CFPO: Counterfactual Policy Optimization for Multimodal Reasoning
Pith reviewed 2026-06-26 09:07 UTC · model grok-4.3
The pith
CFPO enforces causal consistency in vision-language models by maximizing prediction discrepancies when visual cues are suppressed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
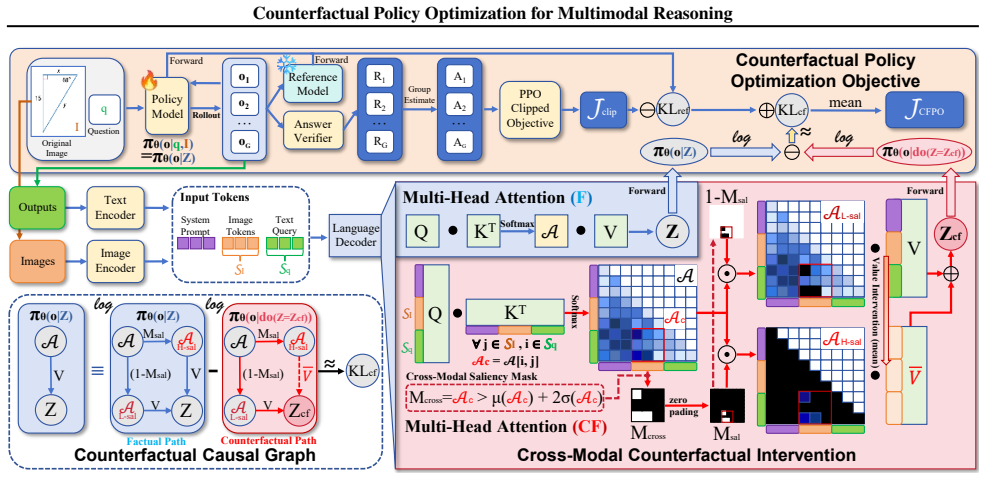
CFPO is a framework that enforces causal consistency between visual perception and textual reasoning by introducing a cross-modal counterfactual enhancement mechanism. The mechanism regularizes the policy by maximizing the discrepancy between the model's predictions on the original input and its predictions on a counterfactual input in which critical visual cues have been suppressed. The resulting objective integrates directly into existing algorithms such as GRPO and DAPO without external reward models or additional supervision and yields measurable gains in reasoning fidelity.
What carries the argument
Cross-modal counterfactual enhancement mechanism that suppresses critical visual cues to form counterfactual states and maximizes the resulting prediction discrepancy to regularize the policy.
If this is right
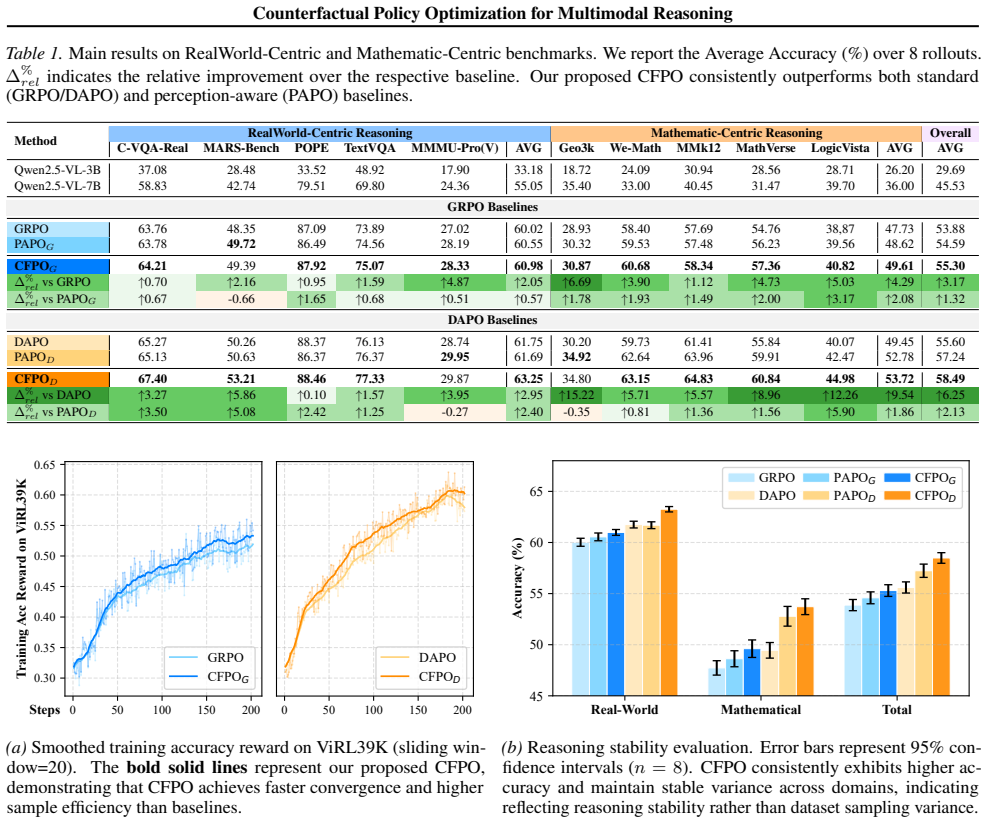
