Collective Hallucination in Multi-Agent LLMs:Modeling and Defense
Pith reviewed 2026-06-27 19:51 UTC · model grok-4.3
The pith
Hallucinations spread through multi-agent LLM interactions as a network diffusion process, but an interaction-aware control method can reduce them by up to 39 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
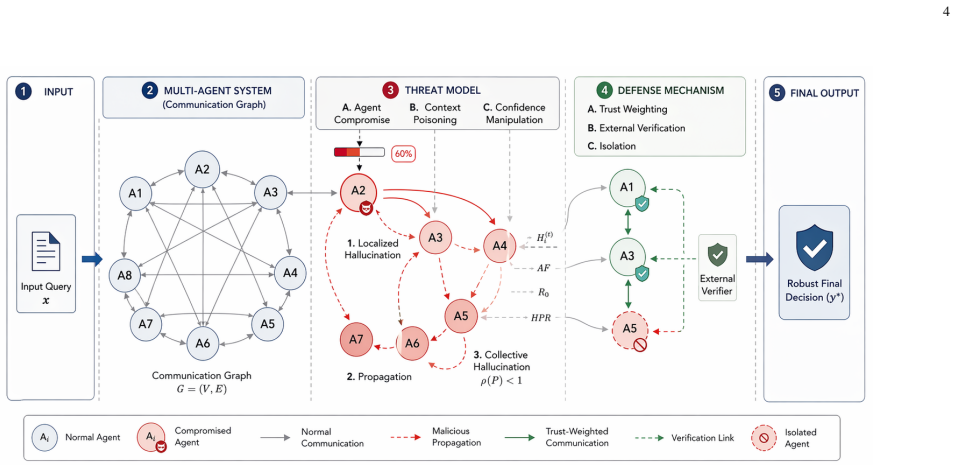
Hallucination in multi-agent LLM systems is governed by both individual model reliability and system-level interaction dynamics, including communication topology, confidence coupling, and recursive information flow. Modeling it as a network process allows an interaction-aware control method combining confidence-weighted aggregation, adaptive impact regulation, external claim verification, and selective isolation to suppress error propagation.
What carries the argument
Network model of hallucination diffusion, with agents as nodes and information exchanges as edges, paired with the interaction-aware control method that regulates propagation.
If this is right
- Collective reliability rises when defense design accounts for communication topology and recursive flow.
- Adaptive impact regulation keeps performance stable across multiple reasoning rounds.
- Selective isolation of low-confidence agents limits the reach of adversarial perturbations.
- External claim verification combined with internal weighting improves both accuracy and consistency metrics.
Where Pith is reading between the lines
- The same network framing could guide defenses in other distributed decision systems that exchange uncertain outputs.
- Topology adjustments such as reducing dense connections might serve as a low-cost complement to the listed controls.
- Overfitting risk in parameter tuning suggests the need for cross-LLM validation beyond the two question-answering benchmarks.
- If confidence signals prove unreliable, heavier reliance on external verification becomes the dominant lever.
Load-bearing premise
The proposed network model of hallucination diffusion accurately reflects how real LLM agents behave and spread errors during interactions.
