Are Tabular Foundation Models Robust to Realistic Query Distribution Shifts in Microbiome Data?
Pith reviewed 2026-06-26 00:18 UTC · model grok-4.3
The pith
Protecting discriminative taxa is insufficient to keep tabular foundation models stable under support-query shifts in microbiome data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
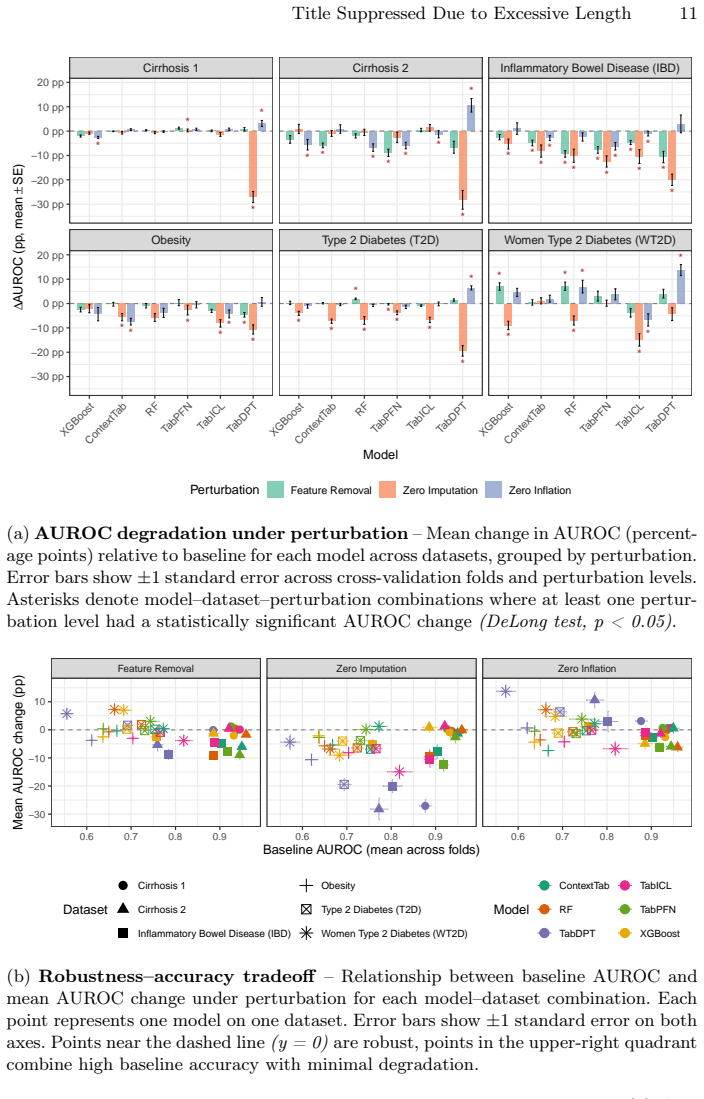
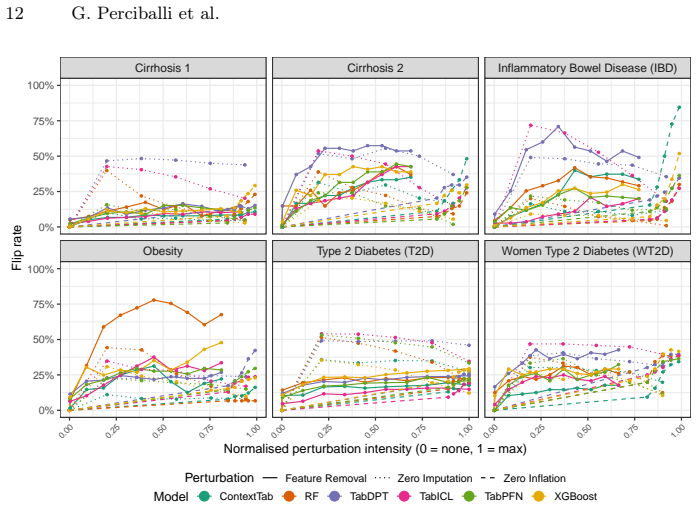
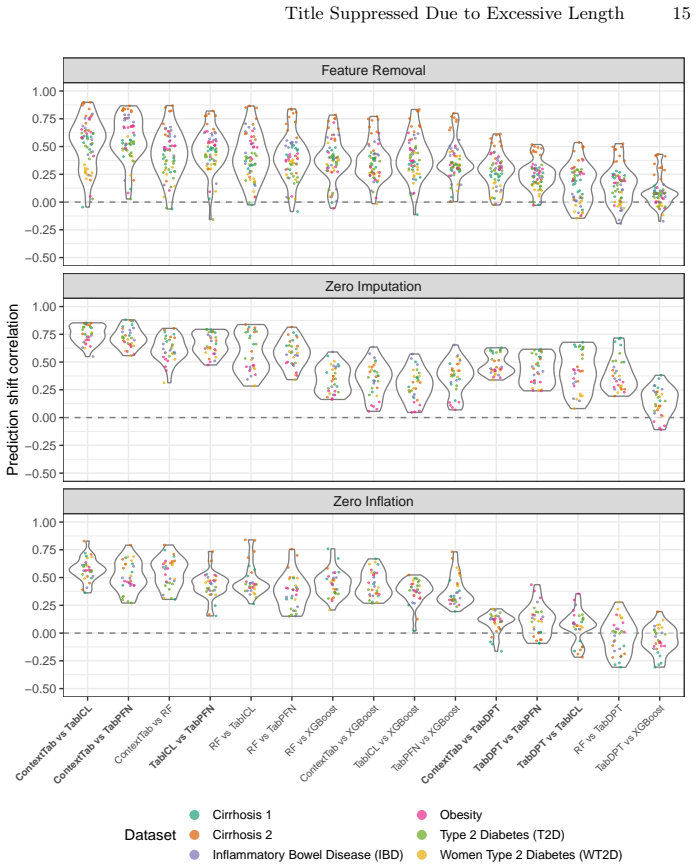
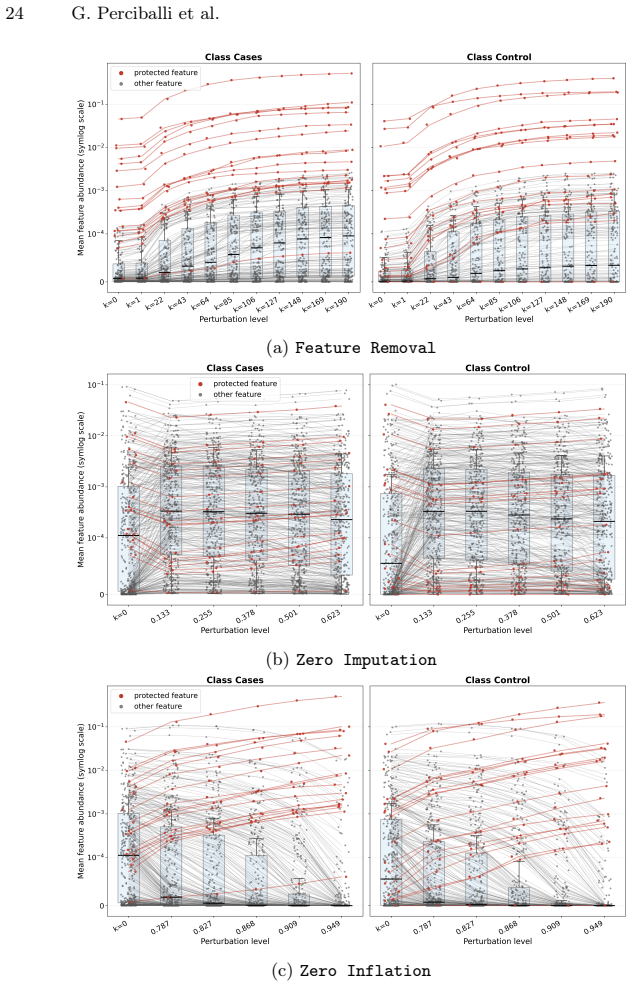
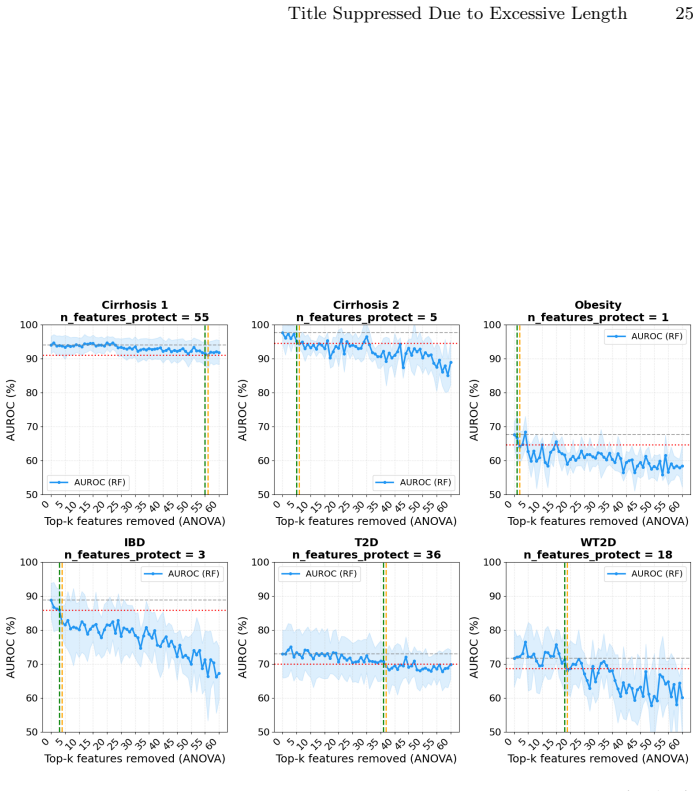
Tabular foundation models achieve strong performance on microbiome abundance data, yet their robustness under realistic distribution shift remains poorly