How Few-Shot Examples Add Up: A Causal Decomposition of Function Vectors in In-Context Learning
Pith reviewed 2026-05-20 19:15 UTC · model grok-4.3
The pith
An n-shot function vector approximates the sum of one-shot sub-vectors from each example, with added context-driven reweighting of their contributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
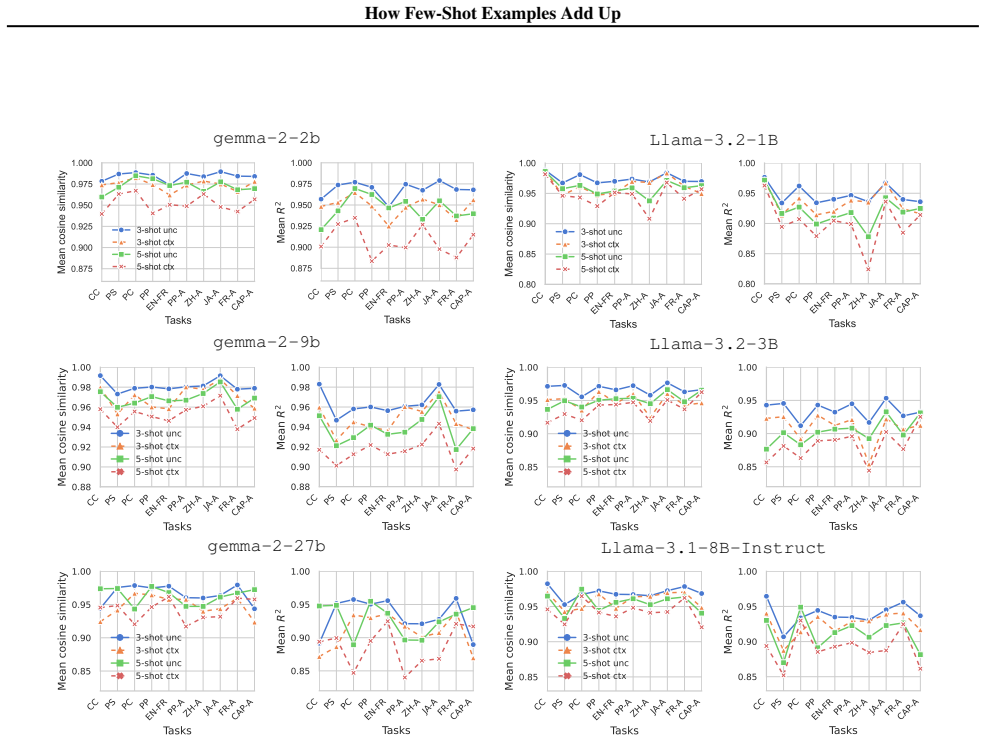
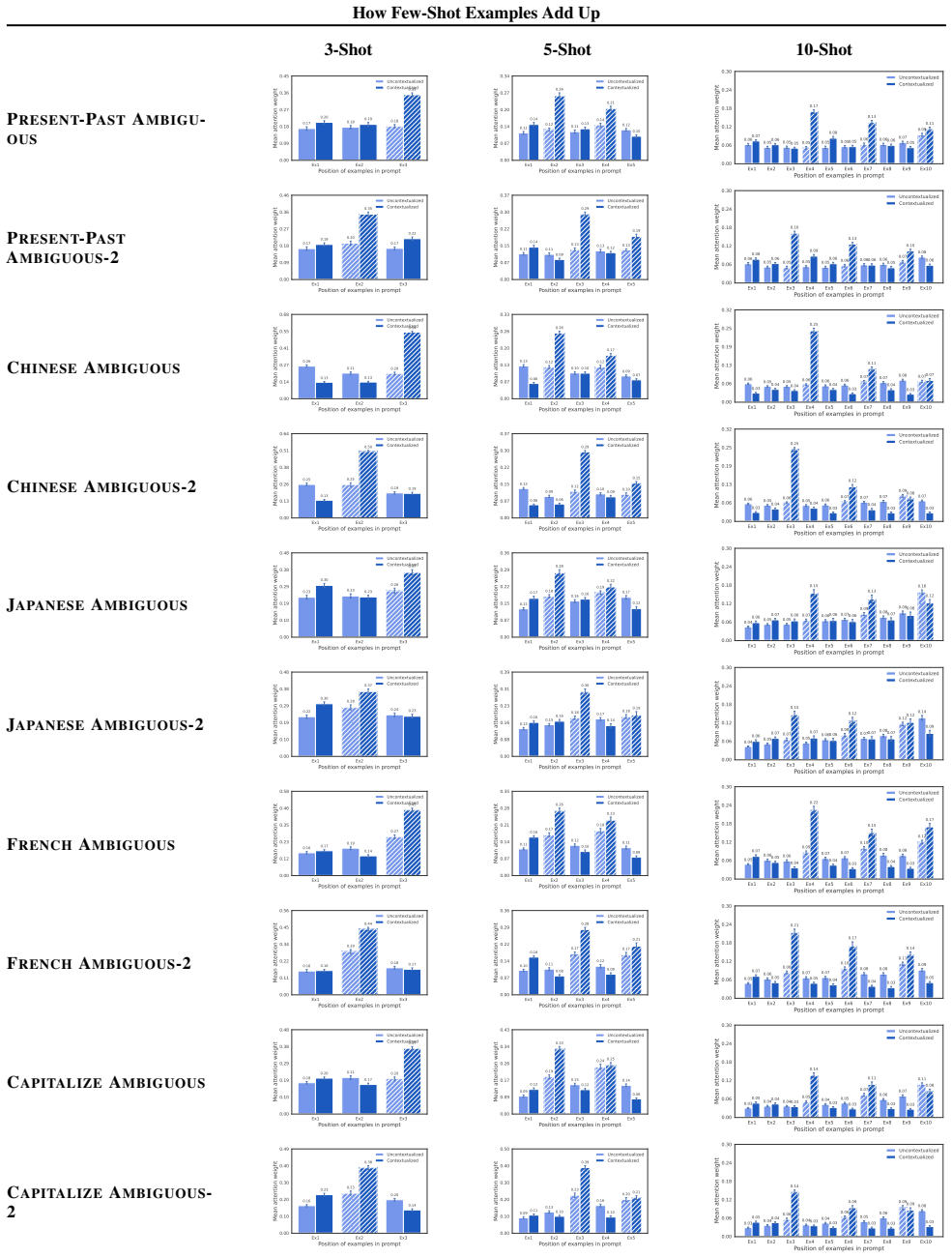
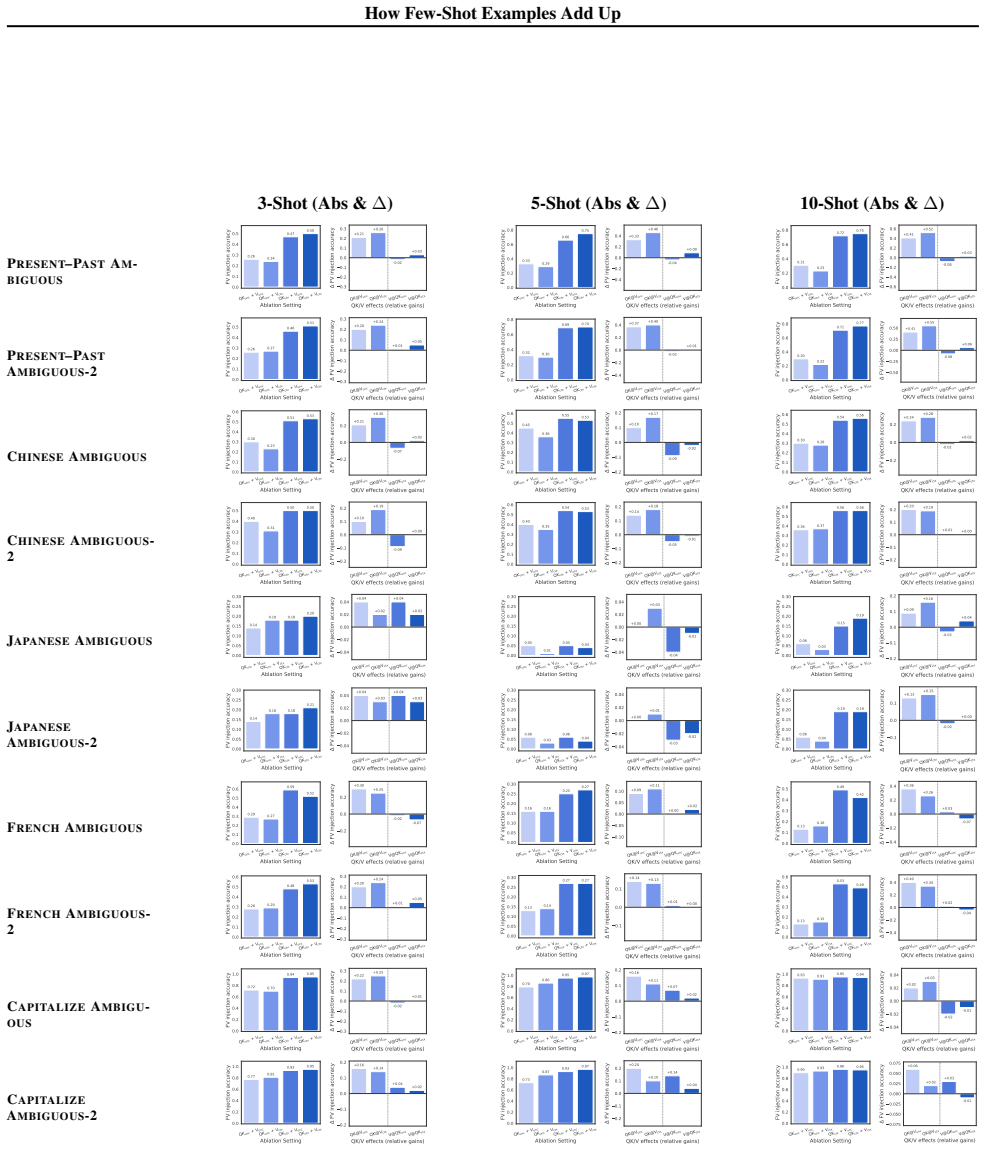
Across tasks and models, an n-shot function vector is well-approximated by a linear combination of example-level sub-function vectors, indicating additive and composable contributions from individual demonstrations. Models further contextualize each example's representation according to the examples that precede it, adaptively reweighting which demonstrations most strongly shape the overall function vector. The dominant causal contribution to this reweighting comes from query-key alignment in attention, particularly when examples are ambiguous, whereas value-mediated updates produce more heterogeneous effects.
What carries the argument
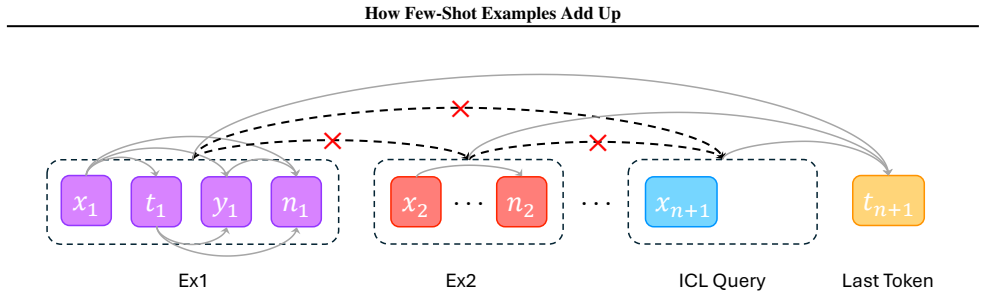
The function vector, defined as the causal activation direction that steers the model toward the demonstrated task on a query, together with its decomposition into per-example sub-vectors and the attention-based reweighting that adjusts their relative influence.
If this is right
- Multi-shot performance could be predicted from single-example measurements if the linear approximation continues to hold.
- The order in which examples appear should affect which ones dominate the final function vector because of the contextual reweighting.
