repair and semantic memory: The mechanism for turning fitted scores and candidate behavior into shared feedback is presented as enabling better refinement and reuse, but no analysis or audit is provided to show that LLM reflection steps avoid introducing systematic errors such as hallucinated repairs, inconsistent mathematical judgments, or confirmation bias toward prior skeletons; this is load-bearing for the closed-loop reliability claim.
Authors: We acknowledge that the absence of a targeted audit of the LLM reflection steps is a limitation for fully substantiating the reliability claim. While our ablations demonstrate net performance benefits, they do not isolate potential hallucination, inconsistency, or bias within individual critic-executor or memory operations. In the revision we will add a dedicated subsection (or supplementary analysis) that samples reflection outputs, compares proposed repairs against ground-truth equations where available, quantifies rates of hallucinated or inconsistent judgments, and discusses observed biases or mitigation strategies. This will directly address the load-bearing concern. revision: yes
Circularity Check
No circularity: framework evaluated on external benchmarks
full rationale
The paper describes an applied engineering framework (STRIDE) for LLM-driven symbolic regression. Its central claims concern empirical improvements in accuracy, OOD robustness, and structural recovery, measured directly against independent symbolic-regression benchmarks and LSR-Synth suites. Ablations and analyses are presented as confirming the contribution of core components such as critic-executor repair and semantic memory. No mathematical derivations, first-principles predictions, or fitted parameters are claimed that reduce by construction to the paper's own inputs or self-referential definitions. The evaluation remains externally falsifiable and does not rely on self-citation chains or renaming of known results as novel derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shojaee, Parshin and Meidani, Kazem and Gupta, Shashank and Barati Farimani, Amir and Reddy, Chandan K. , booktitle =. 2025 , url =
work page 2025
-
[2]
International Conference on Machine Learning , year =
LLM-SRBench: A New Benchmark for Scientific Equation Discovery with Large Language Models , author =. International Conference on Machine Learning , year =
-
[3]
gplearn: Genetic Programming in Python, with a scikit-learn Inspired API , author =. 2022 , howpublished =
work page 2022
-
[4]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl , author =. arXiv preprint arXiv:2305.01582 , year =. 2305.01582 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Deep Symbolic Regression: Recovering Mathematical Expressions from Data via Risk-Seeking Policy Gradients , author =. arXiv preprint arXiv:1912.04871 , year =. 1912.04871 , archivePrefix =
-
[6]
Advances in Neural Information Processing Systems , year =
A Unified Framework for Deep Symbolic Regression , author =. Advances in Neural Information Processing Systems , year =
-
[7]
Advances in Neural Information Processing Systems , year =
Symbolic Regression with a Learned Concept Library , author =. Advances in Neural Information Processing Systems , year =
-
[8]
Proceedings of the National Academy of Sciences , year =
SR-LLM: An Incremental Symbolic Regression Framework Driven by LLM-Based Retrieval-Augmented Generation , author =. Proceedings of the National Academy of Sciences , year =. doi:10.1073/pnas.2516995122 , url =
-
[9]
International Conference on Learning Representations , year =
SR-Scientist: Scientific Equation Discovery With Agentic AI , author =. International Conference on Learning Representations , year =
-
[10]
arXiv preprint arXiv:2506.04282 , year=
DrSR: LLM based Scientific Equation Discovery with Dual Reasoning from Data and Experience , author =. arXiv preprint arXiv:2506.04282 , year =. doi:10.48550/arXiv.2506.04282 , url =
- [11]
-
[12]
ACM Computing Surveys , volume =
Recent Advances in Symbolic Regression , author =. ACM Computing Surveys , volume =. 2025 , doi =
work page 2025
-
[13]
Journal of Data-centric Machine Learning Research , year =
Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery , author =. Journal of Data-centric Machine Learning Research , year =
-
[14]
Machine Learning and the Physical Sciences Workshop @ NeurIPS 2024 , year =
Two-Stage Coefficient Estimation in Symbolic Regression for Scientific Discovery , author =. Machine Learning and the Physical Sciences Workshop @ NeurIPS 2024 , year =
work page 2024
-
[15]
Applied Soft Computing , year =
A Two-Stage Symbolic Regression Method for Discovering Mathematical Formulas , author =. Applied Soft Computing , year =
-
[16]
In-Context Symbolic Regression: Leveraging Large Language Models for Function Discovery , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics: Student Research Workshop , year =. doi:10.18653/v1/2024.acl-srw.34 , url =
- [17]
- [18]
-
[19]
The Levenberg-Marquardt Algorithm: Implementation and Theory , author =. Numerical Analysis: Proceedings of the Biennial Conference Held at Dundee, June 28--July 1, 1977 , pages =
