Acoustic Cue Alignment in Audio Language Models for Speech Emotion Recognition
Pith reviewed 2026-06-27 20:55 UTC · model grok-4.3
The pith
Audio language models for emotion recognition improve when acoustic cue tokens in prompts match the input audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
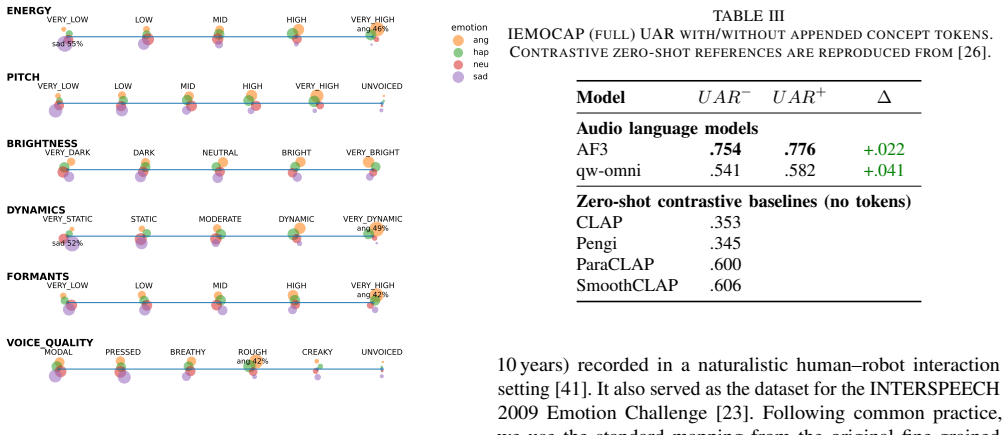
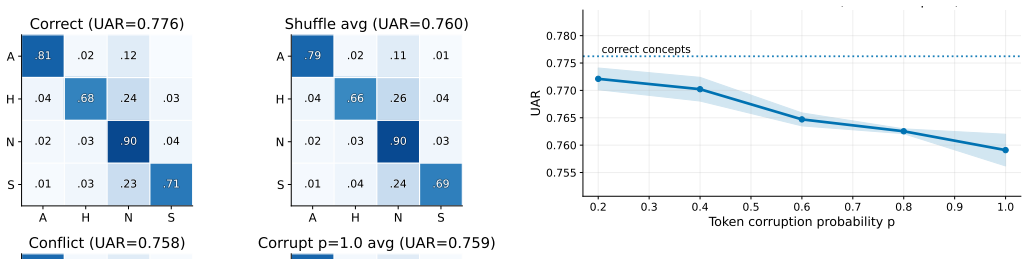
Instruction-following audio language models augmented with six acoustic concept tokens derived from the eGeMAPS paralinguistic feature set show improved unweighted average recall on FAU-Aibo and IEMOCAP when the tokens are aligned with the audio input; shuffled, conflicting, or corrupted tokens reduce performance relative to aligned ones and shift confusions toward neutral, yet predictions do not collapse, indicating sensitivity to the symbolic cue channel together with partial anchoring to the audio signal.
What carries the argument
Six acoustic concept tokens that summarize energy, pitch, dynamics, brightness, formants, and voice quality, appended to the textual prompt.
If this is right
- Aligned tokens raise unweighted average recall on the FAU-Aibo and IEMOCAP benchmarks.
- Shuffled, conflicting, or corrupted tokens lower recall and increase neutral confusions relative to aligned tokens.
- Predictions remain stable and do not collapse under strong token perturbations.
- Token-only changes provide a practical probe for cue use, robustness, and interpretability in ALM-based affective computing.
Where Pith is reading between the lines
- The same token-alignment test could be run on other paralinguistic tasks to check whether cue sensitivity appears outside emotion recognition.
- Deliberate cue conflicts during training might increase model robustness to imperfect prompts.
- Partial audio anchoring implies that prompt engineering alone cannot fully override acoustic evidence in these models.