- Targeted improvements to query-key alignment during training or inference could strengthen in-context learning on ambiguous inputs.
- Demonstrations that remain ambiguous even after earlier context is provided contribute less to the overall task direction.
Where Pith is reading between the lines
- Similar additive decompositions might appear in chain-of-thought or other structured prompting formats if the same internal mechanism is at work.
- Training objectives that reward better contextual reweighting of examples could improve few-shot robustness without increasing example count.
- The pattern may extend to non-language settings such as vision or multimodal models if function-vector-like directions exist there.
- Redundant or mutually inconsistent examples should produce smaller net function vectors under this additive-plus-reweighting view.
Load-bearing premise
That the measured shifts in attention and query-key interactions are direct causes of better function-vector performance rather than incidental byproducts of the intervention technique.
What would settle it
If an intervention that prevents the observed attention shifts toward less ambiguous examples leaves the function vector's task performance unchanged on ambiguous queries, the causal account of reweighting would be falsified.
Figures




























































read the original abstract
In-context learning (ICL) excels at new tasks from minimal examples, yet we still lack a mechanistic explanation of how few-shot prompts shape a model's function vector (FV)--a causal activation direction that drives task behavior on the ICL query. Across tasks and models, an $n$-shot FV is well-approximated by a linear combination of example-level sub-FVs, suggesting additive and composable contributions from individual demonstrations. Beyond additivity, we show that models contextualize individual examples' representations based on prior examples to adaptively reweight which demonstrations dominate the FV: attention shifts toward examples that are more informative and less ambiguous under the context. Finally, a causal decomposition separates Query-Key routing from Value updates, finding that contextualization's most consistent contributions to FV quality arise from Query-Key alignment--particularly in ambiguous settings--while Value-mediated effects are more heterogeneous. Together, these results unify additive superposition with context-dependent attention reweighting into a mechanistic, testable account of how few-shot prompts implement tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that across tasks and models, an n-shot function vector (FV) in in-context learning is well-approximated by a linear combination of example-level sub-FVs, indicating additive and composable contributions from individual demonstrations. It further reports that models contextualize individual examples via attention shifts to adaptively reweight demonstrations (favoring informative, less ambiguous ones), and a causal decomposition separates Query-Key routing from Value updates, finding that Query-Key alignment provides the most consistent contributions to FV quality, especially in ambiguous contexts, while Value-mediated effects are more heterogeneous.