characterized. Protecting the most discriminative taxa is insufficient to guarantee stability under support-query shift: across datasets, all perturbations degrade model performance, with zero-imputation consistently the most harmful, indicating that corrupting global feature structure can break generalization even when key taxa are retained.
What carries the argument
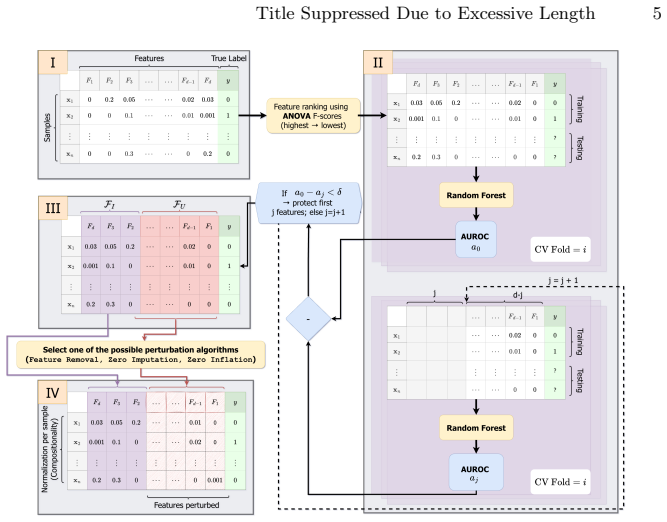
An in-context learning benchmark that feeds unperturbed support sets and evaluates perturbed query samples using three controlled strategies (high-abundance taxon removal, increased zero-inflation, and spurious non-zero injection) while preserving the most discriminative taxa.
If this is right
- Global feature structure beyond the top discriminative taxa is required for stable generalization.
- Zero-imputation via spurious non-zero values is the perturbation that most consistently harms performance.
- Increased zero-inflation affects tabular foundation models more severely than a classical random forest.
- Models must be evaluated under support-query mismatch rather than only on i.i.d. test splits.
- Sparsification-type shifts warrant targeted robustness techniques for these architectures.
Where Pith is reading between the lines
- Similar controlled perturbations could be applied to other tabular domains such as single-cell RNA counts to test whether the same sensitivity appears.
