Customer Churn Prediction on Structured Data Using FT-Transformer and Stacking Ensembles
Pith reviewed 2026-06-29 18:08 UTC · model grok-4.3
The pith
A hybrid FT-Transformer and XGBoost stacking model raises F1 to 62.10 percent on bank churn data by combining self-attention interactions with tree decision boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
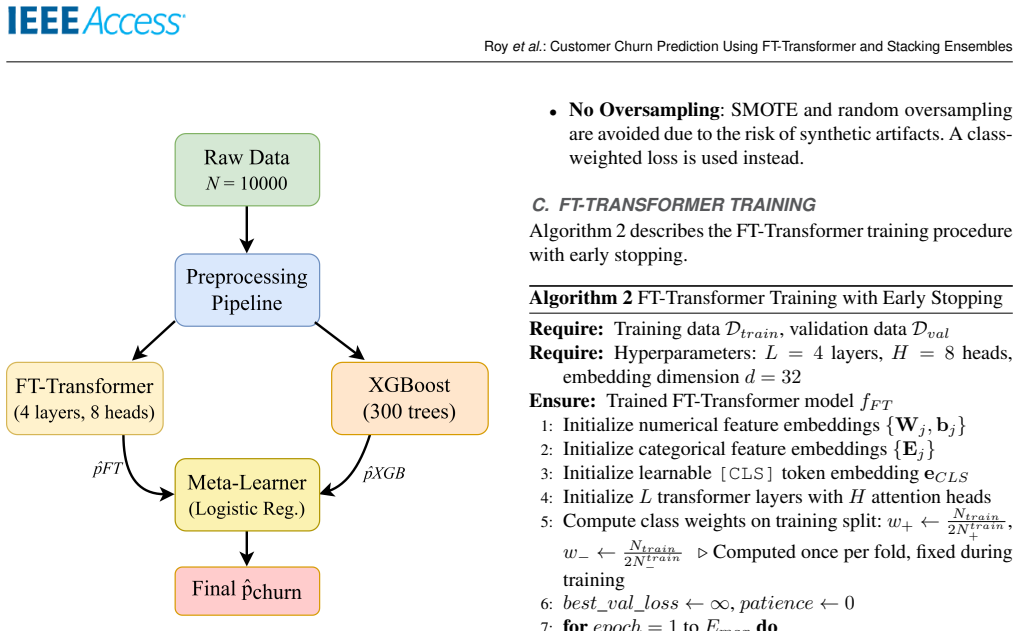
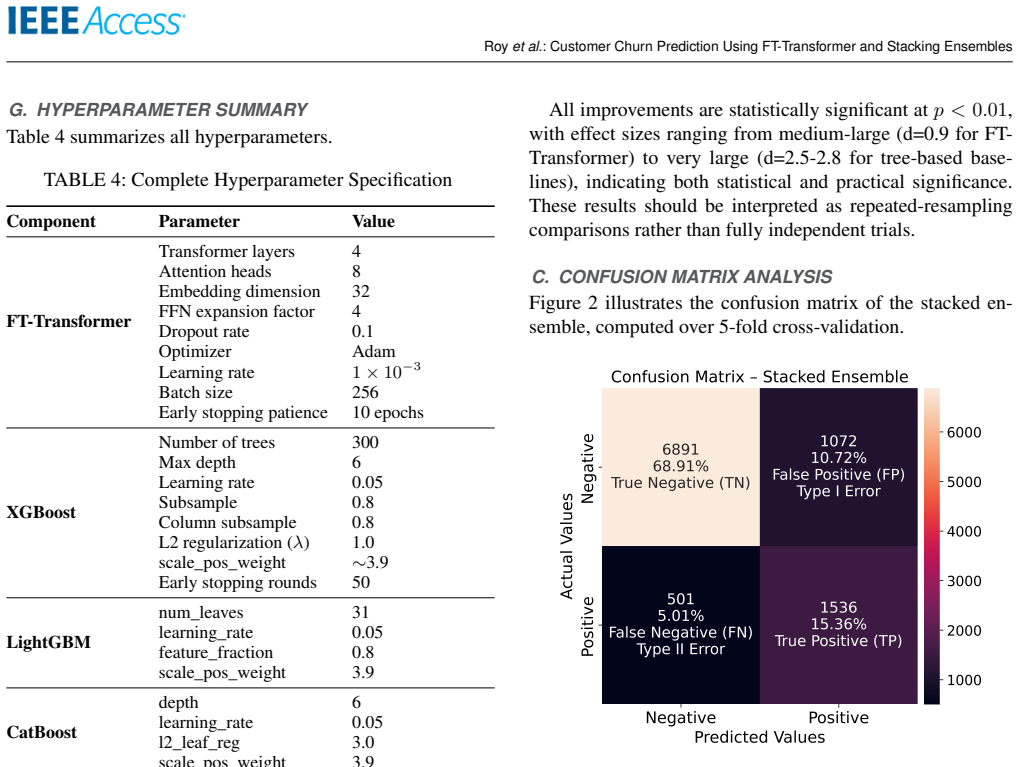
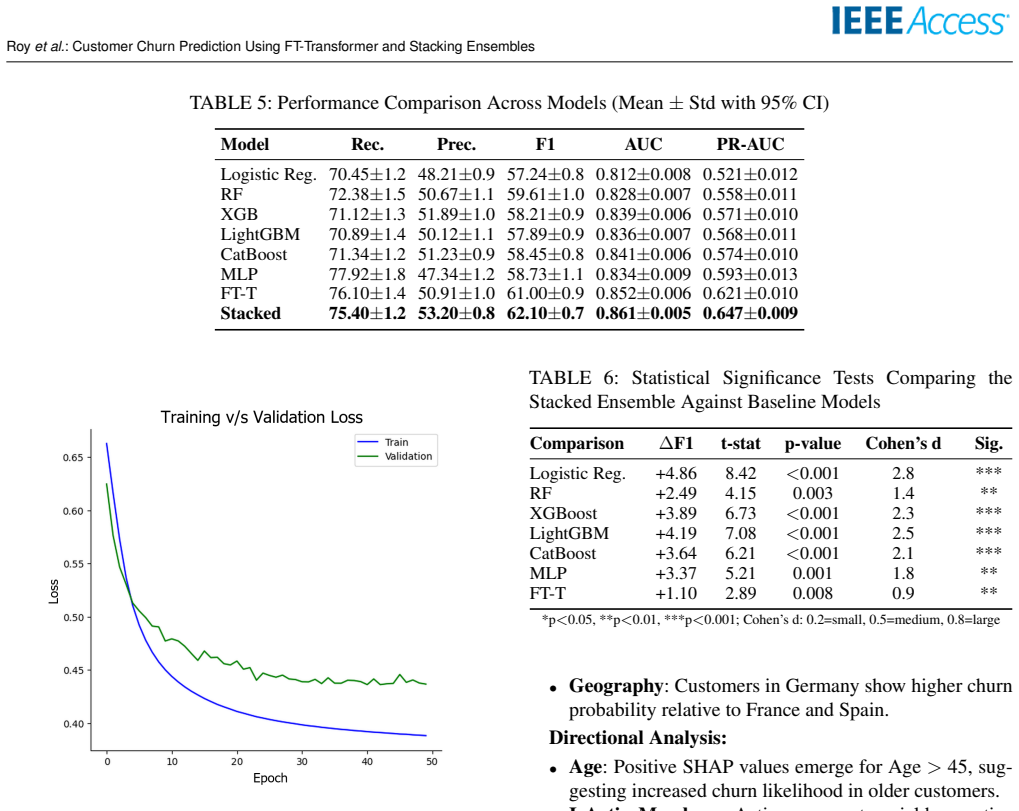
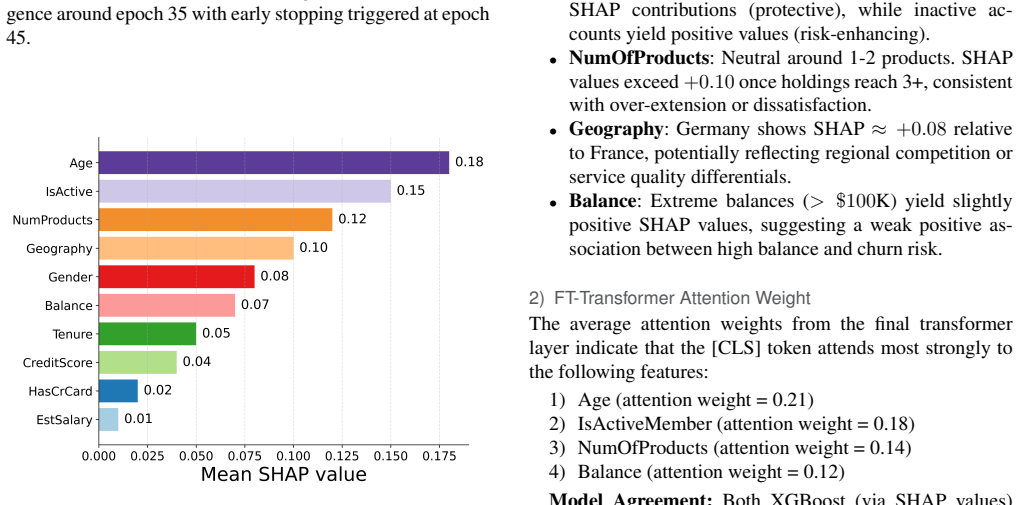
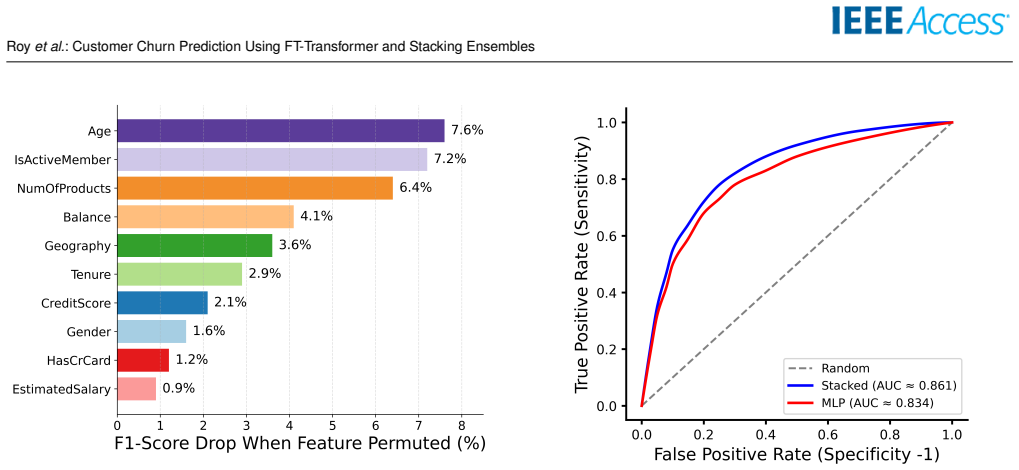
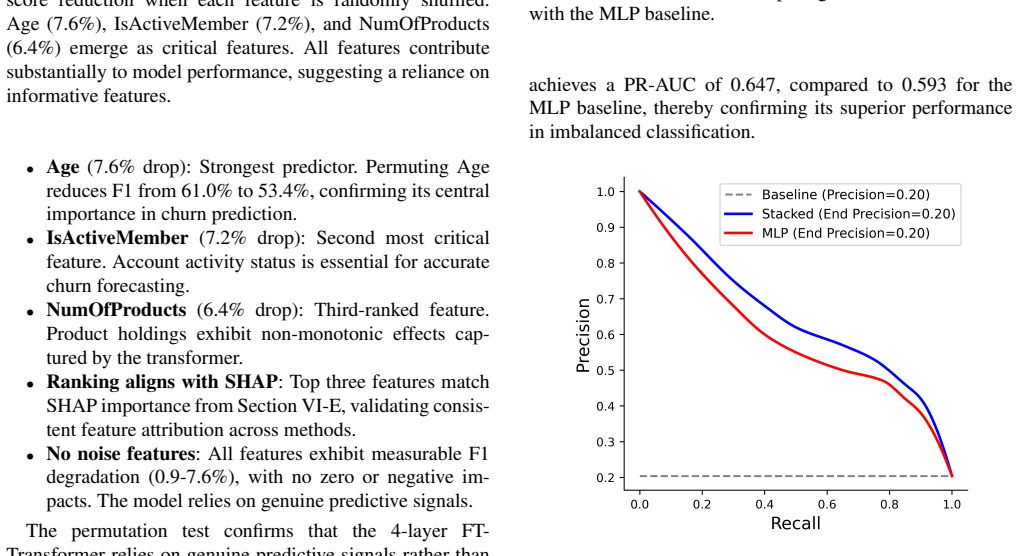
The paper claims that the FT-Transformer captures higher-order feature interactions through self-attention while XGBoost supplies complementary gradient-boosted boundaries; their out-of-fold stacking with a logistic regression meta-learner then recalibrates probabilities and learns optimal weights, yielding 62.10 percent F1, 0.861 AUC-ROC and 0.647 PR-AUC on the bank dataset and beating the MLP baseline by 3.37 F1 points and 0.027 AUC under repeated cross-validation.