Significance. If the results hold, the work offers a mechanistic, testable account unifying additive superposition with context-dependent attention reweighting in ICL. Strengths include consistent empirical patterns across tasks/models and the use of causal interventions to probe the decomposition. This could inform prompt design and LLM interpretability. The additivity approximation is less vulnerable to intervention concerns, but the contextualization and QK-dominance claims depend on clean separation of effects.
major comments (2)
- [Causal Decomposition] Causal Decomposition section: the claim that Query-Key alignment effects are the primary causal driver of FV quality improvements (particularly in ambiguous settings) requires stronger evidence that the intervention isolates QK routing without confounding from entangled attention components or indirect reweighting; if QK and Value pathways share downstream effects, the reported dominance may reflect correlated side effects rather than direct causation.
- [Contextualization and Reweighting] Contextualization results: while attention shifts toward more informative examples are reported, the analysis would benefit from explicit controls confirming these are not artifacts of the specific intervention method or model routing, as this is load-bearing for the claim that models adaptively reweight demonstrations beyond simple additivity.
minor comments (3)
- Clarify the precise extraction and normalization procedure for sub-FVs and how linear coefficients are fitted, including any regularization or constraints applied.
- Add statistical details such as confidence intervals or p-values for the approximation quality of the linear combination across the reported tasks and models.
- Ensure consistent notation for FV, sub-FV, and attention components throughout; define all acronyms on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We provide point-by-point responses to the major comments below and will make revisions to address the concerns about evidence strength in our causal decomposition and controls for contextualization results.
read point-by-point responses
-
Referee: [Causal Decomposition] Causal Decomposition section: the claim that Query-Key alignment effects are the primary causal driver of FV quality improvements (particularly in ambiguous settings) requires stronger evidence that the intervention isolates QK routing without confounding from entangled attention components or indirect reweighting; if QK and Value pathways share downstream effects, the reported dominance may reflect correlated side effects rather than direct causation.
Authors: We appreciate the referee raising this important point about the isolation of effects in our causal interventions. In the manuscript, we separate Query-Key routing by intervening on the pre-softmax attention scores derived from QK alignments while preserving the Value vectors, following established methods in attention mechanism analysis. Our results indicate that these QK interventions yield more reliable improvements to FV quality, especially under ambiguity, compared to Value interventions which are more variable. To mitigate concerns about confounding or shared downstream effects, we will expand the revision with additional experiments that quantify the independence of these pathways, including measuring residual effects after QK intervention and vice versa. This will clarify that the dominance of QK is not an artifact of correlation. revision: partial
-
Referee: [Contextualization and Reweighting] Contextualization results: while attention shifts toward more informative examples are reported, the analysis would benefit from explicit controls confirming these are not artifacts of the specific intervention method or model routing, as this is load-bearing for the claim that models adaptively reweight demonstrations beyond simple additivity.
Authors: Thank you for this feedback. We note that the attention reweighting analysis is based on direct observation of attention patterns in the standard forward computation, without any interventions applied. To address potential artifacts from model routing or specific setups, we will add explicit control experiments in the revised manuscript. These include randomizing example orders, using shuffled contexts, and comparing to baseline models with fixed attention. The results of these controls will be presented to demonstrate that the shifts toward informative and less ambiguous examples are indeed adaptive and not spurious, thereby supporting our claims about contextualization beyond additivity. revision: yes
Circularity Check
No significant circularity; empirical measurements and interventions are self-contained
full rationale
The paper's central claims rest on empirical approximations of n-shot function vectors as linear combinations of sub-FVs, observed attention shifts, and causal interventions separating Query-Key from Value effects. These are obtained via direct measurements and interventions on model activations rather than any derivation that reduces to fitted parameters or self-defined quantities by construction. No equations or results are presented as predictions that are statistically forced by prior fits within the paper. Self-citations, if present, are not load-bearing for the core additivity or decomposition findings, which are tested across tasks and models with external falsifiability through interventions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Function vectors are causal activation directions that drive task behavior on the ICL query
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.