What would settle it
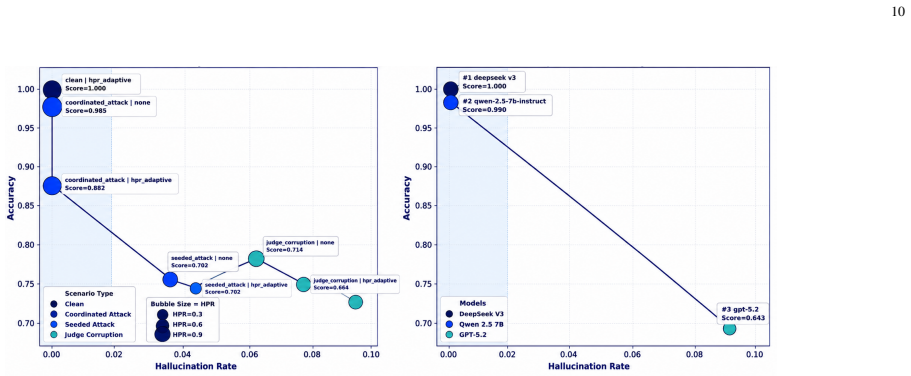
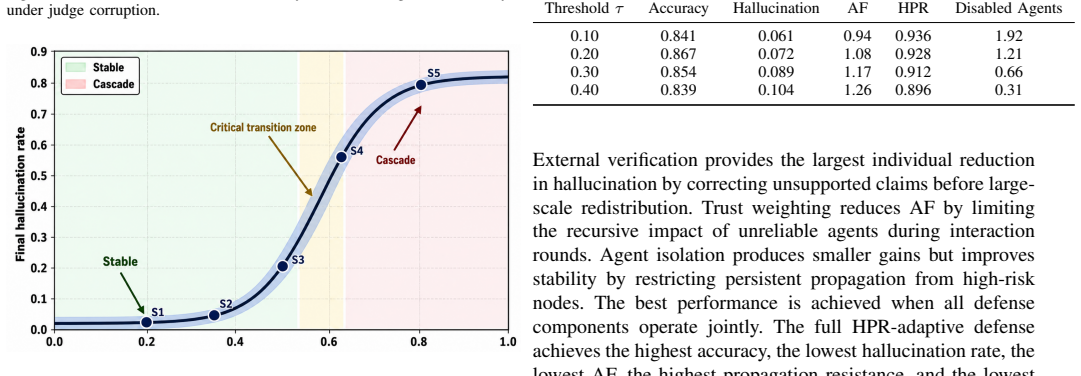
Applying the same multi-agent setup and control method to new benchmarks or different LLMs and observing hallucination amplification above 1.08 or factual accuracy gains below the reported levels.
Figures
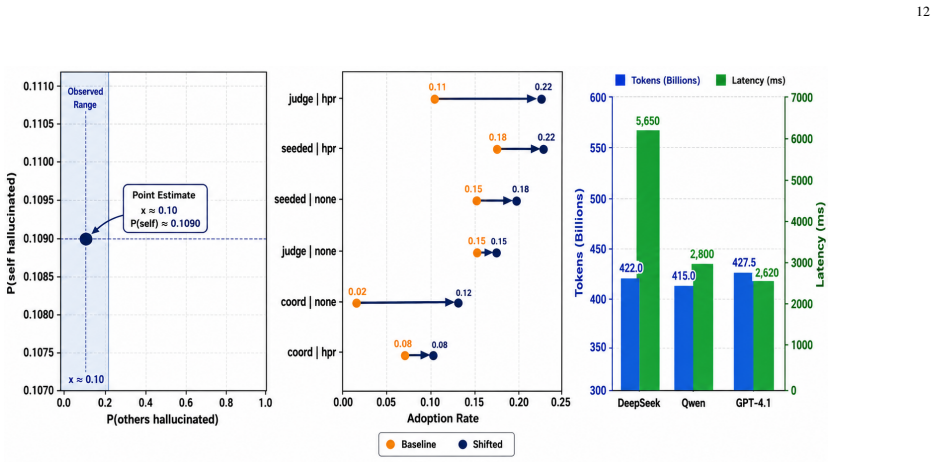
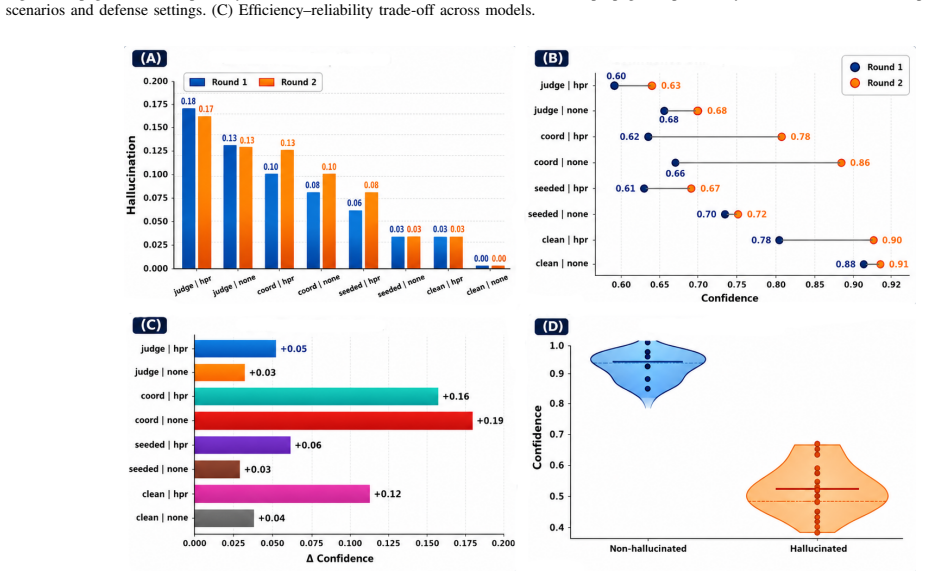
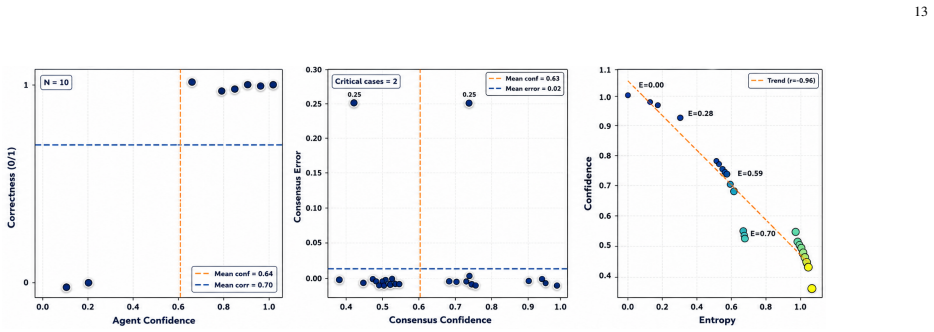
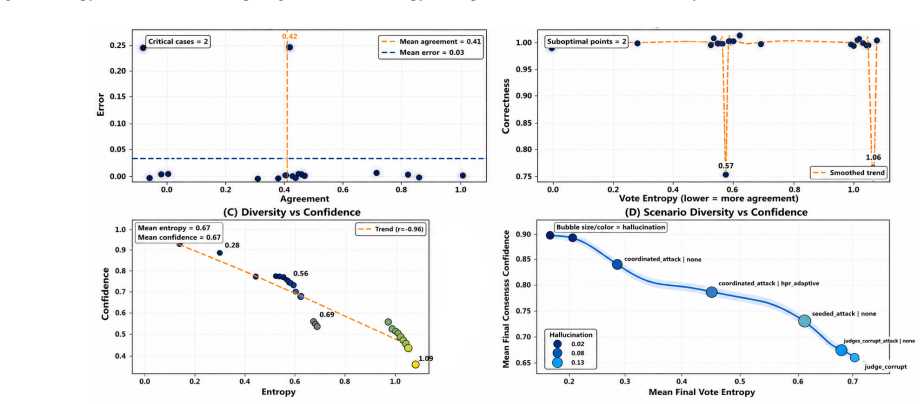
read the original abstract
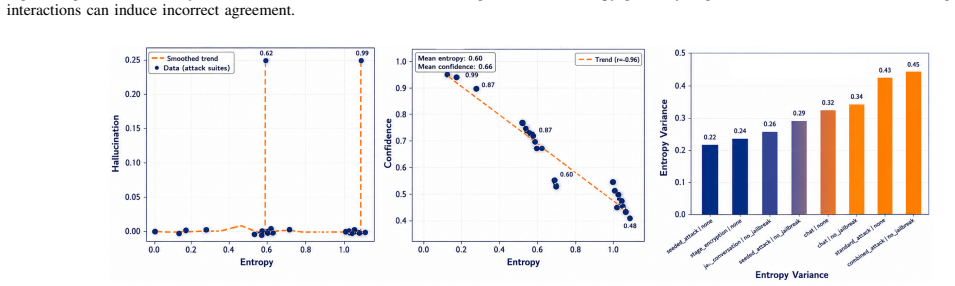
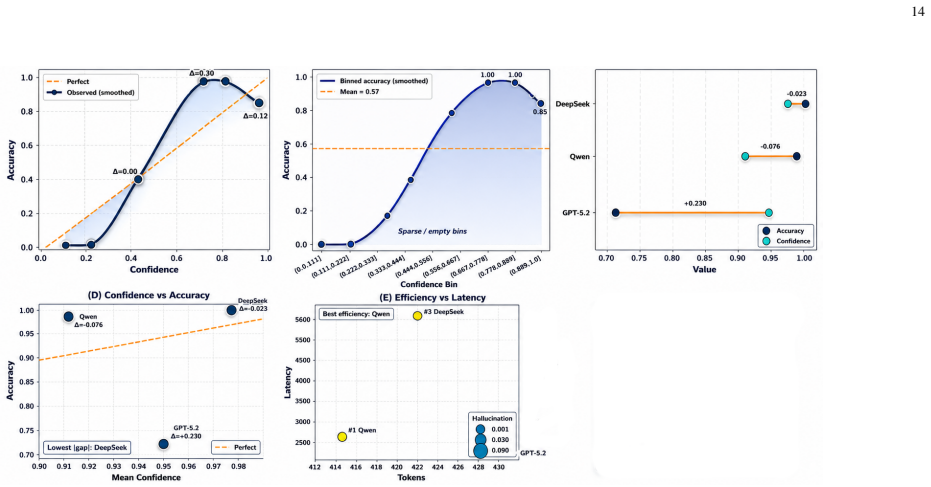
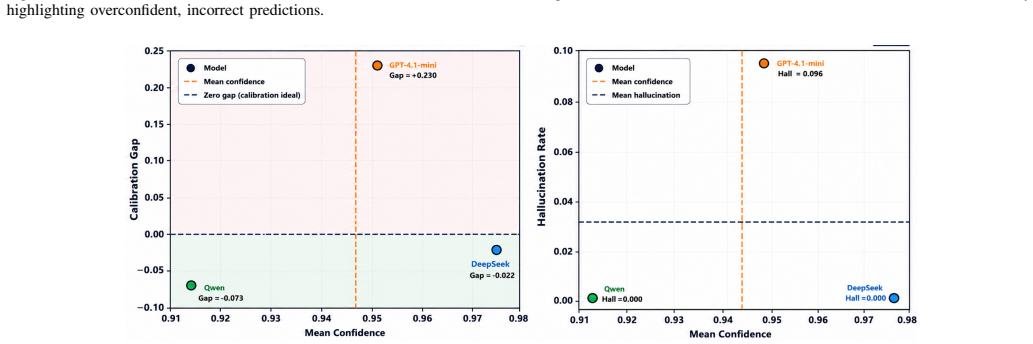
Hallucinations in large language models (LLMs) create heightened risks in multi-agent settings, where recursive agent interactions can propagate, reinforce, and amplify unsupported claims. This paper models hallucination as a system-level, time-evolving process across a network of interacting