What carries the argument
Calibration-aware out-of-fold stacking of FT-Transformer and XGBoost, where the transformer supplies attention-based interaction modeling and the trees supply decision-boundary modeling before the logistic meta-learner combines and recalibrates their outputs.
If this is right
- Ablation results establish that both the transformer component and the stacking meta-learner contribute materially to the final scores.
- Class-weighted loss functions address imbalance without generating synthetic minority samples, preserving the original distribution.
- Out-of-fold stacking with logistic regression produces better-calibrated probabilities than either base model alone.
- The full pipeline supplies a reproducible reference for churn tasks on heterogeneous tabular inputs containing numeric and categorical columns.
- Performance holds under 95 percent confidence intervals derived from the repeated cross-validation folds.
Where Pith is reading between the lines
- The same stacking pattern could be applied to other imbalanced tabular tasks such as fraud detection or credit default to test whether the interaction capture generalizes.
- Replacing the logistic meta-learner with a small neural net might further improve calibration on datasets with stronger nonlinear dependencies.
- Releasing the exact hyperparameter grids and seed values would allow independent verification of whether the gains survive different optimization budgets.
- The emphasis on avoiding oversampling suggests the method may preserve minority-class structure better than SMOTE-style approaches on very small positive classes.
Load-bearing premise
The measured gains arise from the hybrid architecture and stacking rather than from hyperparameter search or from properties unique to the single public bank dataset.
What would settle it
Repeating the identical 5x5 cross-validation protocol on a second public tabular churn dataset and obtaining no statistically significant lift over the MLP baseline would falsify the claim of consistent hybrid superiority.
Figures

read the original abstract
Customer churn prediction is essential across data-driven industries such as insurance, digital banking, eCommerce, and subscription platforms, where retaining existing customers is typically more cost-effective than acquiring new ones. Predicting churn on structured datasets remains challenging due to class imbalance, nonlinear feature interactions, and heterogeneous feature types. Tree-based ensemble methods consistently demonstrate strong performance in these contexts, often outperforming conventional neural networks. This study introduces a validated hybrid architecture that integrates feature-tokenized transformers (FT-Transformer) with gradient-boosted trees through calibration-aware stacking. The proposed framework addresses persistent gaps in statistical validation, probability calibration, and reproducibility found in prior research. The FT-Transformer captures higher-order feature interactions using self-attention, while XGBoost captures gradient-boosted decision boundaries with complementary inductive biases. Class imbalance is handled using class-weighted loss functions, thereby avoiding synthetic oversampling and preserving minority-class distributions. The models are ensembled using out-of-fold (OOF) stacking with a logistic regression meta-learner, which recalibrates overconfident base model outputs and learns optimal combination weights. On a public bank churn dataset, the hybrid model achieves 62.10% F1, 0.861 AUC-ROC, and 0.647 PR-AUC, outperforming the Multi-Layer Perceptron (MLP) baseline by 3.37 F1 points and 0.027 AUC under 5x5 cross-validation with 95% confidence intervals reported. Ablation studies demonstrate that both the transformer component and stacking strategy contribute materially to performance. The proposed methodology offers a reproducible and extensible reference architecture for contemporary churn prediction on structured tabular data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a hybrid architecture for customer churn prediction on structured tabular data that combines an FT-Transformer (for higher-order feature interactions via self-attention) with XGBoost (for gradient-boosted decision boundaries) through out-of-fold stacking with a logistic regression meta-learner for calibration. Class imbalance is addressed via class-weighted losses rather than oversampling. On a public bank churn dataset the hybrid reports 62.10% F1, 0.861 AUC-ROC and 0.647 PR-AUC under 5 imes5 cross-validation with 95% confidence intervals, outperforming an MLP baseline by 3.37 F1 points and 0.027 AUC; ablation studies are stated to show material contributions from both the transformer component and the stacking strategy.