- Reporting exact zero-handling and abundance-filtering steps in microbiome studies would help quantify how often these shifts arise in practice.
- Retraining or fine-tuning on mixtures that include the three perturbation types might reduce the observed drops.
Load-bearing premise
The three controlled perturbation strategies accurately capture the distribution shifts that occur during real microbiome data collection and processing.
What would settle it
A follow-up experiment that applies the same three perturbations to new microbiome cohorts and measures no drop in query accuracy, or finds that zero-imputation is not the most damaging change.
Figures
read the original abstract
Tabular foundation models (TFMs) achieve strong performance on microbiome abundance data, yet their robustness under realistic distribution shift remains poorly characterized. We introduce a benchmark that evaluates the robustness of TFMs to biologically inspired perturbations across six gut microbiome datasets spanning four disease contexts. In this in-context learning setting, models receive unperturbed support sets as context and are evaluated on perturbed query samples. To isolate robustness beyond "shortcut" features, we preserve the most discriminative taxa and apply three controlled perturbation strategies: (i) removal of high-abundance (uninformative) taxa, (ii) sparsification via increased zero-inflation, and (iii) zero-imputation via spurious non-zero injections. Our results show that protecting discriminative features is insufficient to guarantee stability under support-query shift: across datasets, all perturbations degrade model performance, with zero-imputation consistently the most harmful, indicating that corrupting global feature structure can break generalization even when key taxa are retained. Sparsification disproportionately affects TFMs relative to a classical random forest baseline, suggesting greater sensitivity to zero-inflation-type shifts. The code is publicly available at: https://github.com/UMMISCO/metagenomics-fm/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark for tabular foundation models (TFMs) on six gut microbiome datasets, evaluating in-context learning robustness when support sets are unperturbed but query samples undergo three controlled perturbations (high-abundance taxon removal, zero-inflation sparsification, and spurious non-zero injection) while preserving the most discriminative taxa. It reports that all perturbations degrade performance across datasets, with zero-imputation most harmful, and that sparsification affects TFMs more than a random forest baseline, concluding that protecting discriminative features does not guarantee stability under support-query shifts.
Significance. If the perturbations are shown to be realistic, the results would indicate that TFMs remain sensitive to global feature structure changes in microbiome data even after shortcut removal, with implications for their use in shifted real-world settings. Public code availability at the cited GitHub repository is a clear strength for reproducibility of the empirical benchmark.
major comments (2)
- [Abstract] Abstract and perturbation description: the headline claim that 'protecting discriminative features is insufficient to guarantee stability' is load-bearing on the premise that the three strategies (high-abundance removal, zero-inflation, spurious non-zero injection) constitute realistic query distribution shifts, yet no quantitative match is provided to documented real-world microbiome shifts such as batch effects from sequencing platform, DNA extraction protocol, or sample handling.
- [Abstract] Results presentation: the abstract states 'consistent performance degradation' and 'zero-imputation consistently the most harmful' across six datasets but supplies no statistical significance tests, error bars, exact per-dataset sample sizes, or full baseline tables, which undermines assessment of whether the observed differences are reliable or merely directional.
minor comments (1)
- [Abstract] The abstract mentions 'four disease contexts' but does not list the specific datasets or their sizes, which would aid immediate assessment of diversity and statistical power.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and perturbation description: the headline claim that 'protecting discriminative features is insufficient to guarantee stability' is load-bearing on the premise that the three strategies (high-abundance removal, zero-inflation, spurious non-zero injection) constitute realistic query distribution shifts, yet no quantitative match is provided to documented real-world microbiome shifts such as batch effects from sequencing platform, DNA extraction protocol, or sample handling.
Authors: The perturbations were designed to reflect common, documented issues in microbiome sequencing data, such as zero-inflation due to limited sequencing depth and spurious non-zeros from potential contamination or technical artifacts. While we did not perform a direct quantitative comparison to specific batch effects in this work, these strategies are grounded in the literature on microbiome data characteristics. We will revise the abstract and introduction to more explicitly cite supporting references for the biological inspiration of each perturbation and clarify that they represent plausible rather than exhaustive matches to all possible real-world shifts. revision: partial
-
Referee: [Abstract] Results presentation: the abstract states 'consistent performance degradation' and 'zero-imputation consistently the most harmful' across six datasets but supplies no statistical significance tests, error bars, exact per-dataset sample sizes, or full baseline tables, which undermines assessment of whether the observed differences are reliable or merely directional.