Load-bearing premise
Appending the acoustic tokens to the prompt while leaving the audio input unchanged isolates the isolated effect of cue alignment.
What would settle it
Finding identical unweighted average recall scores for aligned versus shuffled or corrupted tokens on both FAU-Aibo and IEMOCAP would falsify the claim that models use the cues in a grounded manner.
Figures

read the original abstract
Instruction-following audio language models (ALMs) can be augmented with explicit acoustic cues, yet it remains unclear whether such cues are used in a grounded way when the raw audio is already available. We study this question in speech emotion recognition (SER) by deriving six interpretable acoustic concept tokens from the standardised eGeMAPS paralinguistic feature set. These tokens summarise energy, pitch, dynamics, brightness, formants, and voice quality, and are appended to the textual prompt while the audio input is kept unchanged. Across the widely used FAU-Aibo and IEMOCAP benchmarks, aligned tokens improve unweighted average recall (UAR), whereas shuffled, conflicting, or corrupted tokens reduce performance relative to aligned tokens and shift confusions toward neutral. Importantly, predictions do not collapse under strong token perturbations, suggesting that the models are sensitive to the symbolic cue channel but remain partly anchored to the audio signal. We argue that token-only interventions provide a practical way to probe audio-grounded cue use, robustness, and interpretability in ALM-based affective computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instruction-following audio language models for speech emotion recognition can be probed for grounded cue use by appending six eGeMAPS-derived acoustic concept tokens (energy, pitch, dynamics, brightness, formants, voice quality) to the textual prompt while leaving the raw audio input unchanged. On FAU-Aibo and IEMOCAP, aligned tokens raise unweighted average recall relative to shuffled, conflicting, or corrupted tokens; perturbations shift confusions toward neutral but do not cause collapse, which the authors interpret as evidence that models remain partly anchored to the audio signal while remaining sensitive to the symbolic cue channel.
Significance. If the central empirical pattern survives controls that isolate text-internal consistency from audio integration, the work supplies a lightweight, token-only intervention technique for testing cue alignment, robustness, and interpretability in ALM-based affective computing. The approach is directly applicable to existing instruction-tuned models and does not require new architectures or training.
major comments (3)
- [Abstract / §3] Abstract and §3 (experimental setup): all reported interventions alter only the textual prompt while the audio waveform remains identical. No text-only baseline, audio-only baseline, or attention-map analysis is described that would distinguish whether UAR changes arise from audio-grounded cue integration or from internal textual consistency/conflict alone. This distinction is load-bearing for the claim that the models are 'partly anchored to the audio signal.'
- [§4] §4 (results): the abstract states that 'predictions do not collapse under strong token perturbations,' yet no quantitative measure of the residual audio contribution (e.g., performance gap between audio+aligned-text vs. text-only or audio-only) is supplied. Without such a decomposition, the non-collapse observation cannot be unambiguously attributed to audio anchoring rather than model robustness to prompt noise.
- [§3.1] §3.1 (token construction): the selection of exactly six eGeMAPS-derived concepts is presented without ablation or justification against alternative feature groupings. Because the free parameter 'selection of six acoustic concepts' directly determines the token set, the reported performance differences are not parameter-free and the robustness claim is tied to this particular choice.
minor comments (2)
- [§3] The manuscript should report the exact prompt templates, the precise mapping from eGeMAPS features to token strings, and the statistical test used for UAR differences (including confidence intervals or p-values).
- [Figures] Figure captions and axis labels should explicitly state whether error bars represent standard deviation across seeds, folds, or runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of our experimental design regarding the isolation of audio grounding effects. We address each point below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (experimental setup): all reported interventions alter only the textual prompt while the audio waveform remains identical. No text-only baseline, audio-only baseline, or attention-map analysis is described that would distinguish whether UAR changes arise from audio-grounded cue integration or from internal textual consistency/conflict alone. This distinction is load-bearing for the claim that the models are 'partly anchored to the audio signal.'