Significance. If the performance deltas can be shown to arise from the claimed inductive-bias complementarity rather than unequal hyperparameter effort, the work would supply a reproducible reference architecture that explicitly addresses calibration, statistical validation and reproducibility gaps noted in prior churn-prediction literature. The use of a public dataset, nested cross-validation and reported confidence intervals is a positive step toward falsifiable empirical claims.
major comments (2)
- [Abstract] Abstract (performance claims paragraph): the headline attribution of the 3.37 F1 / 0.027 AUC improvement to the FT-Transformer + XGBoost OOF stacking architecture requires that the MLP baseline received an equivalent hyperparameter optimization protocol (search space, trial count, compute budget). No such protocol is described, so the reported deltas could arise from optimization disparity on a standard public dataset rather than the claimed architecture.
- [Ablation studies] Ablation studies paragraph: the claim that 'ablation studies demonstrate that both the transformer component and stacking strategy contribute materially' is load-bearing for the central contribution statement, yet the manuscript supplies no quantitative controls confirming that hyperparameter search effort was matched across the ablated variants and the MLP baseline.
minor comments (1)
- [Abstract] The abstract would benefit from an explicit citation or link to the precise public bank churn dataset used (e.g., Kaggle identifier) to support reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for these precise comments on hyperparameter comparability. We agree that explicit documentation of optimization protocols is required to substantiate the performance deltas and ablation claims. The revised manuscript will incorporate the requested details without altering the core experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract (performance claims paragraph): the headline attribution of the 3.37 F1 / 0.027 AUC improvement to the FT-Transformer + XGBoost OOF stacking architecture requires that the MLP baseline received an equivalent hyperparameter optimization protocol (search space, trial count, compute budget). No such protocol is described, so the reported deltas could arise from optimization disparity on a standard public dataset rather than the claimed architecture.
Authors: We agree that the absence of an explicit hyperparameter protocol description for the MLP baseline weakens the attribution of gains. In revision we will add a new subsection (and corresponding appendix table) that specifies the identical Bayesian optimization procedure (search space, trial budget, early-stopping rule, and compute allocation) applied to the MLP, FT-Transformer, XGBoost, and all ensemble variants. This documentation will confirm that the reported 3.37 F1 / 0.027 AUC margins were obtained under matched effort. revision: yes
-
Referee: [Ablation studies] Ablation studies paragraph: the claim that 'ablation studies demonstrate that both the transformer component and stacking strategy contribute materially' is load-bearing for the central contribution statement, yet the manuscript supplies no quantitative controls confirming that hyperparameter search effort was matched across the ablated variants and the MLP baseline.
