video-SALMONN-R³: Learning to ReWatch, ReAsk, and ReAnswer for Efficient Video Understanding
Pith reviewed 2026-06-26 00:16 UTC · model grok-4.3
The pith
video-SALMONN-R³ trains a video LLM with reinforcement learning to re-watch relevant segments without chain-of-thought supervision or data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
video-SALMONN-R³ enables re-watch through reinforcement learning without relying on chain-of-thought cold-start. This removes the need for costly CoT data annotations and avoids CoT-based supervised fine-tuning, which can otherwise degrade the pretrained video understanding abilities. The model first produces a direct answer in the first watch and then refines it after re-watching. A re-ask mechanism re-injects the query when revisiting localized segments. Experimental results show that video-SALMONN-R³ consistently outperforms both the base model and the QA-SFT baseline, while surpassing prior re-watch-based approaches with significantly lower computational cost.
What carries the argument
Reinforcement learning policy that induces re-watch, re-ask, and re-answer actions on a pretrained video-LLM, paired with the re-answer strategy to match pretrained answer-first tendencies.
If this is right
- The model outperforms the base video-LLM and a QA-supervised fine-tuning baseline on video question answering tasks.
- It exceeds earlier re-watch methods while using substantially less computation overall.
- No chain-of-thought annotations or supervised fine-tuning are required, removing that data collection cost.
- Pretrained video understanding abilities remain intact because the chain-of-thought supervised fine-tuning stage is skipped.
Where Pith is reading between the lines
- The same reinforcement learning loop could be tested on longer untrimmed videos to see whether selective re-watching scales without proportional compute growth.
- Combining the re-answer and re-ask steps with existing frame-sampling heuristics might further reduce memory use during inference.
- The approach opens a route to apply similar reinforcement learning signals to other multimodal tasks that benefit from iterative attention, such as video captioning.
Load-bearing premise
Reinforcement learning can successfully induce effective re-watch behavior in a pretrained video-LLM without any chain-of-thought supervised fine-tuning step that would degrade its original abilities.
What would settle it
If training the model with the described reinforcement learning loop produces no measurable gain in video QA accuracy and no observable re-watch behavior on test videos, the central claim would not hold.
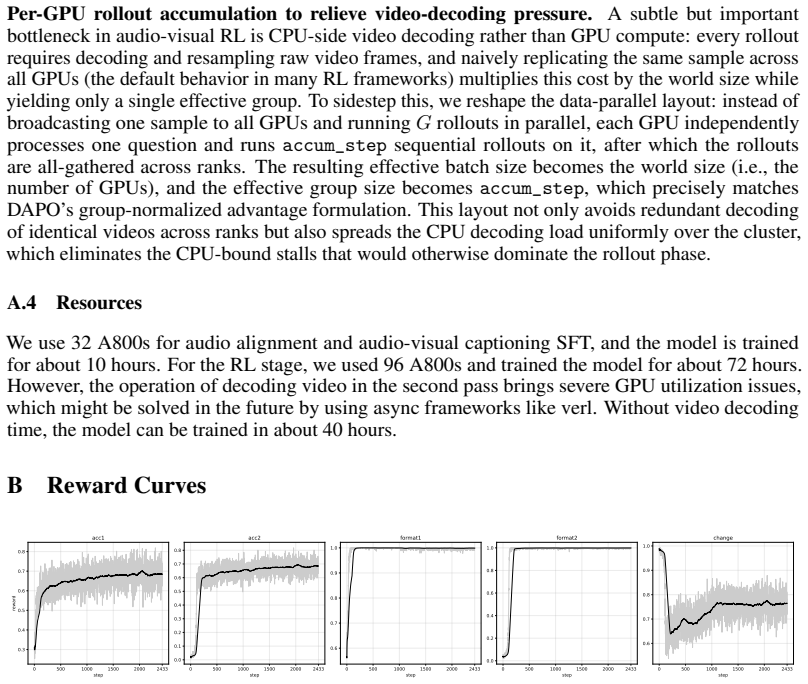
Figures



read the original abstract
Video large language models (LLMs) are often constrained by computation and memory budgets, leading them to use reduced frame rates and spatial resolutions, which may cause them to miss critical information for question answering (QA). A practical and efficient solution is a two-stage paradigm: first perform coarse video understanding to localize relevant segments, and then re-watch these segments at higher temporal or spatial fidelity. In this paper, we present video-SALMONN-R$^3$, the first end-to-end video-LLM that enables re-watch through reinforcement learning without relying on chain-of-thought (CoT) cold-start. This design removes the need for costly CoT data annotations and avoids CoT-based supervised fine-tuning (SFT), which can otherwise degrade the pretrained video understanding abilities. To address the mismatch between the reasoning-first behavior induced by re-watch and the answer-first tendency of pretrained video-LLMs, we propose a re-answer strategy, in which the model first produces a direct answer in the first watch and then refines it after re-watching. Finally, to improve question adherence during re-watching, we propose a re-ask mechanism that re-injects the query when revisiting localized segments. Experimental results show that video-SALMONN-R$^3$ consistently outperforms both the base model and the QA-SFT baseline, while surpassing prior re-watch-based approaches with significantly lower computational cost. Code, models, and data will be publicly released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces video-SALMONN-R³, the first end-to-end video-LLM that uses reinforcement learning to enable re-watching of localized segments at higher fidelity for QA tasks. It avoids CoT cold-start SFT by proposing a re-answer strategy (direct answer first, then refine after re-watch) and a re-ask mechanism (re-inject query on revisit), claiming consistent outperformance over the base model and QA-SFT baseline at lower computational cost.