Authors: We will update the abstract to include references to the statistical significance of the observed degradations, mention the use of error bars from repeated evaluations, and note the dataset sizes. The main body of the paper already contains full tables, per-dataset results with standard deviations, and statistical tests; we will ensure these are clearly cross-referenced in the abstract where space permits. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements
full rationale
The paper is an empirical benchmark study that introduces controlled perturbations on microbiome datasets and reports direct performance measurements under support-query shifts. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. The central claims rest on experimental results across six datasets rather than any reduction to prior inputs by construction. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine learning45(1), 5–32 (2001)
Breiman, L.: Random forests. Machine learning45(1), 5–32 (2001)
2001
-
[2]
Current Opinion in Plant Biology71, 102326 (2023)
Busato, S., Gordon, M., Chaudhari, M., Jensen, I., Akyol, T., Andersen, S., Williams, C.: Compositionality, sparsity, spurious heterogeneity, and other data- driven challenges for machine learning algorithms within plant microbiome studies. Current Opinion in Plant Biology71, 102326 (2023)
2023
-
[3]
In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining
Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. pp. 785–794 (2016)
2016
-
[4]
Biometrics pp
DeLong, E.R., DeLong, D.M., Clarke-Pearson, D.L.: Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics pp. 837–845 (1988)
1988
-
[5]
Scientific reports14(1), 9785 (2024)
Forry, S.P., Servetas, S.L., Kralj, J.G., Soh, K., Hadjithomas, M., Cano, R., Carlin, M., Amorim, M.G.d., Auch, B., Bakker, M.G., et al.: Variability and bias in micro- biome metagenomic sequencing: an interlaboratory study comparing experimental protocols. Scientific reports14(1), 9785 (2024)
2024
-
[6]
Advances in Neural Information Processing Systems 37, 45155–45205 (2024) 18 G
Gardner, J., Perdomo, J.C., Schmidt, L.: Large scale transfer learning for tabular data via language modeling. Advances in Neural Information Processing Systems 37, 45155–45205 (2024) 18 G. Perciballi et al
2024
-
[7]
arXiv preprint arXiv:1412.6572 (2014)
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014)
Pith/arXiv arXiv 2014
-
[8]
arXiv preprint arXiv:2511.08667 (2025)
Grinsztajn, L., Flöge, K., Key, O., Birkel, F., Jund, P., Roof, B., Jäger, B., Safaric, D., Alessi, S., Hayler, A., et al.: Tabpfn-2.5: Advancing the state of the art in tabular foundation models. arXiv preprint arXiv:2511.08667 (2025)
Pith/arXiv arXiv 2025
-
[9]
arXiv preprint arXiv:1610.02136 (2016)
Hendrycks, D., Gimpel, K.: A baseline for detecting misclassified and out-of- distribution examples in neural networks. arXiv preprint arXiv:1610.02136 (2016)
Pith/arXiv arXiv 2016
-
[10]
arXiv preprint arXiv:2207.01848 (2022)
Hollmann, N., Müller, S., Eggensperger, K., Hutter, F.: Tabpfn: A transformer that solves small tabular classification problems in a second. arXiv preprint arXiv:2207.01848 (2022)
Pith/arXiv arXiv 2022
-
[11]
Nature637(8045), 319–326 (2025)
Hollmann, N., Müller, S., Purucker, L., Krishnakumar, A., Körfer, M., Hoo, S.B., Schirrmeister, R.T., Hutter, F.: Accurate predictions on small data with a tabular foundation model. Nature637(8045), 319–326 (2025)
