Greedy Coordinate Diffusion: Effective and Semantically Coherent Adversarial Attacks via Diffusion Guidance
Pith reviewed 2026-06-27 04:33 UTC · model grok-4.3
The pith
Greedy Coordinate Diffusion uses discrete diffusion priors to search for coherent adversarial suffixes that achieve high success rates against safety-aligned LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GCD leverages the generative priors of discrete diffusion language models to guide the search for adversarial suffixes that achieve semantic coherence and adherence, enabling efficient generation of attacks against safety-aligned models in a gray-box setting with the highest attack success rates, competitive response quality, and lower detection rates by perplexity-based and guard-model filters.
What carries the argument
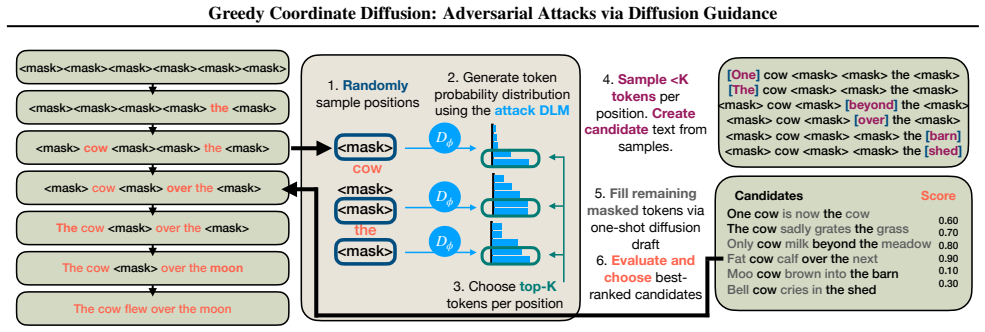
Greedy Coordinate Diffusion (GCD), a search framework that applies generative priors from discrete diffusion language models to direct adversarial suffix construction.
If this is right
- GCD achieves the highest attack success rate among compared methods.
- Response-quality scores stay competitive with other attacks.
- Constructed adversarial prompts are detected at lower rates by perplexity-based and guard-model filters.
- The method operates effectively without requiring direct gradient access to the target model.
Where Pith is reading between the lines
- Diffusion priors may supply a reusable source of semantic structure that other adversarial search algorithms could adopt.
- Models trained with stronger generative diffusion objectives might become both more vulnerable and harder to defend via incoherence filters.
- The same guidance mechanism could be tested as a defense layer that scores prompt coherence against a diffusion prior before generation.
- Gray-box attacks of this form may scale to settings where gradient access is restricted by API design.
Load-bearing premise
The generative priors of discrete diffusion language models can guide suffix search to produce both semantic coherence and successful elicitation of the targeted response.
What would settle it
An experiment replacing the diffusion model guidance in GCD with non-generative search that shows either a sharp drop in attack success rate or a rise in detection rates while holding query intent fixed.
Figures
read the original abstract
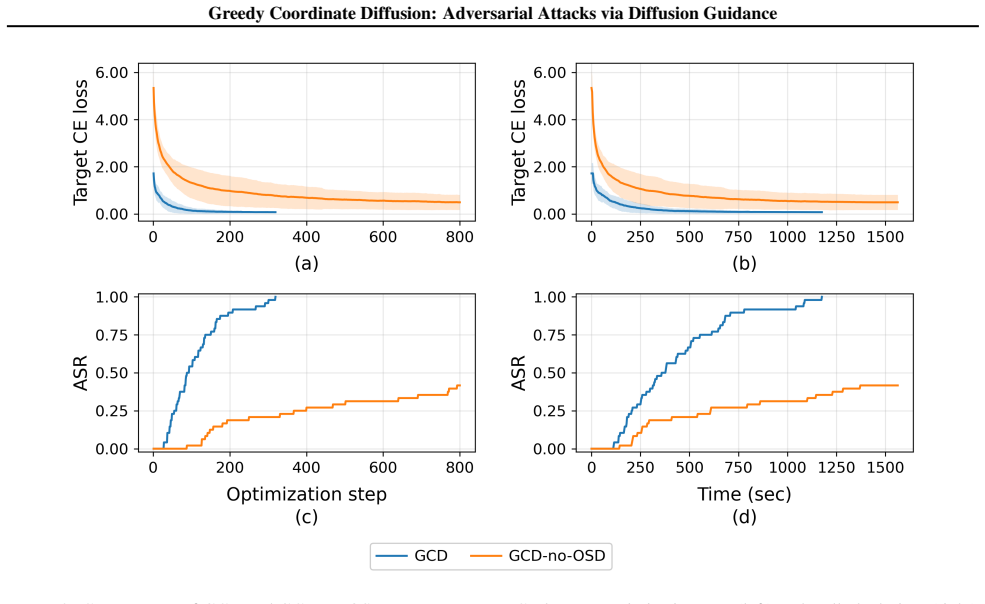