Significance. If the central claim holds, the result would be significant for efficient video understanding: it would show that RL alone can induce effective re-watch behavior in pretrained video-LLMs without the degradation from CoT SFT, eliminating the need for costly CoT annotations while maintaining or improving performance under tight compute budgets.
major comments (3)
- [§3] §3 (RL formulation): the scalar reward used to induce re-watch behavior (accuracy only, length penalty, explicit re-watch bonus, or combination) is not defined, which is load-bearing for the claim that RL succeeds where CoT SFT fails.
- [§3.2] §3.2 (policy optimization): the algorithm (PPO, GRPO, or other), state augmentation for re-watch decisions, and any KL-regularization or stability terms are unspecified, preventing evaluation of whether the approach preserves pretrained abilities.
- [Experiments] Experiments section: no reward formulation, training curves, ablation results on re-answer/re-ask, or statistical details are provided to support the claim of consistent outperformance at lower cost.
minor comments (1)
- The promise to release code, models, and data upon acceptance is a positive step for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional technical detail is required to fully substantiate our claims. We address each major comment below and will incorporate the requested clarifications and supporting results in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (RL formulation): the scalar reward used to induce re-watch behavior (accuracy only, length penalty, explicit re-watch bonus, or combination) is not defined, which is load-bearing for the claim that RL succeeds where CoT SFT fails.
Authors: We agree that the precise scalar reward is central and was insufficiently specified. The reward is a linear combination of QA accuracy (binary correctness of the final answer) and a length penalty on total generated tokens; no explicit re-watch bonus is included. The exact mathematical definition will be added to Section 3. revision: yes
-
Referee: [§3.2] §3.2 (policy optimization): the algorithm (PPO, GRPO, or other), state augmentation for re-watch decisions, and any KL-regularization or stability terms are unspecified, preventing evaluation of whether the approach preserves pretrained abilities.
Authors: Policy optimization is performed with PPO. The state for re-watch decisions is augmented with localized segment features and the re-injected query from the re-ask mechanism. Standard KL regularization to the reference policy is applied for stability. The full algorithm description, state representation, and regularization coefficient will be provided in the revised Section 3.2. revision: yes
-
Referee: [Experiments] Experiments section: no reward formulation, training curves, ablation results on re-answer/re-ask, or statistical details are provided to support the claim of consistent outperformance at lower cost.