Authors: We agree that explicit baselines would strengthen the distinction between textual consistency and audio integration. Our interpretation of partial audio anchoring relies on the observation that strong perturbations in the token channel do not cause prediction collapse, implying the model continues to use the unchanged audio input. To address this, we will add a text-only baseline experiment in the revised version, comparing performance with and without audio input under the same prompts. Regarding attention-map analysis, this is not feasible without model-specific access to attention weights in all tested ALMs, so we will note this as a limitation rather than adding new analysis. revision: partial
-
Referee: [§4] §4 (results): the abstract states that 'predictions do not collapse under strong token perturbations,' yet no quantitative measure of the residual audio contribution (e.g., performance gap between audio+aligned-text vs. text-only or audio-only) is supplied. Without such a decomposition, the non-collapse observation cannot be unambiguously attributed to audio anchoring rather than model robustness to prompt noise.
Authors: We acknowledge the need for a quantitative decomposition. The non-collapse is presented as evidence of residual audio use because the audio remains available and the model is instruction-tuned to process it. However, we will incorporate the text-only baseline as mentioned in response to the first comment, which will provide the performance gap to better quantify the audio contribution. This will be added to §4. revision: yes
-
Referee: [§3.1] §3.1 (token construction): the selection of exactly six eGeMAPS-derived concepts is presented without ablation or justification against alternative feature groupings. Because the free parameter 'selection of six acoustic concepts' directly determines the token set, the reported performance differences are not parameter-free and the robustness claim is tied to this particular choice.
Authors: The six concepts correspond to the primary acoustic dimensions covered by eGeMAPS (energy, pitch, dynamics, brightness, formants, voice quality), which are established in the paralinguistic literature for emotion recognition. While an ablation study on alternative groupings or numbers of concepts would be informative, it was beyond the scope of this initial probing study. In revision, we will expand §3.1 with a justification based on eGeMAPS documentation and note that the results are specific to this selection, with suggestions for future ablations. revision: partial
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential reductions
full rationale
The paper is an empirical study that appends tokens derived from the external eGeMAPS feature set to prompts and reports UAR differences under aligned vs. perturbed conditions on FAU-Aibo and IEMOCAP. No equations, fitted parameters, or derivation chains are present. Token derivation is from a standardised external set, not self-defined. No self-citations are used to justify uniqueness or ansatzes. The central claim rests on observed performance shifts rather than any construction that reduces outputs to inputs by definition. This matches the default expectation of no significant circularity for an empirical benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- selection of six acoustic concepts
axioms (1)
- domain assumption eGeMAPS constitutes a standardised paralinguistic feature set from which interpretable acoustic concept tokens can be derived
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-omni technical report,
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2.5-omni technical report,” arXiv preprint, 2025
2025
-
[2]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S. G. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,” arXiv preprint, 2025
2025
-
[3]
Computer audition: From task-specific machine learning to foundation models,
A. Triantafyllopoulos, I. Tsangko, A. Gebhard, A. Mesaros, T. Virtanen, and B. W. Schuller, “Computer audition: From task-specific machine learning to foundation models,”Proceedings of the IEEE, vol. 113, no. 4, pp. 317–343, 2025
2025
-
[4]
Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness?
A. Jacovi and Y . Goldberg, “Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness?” inProceedings of ACL, 2020, p. no pagination
2020
-
[5]
Eraser: A benchmark to evaluate rationalized NLP models,
J. DeYoung, S. Jain, N. F. Rajani, E. Lehman, C. Xiong, and B. C. Wallace, “Eraser: A benchmark to evaluate rationalized NLP models,” inProceedings of ACL, 2020, p. no pagination
2020
-
[6]
The European Parliament, “Amendments adopted by the European Parliament on 14 June 2023 on the proposal for a regulation of the European Parliament and of the Council on laying down har- monised rules on artificial intelligence (Artificial Intelligence Act) and amending certain Union legislative acts (COM(2021)0206 – C9- 0146/2021 – 2021/0106(COD)),” 2023...