Adversarial attacks on large language models have limited practical impact despite extensive research. Optimization-based attacks such as Greedy Coordinate Gradient (GCG) (Zou et al., 2023) produce high-perplexity, incoherent suffixes that existing defenses easily detect (Bengio et al., 2024). Moreover, attempting to enforce coherence constraints during optimization often prevents the attack from successfully eliciting the specific targeted response, resulting in low success rates against robust models. Conversely, attacks that maintain coherence often alter the semantic intent of queries; when the model complies with these altered queries, responses fail to address the adversary's original goal. In this work, we introduce Greedy Coordinate Diffusion (GCD), a novel framework that efficiently generates adversarial attacks against safety-aligned models while maintaining low perplexity and high semantic adherence to the adversary's original intent. GCD leverages the generative priors of discrete diffusion language models to guide the search for adversarial suffixes that achieve semantic coherence and adherence. Unlike GCG, GCD does not require direct gradient access, allowing it to operate in a gray-box setting. We show GCD achieves highest ASR while remaining competitive on response-quality scores, and that the constructed adversarial prompts are detected at lower rates than other methods by perplexity-based and guard-model filters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Greedy Coordinate Diffusion (GCD), a novel framework for generating adversarial suffixes against safety-aligned LLMs. It leverages generative priors from discrete diffusion language models to guide suffix search, achieving semantic coherence and adherence to the original query intent without direct gradient access (gray-box setting). The central claims are that GCD attains the highest attack success rate (ASR) while remaining competitive on response-quality metrics and producing prompts detected at lower rates than baselines by perplexity-based and guard-model filters, addressing the coherence-vs-elicitation trade-off that limits prior methods such as GCG.
Significance. If the empirical results are substantiated with proper controls, the work would be significant for adversarial ML on LLMs: it offers a mechanism to decouple coherence enforcement from attack failure using diffusion priors, potentially informing both stronger attacks and new detection strategies. The gray-box applicability and avoidance of high-perplexity suffixes are practically relevant strengths.
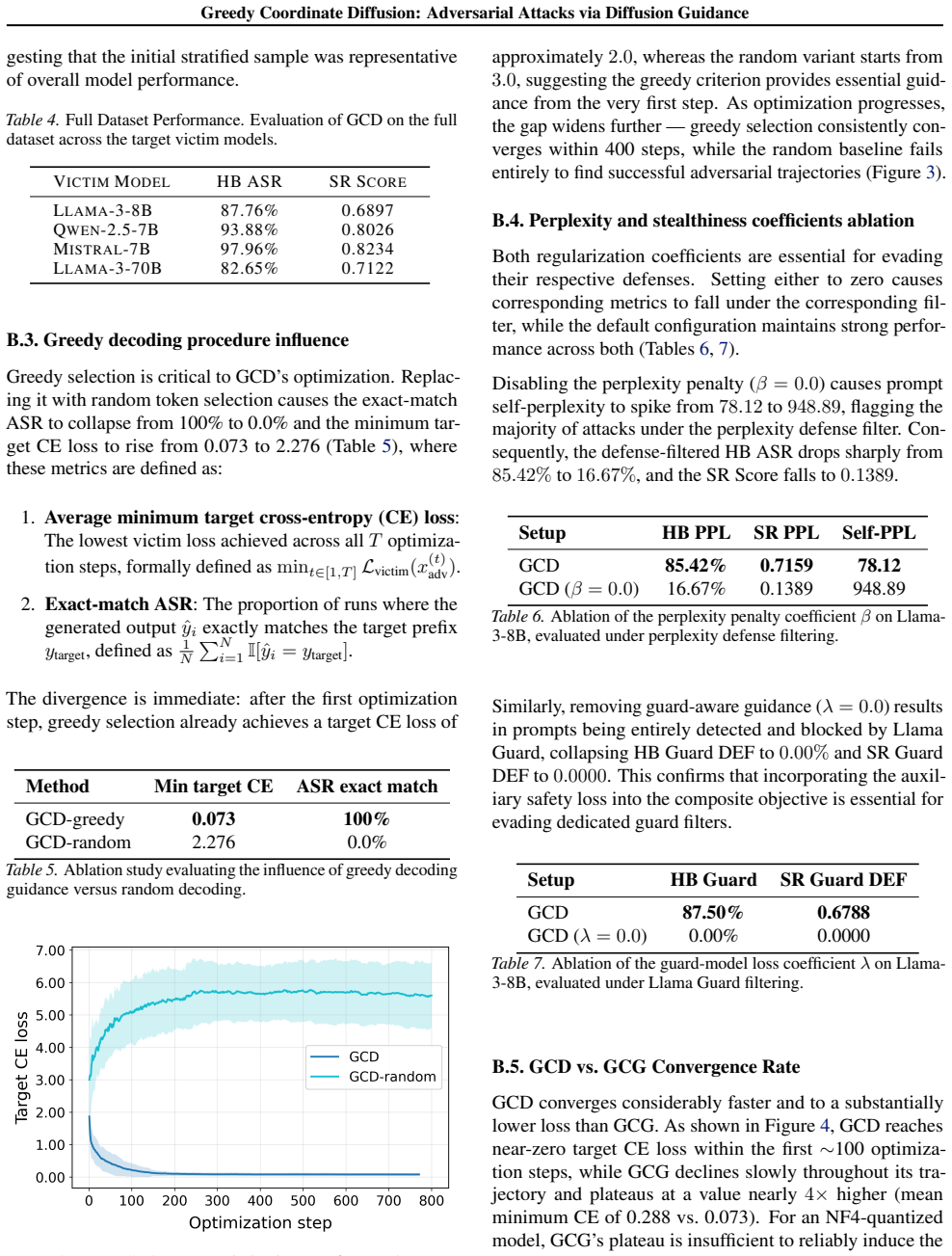
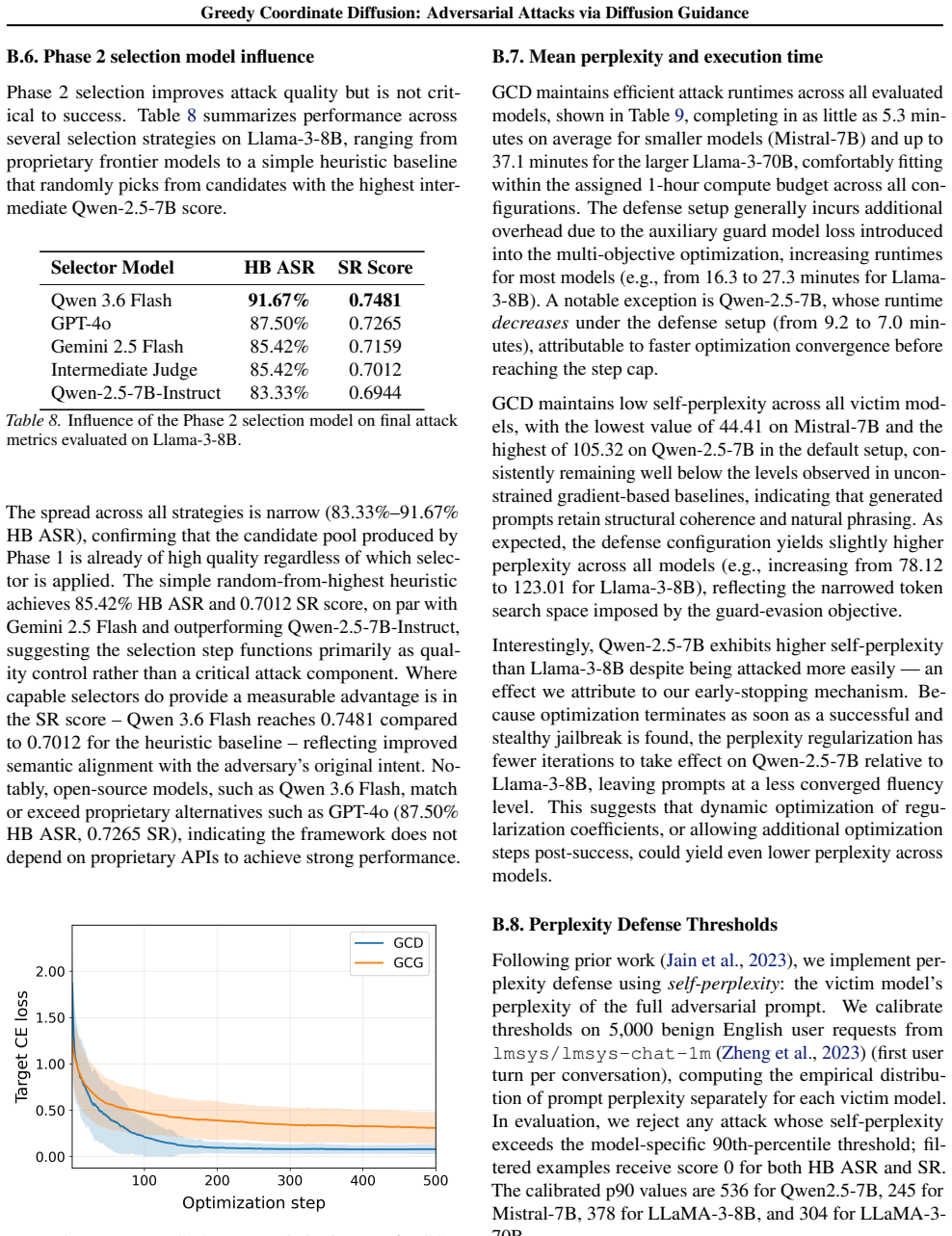
major comments (1)
- [Abstract] Abstract: the claims of 'highest ASR', 'competitive on response-quality scores', and 'detected at lower rates' are asserted without any accompanying experimental details, datasets, baselines, tables, or error bars. This prevents verification of the central empirical contribution.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'highest ASR', 'competitive on response-quality scores', and 'detected at lower rates' are asserted without any accompanying experimental details, datasets, baselines, tables, or error bars. This prevents verification of the central empirical contribution.