Authors: We concur that the ablation paragraph must be supported by evidence of matched hyperparameter effort. The revised manuscript will expand the ablation section with an explicit table listing, for each ablated configuration (FT-Transformer alone, XGBoost alone, no-stacking ensemble, MLP), the search space size, number of trials executed, and final validation scores obtained under the same optimization budget used for the full hybrid model. This will provide the quantitative controls needed to attribute performance differences to architectural components rather than tuning disparity. revision: yes
Circularity Check
No circularity: empirical results on public dataset are self-contained
full rationale
The paper reports standard machine-learning training and 5x5 cross-validation performance of FT-Transformer, XGBoost, MLP, and their OOF-stacked ensemble on a fixed public bank-churn dataset. No equations, uniqueness theorems, or self-citations are invoked to derive the reported metrics; the numbers are obtained by fitting models to held-out folds and computing F1/AUC/PR-AUC directly from those predictions. Ablation results compare variants on the same data splits without any parameter being fitted to a target quantity and then re-presented as a prediction. The central claim therefore rests on external data and conventional evaluation rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- model hyperparameters
- class weights
axioms (2)
- domain assumption The chosen public bank churn dataset is representative of real-world churn scenarios
- domain assumption Out-of-fold stacking with logistic regression meta-learner provides calibrated and optimal combination
Reference graph
Works this paper leans on
-
[1]
Zero defections: Quality comes to services,
F. F. Reichheld and W. E. Sasser, “Zero defections: Quality comes to services,” Harvard Business Review, vol. 68, no. 5, pp. 105–111, 1990. [Online]. Available: https://hbr.org/1990/09/ zero-defections-quality-comes-to-services
1990
-
[2]
De- fection detection: Measuring and understanding the predictive accuracy of customer churn models,
S. A. Neslin, S. Gupta, W. A. Kamakura, J. Lu, and C. H. Mason, “De- fection detection: Measuring and understanding the predictive accuracy of customer churn models,” Journal of Marketing Research, vol. 43, no. 2, pp. 204–211, 2006
2006
-
[3]
Handling class imbalance in customer churn prediction,
J. Burez and D. Van den Poel, “Handling class imbalance in customer churn prediction,” Expert Systems with Applications, vol. 36, no. 3, pp. 4626–4636, 2009
2009
-
[4]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 785–794
2016
-
[5]
Revisiting deep learning models for tabular data,
Y . Gorishniy, I. Rubachev, V . Khrulkov, and A. Babenko, “Revisiting deep learning models for tabular data,” in Advances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 18 932– 18 943
2021
-
[6]
Why do tree-based models still outperform deep learning on tabular data?
L. Grinsztajn, E. Oyallon, and G. Varoquaux, “Why do tree-based models still outperform deep learning on tabular data?” in Advances in Neural Information Processing Systems, vol. 35, 2022
2022
-
[7]
Tabtransformer: Tabular data modeling using contextual embeddings,
X. Huang, A. Khetan, M. Cvitkovic, and Z. Karnin, “Tabtransformer: Tabular data modeling using contextual embeddings,” in Advances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 6543–6553
2020
-
[8]
Saint: Improved neural networks for tabular data via row attention and contrastive pre-training,
G. Somepalli, M. Goldblum, A. Schwarzschild, C. B. Bruss, and T. Gold- stein, “Saint: Improved neural networks for tabular data via row attention and contrastive pre-training,” in Advances in Neural Information Process- ing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 6111–6122
2021
-
[9]
Telecom churn prediction system based on ensemble learning using feature grouping,
T. Xu, Y . Ma, and K. Kim, “Telecom churn prediction system based on ensemble learning using feature grouping,” Applied Sciences, vol. 11, no. 11, p. 4742, 2021
2021
-
[10]
Customer personality analysis for churn prediction using hybrid ensemble models and class balancing techniques,
N. Ahmad, M. J. Awan, H. Nobanee, A. M. Zain, A. Naseem, and A. Mahmoud, “Customer personality analysis for churn prediction using hybrid ensemble models and class balancing techniques,” IEEE Access, vol. 12, pp. 1865–1879, 2024
2024
-
[11]
Sampling- based novel heterogeneous multi-layer stacking ensemble method for telecom customer churn prediction,