LLM agents, where nodes represent agents and edges encode information exchange. The proposed formulation captures how hallucinated claims diffuse through communication topologies, intensify under adversarial perturbations, and affect collective reliability across reasoning rounds. To suppress error propagation, we introduce an interaction-aware control method that combines confidence-weighted aggregation, adaptive impact regulation, external claim verification, and selective isolation of unreliable agents. Experiments on TruthfulQA and TriviaQA show that the proposed method reduces hallucination by up to 39.0% relative to undefended multi-agent reasoning, improves factual accuracy from 0.79 to 0.87, and increases semantic consistency from 0.75 to 0.84. Under adversarial conditions, the method limits hallucination amplification to 1.08, compared with 1.45 without adaptive control, maintaining stable collective behavior across recursive interaction rounds. These results indicate that hallucination in multi-agent LLM systems is governed by both individual model reliability and system-level interaction dynamics, including communication topology, confidence coupling, and recursive information flow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models hallucination in multi-agent LLMs as a time-evolving diffusion process on an agent interaction network and introduces an interaction-aware control method (confidence-weighted aggregation, adaptive impact regulation, external verification, selective isolation) to suppress propagation. Experiments on TruthfulQA and TriviaQA report up to 39% hallucination reduction vs. undefended multi-agent reasoning, factual accuracy rising from 0.79 to 0.87, semantic consistency from 0.75 to 0.84, and adversarial amplification limited to 1.08 (vs. 1.45 without control).
