Do Synthetic Brain MRIs Reliably Improve Tumour Classification? A StyleGAN2-ADA Class-Plane Augmentation Study on BRISC 2025
Pith reviewed 2026-05-25 04:50 UTC · model grok-4.3
The pith
Synthetic brain MRIs from StyleGAN2-ADA improve tumour classification only for MobileViTV2 at a filtered 1:1 ratio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
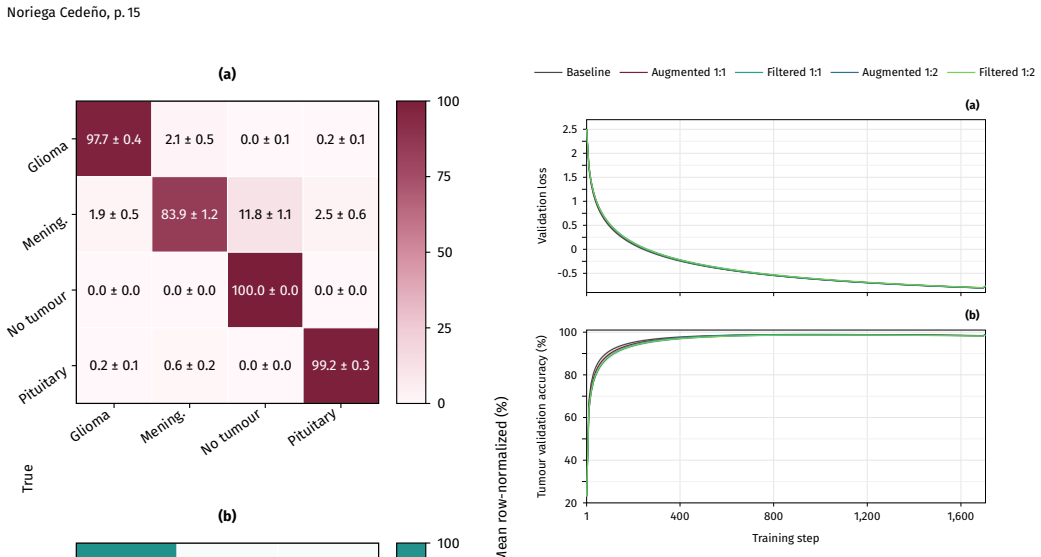
Class-plane StyleGAN2-ADA augmentation supplies architecture- and ratio-dependent gains to tumour classification on BRISC 2025; filtered 1:1 supplementation produces a 1.02 percent absolute accuracy increase (95 percent CI 0.54 to 1.54 percent, Holm-corrected p equals 0.0104) only for MobileViTV2, while the random forest receives no benefit and the compact CNN shows mean gains that fail correction, demonstrating that downstream utility is not assured by visual fidelity alone.
What carries the argument
Class-plane StyleGAN2-ADA generators that produce synthetic MRIs optionally filtered in InceptionV3 feature space before addition to real training sets for downstream tumour classifiers.
If this is right
- Random forest classifiers on InceptionV3 features receive no accuracy benefit from the added synthetic samples at either ratio.
- Compact CNN classifiers record mean accuracy increases that disappear after Holm correction for multiple comparisons.
- MobileViTV2 reaches its largest improvement under filtered 1:1 augmentation.
- Both CNN and MobileViTV2 augmented runs select their best checkpoints after substantially fewer real-data epochs than baseline.
- Augmentation success cannot be inferred from the difficulty of distinguishing real from synthetic images.
Where Pith is reading between the lines
- The architecture dependence suggests that hybrid convolutional-transformer models may exploit distributional cues in the synthetic images differently from pure convolutional or feature-based models.
- Small absolute gains imply that StyleGAN2-ADA outputs may need to be paired with other regularisation techniques to produce larger practical improvements.
- The earlier checkpoint selection under augmentation indicates the synthetic samples may function partly as a training regulariser rather than solely as additional data.
- Varying the strictness of the InceptionV3 filter could be tested to determine whether more selective inclusion of synthetic samples amplifies the observed benefit.
Load-bearing premise
Observed accuracy differences arise from the synthetic samples themselves rather than from random training variation or dataset-specific effects.
What would settle it
Re-running the MobileViTV2 trials with fresh random seeds and checking whether the 1.02 percent gain and its Holm-corrected significance remain stable across independent trainings.