F. E. Usman-Hamza, A. O. Balogun, R. T. Amosa, L. F. Capretz, H. A. Mojeed, S. A. Salihu, A. G. Akintola, and M. A. Mabayoje, “Sampling- based novel heterogeneous multi-layer stacking ensemble method for telecom customer churn prediction,” Scientific African, vol. 24, p. e02223, 2024
2024
-
[12]
Building compre- hensible customer churn prediction models with advanced rule induction techniques,
W. Verbeke, D. Martens, C. Mues, and B. Baesens, “Building compre- hensible customer churn prediction models with advanced rule induction techniques,” Expert Systems with Applications, vol. 38, no. 3, pp. 2354– 2364, 2011
2011
-
[13]
New insights into churn prediction in the telecommunication sector: A profit driven data mining approach,
W. Verbeke, K. Dejaeger, D. Martens, J. Hur, and B. Baesens, “New insights into churn prediction in the telecommunication sector: A profit driven data mining approach,” European Journal of Operational Research, vol. 218, no. 1, pp. 211–229, 2012
2012
-
[14]
Baesens, Analytics in a Big Data World
B. Baesens, Analytics in a Big Data World. Hoboken, NJ: Wiley, 2014
2014
-
[15]
Predictive banking: A deep ensemble customer churn prediction model for enhanced customer retention,
C. Warnakulaarachchi and S. Kumarapathirage, “Predictive banking: A deep ensemble customer churn prediction model for enhanced customer retention,” in World Conference on Information Systems and Technolo- gies. Cham: Springer Nature Switzerland, 2025, pp. 469–483
2025
-
[16]
Ensemble methods in machine learning,
T. G. Dietterich, “Ensemble methods in machine learning,” in Multiple Classifier Systems, ser. Lecture Notes in Computer Science, vol. 1857. Berlin, Heidelberg: Springer, 2000, pp. 1–15
2000
-
[17]
Random forests,
L. Breiman, “Random forests,” Machine Learning, vol. 45, no. 1, pp. 5–32, 2001
2001
-
[18]
A decision-theoretic generalization of on- line learning and an application to boosting,
Y . Freund and R. E. Schapire, “A decision-theoretic generalization of on- line learning and an application to boosting,” Journal of Computer and System Sciences, vol. 55, no. 1, pp. 119–139, 1997
1997
-
[19]
Greedy function approximation: A gradient boosting machine,
J. H. Friedman, “Greedy function approximation: A gradient boosting machine,” Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, 2001
2001
-
[20]
Lightgbm: A highly efficient gradient boosting decision tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y . Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” in Advances in Neural Information Processing Systems, vol. 30, 2017, pp. 3146–3154. [Online]. Available: https://proceedings.neurips.cc/paper/ 2017/hash/6449f44a102fde848669bdd9eb6b76fa-Abstract.html
2017
-
[21]
Catboost: unbiased boosting with categorical features,
L. Prokhorenkova, G. Gusev, A. V orobev, A. V . Dorogush, and A. Gulin, “Catboost: unbiased boosting with categorical features,” Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[22]
A comparative study of advanced transformer learning frameworks for water potability analysis using physicochemical parameters,
E. Algül, S. Oyucu, O. Polat, F. Harrou, and Y . Sun, “A comparative study of advanced transformer learning frameworks for water potability analysis using physicochemical parameters,” Applied Sciences, vol. 15, no. 13, p. 7262, 2025
2025
-
[23]
Flexible label- induced manifold broad learning system for multiclass recognition,
J. Jin, B. Geng, Y . Li, J. Liang, Y . Xiao, and C. L. P. Chen, “Flexible label- induced manifold broad learning system for multiclass recognition,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 11, pp. 16 076–16 090, 2024
2024
-
[24]
Regularized dis- criminative broad learning system for image classification,
J. Jin, Z. Qin, D. Yu, Y . Li, J. Liang, and C. L. P. Chen, “Regularized dis- criminative broad learning system for image classification,” Knowledge- Based Systems, vol. 251, p. 109306, 2022. VOLUME 4, 2016 21 Royet al.: Customer Churn Prediction Using FT -Transformer and Stacking Ensembles
2022
-
[25]
Tabnet: Attentive interpretable tabular learning,
S. O. Arik and T. Pfister, “Tabnet: Attentive interpretable tabular learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8. AAAI Press, 2021, pp. 6679–6687
2021
-
[26]
Improving deep tabular learning,
S. Sarafian, “Improving deep tabular learning,” arXiv preprint, vol. arXiv:2509.16354, 2025
-
[27]
Stacked generalization,
D. H. Wolpert, “Stacked generalization,” Neural Networks, vol. 5, no. 2, pp. 241–259, 1992
1992
-
[28]
Zhou, Ensemble Methods: Foundations and Algorithms
Z.-H. Zhou, Ensemble Methods: Foundations and Algorithms. Boca Raton, FL: CRC Press, 2012
2012
-
[29]
Hastie, R
