Accelerating and Scaling MPC-Guided Reinforcement Learning for Humanoid Locomotion and Manipulation
Pith reviewed 2026-06-28 01:34 UTC · model grok-4.3
The pith
MPC-RL uses centroidal-dynamics trajectories to guide reinforcement learning and achieve better humanoid locomotion and manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
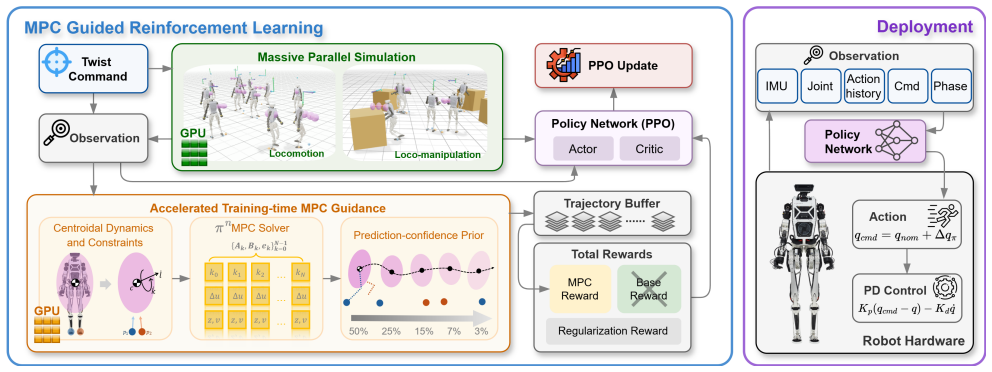
Through MPC-RL, the authors establish that using centroidal-dynamics MPC trajectories as guidance in the RL reward function, facilitated by an efficient parallel batched GPU MPC solver, results in policies with superior performance for humanoid locomotion and manipulation tasks compared to standard approaches.
What carries the argument
The π^n MPC solver, a parallel-in-horizon and construction-free batched GPU MPC solver operating directly on time-varying dynamics to provide guidance without high memory usage or pre-compilation.
If this is right
- MPC-RL achieves superior performance in locomotion and manipulation skills.
- The approach is practical for massively parallel RL training due to the efficient solver.
- Hardware validations confirm the effectiveness of the learned policies.
- The method avoids time-consuming problem construction and excessive training overhead.
Where Pith is reading between the lines
- The framework could extend to other complex robotic systems beyond humanoids if similar dynamics models are available.
- Real-time deployment of the learned policies might benefit from the MPC guidance during training leading to more robust behaviors.
- Future work could explore integrating this with other RL algorithms or dynamics models for further gains.
Load-bearing premise
The centroidal-dynamics MPC trajectories provide useful guidance that improves final policy performance without introducing prohibitive training overhead or requiring per-problem construction.
What would settle it
A direct comparison where MPC-RL policies fail to outperform baseline RL policies in both simulation benchmarks and physical hardware experiments for locomotion and manipulation would falsify the superiority claim.
Figures

read the original abstract
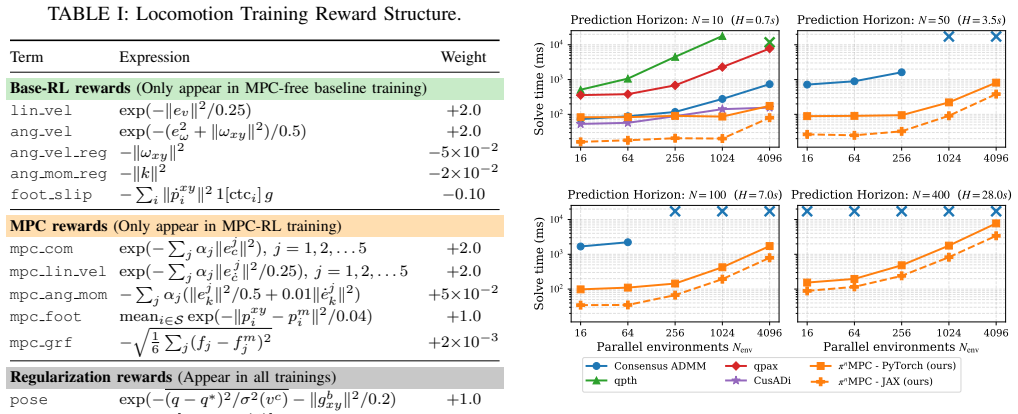
In humanoid motion control, model predictive control (MPC) offers physically grounded prediction and constraint handling, while reinforcement learning (RL) enables robust whole-body skills through large-scale simulation. However, using MPC inside RL often requires time-consuming problem construction or excessive training overhead, making such frameworks difficult to justify in practice. This work studies efficient training-time MPC guidance for humanoid locomotion and manipulation, termed MPC-RL. We introduce a centroidal-dynamics MPC reward formulation that leverages guidance from MPC trajectories in training time. To make this practical in massively parallel RL, we develop $\pi^n$MPC, a parallel-in-horizon and construction-free batched GPU MPC solver that operates directly on time-varying dynamics to avoid high memory usage and pre-compilation. Through a variety of comparative studies and hardware validations, we have found that MPC-RL achieves superior performance in locomotion and manipulation skills. The code base is available at https://github.com/junhengl/mpc-rl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MPC-RL, a framework that incorporates centroidal-dynamics MPC trajectories as a training-time reward signal to guide RL policies for humanoid locomotion and manipulation. It introduces π^n MPC, a parallel-in-horizon and construction-free batched GPU solver that operates on time-varying dynamics to enable efficient massively parallel training. The central claim is that this combination yields superior performance over baselines, supported by comparative studies and hardware validations, with open-source code provided.