- Yields consistent accuracy gains of 3.17% to 6.25% over standard RL baselines on multimodal reasoning benchmarks.
- Delivers further gains of 1.32% to 2.13% over the prior perception-aware method PAPO.
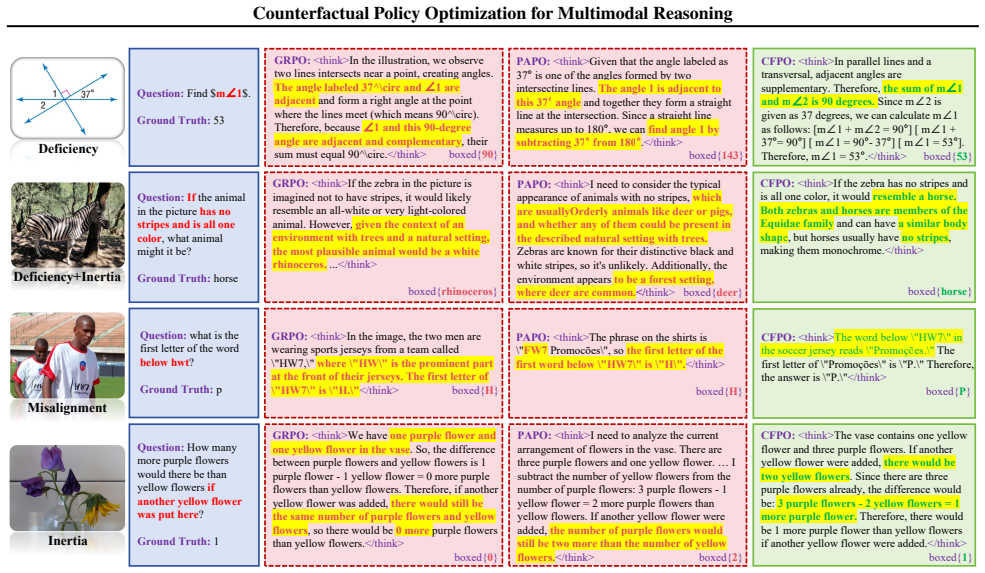
- Reduces the frequency of grounding failures such as visual neglect and hallucination drift during extended chain-of-thought sequences.
- Allows the counterfactual regularizer to be added to existing RL pipelines without new supervision or external models.
Where Pith is reading between the lines
- The same discrepancy-maximization idea could be applied to audio-visual or video reasoning by suppressing key audio or motion features instead of visual cues.
- Similar counterfactual regularization might address over-reliance on statistical patterns in purely textual chain-of-thought settings.
- The method's success hinges on whether the chosen suppression reliably removes the cues that actually drive the model's original prediction.
Load-bearing premise
Maximizing prediction discrepancy under a counterfactual state with suppressed visual cues produces genuine causal grounding that transfers to real reasoning tasks without introducing new failure modes.