Significance. If the diffusion model were shown to reproduce real LLM interaction statistics, the framework would offer a system-level approach to collective reliability in multi-agent setups, with the reported numerical gains indicating potential practical value. The work correctly identifies topology, confidence coupling, and recursion as relevant factors beyond single-model reliability.
major comments (3)
- [Modeling section] The network model of hallucination diffusion (central to the control design) lacks direct empirical validation: no section compares the model's predicted diffusion rates, amplification factors, or topology dependence against observed claim propagation when multiple LLM instances exchange messages on the same benchmarks.
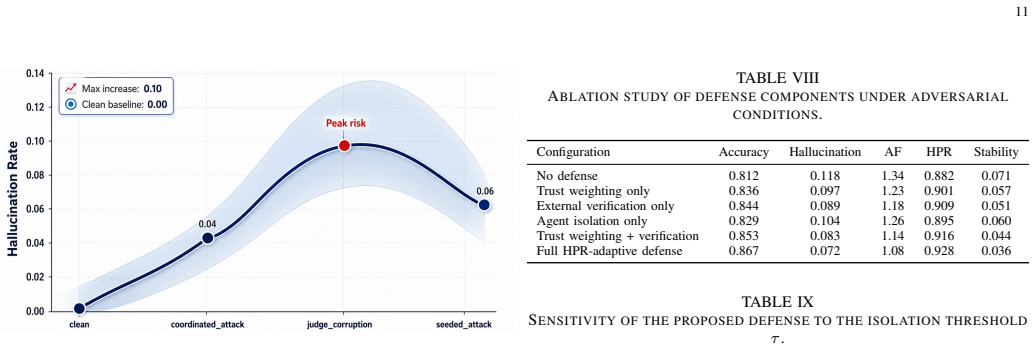
- [Experiments / Evaluation section] Table/figure reporting the 39% reduction, 0.79→0.87 accuracy, and 1.08 amplification limits the gains to defended outputs only; the evaluation does not test whether the control parameters (derived from the diffusion model) remain effective when the underlying network abstraction is replaced by actual multi-agent traces.
- [Control method / Experiments] The adaptive control parameters appear tuned to produce the reported metrics on TruthfulQA/TriviaQA; without an explicit statement or ablation showing parameter selection independent of the test sets, the claimed robustness under adversarial conditions risks circularity.
minor comments (2)
- [Modeling] Notation for the diffusion process (e.g., time-evolving edge weights or confidence coupling) should be defined with explicit equations before the control method is introduced.
- [Abstract / Experiments] The abstract and results section should state the number of independent runs, statistical significance tests, and exact definitions of 'hallucination' and 'semantic consistency' metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond point-by-point to the major comments below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Modeling section] The network model of hallucination diffusion (central to the control design) lacks direct empirical validation: no section compares the model's predicted diffusion rates, amplification factors, or topology dependence against observed claim propagation when multiple LLM instances exchange messages on the same benchmarks.