Authors: We acknowledge that these supporting elements are absent from the current experiments section. The revision will add the reward formulation (cross-referenced to the updated §3), training curves, ablations isolating re-answer and re-ask, and statistical details including standard deviations and significance testing over multiple seeds. revision: yes
Circularity Check
No circularity: method introduces new RL component without reducing claims to self-defined fits or self-citation chains
full rationale
The paper describes an empirical method extending prior video-LLMs via a new RL-based re-watch mechanism, re-answer strategy, and re-ask mechanism, without any equations, derivations, or parameter-fitting steps that reduce the claimed performance gains to quantities defined by the authors' own inputs or prior results. The central claim rests on experimental outcomes rather than a mathematical chain that loops back by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. This is the standard case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLaV A-OneVision: Easy Visual Task Transfer.arXiv preprint arXiv:2408.03326, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. LLaV A-OneVision: Easy Visual Task Transfer.arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[2]
Video Instruction Tuning with Synthetic Data.arXiv preprint arXiv:2410.02713, 2024
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video Instruction Tuning with Synthetic Data.arXiv preprint arXiv:2410.02713, 2024
Pith/arXiv arXiv 2024
-
[3]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, and Chao Zhang. SALMONN: Towards Generic Hearing Abilities for Large Language Models. InProc. ICLR, Vienna, 2024
2024
-
[4]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-SALMONN 2: Caption-Enhanced Audio-Visual Large Language Models.arXiv preprint arXiv:2506.15220, 2025
arXiv 2025
-
[6]
A V oCaDO: An Audiovisual Video Captioner Driven by Temporal Orches- tration
Xinlong Chen, Yue Ding, Weihong Lin, Jingyun Hua, Linli Yao, Yang Shi, Bozhou Li, Yuanxing Zhang, Qiang Liu, Pengfei Wan, et al. A V oCaDO: An Audiovisual Video Captioner Driven by Temporal Orches- tration. InProc. ICLR, Rio de Janeiro, 2026
2026
-
[7]
Qwen3-Omni Technical Report.arXiv preprint arXiv:2509.17765, 2025
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-Omni Technical Report.arXiv preprint arXiv:2509.17765, 2025
Pith/arXiv arXiv 2025
-
[8]
Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[9]
NVILA: Efficient Frontier Visual Language Models.arXiv preprint arXiv:2412.04468, 2024
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. NVILA: Efficient Frontier Visual Language Models.arXiv preprint arXiv:2412.04468, 2024
Pith/arXiv arXiv 2024
-
[10]
Improving LLM Video Understanding with 16 Frames Per Second
Yixuan Li, Changli Tang, Jimin Zhuang, Yudong Yang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. Improving LLM Video Understanding with 16 Frames Per Second. InProc. ICML, Vancouver, 2025
2025
-
[11]
Minghao Qin, Xiangrui Liu, Zhengyang Liang, Yan Shu, Huaying Yuan, Juenjie Zhou, Shitao Xiao, Bo Zhao, and Zheng Liu. Video-XL-2: Towards Very Long-Video Understanding Through Task-Aware KV Sparsification.arXiv preprint arXiv:2506.19225, 2025
arXiv 2025
-
[12]
video- SALMONN S: Memory-Enhanced Streaming Audio-Visual LLM.arXiv preprint arXiv:2510.11129, 2025
Guangzhi Sun, Yixuan Li, Xiaodong Wu, Yudong Yang, Wei Li, Zejun Ma, and Chao Zhang. video- SALMONN S: Memory-Enhanced Streaming Audio-Visual LLM.arXiv preprint arXiv:2510.11129, 2025
arXiv 2025
-
[13]
VideoLucy: Deep Memory Backtracking for Long Video Understanding
Jialong Zuo, Yongtai Deng, Lingdong Kong, Jingkang Yang, Rui Jin, Yiwei Zhang, Nong Sang, Liang Pan, Ziwei Liu, and Changxin Gao. VideoLucy: Deep Memory Backtracking for Long Video Understanding. InProc. NeurIPS, Mexico, 2025
2025
-
[14]
Jeong Hun Yeo, Sangyun Chung, Sungjune Park, Dae Hoe Kim, Jinyoung Moon, and Yong Man Ro. Gcagent: Long-video understanding via schematic and narrative episodic memory.arXiv preprint arXiv:2511.12027, 2025
arXiv 2025
-
[15]
LOVE-R1: Advancing Long Video Understanding with an Adaptive Zoom-in Mechanism via Multi-Step Reasoning
Shenghao Fu, Qize Yang, Yuan-Ming Li, Xihan Wei, Xiaohua Xie, and Wei-Shi Zheng. LOVE-R1: Advancing Long Video Understanding with an Adaptive Zoom-in Mechanism via Multi-Step Reasoning. InProc. ICLR, Rio de Janeiro, 2026
2026
-
[16]
Thinking with Long Videos
Zuhao Yang, Sudong Wang, Kaichen Zhang, Keming Wu, Sicong Leng, Yifan Zhang, Chengwei Qin, Shijian Lu, Xingxuan Li, and Lidong Bing. LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling. InProc. CVPR, Colorado, 2026