What would settle it
A controlled experiment in which CFPO-trained models still answer questions by ignoring explicitly provided visual details that conflict with strong language priors.
Figures













read the original abstract
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in multimodal reasoning. However, prevailing reinforcement learning (RL) paradigms lack explicit counterfactual enhancement and causal learning mechanisms. This fundamental deficiency results in severe grounding failures, manifesting as a tendency to ignore visual evidence in favor of language priors or exhibiting hallucination drift during long chain-of-thought reasoning. To address this root cause, we propose CounterFactual Policy Optimization (CFPO), a novel framework that enforces causal consistency between visual perception and textual reasoning. CFPO introduces a cross-modal counterfactual enhancement mechanism, which regularizes the policy by maximizing the discrepancy between the model's predictions and those from a counterfactual state where critical visual cues are suppressed. This approach seamlessly integrates with standard algorithms like GRPO and DAPO without requiring external reward models or additional supervision. Extensive experiments demonstrate that CFPO significantly improves reasoning fidelity, achieving consistent gains of 3.17%-6.25% over standard RL baselines and 1.32%-2.13% over the state-of-the-art perception-aware method (PAPO). Code is available at https://github.com/Raven-July/CFPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CounterFactual Policy Optimization (CFPO), a framework for large vision-language models that augments standard RL algorithms (GRPO, DAPO) with a cross-modal counterfactual enhancement mechanism. This regularizer maximizes the discrepancy between a model's predictions on a standard forward pass and those on a counterfactual state in which critical visual cues are suppressed, with the goal of enforcing causal consistency between visual