Authors: Abstracts are written to be concise high-level summaries; the detailed experimental protocol (AdvBench and related datasets, GCG and other baselines, full tables with ASR, response-quality metrics, detection rates by perplexity/guard models, and error bars or statistical reporting) appears in Sections 4 and 5 together with the associated figures and tables. The abstract claims are therefore directly substantiated by the body of the paper, which follows conventional academic structure. We do not believe the abstract itself requires expansion. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract and available description introduce GCD as a new framework that uses external discrete diffusion language model priors to guide suffix search, without any equations, parameter fits, or derivations shown. No self-citations appear as load-bearing premises, no uniqueness theorems are invoked, and no predictions reduce to fitted inputs by construction. The method is presented as an empirical alternative to GCG with claimed advantages in ASR and detection rates; these rest on external benchmarks rather than internal redefinition. The derivation chain is therefore self-contained against the supplied text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2307.15043 , year=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[2]
arXiv preprint arXiv:2504.10694 , year=
The Jailbreak Tax: How Useful are Your Jailbreak Outputs? , author=. arXiv preprint arXiv:2504.10694 , year=
-
[3]
arXiv preprint arXiv:2508.15487 , year=
Dream 7B: Diffusion Large Language Models , author=. arXiv preprint arXiv:2508.15487 , year=
-
[4]
arXiv preprint arXiv:2310.08419 , year=
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. arXiv preprint arXiv:2310.08419 , year=
-
[5]
Tree of Attacks: Jailbreaking Black-Box
Mehrotra, Anay and Zampetakis, Manolis and Kassianik, Paul and Nelson, Blaine and Anderson, Hyrum and Singer, Yaron and Karbasi, Amin , journal=. Tree of Attacks: Jailbreaking Black-Box
-
[6]
arXiv preprint arXiv:2309.10253 , year=
Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts , author=. arXiv preprint arXiv:2309.10253 , year=
-
[7]
Advances in Neural Information Processing Systems , year=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. Advances in Neural Information Processing Systems , year=
-
[8]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[10]
arXiv preprint arXiv:2309.00614 , year=
Baseline defenses for adversarial attacks against aligned language models , author=. arXiv preprint arXiv:2309.00614 , year=
-
[11]
International Conference on Learning Representations , year=
Safety alignment should be made more than just a few tokens deep , author=. International Conference on Learning Representations , year=
-
[12]
2025 , month = apr, howpublished =