Figures












read the original abstract
Generative augmentation is often proposed as a remedy for small medical-image datasets, but synthetic images are only useful when they improve downstream task performance. "Augmentation" here means synthetic supplementation: GAN-generated samples added to the real training pool, not geometric or photometric transforms of existing images. Twelve class-plane StyleGAN2-ADA generators were trained on constrained BRISC 2025 partitions to test whether their output, with or without InceptionV3 feature-space filtering, improves held-out tumour classification across three classifier families: a random forest (RF) on InceptionV3 features, a compact two-headed convolutional neural network (CNN), and MobileViTV2, a mobile hybrid convolutional-transformer. Each was evaluated at 1:1 and 1:2 real-to-synthetic ratios. An independent GPT-5.5 blind test placed gated real-versus-synthetic discrimination at 57.73% (95% CI: 54.48--60.92%) on the model-legible subset -- modestly above chance. The RF classifier did not benefit from the synthetic MRIs. The CNN showed consistent mean gains that did not survive Holm correction. MobileViTV2 showed the clearest benefit: filtered 1:1 augmentation improved tumour classification accuracy by 1.02% absolute (95% CI: 0.54--1.54%; Holm-corrected p = 0.0104). A secondary efficiency analysis found that every augmented CNN condition selected its checkpoint 42--64% earlier than baseline, while compute-matched MobileViTV2 runs reached selection after 50--67% fewer real-data epochs. Overall, augmentation utility was found to be architecture- and ratio-dependent, not guaranteed by visual fidelity alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates whether synthetic brain MRIs from twelve class-plane StyleGAN2-ADA generators, with or without InceptionV3 feature-space filtering, improve held-out tumour classification when added to real BRISC 2025 training data at 1:1 and 1:2 ratios. Three classifier families are tested: a random forest on InceptionV3 features, a compact two-headed CNN, and MobileViTV2. Results indicate architecture-dependent effects, with no benefit for RF, non-significant gains for CNN after Holm correction, and a 1.02% absolute accuracy improvement for MobileViTV2 under filtered 1:1 augmentation (95% CI 0.54–1.54%, Holm-corrected p=0.0104). A secondary GPT-5.5 blind test reports 57.73% real-vs-synthetic discrimination, supporting that visual fidelity alone does not predict utility. Efficiency gains in checkpoint selection are also noted for augmented conditions.
Significance. If the reported gains and statistical controls hold under full methodological scrutiny, the work supplies concrete empirical evidence that GAN augmentation benefits in medical imaging are classifier-specific rather than universal, cautioning against reliance on generative fidelity metrics alone. The use of Holm correction, explicit CIs, and an independent discrimination test strengthens the falsifiability of the architecture-dependence claim.
major comments (2)
- [Abstract and Methods] Abstract/Methods: The central claim of a statistically significant 1.02% gain for MobileViTV2 rests on held-out accuracy differences, yet the manuscript provides no explicit description of the train/validation/test partitioning of BRISC 2025, the number of independent random seeds or runs used to derive the 95% CIs, or the precise training hyperparameters; these omissions directly affect whether the reported p=0.0104 can be interpreted as evidence against chance or unaccounted variance.
- [Results] Results: The differential outcome across RF (no benefit), CNN (gains fail correction), and MobileViTV2 is presented as supporting architecture dependence, but without tabulated per-run accuracies, variance estimates, or confirmation that all three families used identical data splits and augmentation pipelines, it remains unclear whether the pattern is robust or could arise from implementation differences.
minor comments (1)
- [Abstract] The abstract states that 'twelve class-plane StyleGAN2-ADA generators were trained on constrained BRISC 2025 partitions' but does not specify whether this means one generator per tumour class or another partitioning; a brief clarification in the methods would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on methodological clarity and reproducibility. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract/Methods: The central claim of a statistically significant 1.02% gain for MobileViTV2 rests on held-out accuracy differences, yet the manuscript provides no explicit description of the train/validation/test partitioning of BRISC 2025, the number of independent random seeds or runs used to derive the 95% CIs, or the precise training hyperparameters; these omissions directly affect whether the reported p=0.0104 can be interpreted as evidence against chance or unaccounted variance.