Significance. If the empirical results hold with proper controls, the work could offer a scalable way to inject physically grounded guidance into RL without prohibitive overhead, addressing a practical gap in humanoid control. The availability of the code base supports reproducibility and is a strength.
major comments (2)
- [Abstract] Abstract: the claim of 'superior performance' from 'comparative studies and hardware validations' is presented without any quantitative metrics, baseline descriptions, or statistical details. This absence prevents evaluation of the central empirical claim and must be addressed with specific results (e.g., success rates, tracking errors, or reward curves) in the main text.
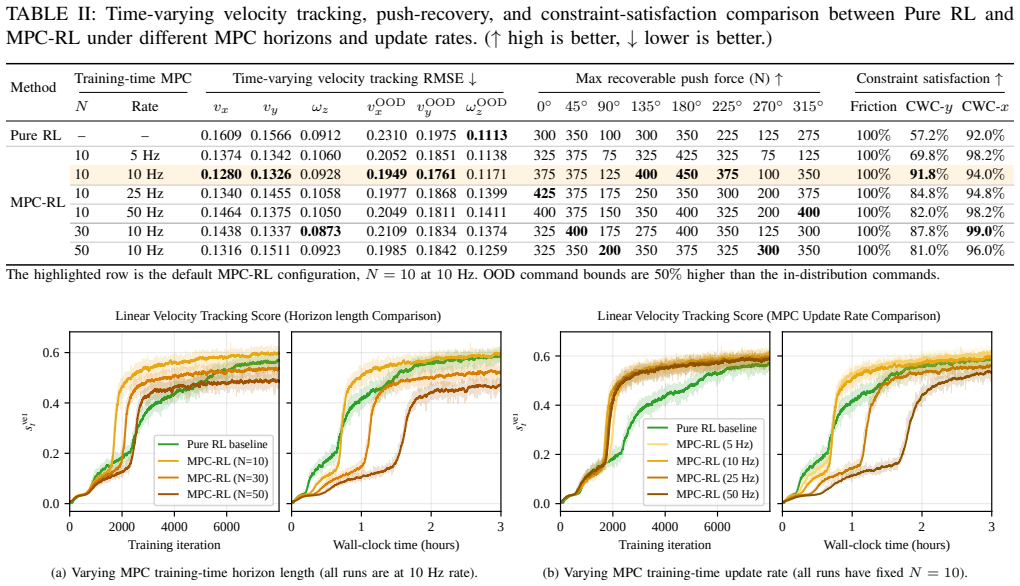
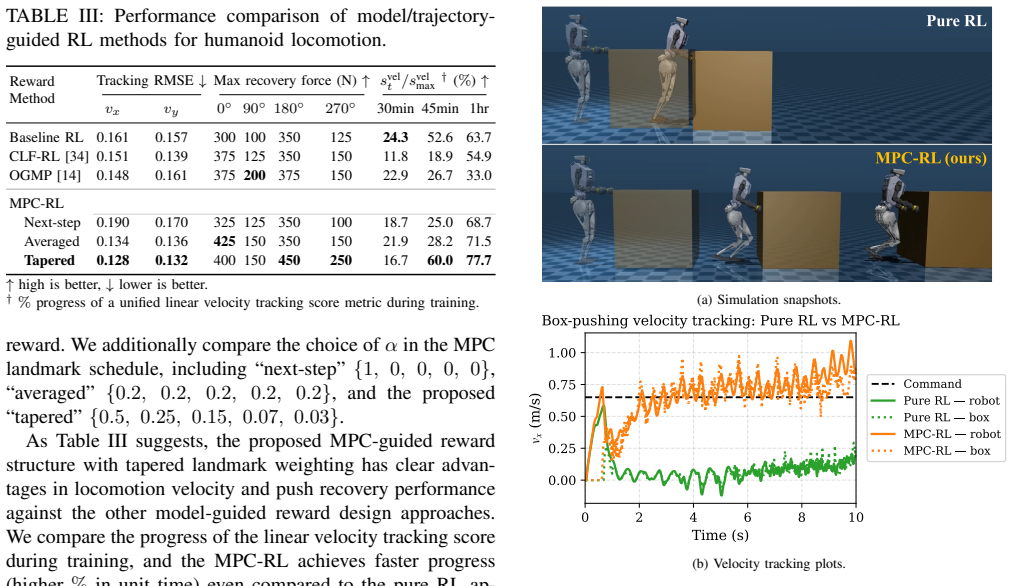
- [Results / Experiments] The manuscript does not appear to contain an ablation that isolates the centroidal-dynamics MPC reward term on manipulation tasks (as opposed to the parallel solver itself). Without such an experiment (e.g., in the results section comparing MPC-RL against an RL-only variant with equivalent sample count), it remains unclear whether performance gains on contact-rich manipulation stem from trajectory quality or from increased parallelism.
minor comments (1)
- [Method] The π^n MPC solver description would benefit from a brief complexity or memory analysis to substantiate the 'avoid high memory usage' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our empirical results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior performance' from 'comparative studies and hardware validations' is presented without any quantitative metrics, baseline descriptions, or statistical details. This absence prevents evaluation of the central empirical claim and must be addressed with specific results (e.g., success rates, tracking errors, or reward curves) in the main text.
Authors: The main text presents the quantitative results from comparative studies and hardware validations, including success rates, tracking errors, and reward curves in the Results section. To strengthen the abstract's claim, we will revise it to include key quantitative metrics drawn from those studies. revision: yes
-
Referee: [Results / Experiments] The manuscript does not appear to contain an ablation that isolates the centroidal-dynamics MPC reward term on manipulation tasks (as opposed to the parallel solver itself). Without such an experiment (e.g., in the results section comparing MPC-RL against an RL-only variant with equivalent sample count), it remains unclear whether performance gains on contact-rich manipulation stem from trajectory quality or from increased parallelism.
Authors: We agree that an explicit ablation isolating the MPC reward contribution on manipulation tasks would improve clarity. While our comparative studies include RL baselines, we will add a dedicated ablation comparing MPC-RL to an RL-only variant with matched sample counts on the manipulation tasks in the revised manuscript. revision: yes
Circularity Check
No circularity detected; performance claims rest on external empirical comparisons
full rationale