T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. New York, NY: Springer, 2009. [Online]. Available: https://hastie.su.domains/ ElemStatLearn
2009
-
[30]
Ensemble-based classifiers,
L. Rokach, “Ensemble-based classifiers,” Artificial Intelligence Review, vol. 33, no. 1–2, pp. 1–39, 2010
2010
-
[31]
A novel transformer-based stacking ensemble method with multi-model integration for cancer classification,
X. Yang, Y . Zhao, and X. Chen, “A novel transformer-based stacking ensemble method with multi-model integration for cancer classification,” PeerJ Computer Science, vol. 11, p. e3314, 2025
2025
-
[32]
Tabpfn: A transformer that solves small tabular classification problems in a second,
N. Hollmann, S. Muller, K. Eggensperger, and F. Hutter, “Tabpfn: A transformer that solves small tabular classification problems in a second,” in Proceedings of the International Conference on Learning Representations. OpenReview.net, 2023. [Online]. Available: https: //openreview.net/forum?id=cp5PvcI6w8
2023
-
[33]
Accurate predictions on small data with a tabular foundation model,
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, J. Grabocka, and F. Hutter, “Accurate predictions on small data with a tabular foundation model,” Nature, vol. 637, pp. 319–326, 2025
2025
-
[34]
Excelformer: A neural network surpassing gbdts on tabular data,
J. Chen, R. Ye, X. Zhu, and H. Chen, “Excelformer: A neural network surpassing gbdts on tabular data,” arXiv preprint, vol. arXiv:2301.02819, 2023
-
[35]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
N. Erickson, J. Mueller, A. Shirkov, H. Zhang, P. Larroy, M. Li, and A. Smola, “Autogluon-tabular: Robust and accurate automl for structured data,” arXiv preprint, vol. arXiv:2003.06505, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[36]
H2o automl: Scalable automatic machine learning,
E. LeDell and S. Poirier, “H2o automl: Scalable automatic machine learning,” in Proceedings of the ICML Workshop on Automated Machine Learning, 2020. [Online]. Available: https://www.automl.org/wp-content/ uploads/2020/07/AutoML_2020_paper_61.pdf
2020
-
[37]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint, vol. arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Gaussian error linear units (GELUs),
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” 2016
2016
-
[39]
Bank customer churn modeling dataset,
Kaggle Community, “Bank customer churn modeling dataset,” https://www.kaggle.com/datasets/barelydedicated/ bank-customer-churn-modeling, 2018, accessed: 2024-12-20
2018
-
[40]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proceedings of the 3rd International Conference on Learning Representations, 2015. [Online]. Available: https://openreview.net/forum? id=8gmWwjFyLj
2015
-
[41]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
N. Hollmann, S. Müller, K. Eggensperger, and F. Hutter, “Tabpfn: A transformer that solves small tabular classification problems in a second,” arXiv preprint arXiv:2207.01848, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017, pp. 4765–4774
2017
-
[43]
Predicting good probabilities with supervised learning,
A. Niculescu-Mizil and R. Caruana, “Predicting good probabilities with supervised learning,” in Proceedings of the 22nd International Conference on Machine Learning. New York, NY: ACM, 2005, pp. 625–632
2005
-
[44]
Tabular data: Deep learning is not all you need,
R. Shwartz-Ziv and A. Armon, “Tabular data: Deep learning is not all you need,” Information Fusion, vol. 81, pp. 84–90, 2022
2022
-
[45]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Weinberger, “On calibration of modern neural networks,” in Proceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 70. PMLR, 2017, pp. 1321–1330. [Online]. Available: https://proceedings.mlr.press/v70/guo17a.html
2017
-
[46]
Obtaining well calibrated probabilities using bayesian binning,
M. P. Naeini, G. F. Cooper, and M. Hauskrecht, “Obtaining well calibrated probabilities using bayesian binning,” in Proceedings of the 29th AAAI Conference on Artificial Intelligence. AAAI Press, 2015, pp. 2901–2907. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/ article/view/9602
2015
-
[47]
Customer base analysis: Partial defec- tion of behaviorally loyal clients in a non-contractual FMCG retail setting,
W. Buckinx and D. Van den Poel, “Customer base analysis: Partial defec- tion of behaviorally loyal clients in a non-contractual FMCG retail setting,” European Journal of Operational Research, vol. 164, no. 1, pp. 252–268, 2005. JOYJIT ROYis a senior technology and program management leader with over 21 years of expe- rience in enterprise digital transform...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.