Authors: We agree that these details are necessary for full interpretation of the results. The revised manuscript will expand the Methods section to explicitly describe the train/validation/test partitioning of BRISC 2025, the number of independent random seeds or runs used to compute the 95% CIs and Holm-corrected p-values, and the complete training hyperparameters for each classifier family. revision: yes
-
Referee: [Results] Results: The differential outcome across RF (no benefit), CNN (gains fail correction), and MobileViTV2 is presented as supporting architecture dependence, but without tabulated per-run accuracies, variance estimates, or confirmation that all three families used identical data splits and augmentation pipelines, it remains unclear whether the pattern is robust or could arise from implementation differences.
Authors: We confirm that the RF, CNN, and MobileViTV2 classifiers were evaluated using identical data splits and the same augmentation pipelines. The revised manuscript will add a supplementary table with per-run accuracies and variance estimates across conditions to demonstrate that the architecture-dependent pattern is consistent and not attributable to implementation differences. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a purely empirical study: it trains StyleGAN2-ADA generators on real partitions, produces synthetic samples, augments training sets at explicit 1:1 and 1:2 ratios, trains three classifier families, and reports held-out accuracy with 95% CIs and Holm-corrected p-values. No equations, fitted parameters, or derivations appear; the central claims (architecture-dependent gains, fidelity not guaranteeing utility) are direct experimental outcomes on an independent test set. No self-citation chains or uniqueness theorems are invoked to justify the results. The design measures external performance metrics and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying confidence intervals and Holm multiple-testing correction hold for the reported p-values and CIs.
Reference graph
Works this paper leans on
-
[1]
I. Goodfellow et al. , “Generative adversarial nets,” in Advances in Neural Information Processing Systems , 2014
work page 2014
-
[2]
Unsupervised representation learning with deep convolutional genera- tive adversarial networks,
A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional genera- tive adversarial networks,” in International Conference on Learning Representations , 2016
work page 2016
-
[3]
GANs trained by a two time-scale update rule converge to a local Nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “GANs trained by a two time-scale update rule converge to a local Nash equilibrium,” in Advances in Neural Information Processing Systems , 2017
work page 2017
-
[4]
M. Binkowski, D. J. Sutherland, M. Arbel, and A. Gretton, “Demystifying MMD GANs,” in International Conference on Learning Representations , 2018
work page 2018
-
[5]
Analyzing and improving the image quality of StyleGAN,
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “ Analyzing and improving the image quality of StyleGAN,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020
work page 2020
-
[6]
Training generative adversarial networks with limited data,
T. Karras et al. , “Training generative adversarial networks with limited data,” in Advances in Neural Information Pro- cessing Systems, 2020
work page 2020
-
[7]
Alias-free generative adversarial net- works,
T. Karras et al. , “ Alias-free generative adversarial net- works,” in Advances in Neural Information Processing Sys- tems, 2021
work page 2021
-
[8]
Generative adversarial network in medical imaging: A review ,
X. Yi, E. Walia, and P . Babyn, “Generative adversarial network in medical imaging: A review ,” Medical Image Analysis, vol. 58, 101552, 2019. Noriega Cedeño, p. 18
work page 2019
-
[9]
M. Frid-Adar et al. , “GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification,” Neurocomputing, vol. 321, pp. 321– 331, 2018
work page 2018
-
[10]
H.-C. Shin et al. , “Medical image synthesis for data aug- mentation and anonymization using generative adversar- ial networks,” in International Workshop on Simulation and Synthesis in Medical Imaging , 2018
work page 2018
-
[11]
GAN-based synthetic brain MR image generation,
C. Han et al. , “GAN-based synthetic brain MR image generation,” in IEEE International Symposium on Biomedical Imaging, 2018
work page 2018
-
[12]
Brain tumor image generation using an aggrega- tion of GAN models with style transfer,