The paper presents MPC-RL as an engineering combination of centroidal-dynamics MPC reward guidance and a new parallel batched GPU solver (π^nMPC). No equations, derivations, or self-citations are shown that reduce any claimed prediction or uniqueness result to a fitted input or prior author work by construction. The superiority claim is justified solely by comparative studies and hardware validations, which are independent of the method definition itself. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning,
Z. Gu, J. Li, W. Shen, W. Yu, Z. Xie, S. McCrory, X. Cheng, A. Shamsah, R. Griffin, C. K. Liu,et al., “Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning,”IEEE/ASME Transactions on Mechatronics, vol. 31, no. 2, pp. 2300–2330, 2026
2026
-
[2]
Tailoring Solution Accuracy for Fast Whole-body Model Predictive Control of Legged Robots,
C. Khazoom, S. Hong, M. Chignoli, E. Stanger-Jones, and S. Kim, “Tailoring Solution Accuracy for Fast Whole-body Model Predictive Control of Legged Robots,”arXiv preprint arXiv:2407.10789, 2024
-
[3]
Online non-linear centroidal mpc for humanoid robot locomotion with step adjustment,
G. Romualdi, S. Dafarra, G. L’Erario, I. Sorrentino, S. Traversaro, and D. Pucci, “Online non-linear centroidal mpc for humanoid robot locomotion with step adjustment,” in2022 International Conference on Robotics and Automation (ICRA), pp. 10412–10419, IEEE, 2022
2022
-
[4]
Optimization-based control for dynamic legged robots,
P. M. Wensing, M. Posa, Y . Hu, A. Escande, N. Mansard, and A. Del Prete, “Optimization-based control for dynamic legged robots,” IEEE Transactions on Robotics, vol. 40, pp. 43–63, 2023
2023
-
[5]
Reinforcement learning for robust parameterized locomotion control of bipedal robots,
Z. Li, X. Cheng, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Reinforcement learning for robust parameterized locomotion control of bipedal robots,” in2021 IEEE International Conference on Robotics and Automation (ICRA), pp. 2811–2817, IEEE, 2021
2021
-
[6]
Sim-to-real learning for humanoid box loco-manipulation,
J. Dao, H. Duan, and A. Fern, “Sim-to-real learning for humanoid box loco-manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 16930–16936, IEEE, 2024
2024
-
[7]
Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid loco-manipulation,
F. Liu, Z. Gu, Y . Cai, Z. Zhou, H. Jung, J. Jang, S. Zhao, S. Ha, Y . Chen, D. Xu,et al., “Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid loco-manipulation,” IEEE Robotics and Automation Letters, 2025
2025
-
[8]
RL-augmented Adaptive Model Predictive Control for Bipedal Loco- motion over Challenging Terrain,
J. Kamohara, F. Wu, C. Wamorkar, S. Hutchinson, and Y . Zhao, “RL-augmented Adaptive Model Predictive Control for Bipedal Loco- motion over Challenging Terrain,”arXiv preprint arXiv:2509.18466, 2025
-
[9]
Rl-augmented mpc framework for agile and robust bipedal footstep locomotion planning and con- trol,
S. H. Bang, C. A. Jov ´e, and L. Sentis, “Rl-augmented mpc framework for agile and robust bipedal footstep locomotion planning and con- trol,” in2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids), pp. 607–614, IEEE, 2024
2024
-
[10]
Residual MPC: Blend- ing Reinforcement Learning with GPU-Parallelized Model Predictive Control,
S. H. Jeon, H. J. Lee, S. Hong, and S. Kim, “Residual MPC: Blend- ing Reinforcement Learning with GPU-Parallelized Model Predictive Control,”arXiv preprint arXiv:2510.12717, 2025