2026
-
[17]
VideoChat-R1.5: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception
Ziang Yan, Yinan He, Xinhao Li, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. VideoChat-R1.5: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception. InProc. NeurIPS, Mexico, 2025
2025
-
[18]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning. arXiv preprint arXiv:2504.06958, 2025. 10
Pith/arXiv arXiv 2025
-
[19]
VideoZoomer: Reinforcement-Learned Temporal Focusing for Long Video Reasoning
Yang Ding, Yizhen Zhang, Xin Lai, Ruihang Chu, and Yujiu Yang. VideoZoomer: Reinforcement-Learned Temporal Focusing for Long Video Reasoning. InProc. ICLR, Rio de Janeiro, 2026
2026
-
[20]
Houlun Chen, Xin Wang, Guangyao Li, Yuwei Zhou, Yihan Chen, Jia Jia, and Wenwu Zhu. Think with Grounding: Curriculum Reinforced Reasoning with Video Grounding for Long Video Understanding. arXiv preprint arXiv:2602.18702, 2026
arXiv 2026
-
[21]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-R1: Reinforcing Video Reasoning in MLLMs. InProc. NeurIPS, Mexico, 2025
2025
-
[22]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, et al. DAPO: An Open-Source LLM Reinforcement Learning System at Scale. InProc. NeurIPS, Mexico, 2025
2025
-
[23]
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, and Deli Zhao. VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding.arXiv preprint arXiv:2501.13106, 2025
Pith/arXiv arXiv 2025
-
[24]
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, and Limin Wang. VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling. InProc. ICLR, Rio de Janeiro, 2026
2026
-
[25]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[26]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs.arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[27]
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, Yuxuan Wang, and Chao Zhang. video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models. In Proc. ICML, 2024
2024
-
[28]
Qwen2.5-Omni Technical Report.arXiv preprint arXiv:2503.20215, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2.5-Omni Technical Report.arXiv preprint arXiv:2503.20215, 2025
Pith/arXiv arXiv 2025
-
[29]
Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Ziyang Ma, Ruiyang Xu, Zhenghao Xing, Yunfei Chu, Yuxuan Wang, Jinzheng He, Jin Xu, Pheng-Ann Heng, Kai Yu, Junyang Lin, et al. Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception. Rio de Janeiro, 2026
2026
-
[30]
Changli Tang, Tianyi Wang, Fengyun Rao, Jing LYU, and Chao Zhang. D-ORCA: Dialogue-Centric Optimization for Robust Audio-Visual Captioning.arXiv preprint arXiv:2602.07960, 2026
arXiv 2026
-
[31]
Junbo Cui, Bokai Xu, Chongyi Wang, Tianyu Yu, Weiyue Sun, Yingjing Xu, Tianran Wang, Zhihui He, Wenshuo Ma, Tianchi Cai, et al. MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction.arXiv preprint arXiv:2604.27393, 2026
Pith/arXiv arXiv 2026
-
[32]
Junjie Fei, Jun Chen, Zechun Liu, Yunyang Xiong, Chong Zhou, Wei Wen, Junlin Han, Mingchen Zhuge, Saksham Suri, Qi Qian, et al. Small Vision-Language Models are Smart Compressors for Long Video Understanding.arXiv preprint arXiv:2604.08120, 2026
Pith/arXiv arXiv 2026
-
[33]
AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding
Xiao Wang, Qingyi Si, Jianlong Wu, Shiyu Zhu, Li Cao, and Liqiang Nie. AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding. InProc. ACL (Findings), Vienna, 2025
2025
-
[34]
APVR: Hour-Level Long Video Understanding with Adaptive Pivot Visual Information Retrieval
Hong Gao, Yiming Bao, Xuezhen Tu, Bin Zhong, Linan Yue, and Min-Ling Zhang. APVR: Hour-Level Long Video Understanding with Adaptive Pivot Visual Information Retrieval . InProc. AAAI, Singapore, 2026
2026
-
[35]
Xuyang Liu, Yiyu Wang, Junpeng Ma, and Linfeng Zhang. Video Compression Commander: Plug- and-Play Inference Acceleration for Video Large Language Models.arXiv preprint arXiv:2505.14454, 2025
arXiv 2025
-
[36]
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zenghui Ding, Xianjun Yang, and Yining Sun. Beyond Training: Dynamic Token Merging for Zero-Shot Video Understanding.arXiv preprint arXiv:2411.14401, 2024. 11
arXiv 2024
-
[37]
Minsoo Kim, Kyuhong Shim, Jungwook Choi, and Simyung Chang. InfiniPot-V: Memory-Constrained KV Cache Compression for Streaming Video Understanding.arXiv:2506.15745, 2025
arXiv 2025
-
[38]
Streaming Long Video Understanding with Large Language Models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming Long Video Understanding with Large Language Models. InProc. NeurIPS, 2024