2023
-
[7]
Schuller and A
B. Schuller and A. Batliner,Computational Paralinguistics: Emotion, Affect and Personality in Speech and Language Processing. Wiley, 2014
2014
-
[8]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Advances in Neural Information Processing Systems, 2020, pp. 12 449– 12 460
2020
-
[9]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
2021
-
[10]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[11]
Clap: Learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “Clap: Learning audio concepts from natural language supervision,” inProceedings of ICASSP, Rhodes, Greece, 2023, pp. 1–5
2023
-
[12]
Affective computing has changed: The foundation model disruption,
B. Schuller, A. Mallol-Ragolta, A. P. Almansa, I. Tsangko, M. M. Amin, A. Semertzidou, L. Christ, and S. Amiriparian, “Affective computing has changed: The foundation model disruption,”npj Artificial Intelligence, vol. 2, no. 1, p. 16, 2026
2026
-
[13]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. André, C. Busso, L. Y . Devillers, J. Epps, P. Laukka, S. S. Narayananet al., “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,”IEEE Transactions on Affective Computing, vol. 7, no. 2, pp. 190–202, 2016
2016
-
[14]
opensmile: The munich versatile and fast open-source audio feature extractor,
F. Eyben, M. Wöllmer, and B. W. Schuller, “opensmile: The munich versatile and fast open-source audio feature extractor,” inProceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 2010, pp. 1459–1462
2010
-
[15]
Audiobench: A universal benchmark for audio large language models,
B. Wang, X. Zou, G. Lin, S. Sun, Z. Liu, W. Zhang, Z. Liu, A. Aw, and N. F. Chen, “Audiobench: A universal benchmark for audio large language models,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Albuquerque, New Mexico: As...
2025
-
[16]
AIR-bench: Benchmarking large audio-language models via generative comprehension,
Q. Yang, J. Xu, W. Liu, Y . Chu, Z. Jiang, X. Zhou, Y . Leng, Y . Lv, Z. Zhao, C. Zhou, and J. Zhou, “AIR-bench: Benchmarking large audio-language models via generative comprehension,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguist...
2024
-
[17]
V ocalbench: Benchmarking the vocal conversational abilities for speech interaction models,
H. Liu, Y . Wang, Z. Cheng, R. Wu, Q. Gu, Y . Wang, and Y . Wang, “V ocalbench: Benchmarking the vocal conversational abilities for speech interaction models,”arXiv preprint arXiv:2505.15727, 2025. [Online]. Available: https://arxiv.org/abs/2505.15727
arXiv 2025
-
[18]
Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,
C.-Y . Kuan, W.-P. Huang, and H. yi Lee, “Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,” inInterspeech 2024, 2024, pp. 4144–
2024
-
[19]
Available: https://www.isca-archive.org/interspeech_ 2024/kuan24_interspeech.html
[Online]. Available: https://www.isca-archive.org/interspeech_ 2024/kuan24_interspeech.html
2024
-
[20]
Teaching audio-aware large language models what does not hear: Mitigating hallucinations through synthesized negative samples,
C.-Y . Kuan and H. yi Lee, “Teaching audio-aware large language models what does not hear: Mitigating hallucinations through synthesized negative samples,” inInterspeech 2025, 2025, pp. 2073–
2025
-
[21]
Available: https://www.isca-archive.org/interspeech_ 2025/kuan25_interspeech.html
[Online]. Available: https://www.isca-archive.org/interspeech_ 2025/kuan25_interspeech.html
2025
-
[22]
Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information,
C.-K. Yang, N. Ho, Y .-T. Piao, and H. yi Lee, “Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information,” inInterspeech 2025, 2025, pp. 1788–