Preparedness Framework , author =. 2025 , month = apr, howpublished =
2025
-
[13]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[14]
Lmsys-chat-1m: A large-scale real-world
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Li, Tianle and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Li, Zhuohan and Lin, Zi and Xing, Eric P and others , journal=. Lmsys-chat-1m: A large-scale real-world
-
[15]
arXiv preprint arXiv:2505.24445 , year=
Learning Safety Constraints for Large Language Models , author=. arXiv preprint arXiv:2505.24445 , year=
-
[16]
arXiv preprint arXiv:2502.17420 , year=
The geometry of refusal in large language models: Concept cones and representational independence , author=. arXiv preprint arXiv:2502.17420 , year=
-
[17]
arXiv preprint arXiv:2412.16339 , year=
Deliberative alignment: Reasoning enables safer language models , author=. arXiv preprint arXiv:2412.16339 , year=
-
[18]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Inferaligner: Inference-time alignment for harmlessness through cross-model guidance , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[19]
arXiv preprint arXiv:2404.14082 , year=
Mechanistic interpretability for AI safety--a review , author=. arXiv preprint arXiv:2404.14082 , year=
-
[20]
Who’s harry potter? approximate unlearning in
Eldan, Ronen and Russinovich, Mark , journal=. Who’s harry potter? approximate unlearning in
-
[21]
arXiv preprint arXiv:2404.11045 , year=
Offset unlearning for large language models , author=. arXiv preprint arXiv:2404.11045 , year=
-
[22]
Jailbreakradar: Comprehensive assessment of jailbreak attacks against
Chu, Junjie and Liu, Yugeng and Yang, Ziqing and Shen, Xinyue and Backes, Michael and Zhang, Yang , booktitle=. Jailbreakradar: Comprehensive assessment of jailbreak attacks against
-
[23]
Proceedings of the 2025 Annual Network and Distributed System Security Symposium (NDSS) , year=
Safety misalignment against large language models , author=. Proceedings of the 2025 Annual Network and Distributed System Security Symposium (NDSS) , year=
2025
-
[24]
Llama guard:
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and others , journal=. Llama guard:
-
[25]
The Llama 3 Family of Models , howpublished =
-
[26]
arXiv preprint arXiv:2510.14276 , year=
Qwen3guard technical report , author=. arXiv preprint arXiv:2510.14276 , year=
-
[27]
Cold-attack: Jailbreaking
Guo, Xingang and Yu, Fangxu and Zhang, Huan and Qin, Lianhui and Hu, Bin , journal=. Cold-attack: Jailbreaking
-
[28]
Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak
Liu, Xiaogeng and Li, Peiran and Suh, Edward and Vorobeychik, Yevgeniy and Mao, Zhuoqing and Jha, Somesh and McDaniel, Patrick and Sun, Huan and Li, Bo and Xiao, Chaowei , journal=. Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak
-
[29]
arXiv preprint arXiv:2502.01633 , year=