-
[11]
Learning agile locomotion and adaptive behaviors via rl-augmented mpc,
Y . Chen and Q. Nguyen, “Learning agile locomotion and adaptive behaviors via rl-augmented mpc,” in2024 IEEE International Confer- ence on Robotics and Automation (ICRA), pp. 11436–11442, IEEE, 2024
2024
-
[12]
Amo: Adaptive motion optimization for hyper-dexterous humanoid whole- body control,
J. Li, X. Cheng, T. Huang, S. Yang, R.-Z. Qiu, and X. Wang, “Amo: Adaptive motion optimization for hyper-dexterous humanoid whole- body control,”arXiv preprint arXiv:2505.03738, 2025
-
[13]
Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds,
M. Dai, W. D. Compton, J. Li, L. Yang, and A. D. Ames, “Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds,”arXiv preprint arXiv:2601.06286, 2026
-
[14]
Ogmp: Oracle guided multi-mode policies for agile and versatile robot control,
L. Krishna, N. Sobanbabu, and Q. Nguyen, “Ogmp: Oracle guided multi-mode policies for agile and versatile robot control,”arXiv preprint arXiv:2403.04205, 2024
-
[15]
Actor-critic model predic- tive control,
A. Romero, Y . Song, and D. Scaramuzza, “Actor-critic model predic- tive control,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 14777–14784, IEEE, 2024
2024
-
[16]
Reinforcement learning and model predictive control for robust embedded quadrotor guidance and control,
C. Greatwood and A. G. Richards, “Reinforcement learning and model predictive control for robust embedded quadrotor guidance and control,”Autonomous Robots, vol. 43, no. 7, pp. 1681–1693, 2019
2019
-
[17]
Learning deep con- trol policies for autonomous aerial vehicles with mpc-guided policy search,
T. Zhang, G. Kahn, S. Levine, and P. Abbeel, “Learning deep con- trol policies for autonomous aerial vehicles with mpc-guided policy search,” in2016 IEEE international conference on robotics and automation (ICRA), pp. 528–535, IEEE, 2016
2016
-
[18]
Dtc: Deep tracking control,
F. Jenelten, J. He, F. Farshidian, and M. Hutter, “Dtc: Deep tracking control,”Science Robotics, vol. 9, no. 86, p. eadh5401, 2024
2024
-
[19]
Synthesis of model predictive control and reinforcement learning: Survey and classifica- tion,
R. Reiter, J. Hoffmann, D. Reinhardt, F. Messerer, K. Baumg ¨artner, S. Sawant, J. Boedecker, M. Diehl, and S. Gros, “Synthesis of model predictive control and reinforcement learning: Survey and classifica- tion,”Annual Reviews in Control, vol. 61, p. 101045, 2026
2026
-
[20]
Cusadi: A gpu parallelization framework for symbolic expressions and optimal control,
S. H. Jeon, S. Hong, H. J. Lee, C. Khazoom, and S. Kim, “Cusadi: A gpu parallelization framework for symbolic expressions and optimal control,”IEEE Robotics and Automation Letters, vol. 10, no. 2, pp. 899–906, 2024
2024
-
[21]
Relu-qp: A gpu-accelerated quadratic programming solver for model-predictive control,
A. L. Bishop, J. Z. Zhang, S. Gurumurthy, K. Tracy, and Z. Manch- ester, “Relu-qp: A gpu-accelerated quadratic programming solver for model-predictive control,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 13285–13292, IEEE, 2024
2024
-
[22]
Cost-Matching Model Predictive Control for Efficient Reinforcement Learning in Humanoid Locomotion,