D. Mukherkjee, P . Saha, D. Kaplun, A. Sinitca, and R. Sarkar, “Brain tumor image generation using an aggrega- tion of GAN models with style transfer,” Scientific Reports, vol. 12, article 9141, 2022, doi:10.1038/s41598-022-12646-y
-
[13]
Evaluating the performance of StyleGAN2-ADA on medical images,
M. Woodland et al. , “Evaluating the performance of StyleGAN2-ADA on medical images,” arXiv:2210.03786, 2022
-
[14]
Brain tumor segmentation using synthetic MR images: A comparison of GANs and diffusion models,
M. U. Akbar, M. Larsson, I. Blystad, and A. Eklund, “Brain tumor segmentation using synthetic MR images: A comparison of GANs and diffusion models,” Scientific Data, vol. 11, 259, 2024
work page 2024
-
[15]
Brain imaging generation with latent diffusion models,
W. H. L. Pinaya et al. , “Brain imaging generation with latent diffusion models,” arXiv:2209.07162, 2022
-
[16]
Denoising diffusion probabilistic models for 3D medical image generation,
F. Khader et al., “Denoising diffusion probabilistic models for 3D medical image generation,” Scientific Reports , vol. 13, 7303, 2023
work page 2023
-
[17]
G. Müller-Franzes et al. , “ A multimodal comparison of latent denoising diffusion probabilistic models and gener- ative adversarial networks for medical image synthesis,” Scientific Reports , vol. 13, 12098, 2023
work page 2023
-
[18]
BRISC 2025: Brain T umor MRI Dataset for Segmentation and Classification,
A. Fateh et al. , “BRISC 2025: Brain T umor MRI Dataset for Segmentation and Classification,” Kaggle, 2025. [On- line]. Available: https://www.kaggle.com/datasets/ briscdataset/brisc2025. Accessed: February 21, 2026
work page 2025
-
[19]
BRISC: Annotated dataset for brain tumor segmentation and classification,
A. Fateh, Y . Rezvani, S. Moayedi et al., “BRISC: Annotated dataset for brain tumor segmentation and classification,” Scientific Data , vol. 13, 361, 2026, doi: 10.1038/s41597-026- 06753-y
-
[20]
CNNs vs. hybrid transformers for brain tumor classification on the BRISC dataset,
M. Thahiruddin and A. Wulandari, “CNNs vs. hybrid transformers for brain tumor classification on the BRISC dataset,” Jurnal Aplikasi T eknologi Informasi dan Manajemen , vol. 6, no. 1, pp. 24–33, 2025, doi: 10.31102/jatim.v6i1.3545
-
[21]
Generative adversarial synthe- sis and deep feature discrimination of brain tumor MRI images,
M. S. Ali and M. Behzad, “Generative adversarial synthe- sis and deep feature discrimination of brain tumor MRI images,” arXiv:2511.01574, 2025
-
[22]
Convolutional neural networks for medical image analysis: Full training or fine tuning?
N. Tajbakhsh et al. , “Convolutional neural networks for medical image analysis: Full training or fine tuning?” IEEE T ransactions on Medical Imaging , vol. 35, no. 5, pp. 1299– 1312, 2016
work page 2016
-
[23]
L. Breiman, “Random forests,” Machine Learning , vol. 45, pp. 5–32, 2001
work page 2001
-
[24]
Rethinking the Inception architecture for computer vision,
C. Szegedy , V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wo- jna, “Rethinking the Inception architecture for computer vision,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016
work page 2016
-
[25]
Separable self-attention for mobile vision transformers,
S. Mehta and M. Rastegari, “Separable self-attention for mobile vision transformers,” arXiv:2206.02680, 2022
-
[26]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,
A. Kendall, Y . Gal, and R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[27]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy , and J. Melville, “UMAP: Uniform manifold approximation and projection for dimension reduction,” arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
A well-conditioned estimator for large-dimensional covariance matrices,
O. Ledoit and M. Wolf, “ A well-conditioned estimator for large-dimensional covariance matrices,” Journal of Multi- variate Analysis, vol. 88, no. 2, pp. 365–411, 2004
work page 2004
-
[29]
SGDR: Stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,” in International Conference on Learning Representations , 2017
work page 2017
-
[30]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Rep- resentations, 2019
work page 2019
-
[31]
mixup: Beyond empirical risk minimization,
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” in Interna- tional Conference on Learning Representations , 2018
work page 2018
-
[32]
Implementation and benchmarking of per- ceptual image hash functions,
C. Zauner, “Implementation and benchmarking of per- ceptual image hash functions,” B.S. thesis, Alpen-Adria Universität Klagenfurt, Austria, 2010
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.