Adversarial reasoning at jailbreaking time , author=. arXiv preprint arXiv:2502.01633 , year=
-
[30]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[31]
Advances in neural information processing systems , volume=
Xlnet: Generalized autoregressive pretraining for language understanding , author=. Advances in neural information processing systems , volume=
-
[32]
arXiv preprint arXiv:2210.08933 , year=
Diffuseq: Sequence to sequence text generation with diffusion models , author=. arXiv preprint arXiv:2210.08933 , year=
-
[33]
Advances in neural information processing systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:2302.10025 , year=
Dinoiser: Diffused conditional sequence learning by manipulating noises , author=. arXiv preprint arXiv:2302.10025 , year=
-
[35]
Proceedings of the 41st International Conference on Machine Learning , pages =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , publisher =
2024
-
[36]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2502.09992 , year=
Large language diffusion models , author=. arXiv preprint arXiv:2502.09992 , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
A strongreject for empty jailbreaks , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2501.18837 , year=
Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming , author=. arXiv preprint arXiv:2501.18837 , year=
-
[40]
arXiv preprint arXiv:2601.04603 , year=
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author=. arXiv preprint arXiv:2601.04603 , year=
-
[41]
arXiv preprint arXiv:2412.05282 , year=
International scientific report on the safety of advanced ai (interim report) , author=. arXiv preprint arXiv:2412.05282 , year=
-
[42]
1990 , publisher=
Human error , author=. 1990 , publisher=
1990
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maskgit: Masked generative image transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[44]
arXiv preprint arXiv:2502.06768 , year=
Train for the worst, plan for the best: Understanding token ordering in masked diffusions , author=. arXiv preprint arXiv:2502.06768 , year=
- [45]
-
[46]
Diffusionattacker: Diffusion-driven prompt manipulation for
Wang, Hao and Li, Hao and Zhu, Junda and Wang, Xinyuan and Pan, Chengwei and Huang, MinLie and Sha, Lei , booktitle=. Diffusionattacker: Diffusion-driven prompt manipulation for
-
[47]
arXiv preprint arXiv:2509.03888 , year=
False sense of security: Why probing-based malicious input detection fails to generalize , author=. arXiv preprint arXiv:2509.03888 , year=
-
[48]
arXiv preprint arXiv:2311.11509 , year=
Token-level adversarial prompt detection based on perplexity measures and contextual information , author=. arXiv preprint arXiv:2311.11509 , year=
-
[49]
arXiv preprint arXiv:2405.21018 , year=