perception and textual reasoning. The method is presented as unsupervised (no external reward models required) and is evaluated on multimodal reasoning tasks, reporting gains of 3.17%-6.25% over standard RL baselines and 1.32%-2.13% over the perception-aware baseline PAPO. Code is released at the cited GitHub repository.
Significance. If the reported gains are reproducible and the counterfactual regularizer demonstrably improves causal grounding without introducing new failure modes, the work would offer a practical, integrable technique for mitigating grounding failures and hallucination drift in LVLMs. The explicit release of code is a positive feature that supports verification of the suppression operator and integration equations.
minor comments (3)
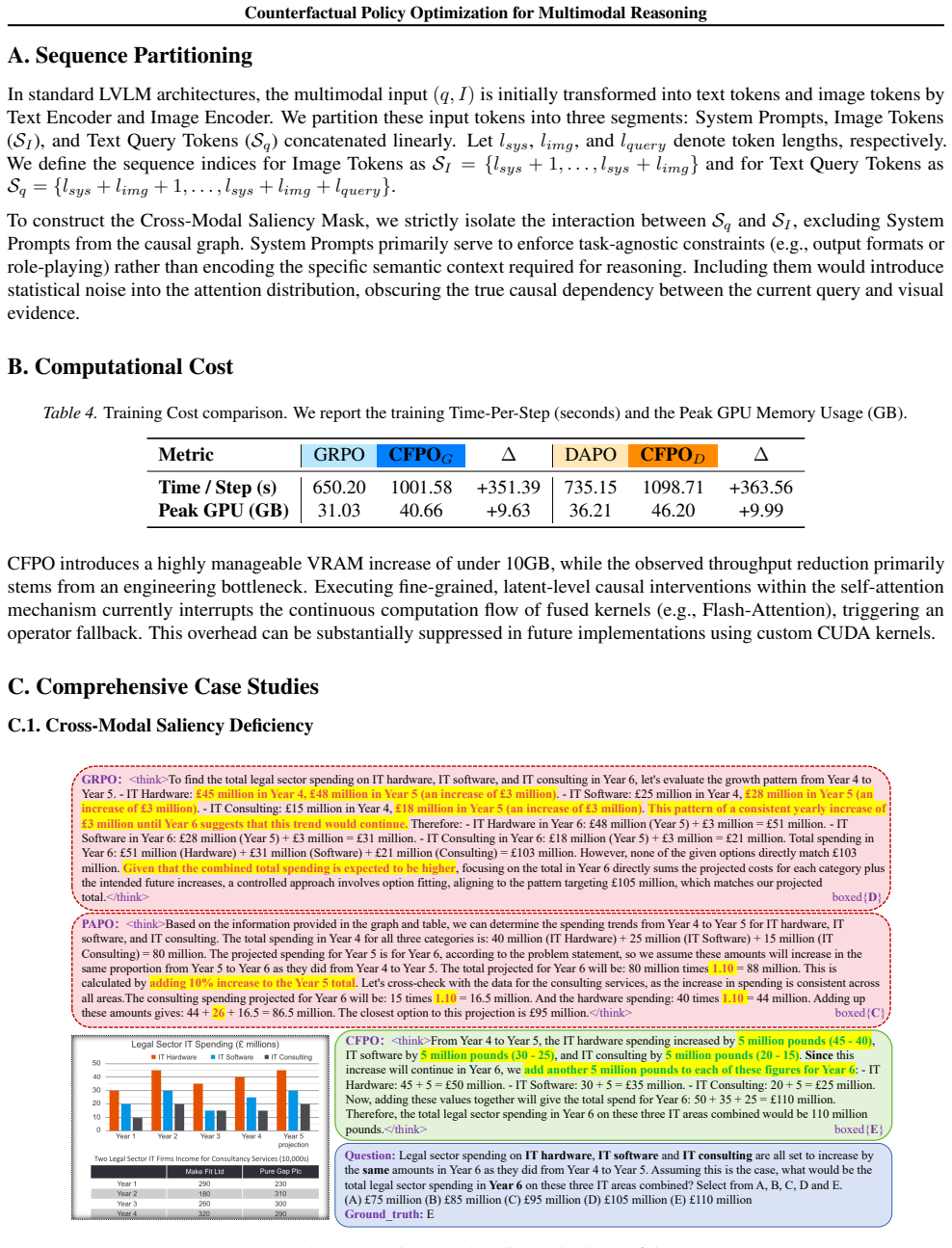
- [§3.2] §3.2: The precise definition of the visual-cue suppression operator (e.g., masking strategy, threshold, or learned component) should be stated explicitly in the main text rather than deferred entirely to the appendix or code, to aid immediate understanding of the counterfactual state construction.
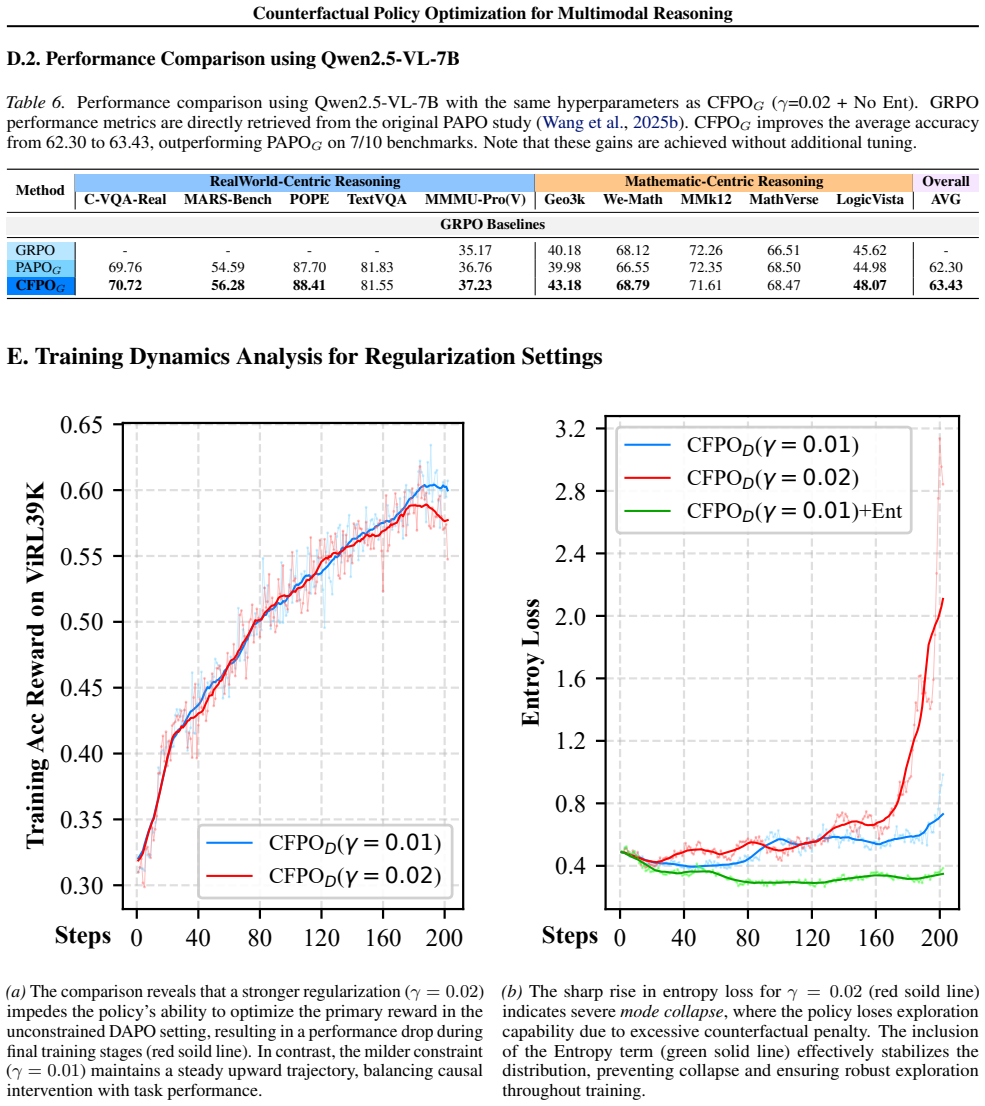
- [Table 2, §4.3] Table 2 and §4.3: The reported standard deviations or number of random seeds for the 3.17%-6.25% gains are not visible in the excerpted results; adding these would strengthen the statistical claim.
- [§4.1] §4.1: The integration equations with DAPO (how the discrepancy term is added to the original objective) would benefit from an explicit side-by-side comparison with the unmodified DAPO loss to clarify any changes to the policy gradient.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, positive assessment of significance, and recommendation of minor revision. The report does not list any specific major comments or concerns requiring rebuttal.