Authors: We agree that the manuscript does not include a direct empirical comparison of the diffusion model's predicted rates, amplification factors, or topology effects against observed propagation statistics from actual multi-agent LLM message exchanges on the benchmarks. The diffusion model is introduced as a theoretical framework to derive the control mechanisms, with experiments focused on evaluating the resulting control method rather than validating the model's predictive accuracy against real traces. We will revise the modeling section to explicitly state this scope limitation and suggest directions for future empirical calibration of the model parameters. revision: partial
-
Referee: [Experiments / Evaluation section] Table/figure reporting the 39% reduction, 0.79→0.87 accuracy, and 1.08 amplification limits the gains to defended outputs only; the evaluation does not test whether the control parameters (derived from the diffusion model) remain effective when the underlying network abstraction is replaced by actual multi-agent traces.
Authors: The reported experiments instantiate the multi-agent system using actual LLM instances that exchange messages on TruthfulQA and TriviaQA, so the results already reflect performance under real interaction traces rather than purely abstract network simulations. The control parameters are applied directly within these LLM-based interactions. We will revise the evaluation section to clarify this distinction and add explicit description of how the agent interaction traces are generated and used. revision: yes
-
Referee: [Control method / Experiments] The adaptive control parameters appear tuned to produce the reported metrics on TruthfulQA/TriviaQA; without an explicit statement or ablation showing parameter selection independent of the test sets, the claimed robustness under adversarial conditions risks circularity.
Authors: The parameters are derived analytically from the diffusion model properties (e.g., confidence coupling and topology) rather than optimized on the test sets. To eliminate any perception of circularity, we will add an explicit statement in the control method section and include a parameter sensitivity analysis or ablation in the experiments section demonstrating selection independent of the specific benchmark instances. revision: yes
- Direct empirical validation of the diffusion model's predicted diffusion rates and topology dependence against observed claim propagation in multi-agent LLM interactions.
Circularity Check
No circularity: model and control validated on external benchmarks
full rationale
The paper introduces a diffusion model on agent networks and an interaction-aware control method, then reports empirical gains on TruthfulQA and TriviaQA relative to undefended baselines. No equations, parameter-fitting steps, or self-citations are shown that would make the reported reductions (39% hallucination drop, accuracy 0.79→0.87) equivalent to the inputs by construction. The evaluation uses standard external datasets and direct comparisons, keeping the derivation self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Delayed Verification Destabilizes Multi-Agent LLM Belief: Instability Thresholds and Optimal Corrector Placement
Models delayed verification in multi-agent LLMs as graph consensus, derives stability thresholds (inverse golden ratio for delay two) via grounded Laplacian, and gives a supermodular greedy rule for corrector placemen...
Reference graph
Works this paper leans on
-
[1]
A survey on the optimization of large language model-based agents,
S. Du, J. Zhao, J. Shi, Z. Xie, X. Jiang, Y . Bai, and L. He, “A survey on the optimization of large language model-based agents,”ACM Computing Surveys, vol. 58, no. 9, pp. 1–37, 2026
2026
-
[2]
Llm and ai agents for autonomous systems: A survey of applications, datasets, and security challenges,
M. A. Ferrag, A. Lakas, N. Tihanyi, and M. Debbah, “Llm and ai agents for autonomous systems: A survey of applications, datasets, and security challenges,”IEEE Open Journal of Intelligent Transportation Systems, vol. 7, pp. 615–657, 2026
2026
-
[3]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations, 2023
2023
-
[4]
Autogen: Enabling next-gen llm applications via multi-agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “Autogen: Enabling next-gen llm applications via multi-agent conversation,”arXiv preprint arXiv:2308.08155, 2023
Pith/arXiv arXiv 2023
-
[5]
Camel: Communicative agents for “mind
G. Li, H. A. A. K. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicative agents for “mind” exploration of large language model society,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[6]