2025
-
[23]
Available: https://www.isca-archive.org/interspeech_ 2025/yang25g_interspeech.html
[Online]. Available: https://www.isca-archive.org/interspeech_ 2025/yang25g_interspeech.html
2025
-
[24]
Benchmarking and confidence evaluation of lalms for temporal reasoning,
D. Bhattacharya, A. Kulkarni, and S. Ganapathy, “Benchmarking and confidence evaluation of lalms for temporal reasoning,” inInterspeech 2025, 2025, pp. 2068–2072. [Online]. Available: https://www.isca-archive. org/interspeech_2025/bhattacharya25b_interspeech.html
2025
-
[25]
Frozen large language models can perceive paralinguistic aspects of speech,
W. Kang, J. Jia, C. Wu, W. Zhou, E. Lakomkin, Y . Gaur, L. Sari, S. Kim, K. Li, J. Mahadeokar, and O. Kalinli, “Frozen large language models can perceive paralinguistic aspects of speech,” in Interspeech 2025, 2025, pp. 4323–4327. [Online]. Available: https: //www.isca-archive.org/interspeech_2025/kang25_interspeech.html
2025
-
[26]
The interspeech 2009 emotion challenge,
B. Schuller, S. Steidl, and A. Batliner, “The interspeech 2009 emotion challenge,” inProceedings of INTERSPEECH, Brighton, United Kingdom, 2009, p. no pagination
2009
-
[27]
Dawn of the transformer era in speech emotion recognition: Closing the valence gap,
J. Wagner, A. Triantafyllopoulos, H. Wierstorf, M. Schmitt, F. Burkhardt, F. Eyben, and B. W. Schuller, “Dawn of the transformer era in speech emotion recognition: Closing the valence gap,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 2, pp. 10 745– 10 759, 2023
2023
-
[28]
Paraclap: Towards a general language-audio model for computational paralinguistic tasks,
X. Jing, A. Triantafyllopoulos, and B. Schuller, “Paraclap: Towards a general language-audio model for computational paralinguistic tasks,” inProceedings of INTERSPEECH, Kos Island, Greece, 2024, p. no pagination
2024
-
[29]
Smoothclap: Soft-target enhanced contrastive language-audio pretraining for affective computing,
X. Jing, J. Wang, A. Triantafyllopoulos, M. Gerczuk, S. Amiriparian, J. Luo, and B. Schuller, “Smoothclap: Soft-target enhanced contrastive language-audio pretraining for affective computing,” arXiv preprint, 2026
2026
-
[30]
Qwen2-audio: Improving audio understanding in large language models,
J. Xu, H. Zhou, J. Wu, J. Wang, P. Zhu, H. Zhang, S. Bai, J. Lin, Z. Yu, K. Danget al., “Qwen2-audio: Improving audio understanding in large language models,” arXiv preprint, 2024. [Online]. Available: https://arxiv.org/abs/2407.10759
Pith/arXiv arXiv 2024
-
[31]
J. Xuet al., “Qwen3-omni technical report,” arXiv preprint, 2025. [Online]. Available: https://arxiv.org/abs/2509.17765
Pith/arXiv arXiv 2025
-
[32]
Audio-reasoner: Improving reasoning capability in large audio language models,
X. Chen, W. Hu, Z. Yu, L. Xu, Z. Wang, J. Wu, Y . Ding, M. Wu, S. Wen, Y . Zhanget al., “Audio-reasoner: Improving reasoning capability in large audio language models,” arXiv preprint, 2025, accepted by EMNLP 2025. [Online]. Available: https://arxiv.org/abs/2503.02318
arXiv 2025
-
[33]
Echo: Towards advanced audio comprehension via audio-interleaved reasoning,
Y . Gao, Z. Yu, S. Geng, X. Han, Z. Wu, J. Li, S. Li, S. Cao, J. Wu, X. Hu, Z. Chen, J. Wang, K. Chen, F. Huang, and J. Zhou, “Echo: Towards advanced audio comprehension via audio-interleaved reasoning,” arXiv preprint, 2026, accepted by ICLR 2026. [Online]. Available: https://arxiv.org/abs/2602.11909
arXiv 2026
-
[34]
Unveiling hidden factors: explainable ai for feature boosting in speech emotion recognition: N. alaa et al