Improved techniques for optimization-based jailbreaking on large language models , author=. arXiv preprint arXiv:2405.21018 , year=
-
[50]
Don't say no: Jailbreaking
Zhou, Yukai and Lou, Jian and Huang, Zhijie and Qin, Zhan and Yang, Sibei and Wang, Wenjie , booktitle=. Don't say no: Jailbreaking
-
[51]
arXiv preprint arXiv:2104.13733 , year=
Gradient-based adversarial attacks against text transformers , author=. arXiv preprint arXiv:2104.13733 , year=
-
[52]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[53]
5-coder technical report , author=
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
-
[54]
Jiang, Dongsheng and Liu, Yuchen and Liu, Songlin and Zhao, Jin'e and Zhang, Hao and Gao, Zhen and Zhang, Xiaopeng and Li, Jin and Xiong, Hongkai , journal=. From
-
[55]
Advances in Neural Information Processing Systems , volume=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Towards understanding jailbreak attacks in
Lin, Yuping and He, Pengfei and Xu, Han and Xing, Yue and Yamada, Makoto and Liu, Hui and Tang, Jiliang , journal=. Towards understanding jailbreak attacks in
-
[57]
arXiv preprint arXiv:2310.04451 , year=
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. arXiv preprint arXiv:2310.04451 , year=
-
[58]
Foundations and Trends
Introduction to multi-armed bandits , author=. Foundations and Trends. 2019 , publisher=
2019
-
[59]
arXiv preprint arXiv:1904.09751 , year=
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
Pith/arXiv arXiv 1904
-
[60]
Advprefix: An objective for nuanced
Zhu, Sicheng and Amos, Brandon and Tian, Yuandong and Guo, Chuan and Evtimov, Ivan , journal=. Advprefix: An objective for nuanced
-
[61]
The journal of the Acoustical Society of America , volume=
Perplexity—a measure of the difficulty of speech recognition tasks , author=. The journal of the Acoustical Society of America , volume=. 1977 , publisher=
1977
-
[62]
Computer Speech & Language , volume=
An empirical study of smoothing techniques for language modeling , author=. Computer Speech & Language , volume=. 1999 , publisher=
1999
-
[63]
Proceedings of the twelfth language resources and evaluation conference , pages=
Wenzek, Guillaume and Lachaux, Marie-Anne and Conneau, Alexis and Chaudhary, Vishrav and Guzm. Proceedings of the twelfth language resources and evaluation conference , pages=
-
[64]
Improved generation of adversarial examples against safety-aligned
Li, Qizhang and Guo, Yiwen and Zuo, Wangmeng and Chen, Hao , journal=. Improved generation of adversarial examples against safety-aligned
-
[65]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[66]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[67]
arXiv preprint arXiv:2402.04249 , year=
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
-
[68]
2023 , eprint=
Detecting Language Model Attacks with Perplexity , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.