work page 1977
-
[20]
SIAM Journal on Scientific Computing , volume=
A subspace, interior, and conjugate gradient method for large-scale bound-constrained minimization problems , author=. SIAM Journal on Scientific Computing , volume=
-
[21]
Information Processing & Management , volume=
Term-weighting approaches in automatic text retrieval , author=. Information Processing & Management , volume=. 1988 , doi=
work page 1988
- [22]
-
[23]
Distilling free-form natural laws from experimental data , author=. Science , volume=. 2009 , doi=
work page 2009
-
[24]
Genetic Programming: On the Programming of Computers by Means of Natural Selection , author =. 1992 , publisher =
work page 1992
-
[25]
Artificial Intelligence Review , volume =
Interpretable Scientific Discovery with Symbolic Regression: A Review , author =. Artificial Intelligence Review , volume =. 2024 , doi =
work page 2024
-
[26]
Transactions on Machine Learning Research , year =
Symbolic Regression is NP-hard , author =. Transactions on Machine Learning Research , year =
-
[27]
Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , year =
Contemporary Symbolic Regression Methods and their Relative Performance , author =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , year =
-
[28]
AI Feynman: A Physics-Inspired Method for Symbolic Regression , author =. Science Advances , volume =. 2020 , doi =
work page 2020
-
[29]
Mathematical Discoveries from Program Search with Large Language Models , author=. Nature , volume=. 2024 , doi=
work page 2024
-
[30]
Machine Learning: Science and Technology , volume =
Rediscovering Orbital Mechanics with Machine Learning , author =. Machine Learning: Science and Technology , volume =. 2023 , doi =
work page 2023
-
[31]
International Conference on Learning Representations , year =
Symbolic Physics Learner: Discovering Governing Equations via Monte Carlo Tree Search , author =. International Conference on Learning Representations , year =
-
[32]
Claude 3 Haiku: Our Fastest Model Yet , author =. 2024 , howpublished =
work page 2024
-
[33]
A Comprehensive Survey of Scientific Large Language Models and Their Applications in Scientific Discovery , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.498 , url =
-
[34]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Large Language Models Can Self-Improve , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2023.emnlp-main.67 , url =
-
[35]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Logic-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =. doi:10.18653/v1/2023.findings-emnlp.248 , url =
-
[36]
Ma, Yubo and Gou, Zhibin and Hao, Junheng and Xu, Ruochen and Wang, Shuohang and Pan, Liangming and Yang, Yujiu and Cao, Yixin and Sun, Aixin , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.880 , url =
-
[37]
Gupta, Priyanshu and Kirtania, Shashank and Singha, Ananya and Gulwani, Sumit and Radhakrishna, Arjun and Soares, Gustavo and Shi, Sherry , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.477 , url =
-
[38]
Xiang, Yufei and Shen, Yiqun and Zhang, Yeqin and Nguyen, Cam-Tu , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.268 , url =
-
[39]
Compilers Principles, Techniques , author =
-
[40]
Tu, Songjun and Ma, Yiwen and Lin, Jiahao and Zhang, Qichao and Lan, Xiangyuan and Li, Junfeng and Xu, Nan and Li, Linjing and Zhao, Dongbin , journal =
-
[41]
arXiv preprint arXiv:2603.28716 , year =
Dynamic Dual-Granularity Skill Bank for Agentic RL , author =. arXiv preprint arXiv:2603.28716 , year =
work page internal anchor Pith review arXiv
-
[42]
arXiv preprint arXiv:2602.12259 , year=
Think like a Scientist: Physics-guided LLM Agent for Equation Discovery , author =. arXiv preprint arXiv:2602.12259 , year =
-
[43]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery , author =. arXiv preprint arXiv:2408.06292 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
and Cox, Sam and Schilter, Oliver and Baldassari, Carlo and White, Andrew D
Bran, Andres M. and Cox, Sam and Schilter, Oliver and Baldassari, Carlo and White, Andrew D. and Schwaller, Philippe , journal =
-
[45]
Sun, Jingbo and Chong, Wenyue and Tu, Songjun and Zhang, Qichao and Zhang, Yaocheng and Chai, Jiajun and Wang, Xiaohan and Lin, Wei and Yin, Guojun and Zhao, Dongbin , journal =
-
[46]
Du, Mengge and Chen, Yuntian and Wang, Zhongzheng and Nie, Longfeng and Zhang, Dongxiao , journal =
-
[47]
arXiv preprint arXiv:2402.17879 , year =
Automated Statistical Model Discovery with Language Models , author =. arXiv preprint arXiv:2402.17879 , year =
-
[48]
Agent Laboratory: Using LLM Agents as Research Assistants
Agent Laboratory: Using LLM Agents as Research Assistants , author =. arXiv preprint arXiv:2501.04227 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:2505.13259 , year =
From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery , author =. arXiv preprint arXiv:2505.13259 , year =
-
[50]
Proceedings of the First Instructional Conference on Machine Learning , pages =
Using TF-IDF to Determine Word Relevance in Document Queries , author =. Proceedings of the First Instructional Conference on Machine Learning , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.