A. Nfissi, W. Bouachir, N. Bouguila, and B. Mishara, “Unveiling hidden factors: explainable ai for feature boosting in speech emotion recognition: N. alaa et al.”Applied Intelligence, vol. 54, no. 11, pp. 7046–7069, 2024
2024
-
[35]
Improving audio explanations using audio language models,
A. Akman, Q. Sun, and B. W. Schuller, “Improving audio explanations using audio language models,”IEEE Signal Processing Letters, vol. 32, pp. 741–745, 2025
2025
-
[36]
Attention is not explanation,
S. Jain and B. C. Wallace, “Attention is not explanation,” inProceedings of NAACL, 2019, p. no pagination
2019
-
[37]
Sanity checks for saliency maps,
J. Adebayo, J. Gilmer, M. Muelly, I. Goodfellow, M. Hardt, and B. Kim, “Sanity checks for saliency maps,” inAdvances in Neural Information Processing Systems, 2018, p. no pagination
2018
-
[38]
Improving audio explanations using audio language models,
A. Akman, Q. Sun, and B. W. Schuller, “Improving audio explanations using audio language models,”IEEE Signal Processing Letters, 2025
2025
-
[39]
Investigating faithful- ness in large audio language models,
L. Jain, P. Mousavi, M. Ravanelli, and C. Subakan, “Investigating faithful- ness in large audio language models,”arXiv preprint arXiv:2509.22363, 2025
Pith/arXiv arXiv 2025
-
[40]
Discovering and causally validating emotion-sensitive neurons in large audio-language models,
X. Zhao, B. Schuller, and B. Sisman, “Discovering and causally validating emotion-sensitive neurons in large audio-language models,” arXiv preprint, 2026
2026
-
[41]
A survey on speech large language models for understanding,
J. Peng, Y . Wang, B. Li, Y . Guo, H. Wang, Y . Fang, Y . Xi, H. Li, X. Li, K. Zhanget al., “A survey on speech large language models for understanding,”IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[42]
Audio-language models for audio-centric tasks: A survey,
Y . Su, J. Bai, Q. Xu, K. Xu, and Y . Dou, “Audio-language models for audio-centric tasks: A survey,”arXiv preprint arXiv:2501.15177, 2025
arXiv 2025
-
[43]
J. Fan, R. Ren, J. Li, R. Pandey, P. G. Shivakumar, I. Bulyko, A. Gandhe, G. Liu, and Y . Gu, “Incentivizing consistent, effective and scalable reasoning capability in audio llms via reasoning process rewards,”arXiv preprint arXiv:2510.20867, 2025
arXiv 2025
-
[44]
Releasing a thoroughly annotated and processed spontaneous emotional database: The FAU aibo emotion corpus,
A. Batliner, S. Steidl, and E. Nöth, “Releasing a thoroughly annotated and processed spontaneous emotional database: The FAU aibo emotion corpus,” inProceedings of LREC, 2008, p. no pagination
2008
-
[45]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,”Language Resources and Evaluation, vol. 42, no. 4, pp. 335–359, 2008
2008
-
[46]
Designing and evaluating speech emotion recognition systems: A reality check case study with iemocap,
N. Antoniou, A. Katsamanis, T. Giannakopoulos, and S. Narayanan, “Designing and evaluating speech emotion recognition systems: A reality check case study with iemocap,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[47]
Pengi: An audio language model for audio tasks,
S. Deshmukh, B. Elizalde, R. Singh, and H. Wang, “Pengi: An audio language model for audio tasks,” inAdvances in Neural Information Processing Systems, 2024, p. no pagination
2024
-
[48]
Training large language models to reason in a continuous latent space,
S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y . Tian, “Training large language models to reason in a continuous latent space,” arXiv preprint arXiv:2412.06769, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.