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description frame CFPO as an additive regularizer that maximizes prediction discrepancy under a counterfactual suppression operator, then integrates directly with existing algorithms GRPO and DAPO. No equations, derivations, or self-citation chains appear in the text that would reduce any claimed prediction or causal-consistency result to a fitted input or prior result by construction. The reported improvements are presented as empirical outcomes rather than a closed-form derivation, leaving the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv. org/abs/2509.01544. Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Re...
-
[2]
Nature Machine Intelligence , author =
ISSN 2522-5839. doi: 10.1038/s42256-020-00257-z. URL http://dx. doi.org/10.1038/s42256-020-00257-z. Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., and Bing, L. Mitigating object hallucinations in large vision- language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition...
-
[3]
Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., et al. Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
-
[4]
Li, J., Zhang, J., Jie, Z., Ma, L., and Li, G. Mitigating hallucination for large vision language model by inter- modality correlation calibration decoding.arXiv preprint arXiv:2501.01926, 2025a. Li, Y ., Du, Y ., Zhou, K., Wang, J., Zhao, W. X., and Wen, J.-R. Evaluating object hallucination in large vision- language models.arXiv preprint arXiv:2305.1035...
-
[5]
Qiao, R., Tan, Q., Dong, G., Wu, M., Sun, C., Song, X., GongQue, Z., Lei, S., Wei, Z., Zhang, M., et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning?arXiv preprint arXiv:2407.01284,
-
[6]
Proximal policy optimization algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
-
[7]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[8]
Wang, H., Qu, C., Huang, Z., Chu, W., Lin, F., and Chen, W. Vl-rethinker: Incentivizing self-reflection of vision- language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025a. Wang, X., Pan, J., Ding, L., and Biemann, C. Miti- gating hallucinations in large vision-language models with instruction contrastive decoding.arXiv preprint ...