2024
-
[39]
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-VStream: Memory-Based Real-Time Understanding for Long Video Streams.arXiv preprint arXiv:2406.08085, 2024
arXiv 2024
-
[40]
Dispider: Enabling Video LLMs with Active Real-Time Interaction via Disentangled Perception, Decision, and Reaction
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling Video LLMs with Active Real-Time Interaction via Disentangled Perception, Decision, and Reaction. InProc. CVPR, 2025
2025
-
[41]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. InProc. ICLR, 2022
2022
-
[42]
Robust Speech Recognition via Large-scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust Speech Recognition via Large-scale Weak Supervision. InProc. ICML, 2023
2023
-
[43]
LibriSpeech: An ASR Corpus Based on Public Domain Audio Books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. LibriSpeech: An ASR Corpus Based on Public Domain Audio Books. InProc. ICASSP, 2015
2015
-
[44]
Common V oice: A Massively-Multilingual Speech Corpus
Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Tyers, and Gregor Weber. Common V oice: A Massively-Multilingual Speech Corpus. InProc. LREC, 2020
2020
-
[45]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. WavCaps: A Chatgpt-Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multimodal Research.IEEE Transactions on Audio, Speech and Language Processing, 32:3339–3354, 2024
2024
-
[46]
AudioCaps: Generating Captions for Audios in the Wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. AudioCaps: Generating Captions for Audios in the Wild. InProc. NAACL-HLT, 2019
2019
-
[47]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[48]
Cinepile: A long video question answering dataset and benchmark.arXiv:2405.08813, 2024
Ruchit Rawal, Khalid Saifullah, Ronen Basri, David Jacobs, Gowthami Somepalli, and Tom Goldstein. Cinepile: A long video question answering dataset and benchmark.arXiv:2405.08813, 2024
arXiv 2024
-
[49]
Cg-bench: Clue-grounded question answering benchmark for long video understanding
Guo Chen, Yicheng Liu, Yifei Huang, Yuping He, Baoqi Pei, Jilan Xu, Yali Wang, Tong Lu, and Limin Wang. Cg-bench: Clue-grounded question answering benchmark for long video understanding. InProc. ICLR, Singapore, 2025
2025
-
[50]
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?arXiv preprint arXiv:2505.21374, 2025
Pith/arXiv arXiv 2025
-
[51]
Ziwei Zhou, Rui Wang, and Zuxuan Wu. Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities.arXiv preprint arXiv:2505.17862, 2025
arXiv 2025
-
[52]
Audio-centric Video Understanding Benchmark without Text Shortcut
Yudong Yang, Jimin Zhuang, Guangzhi Sun, Changli Tang, Yixuan Li, Peihan Li, Yifan Jiang, Wei Li, Zejun Ma, and Chao Zhang. Audio-centric Video Understanding Benchmark without Text Shortcut. In Proc. EMNLP, Suzhou, 2025
2025
-
[53]
OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Jiafu Tang, Zhenghao Song, Dingling Zhang, et al. OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs. InProc. ICLR, Rio de Janeiro, 2026
2026
-
[54]
Video-MME: The First Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-MME: The First Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. InProc. CVPR, Nashville TN, 2025
2025
-
[55]
Keda Tao, Yuhua Zheng, Jia Xu, Wenjie Du, Kele Shao, Hesong Wang, Xueyi Chen, Xin Jin, Junhan Zhu, Bohan Yu, et al. LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs.arXiv preprint arXiv:2603.19217, 2026. 12
arXiv 2026
-
[56]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProc. SOSP, Koblenz, 2023
2023
-
[57]
Liger-Kernel: Efficient Triton Kernels for LLM Training
Pin-Lun Hsu, Yun Dai, Vignesh Kothapalli, Qingquan Song, Shao Tang, Siyu Zhu, Steven Shimizu, Shivam Sahni, Haowen Ning, Yanning Chen, and Zhipeng Wang. Liger-Kernel: Efficient Triton Kernels for LLM Training. InProc. ICML Workshop, Vancouver, 2025
2025
-
[58]
DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. InProc. KDD, 2020. A More Implementation Details A.1 System Prompt The reinforcement learning stage of video-SALMONN-R3 relies on a carefully crafted system prompt that specifies the proto...
2020
-
[59]
to replace several memory- and compute-heavy operators in the Qwen3-VL backbone with fused Triton kernels, most notably the fused cross-entropy, RMSNorm, RoPE, and SwiGLU im- plementations. These fused kernels reduce both activation memory and kernel-launch overhead, which in our long-trajectory regime directly translates into a larger per-GPU effective b...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.