2025
-
[12]
arXiv preprint arXiv:2510.06162 (2025)
Kolberg, C., Eggensperger, K., Pfeifer, N.: Tabpfn-wide: Continued pre-training for extreme feature counts. arXiv preprint arXiv:2510.06162 (2025)
arXiv 2025
-
[13]
Frontiers in microbiology15, 1343572 (2024)
Kumar, B., Lorusso, E., Fosso, B., Pesole, G.: A comprehensive overview of micro- biome data in the light of machine learning applications: categorization, accessi- bility, and future directions. Frontiers in microbiology15, 1343572 (2024)
2024
-
[14]
arXiv preprint arXiv:2410.18164 (2024)
Ma, J., Thomas, V., Hosseinzadeh, R., Labach, A., Kamkari, H., Cresswell, J.C., Golestan, K., Yu, G., Caterini, A.L., Volkovs, M.: Tabdpt: Scaling tabular foun- dation models on real data. arXiv preprint arXiv:2410.18164 (2024)
arXiv 2024
-
[15]
MSystems4(1), 10–1128 (2019)
Martino, C., Morton, J.T., Marotz, C.A., Thompson, L.R., Tripathi, A., Knight, R., Zengler, K.: A novel sparse compositional technique reveals microbial pertur- bations. MSystems4(1), 10–1128 (2019)
2019
-
[16]
arXiv preprint arXiv:2112.10510 (2021)
Müller, S., Hollmann, N., Arango, S.P., Grabocka, J., Hutter, F.: Transformers can do bayesian inference. arXiv preprint arXiv:2112.10510 (2021)
arXiv 2021
-
[17]
Nature methods14(11), 1023–1024 (2017)
Pasolli, E., Schiffer, L., Manghi, P., Renson, A., Obenchain, V., Truong, D.T., Beghini, F., Malik, F., Ramos, M., Dowd, J.B., et al.: Accessible, curated metage- nomic data through experimenthub. Nature methods14(11), 1023–1024 (2017)
2017
-
[18]
In: NeurIPS 2024 Third Table Repre- sentation Learning Workshop (2024)
Perciballi, G., Granese, F., Fall, A., Zehraoui, F., Prifti, E., Zucker, J.D.: Adapting tabpfn for zero-inflated metagenomic data. In: NeurIPS 2024 Third Table Repre- sentation Learning Workshop (2024)
2024
-
[19]
arXiv preprint arXiv:2502.05564 (2025)
Qu, J., HolzmÞller, D., Varoquaux, G., Morvan, M.L.: Tabicl: A tabular founda- tion model for in-context learning on large data. arXiv preprint arXiv:2502.05564 (2025)
Pith/arXiv arXiv 2025
-
[20]
arXiv preprint arXiv:2602.11139 (2026)
Qu, J., Holzmüller, D., Varoquaux, G., Morvan, M.L.: Tabiclv2: A better, faster, scalable, and open tabular foundation model. arXiv preprint arXiv:2602.11139 (2026)
arXiv 2026
-
[21]
Current opinion in gastroenterology31(1), 69–75 (2015)
Shreiner, A.B., Kao, J.Y., Young, V.B.: The gut microbiome in health and in disease. Current opinion in gastroenterology31(1), 69–75 (2015)
2015
-
[22]
arXiv preprint arXiv:2506.10707 (2025)
Spinaci, M., Polewczyk, M., Schambach, M., Thelin, S.: Contexttab: A semantics- aware tabular in-context learner. arXiv preprint arXiv:2506.10707 (2025)
arXiv 2025
-
[23]
ACM SIGKDD Explorations Newsletter15(2), 49–60 (2014)
Vanschoren, J., Van Rijn, J.N., Bischl, B., Torgo, L.: Openml: networked science in machine learning. ACM SIGKDD Explorations Newsletter15(2), 49–60 (2014)
2014
-
[24]
Zeng, Y., Dinh, T., Kang, W., Mueller, A.C.: Tabflex: Scaling tabular learning to millions with linear attention. arXiv preprint arXiv:2506.05584 (2025) Title Suppressed Due to Excessive Length 19 A Supplementary Material to Section 3 A.1 Perturbed data example A.2 Perturbation algorithm pseudocodes Algorithm 1Feature Removal Require:Taxonomic abundance m...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.