-
[9]
Wang, Z., Guo, X., Stoica, S., Xu, H., Wang, H., Ha, H., Chen, X., Chen, Y ., Yan, M., Huang, F., et al. Perception-aware policy optimization for multimodal rea- soning.arXiv preprint arXiv:2507.06448, 2025b. Xiao, Y ., Sun, E., Liu, T., and Wang, W. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts,
-
[10]
Xu, T., Jing, H., Li, Y ., Wei, Y ., Feng, J., Chen, G., Gao, H., Zhang, T., and Chen, F
URL https://arxiv.org/abs/ 2407.04973. Xu, T., Jing, H., Li, Y ., Wei, Y ., Feng, J., Chen, G., Gao, H., Zhang, T., and Chen, F. Defacto: Counterfactual thinking with images for enforcing evidence-grounded and faithful reasoning.arXiv preprint arXiv:2509.20912,
-
[11]
Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[12]
Yue, X., Zheng, T., Ni, Y ., Wang, Y ., Zhang, K., Tong, S., Sun, Y ., Yu, B., Zhang, G., Sun, H., Su, Y ., Chen, W., and Neubig, G. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark.arXiv preprint arXiv:2409.02813,
-
[13]
Cf- vlm: Counterfactual vision-language fine-tuning.arXiv preprint arXiv:2506.17267,
Zhang, J., Cai, K., Fan, Y ., Wang, J., and Wang, K. Cf- vlm: Counterfactual vision-language fine-tuning.arXiv preprint arXiv:2506.17267,
-
[14]
10 Counterfactual Policy Optimization for Multimodal Reasoning A
URL https://arxiv.org/abs/2310.00754. 10 Counterfactual Policy Optimization for Multimodal Reasoning A. Sequence Partitioning In standard LVLM architectures, the multimodal input(q, I) is initially transformed into text tokens and image tokens by Text Encoder and Image Encoder. We partition these input tokens into three segments: System Prompts, Image Tok...
-
[15]
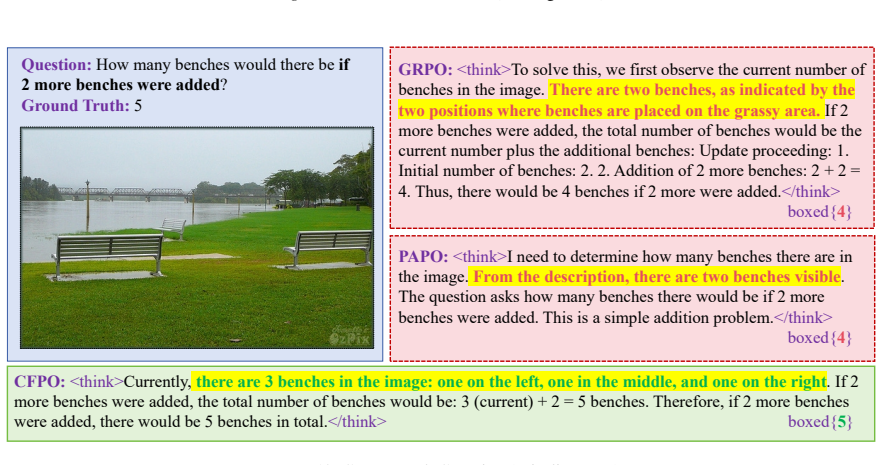
Thus, the hypotenuse x can be found as: [x = 4 \times \sqrt{2}]</think> boxed{4\sqrt{2}} Figure 15.Case: Isosceles Triangle Reasoning (Misalignment) Question: Find AB Ground Truth: 10 GRPO: <think>To find the length of AB, we need to use the given relationship between the sides of the two triangles. The triangles are similar because they have correspondin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.