Trustworthiness of large language models: hallu- cinations,
N. Brunelloet al., “Trustworthiness of large language models: hallu- cinations,”Challenges and Applications of Generative Large Language Models, pp. 107–126, 2026
2026
-
[7]
Cao,Factual Consistency in Neural Text Generation: Detecting, Correcting, and Understanding Hallucinations
M. Cao,Factual Consistency in Neural Text Generation: Detecting, Correcting, and Understanding Hallucinations. McGill University (Canada), 2025
2025
-
[8]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[9]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,”Transactions of the ACL, 2022
2022
-
[10]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024
2024
-
[11]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Kuttler, M. Lewis, W.-t. Yih, T. Rocktaschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[12]
Knowhalu: Hal- lucination detection via multi-form knowledge based factual checking,
J. Zhang, C. Xu, Y . Gai, F. Lecue, D. Song, and B. Li, “Knowhalu: Hal- lucination detection via multi-form knowledge based factual checking,” arXiv preprint arXiv:2404.02935, 2024
arXiv 2024
-
[13]
Hallucination detection in large language models with metamorphic relations, 2025a,
B. Yang, M. Mamun, J. M. Zhang, and G. Uddin, “Hallucination detection in large language models with metamorphic relations, 2025a,” URL https://arxiv. org/abs/2502.15844
-
[14]
Selfcheckgpt: Zero-resource black-box hallucination detection,
P. Manakul, A. Liusie, and M. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection,” inEMNLP, 2023
2023
-
[15]
Hallucinot: Hallucination detection through context and common knowledge verification,
B. Paudel, A. Lyzhov, P. Joshi, and P. Anand, “Hallucinot: Hallucination detection through context and common knowledge verification,”arXiv preprint arXiv:2504.07069, 2025
arXiv 2025
-
[16]
Hallucination detection in llms using spectral features of attention maps,
J. Binkowski, D. Janiak, A. Sawczyn, B. Gabrys, and T. J. Kajdanowicz, “Hallucination detection in llms using spectral features of attention maps,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 365–24 396
2025
-
[17]
Improving factuality and reasoning in language models through multiagent debate,
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improving factuality and reasoning in language models through multiagent debate,” arXiv preprint arXiv:2305.14325, 2023
Pith/arXiv arXiv 2023
-
[18]
Hallucina- tion detection in large language models with metamorphic relations,
B. Yang, M. A. Al Mamun, J. M. Zhang, and G. Uddin, “Hallucina- tion detection in large language models with metamorphic relations,” Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 1–21, 2025
2025
-
[19]
Knowledge graphs, large language models, and hallucinations: An nlp perspective,
E. Lavrinovicset al., “Knowledge graphs, large language models, and hallucinations: An nlp perspective,”Web Semantics, 2025
2025
-
[20]
Mitigating hallucinations in sysml v2 generation using llms and a tri-layered knowledge graph reasoning framework,
R. A. Qualis, “Mitigating hallucinations in sysml v2 generation using llms and a tri-layered knowledge graph reasoning framework,” in2025 ACM/IEEE 28th International Conference on Model Driven Engineering Languages and Systems Companion (MODELS-C). IEEE, 2025, pp. 357–366
2025
-
[21]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, pp. 625–630, 2024
2024
-
[22]
Hallucination detection in llms using spectral features of attention maps,
J. Binkowski, D. Janiak, A. Sawczyn, B. Gabrys, and T. Kajdanowicz, “Hallucination detection in llms using spectral features of attention maps,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 354–24 385
2025
-
[23]
G-eval: Nlg evaluation using gpt-4 with better human alignment,
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: Nlg evaluation using gpt-4 with better human alignment,”arXiv preprint arXiv:2303.16634, 2023
Pith/arXiv arXiv 2023
-
[24]
Halluci- nations in medical devices,
J. Granstedt, P. Kc, R. Deshpande, V . Garcia, and A. Badano, “Halluci- nations in medical devices,”Artificial Intelligence in the Life Sciences, vol. 8, p. 100145, 2025
2025
-
[25]
Probabilistic bernoulli and euler polynomials,
T. Kim and D. Kim, “Probabilistic bernoulli and euler polynomials,” Russian Journal of Mathematical Physics, vol. 31, no. 1, pp. 94–105, 2024
2024
-
[26]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,” inProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2017, pp. 1601– 1611
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.