W. Cai, K. G. Vamvoudakis, S. Gros, and A. Tzes, “Cost-Matching Model Predictive Control for Efficient Reinforcement Learning in Humanoid Locomotion,”arXiv preprint arXiv:2603.28243, 2026
-
[23]
$\pi$MPC: A Parallel-in-horizon and Construction-free NMPC Solver
L. Wu, B. Yang, J. Li, X. Yang, Y . Mo, Y . Shi, A. D. Ames, and J. Drgo ˇna, “πMPC: A Parallel-in-horizon and Construction-free NMPC Solver,”arXiv preprint arXiv:2601.14414v2, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Centroidal dynamics of a humanoid robot,
D. E. Orin, A. Goswami, and S.-H. Lee, “Centroidal dynamics of a humanoid robot,”Autonomous robots, vol. 35, no. 2, pp. 161–176, 2013
2013
-
[25]
Stability of surface contacts for humanoid robots: Closed-form formulae of the contact wrench cone for rectangular support areas,
S. Caron, Q.-C. Pham, and Y . Nakamura, “Stability of surface contacts for humanoid robots: Closed-form formulae of the contact wrench cone for rectangular support areas,” in2015 IEEE International Conference on Robotics and Automation (ICRA), pp. 5107–5112, IEEE, 2015
2015
-
[26]
Gait-Net-augmented Implicit Kino-dynamic MPC for Dynamic Variable-frequency Humanoid Lo- comotion over Discrete Terrains,
J. Li, Z. Duan, J. Ma, and Q. Nguyen, “Gait-Net-augmented Implicit Kino-dynamic MPC for Dynamic Variable-frequency Humanoid Lo- comotion over Discrete Terrains,” inProceedings of Robotics: Science and Systems, (LosAngeles, CA, USA), June 2025
2025
-
[27]
Fast alternating direction optimization methods,
T. Goldstein, B. O’Donoghue, S. Setzer, and R. Baraniuk, “Fast alternating direction optimization methods,”SIAM Journal on Imaging Sciences, vol. 7, no. 3, pp. 1588–1623, 2014
2014
- [28]
-
[29]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu, “Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,”arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A Differentiable Interior-Point Method in Single Precision
J. Arrizabalaga, K. Tracy, and Z. Manchester, “A Differen- tiable Interior-Point Method in Single Precision,”arXiv preprint arXiv:2605.17913, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
OptNet: Differentiable Optimization as a Layer in Neural Networks,
B. Amos and J. Z. Kolter, “OptNet: Differentiable Optimization as a Layer in Neural Networks,”arXiv preprint arXiv:1703.00443, 2017
-
[32]
Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers,
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers,”Foundations and Trends in Machine Learning, vol. 3, no. 1, pp. 1–122, 2011
2011
-
[33]
OSQP: An operator splitting solver for quadratic programs,
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd, “OSQP: An operator splitting solver for quadratic programs,” in2018 UKACC 12th international conference on control (CONTROL), pp. 339–339, IEEE, 2018
2018
-
[34]
Clf-rl: Control lyapunov function guided reinforcement learning,
K. Li, Z. Olkin, Y . Yue, and A. D. Ames, “Clf-rl: Control lyapunov function guided reinforcement learning,”IEEE Robotics and Automa- tion Letters, 2026. APPENDIX TABLE IV: Comparison of inertia-based gain selection for THEMIS v2. Herek g is the gear ratio,I rotor =A i/k2 g is the rotor inertia, andω n = 2πfn. Joint Method kg Irotor (kg m2) Ai (kg m2) Jef...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.